O que é o repositório analítico do Azure Cosmos DB?
APLICA-SE AO: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Gremlin
Gremlin
Importante
O espelhamento no Microsoft Fabric agora está disponível em versão prévia para API NoSql. Esse recurso fornece todos os recursos do Link do Azure Synapse com melhor desempenho analítico, capacidade de unificar seu patrimônio de dados com o Fabric OneLake e acesso aberto aos seus dados no OneLake com formato Delta Parquet. Se estiver a considerar o Link do Azure Synapse, recomendamos que tente espelhar para avaliar a adequação geral à sua organização. Para começar a usar o espelhamento, clique aqui.
Para começar a usar o Link do Azure Synapse, visite “Introdução ao Link do Azure Synapse”
O repositório analítico do Azure Cosmos DB é um repositório de coluna totalmente isolado para habilitar a análise em grande escala de dados operacionais em seu Azure Cosmos DB, sem nenhum impacto as cargas de trabalho transacionais.
O repositório transacional do Azure Cosmos DB é independente de esquema e permite que você faça uma iteração nos seus aplicativos transacionais sem a necessidade de lidar com gerenciamento de índices ou de esquemas. De modo contrastante, o repositório analítico do Azure Cosmos DB é esquematizado para otimizar o desempenho de consultas analíticas. Este artigo descreve em detalhes o repositório analítico.
Desafios com análise em larga escala sobre dados operacionais
Os dados operacionais multimodelo em um contêiner do Azure Cosmos DB são armazenados internamente em um "repositório transacional" baseado em linha e indexado. O formato de repositório de linha foi projetado para permitir leituras e gravações transacionais rápidas nos tempos de resposta na casa de milissegundos e consultas operacionais. Se o conjunto de dados aumentar, as consultas analíticas complexas poderão ser caras em termos de taxa de transferência provisionada nos dados armazenados nesse formato. O alto consumo de taxa de transferência provisionada, por sua vez, impacta o desempenho de cargas de trabalho transacionais que são usadas pelos aplicativos e serviços em tempo real.
Tradicionalmente, para analisar grandes quantidades de dados, os dados operacionais são extraídos do repositório transacional do Azure Cosmos DB e armazenados em uma camada de dados separada. Por exemplo, os dados são armazenados em um data warehouse ou em um data lake em um formato adequado. Esses dados são usados posteriormente para a análise em larga escala e são analisados usando mecanismos de computação, como os clusters do Apache Spark. A separação analítica dos dados operacionais resulta em atrasos para os analistas que desejam usar os dados mais recentes.
Os pipelines de ETL também se tornam complexos ao lidar com atualizações dos dados operacionais quando comparados ao tratamento apenas de dados operacionais recentemente ingeridos.
Repositório analítico orientado por coluna
O repositório analítico do Azure Cosmos DB aborda os desafios de complexidade e latência que ocorrem com os pipelines de ETL tradicionais. O repositório analítico do Azure Cosmos DB pode sincronizar automaticamente seus dados operacionais em um repositório de coluna separado. O formato de repositório de coluna é adequado para consultas analíticas de larga escala a serem executadas de maneira otimizada, resultando na melhoria da latência dessas consultas.
Agora, ao usar o Link do Azure Synapse, você pode criar soluções de HTAP sem ETL ao vincular diretamente ao repositório analítico do Azure Cosmos DB a partir do Azure Synapse Analytics. Isso permite que você execute análises de larga escala quase em tempo real em seus dados operacionais.
Recursos de repositório analítico
Quando você habilitar o repositório analítico em um contêiner do Azure Cosmos DB, um novo repositório de coluna será criado internamente com base nos dados operacionais em seu contêiner. Esse repositório de colunas é mantido separadamente do repositório transacional orientado por linhas para esse contêiner, em uma conta de armazenamento totalmente gerenciada pelo Azure Cosmos DB, em uma assinatura interna. Os clientes não precisam gastar tempo com a administração do armazenamento. As inserções, atualizações e exclusões dos seus dados operacionais são sincronizadas automaticamente ao repositório analítico. Você não precisa do feed de alterações ou do ETL para sincronizar os dados.
