O que é o reconhecimento de palavra-chave?
O reconhecimento de palavra-chave detecta uma palavra ou frase curta em um fluxo de áudio. Ele também é chamado de detecção de palavra-chave.
O caso de uso mais comum de reconhecimento de palavra-chave é a ativação de assistentes virtuais por voz. Por exemplo, "Ei Cortana" é a palavra-chave da assistente Cortana. Após o reconhecimento da palavra-chave, uma ação específica do cenário é executada. Para cenários de assistente virtual, uma ação resultante comum é o reconhecimento de fala do áudio que segue a palavra-chave.
Em geral, os assistentes virtuais estão sempre escutando. O reconhecimento de palavra-chave atua como um limite de privacidade para o usuário. Um requisito de palavra-chave atua como uma porta que impede que um áudio do usuário não relacionado ultrapasse o dispositivo local e chegue na nuvem.
Para equilibrar a precisão, a latência e a complexidade computacional, o reconhecimento de palavra-chave é implementado como um sistema de vários estágios. Para todas as fases além da primeira, o áudio só será processado se a fase anterior a ele reconhecer a palavra-chave de interesse.
O sistema atual foi projetado com vários estágios que abrangem a borda e a nuvem:
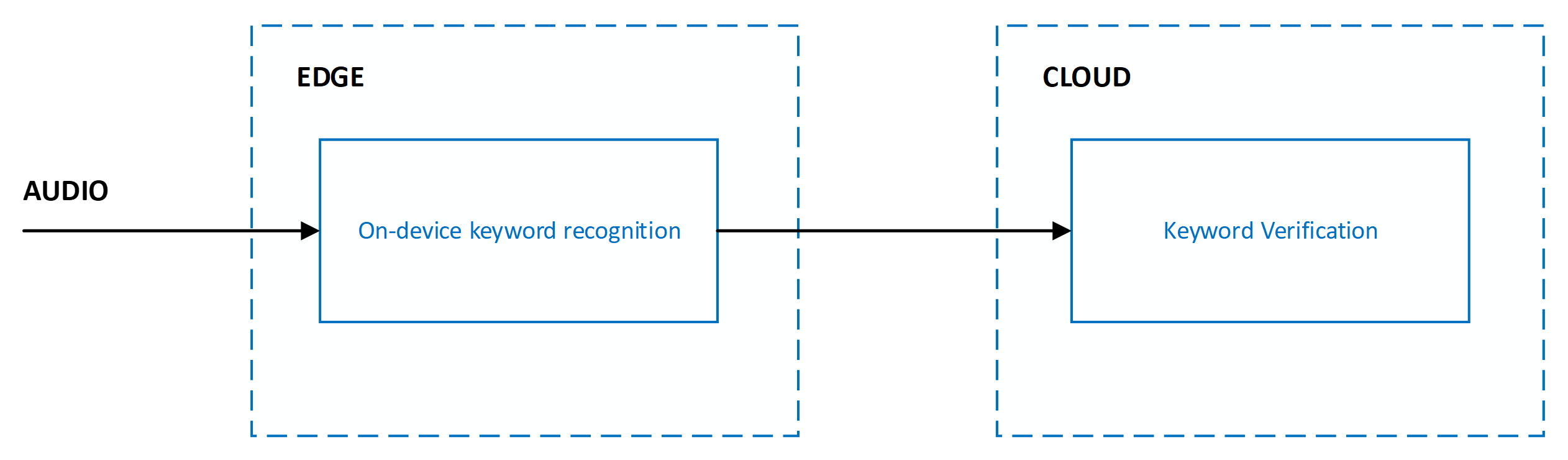
A precisão do reconhecimento de palavra-chave é medida por meio das seguintes métricas:
- Taxa de aceitação correta: Mede a capacidade do sistema de reconhecer a palavra-chave quando ela é falada por um usuário. A taxa de aceitação correta também é conhecida como a taxa de verdadeiro positivo.
