Aplicativos de dados (alinhado à origem)
Se você optou por não implementar um mecanismo independente de dados para ingerir dados uma vez de fontes operacionais ou se conexões complexas não forem facilitadas no mecanismo independente de dados, crie um aplicativo de dados alinhado à origem. Ele deve seguir o mesmo fluxo que um mecanismo independente de dados seguiria ao ingerir dados de fontes de dados externas.
Visão geral
O grupo de recursos de aplicativo é responsável pela ingestão e enriquecimento de dados somente de fontes externas, como telemetria, finanças ou CRM. Essa camada pode operar em tempo real, em lote e em microlote.
Esta seção explica a infraestrutura implantada para cada grupo de recursos de (alinhado à origem) dentro de uma zona de destino de dados.
Dica
Para a malha de dados, você pode optar por implantar um deles por origem ou um por domínio. Os princípios de padronização de dados, qualidade de dados e linhagem de dados ainda devem ser seguidos. As equipes de operações de plataforma de dados podem desenvolver snippets de código padrão e chamá-los para fazer isso.
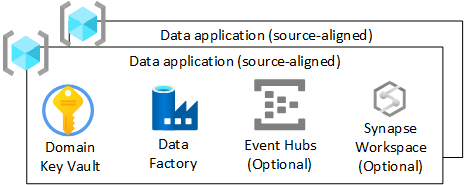
Para cada grupo de recursos de aplicativo de dados (alinhado à origem) na zona de destino de dados, você deve criar:
- Um Azure Key Vault
- Um Azure Data Factory para executar pipelines de engenharia desenvolvidos para transformar de brutos em enriquecidos
- Uma entidade de serviço usada pelo aplicativo de dados (alinhado à origem) para implantar trabalhos de ingestão no Azure Databricks (somente se estiver usando o Azure Databricks)
Você também podem criar instâncias de outros serviços, como Hubs de Eventos do Azure, Hub IoT do Azure, Azure Stream Analytics e Azure Machine Learning.
Observação
Você precisa usar um mecanismo do spark, como o Azure Synapse Spark ou o Azure Databricks, para impor o padrão delta lake.
Se você decidir usar o Azure Databricks, recomendamos implantar o Azure Data Factory, em vez do workspace do Azure Synapse Analytics, para reduzir a área de superfície para somente recursos necessários.
No entanto, se você precisar de uma área de desenvolvimento abrangente com pipelines e spark, use o Azure Synapse Analytics. Aplique uma política para permitir apenas o uso de spark e pipelines, para evitar a criação de silos em um pool de SQL do Azure Synapse.
Cofre de Chave do Azure
Use a funcionalidade do Azure Key Vault para armazenar segredos no Azure, sempre que possível.
Cada aplicativo de dados (alinhado à origem) ou domínio de dados (em caso de malha) terá um Azure Key Vault. Isso garante que a chave de criptografia, o segredo e a derivação do certificado atendam aos requisitos do ambiente. Isso permite uma melhor separação de tarefas administrativas e também reduz o risco de misturar chaves, integrações e segredos de classificações diferentes.
Todas as chaves relacionadas ao aplicativo de dados (alinhado à origem) devem estar no Azure Key Vault.
Importante
Os cofres de chaves do aplicativo de dados (alinhado à origem) devem seguir o modelo de privilégios mínimos e evitar os limites de escala de transações e o compartilhamento de segredos entre ambientes.
Fábrica de dados do Azure
Implante um Azure Data Factory para permitir que os pipelines gravados pela equipe de aplicativos de dados transformar dados de brutos em enriquecidos usando pipelines desenvolvidos. Use fluxos de dados de mapeamento para transformações e use o workspace do Azure Databricks (ingestão) ou o Spark do Azure Synapse para transformações complexas.
Você deve conectar o Azure Data Factory à instância de DevOps do repositório de aplicativos de dados (alinhados à origem). Essa conexão permite implantações de CI/CD.
Hubs de Eventos
Se o aplicativo de dados (alinhado à origem) tiver um requisito de transmissão de entrada de dados, você poderá implantar Hubs de Eventos downstream no grupo de recursos de aplicativo de dados (alinhado à origem).