Repositório de coluna para cargas de trabalho analíticas em dados operacionais
As cargas de trabalho analíticas normalmente envolvem agregações e exames sequenciais dos campos selecionados. O repositório de análise de dados é armazenado em uma ordem de colunas principais, permitindo que os valores de cada campo sejam serializados juntos, quando aplicável. Esse formato reduz as IOPS necessárias para verificar ou computar estatísticas em campos específicos. Ele melhora significativamente os tempos de resposta de consulta para verificações em grandes conjuntos de dados.
Por exemplo, se suas tabelas operacionais estiverem no seguinte formato:
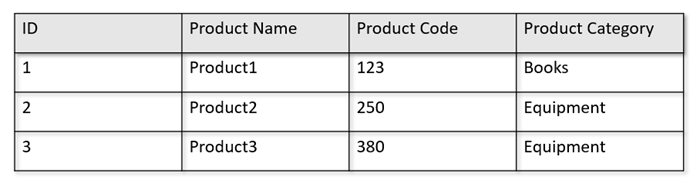
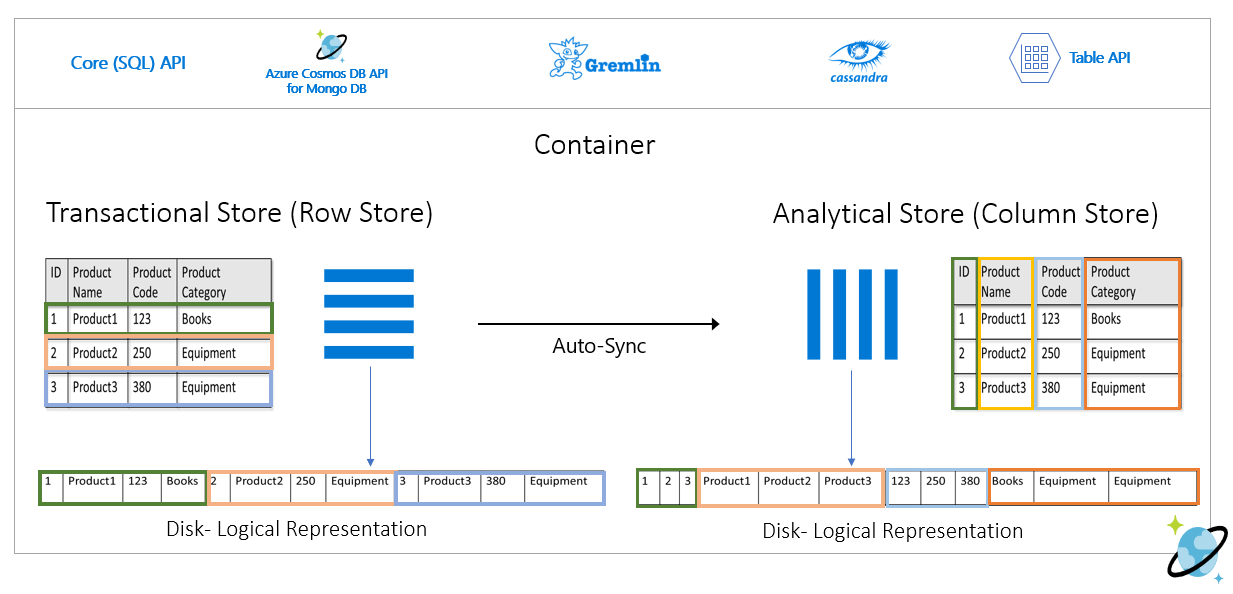
O repositório de linha persiste os dados acima em um formato serializado, por linha, no disco. Esse formato permite leituras, gravações e consultas operacionais transacionais mais rápidas, como “Retornar informações sobre Product 1”. No entanto, como o conjunto de dados aumenta e se você quiser executar consultas analíticas complexas sobre eles, isso pode se tornar caro. Por exemplo, se você quiser saber "as tendências de vendas de um produto sob a categoria chamada 'equipamentos' entre diferentes unidades de negócios e meses", você precisará executar uma consulta complexa. Grandes exames nesse conjunto de recursos podem ser caros em termos de taxa de transferência provisionada e também podem impactar o desempenho das cargas de trabalho transacionais, capacitando seus aplicativos e serviços em tempo real.
O repositório analítico, que é um repositório de coluna, é mais adequado para essas consultas porque ele serializa campos semelhantes de dados juntos e reduz as IOPS de disco.