- Taxa de aceitação falsa: Mede a capacidade do sistema de filtrar o áudio que não é a palavra-chave falada por um usuário. A taxa de aceitação falsa também é conhecida como a taxa de falso positivo.
A meta é maximizar a taxa de aceitação correta, minimizando a taxa de aceitação falsa. O sistema atual foi projetado para detectar uma palavra-chave ou frase precedida por um curto período de silêncio. Não há suporte para a detecção de uma palavra-chave no meio de uma frase ou enunciado.
Palavra-chave personalizada para modelos no dispositivo
Com o portal de Palavra-chave Personalizada no Speech Studio é possível gerar modelos de reconhecimento de palavra-chave, que são executados na borda, especificando qualquer palavra ou frase curta. Você pode personalizar ainda mais o modelo de palavra-chave escolhendo as pronúncias corretas.
Preços
Não há nenhum custo para usar o recurso palavra-chave personalizada a fim de gerar modelos, inclusive modelos básicos e avançados. Também não há custo para executar modelos no dispositivo com o SDK de Fala quando usado com outros recursos do serviço de Fala, como a conversão de fala em texto.
Tipos de modelos
É possível usar o recurso Palavra-chave Personalizada para gerar dois tipos de modelos no dispositivo para qualquer palavra-chave.
| Tipo de modelo | Descrição |
|---|---|
| Basic | Mais adequado para fins de demonstração ou criação rápida de protótipos. Os modelos são gerados com um modelo base comum e podem levar até 15 minutos para ficar prontos. Os modelos podem não ter características de precisão ideais. |
| Avançado | Mais adequado para fins de integração de produtos. Os modelos são gerados com a adaptação de um modelo base comum usando dados de treinamento simulados para aprimorar as características de precisão. Pode levar até 48 horas para que os modelos fiquem prontos. |
Observação
Veja uma lista de regiões com suporte ao tipo de modelo Avançado na documentação de Suporte a região de reconhecimento de palavras-chave.
Nenhum tipo de modelo exige que você carregue os dados de treinamento. O recurso Palavra-chave Personalizada processa completamente a geração de dados e o treinamento do modelo.
Pronúncias
Durante a criação de um novo modelo, o recurso Palavra-chave Personalizada gera automaticamente possíveis pronúncias da palavra-chave fornecida. Você pode escutar cada pronúncia e escolher todas as variações que mais representam como se espera que os usuários finais digam a palavra-chave. Nenhuma outra pronúncia deve ser selecionada.
É importante analisar bem as pronúncias selecionadas para garantir as melhores características de precisão. Por exemplo, se você escolher mais pronúncias do que o necessário, poderá obter taxas de aceitação falsa mais altas. Se você escolher poucas pronúncias, sem abranger todas as variações esperadas, poderá obter uma taxa de aceitação de correto mais baixa.
Modelos de teste
Depois que a palavra-chave personalizada gera os modelos no dispositivo, eles podem ser testados diretamente no portal. É possível usar o portal para falar diretamente no navegador e receber os resultados de reconhecimento de palavra-chave.
Verificação de palavra-chave
A verificação de palavra-chave é um serviço de nuvem que reduz o efeito de falsas aceitações de modelos no dispositivo com modelos robustos em execução no Azure. Não é necessário fazer ajustes nem treinamento para que a Verificação de Palavra-chave funcione com a palavra-chave. Atualizações incrementais de modelo são implantadas continuamente no serviço para aprimorar a precisão e a latência, e são transparentes para aplicativos cliente.
Preços
A verificação de palavras-chave é sempre usada em combinação com a conversão de fala em texto. Não há custo para usar a verificação de palavras-chave além do custo da conversão de fala em texto.
Verificação de palavras-chave e conversão de fala em texto
Quando a verificação de palavras-chave é usada, ela está sempre em combinação com a conversão de fala em texto. Ambos os serviços são executados em paralelo, o que significa que o áudio é enviado para os ambos os serviços para processamento simultâneo.