A imagem a seguir mostra o repositório de linhas transacional em comparação ao repositório de colunas analíticas no Azure Cosmos DB:
Desempenho separado para cargas de trabalho analíticas
Não há nenhum impacto no desempenho das suas cargas de trabalho transacionais devido a consultas analíticas, pois o repositório analítico é separado do repositório transacional. O repositório analítico não precisa de RUs (unidades de solicitação) separadas para ser alocado.
Sincronização automática
A sincronização automática refere-se à capacidade totalmente gerenciada do Azure Cosmos DB em que as inserções, atualizações e exclusões em relação a dados operacionais são sincronizadas automaticamente do repositório transacional para o repositório analítico em tempo quase real. A latência de sincronização automática geralmente é de 2 minutos. Em casos de banco de dados de taxa de transferência compartilhado com um grande número de contêineres, a latência de sincronização automática de contêineres individuais pode ser maior e levar até 5 minutos.
No final de cada execução do processo de sincronização automática, seus dados transacionais estarão imediatamente disponíveis para os runtimes do Azure Synapse Analytics:
Os pools do Spark no Azure Synapse Analytics podem ler todos os dados, incluindo as atualizações mais recentes, por meio das tabelas do Spark, que são atualizadas automaticamente ou por meio do comando
spark.read, que sempre lê o último estado dos dados.Os pools Sem Servidor SQL no Azure Synapse Analytics podem ler todos os dados, incluindo as atualizações mais recentes, por meio das exibições, que são atualizadas automaticamente ou por meio do comando
SELECTjunto com o comandoOPENROWSET, que sempre leem o último estado dos dados.
Observação
Seus dados transacionais serão sincronizados com o armazenamento analítico mesmo que a TTL (vida útil) transacional seja menor que 2 minutos.
Observação
Observe que, se você excluir seu contêiner, o repositório analítico também será excluído.
Escalabilidade e elasticidade
O repositório transacional do Azure Cosmos DB usa o particionamento horizontal para escalar elasticamente o armazenamento e a taxa de transferência sem nenhum tempo de inatividade. O particionamento horizontal no repositório transacional fornece escalabilidade e elasticidade na sincronização automática para garantir que os dados sejam sincronizados com o repositório analítico quase em tempo real. A sincronização de dados ocorre independentemente da taxa de transferência do tráfego transacional, sejam mil ou 1 milhão de operações/s, e não impacta a taxa de transferência provisionada no repositório transacional.
Lidar automaticamente com atualizações de esquema
O repositório transacional do Azure Cosmos DB é independente de esquema e permite que você faça uma iteração nos seus aplicativos transacionais sem a necessidade de lidar com gerenciamento de índices ou de esquemas. De modo contrastante, o repositório analítico do Azure Cosmos DB é esquematizado para otimizar o desempenho de consultas analíticas. Com o recurso de sincronização automática, o Azure Cosmos DB gerencia a inferência de esquema sobre as atualizações mais recentes do repositório transacional. Ele também gerencia a representação do esquema no repositório analítico pronto para uso, que inclui o tratamento de tipos de dados aninhados.
Conforme seu esquema evolui e novas propriedades são adicionadas ao longo do tempo, o repositório analítico apresenta automaticamente um esquema unido entre todos os esquemas históricos no repositório transacional.
Observação
No contexto do armazenamento analítico, consideramos as seguintes estruturas como propriedade:
- Os "elements" do JSON ou o "string-value pairs separated by a
:". - Objetos JSON, delimitados por
{e}. - Matrizes JSON, delimitadas por
[e].
Restrições de esquema
As seguintes restrições são aplicáveis aos dados operacionais em Azure Cosmos DB quando você habilita o repositório analítico para inferir e representar automaticamente o esquema corretamente:
Você pode ter no máximo mil propriedades em todos os níveis aninhados no esquema do documento e uma profundidade de aninhamento máxima de 127.
- Somente as primeiras 1000 propriedades são representadas no repositório analítico.
- Somente os primeiros 127 níveis aninhados são representados no repositório analítico.
- O primeiro nível de um documento JSON é seu nível raiz
/. - As propriedades no primeiro nível do documento serão representadas como colunas.
Cenários de exemplo:
- Se o primeiro nível do documento tiver 2.000 propriedades, o processo de sincronização representará as primeiras 1000 delas.