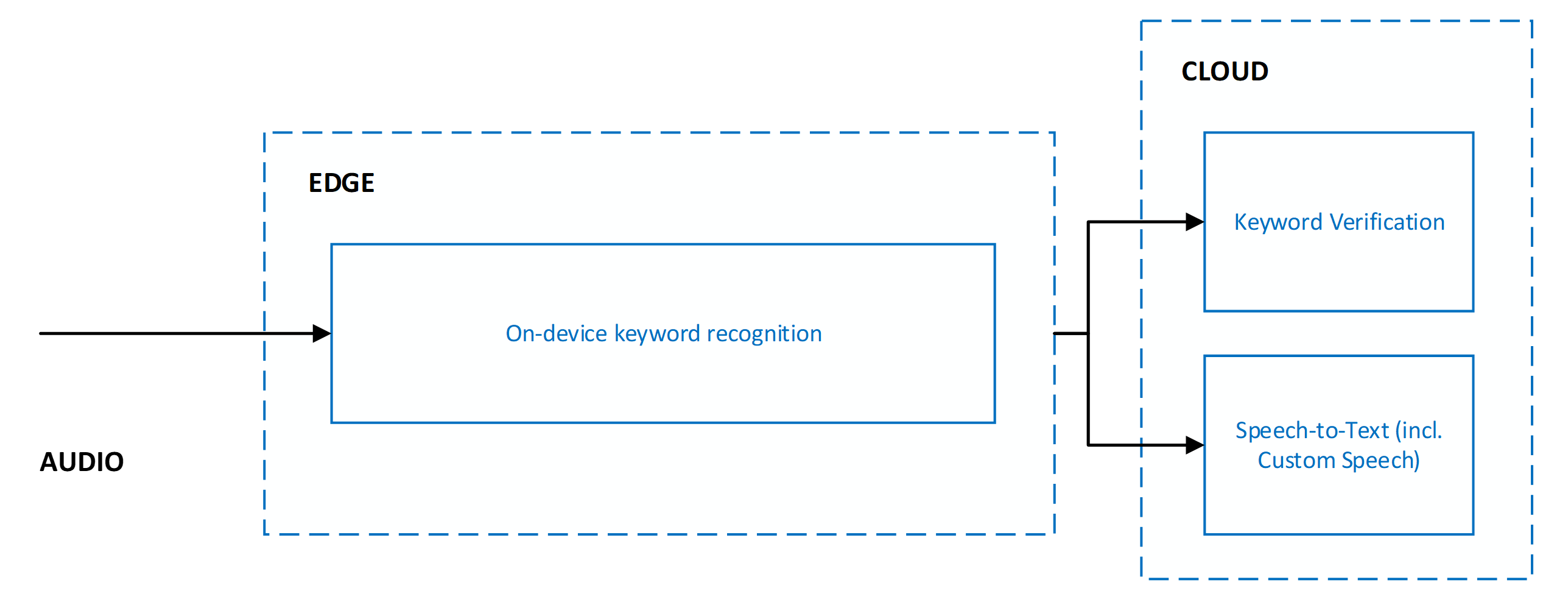
Executar a verificação de palavras-chave e a conversão de fala em texto em paralelo gera os seguintes benefícios:
- Nenhuma outra latência nos resultados da conversão de fala em texto: a execução paralela significa que a verificação de palavras-chave não adiciona latência. O cliente recebe resultados de conversão de fala em texto com a mesma rapidez. Se a verificação de palavras-chave determinar que a palavra-chave não estava presente no áudio, o processamento da conversão de fala em texto será encerrado. Esta ação protege contra o processamento desnecessário da conversão de fala em texto. O processamento de modelo de rede e nuvem aumenta a latência percebida pelo usuário da ativação de voz. Para obter mais informações, consulte Recomendações e diretrizes.