- Se os documentos tiverem cinco níveis com 200 propriedades em cada um, o processo de sincronização representará todas as propriedades.
- Se os documentos tiverem dez níveis com 400 propriedades em cada um, o processo de sincronização representará totalmente os dois primeiros níveis e apenas metade do terceiro nível.
O documento hipotético abaixo contém quatro propriedades e três níveis.
- Os níveis são
root,myArray, e a estrutura aninhada dentro domyArray. - As propriedades são
id,myArray,myArray.nested1emyArray.nested2. - A representação do repositório analítico terá duas colunas:
idemyArray. Você pode usar funções do Spark ou do T-SQL para expor as estruturas aninhadas como colunas também.
- Os níveis são
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
Embora os documentos JSON (e coleções/contêineres do Azure Cosmos DB) diferenciem maiúsculas de minúsculas da perspectiva de exclusividade, o repositório analítico não faz isso.
- No mesmo documento: os nomes de propriedades no mesmo nível devem ser exclusivos quando comparados sem distinção entre maiúsculas e minúsculas. Por exemplo, o documento JSON a seguir tem "Name" e "name" no mesmo nível. Embora seja um documento JSON válido, ele não satisfaz a restrição de exclusividade e, portanto, não será totalmente representado no repositório analítico. Neste exemplo, "Name" e "name" são iguais quando comparados sem distinção de maiúsculas e minúsculas. Somente
"Name": "fred"será representado no repositório analítico, porque é a primeira ocorrência. E"name": "john"não será representado.
{"id": 1, "Name": "fred", "name": "john"}- Em documentos diferentes: as propriedades no mesmo nível e com o mesmo nome, mas em casos diferentes, serão representadas na mesma coluna, usando o formato de nome da primeira ocorrência. Por exemplo, os documentos JSON a seguir têm
"Name"e"name"no mesmo nível. Como o primeiro formato de documento é"Name", isso é o que será usado para representar o nome da propriedade no repositório analítico. Em outras palavras, o nome da coluna no repositório analítico será"Name". Ambos"fred"e"john"serão representados na coluna"Name".
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- No mesmo documento: os nomes de propriedades no mesmo nível devem ser exclusivos quando comparados sem distinção entre maiúsculas e minúsculas. Por exemplo, o documento JSON a seguir tem "Name" e "name" no mesmo nível. Embora seja um documento JSON válido, ele não satisfaz a restrição de exclusividade e, portanto, não será totalmente representado no repositório analítico. Neste exemplo, "Name" e "name" são iguais quando comparados sem distinção de maiúsculas e minúsculas. Somente
O primeiro documento da coleção define o esquema inicial do repositório analítico.
- Documentos com mais propriedades do que o esquema inicial gerarão novas colunas no repositório analítico.
- Não é possível remover colunas.
- A exclusão de todos os documentos em uma coleção não redefine o esquema de armazenamento analítico.
- Não há controle de versão do esquema. A última versão inferida do repositório transacional é o que você verá no repositório analítico.
Atualmente, o Azure Synapse Spark não pode ler propriedades que contêm alguns caracteres especiais em seus nomes, listados abaixo. O SQL do Azure Synapse sem servidor não é afetado.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Observação
Espaços em branco também são listados na mensagem de erro do Spark retornada quando você atinge essa limitação. No entanto, adicionamos um tratamento especial para espaços em branco. Confira mais detalhes nos itens abaixo.
- Se você tiver nomes de propriedades que usam os caracteres listados acima, as alternativas são as seguintes:
- Altere o modelo de dados com antecedência para evitar esses caracteres.
- Como não há suporte para redefinição de esquema no momento, você pode alterar o aplicativo para adicionar uma propriedade redundante com um nome semelhante, evitando esses caracteres.
- Use o Feed de Alterações para criar uma exibição materializada do contêiner, sem esses caracteres nos nomes de propriedades.