- Prefixo forçado de palavra-chave nos resultados de conversão de fala em texto: o processamento da conversão de fala em texto garante que os resultados enviados ao cliente sejam prefixados com a palavra-chave. Esse comportamento permite maior precisão nos resultados da conversão de fala em texto para a fala que segue a palavra-chave.
- Aumento do tempo limite de fala para texto : devido à presença esperada da palavra-chave no início do áudio, a conversão de fala em texto permite uma pausa mais longa de até cinco segundos após a palavra-chave antes de determinar o final da fala e encerrar o processamento de conversão de fala em texto. Esse comportamento garante que a experiência do usuário seja tratada corretamente para os comandos de preparo (<keyword><pause><command>) e os comandos encadeados (<keyword><command>).
Respostas da verificação de palavra-chave e considerações de latência
Para cada solicitação ao serviço, a verificação de palavra-chave retornará uma das duas respostas: aceito ou rejeitado. A latência do processamento varia dependendo do tamanho da palavra-chave e da duração do segmento de áudio que deve conter a palavra-chave. A latência do processamento não inclui o custo de rede entre o cliente e os serviços de Fala.
| Resposta da verificação de palavra-chave | Descrição |
|---|---|
| Aceito | Indica que o serviço acredita que a palavra-chave estava presente no fluxo de áudio fornecido na solicitação. |
| Rejeitado | Indica que o serviço acredita que a palavra-chave não estava presente no fluxo de áudio fornecido na solicitação. |
Os casos rejeitados geralmente produzem latências mais altas, pois o serviço processa mais áudio do que os casos aceitos. Por padrão, a verificação de palavra-chave processará, no máximo, dois segundos de áudio para procurar a palavra-chave. Se a palavra-chave não for encontrada em dois segundos, o serviço atingirá o tempo limite e sinalizará uma resposta de rejeição ao cliente.
Usar a verificação de palavra-chave com modelos no dispositivo do recurso palavra-chave personalizada
O SDK de Fala permite o uso contínuo de modelos no dispositivo gerados usando palavras-chave personalizadas com verificação de palavras-chave e conversão de fala em texto. Ele processa com transparência:
- A porta de áudio para a verificação de palavra-chave e o reconhecimento de fala com base no resultado de um modelo no dispositivo.
- A comunicação da palavra-chave para a verificação de palavra-chave.
- A comunicação de metadados adicionais para a nuvem a fim de orquestrar o cenário de ponta a ponta.
Você não precisa especificar explicitamente nenhum parâmetro de configuração. Todas as informações necessárias serão extraídas automaticamente do modelo no dispositivo gerado pelo recurso de palavra-chave personalizada.
O exemplo e os tutoriais vinculados aqui mostram como usar o SDK de Fala:
- Exemplos de assistente de voz no GitHub
- Tutorial: habilitar por voz seu assistente criado usando o Serviço de Bot de IA do Azure com o SDK de Fala do C#
Cenários e integração do SDK de Fala
O SDK de Fala permite o uso de modelos personalizados de reconhecimento de palavra-chave no dispositivo gerados com os recursos de palavra-chave personalizada e verificação de palavra-chave. Para garantir que as necessidades do produto sejam atendidas, o SDK dá suporte aos dois cenários a seguir:
| Cenário | Descrição | Exemplos |
|---|---|---|
| Reconhecimento de palavras-chave de ponta a ponta com a conversão de fala em texto | Mais adequado para produtos que usam um modelo de palavra-chave personalizado no dispositivo a partir de palavras-chave personalizadas com a verificação de palavras-chave e a conversão de fala em texto. Esse é o cenário mais comum. | |
| Reconhecimento de palavra-chave offline | Mais adequado para produtos sem conectividade de rede que usam um modelo de palavra-chave personalizado no dispositivo do recurso palavra-chave personalizada. |