- Use opção
dropColumndo Spark para ignorar as colunas afetadas e carregar todas as outras colunas em um DataFrame. A sintaxe do é:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- O Spark do Azure Synapse agora dá suporte a propriedades cujos nomes contêm espaços em branco. Para isso, você precisa usar a opção
allowWhiteSpaceInFieldNamesdo Spark para carregar as colunas afetadas em um DataFrame, mantendo o nome original. A sintaxe do é:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
Os seguintes tipos de dados BSON não têm suporte e não serão representados no repositório analítico:
- Decimal128
- Expressão regular
- Ponteiro de BD
- JavaScript
- Símbolo
- MinKey/MaxKey
Ao usar cadeias de caracteres DateTime que seguem o padrão ISO 8601 UTC, espere o seguinte comportamento:
- Os pools do Spark no Azure Synapse representam essas colunas como
string. - Os pools sem servidor SQL no Azure Synapse representam essas colunas como
varchar(8000).
- Os pools do Spark no Azure Synapse representam essas colunas como
As propriedades com tipos
UNIQUEIDENTIFIER (guid)são representadas comostringno repositório analítico e devem ser convertidas emVARCHARno SQL oustringno Spark para uma visualização correta.Os pools sem servidor do SQL no Azure Synapse dão suporte a conjuntos de resultados com até mil colunas e a exposição de colunas aninhadas também conta com relação ao limite. É uma boa prática considerar essas informações em sua arquitetura e modelagem de dados transacionais.
Se você renomear uma propriedade, em um ou muitos documentos, ela será considerada uma nova coluna. Se você renomear da mesma maneira em todos os documentos da coleção, todos os dados serão migrados para a nova coluna e a coluna antiga será representada com valores
NULL.
Representação do esquema
Há dois métodos de representação de esquema no repositório analítico, válidos para todos os contêineres na conta de banco de dados. Eles têm compensações entre a simplicidade da experiência de consulta versus a conveniência de uma representação colunar mais inclusiva para esquemas polimórficos.
- Representação de esquema bem definida, opção padrão para contas da API para NoSQL e Gremlin.
- Representação de esquema de fidelidade total, opção padrão para contas da API para MongoDB.
Representação de esquema bem definido
A representação de esquema bem definido cria uma representação de tabela simples dos dados independentes de esquema no repositório transacional. A representação de esquema bem definida tem as seguintes considerações:
- O primeiro documento define o esquema base e a propriedade sempre precisa ter o mesmo tipo em todos os documentos. As únicas exceções são:
- De
NULLpara qualquer outro tipo de dados. A primeira ocorrência não nula define o tipo de dados da coluna. Qualquer documento que não esteja seguindo o primeiro tipo de dados não nulo não será representado no repositório analítico. - De
floatainteger. Todos os documentos são representados no repositório analítico. - De
integerafloat. Todos os documentos são representados no repositório analítico. No entanto, para ler esses dados com os pools sem servidor SQL do Azure Synapse, você deverá usar uma cláusula WITH para converter a coluna emvarchar. E, após essa conversão inicial, é possível convertê-la novamente em um número. Verifique o exemplo abaixo, em que o valor inicial num era um inteiro e o segundo era um float.
- De
SELECT CAST (num as float) as num
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = '<your-connection',
OBJECT = 'IntToFloat',
SERVER_CREDENTIAL = 'your-credential'
)
WITH (num varchar(100)) AS [IntToFloat]
As propriedades que não seguem o tipo de dados do esquema base não serão representadas no repositório analítico. Por exemplo, considere os documentos abaixo: o primeiro definiu o esquema base do repositório analítico. O segundo documento, em que
idé"2", não tem um esquema bem definido, pois a propriedade"code"é uma cadeia de caracteres e o primeiro documento tem"code"como um número. Nesse caso, o repositório analítico registra o tipo de dados de"code"comointegerno tempo de vida do contêiner. O segundo documento ainda será incluído no repositório analítico, mas a propriedade"code"não será.{"id": "1", "code":123}{"id": "2", "code": "123"}
Observação
A condição acima não se aplica a propriedades NULL. Por exemplo, {"a":123} and {"a":NULL} ainda é bem definido.
Observação
A condição acima não muda se você atualizar o "code" do documento "1" para uma cadeia de caracteres em seu repositório transacional. No repositório analítico, "code" será mantido como integer, já que atualmente não há suporte para redefinição de esquema.
- Tipos de matriz devem conter um só tipo repetido. Por exemplo,
{"a": ["str",12]}não é um esquema bem-definido porque a matriz contém uma combinação de tipos de inteiros e de cadeias de caracteres.
Observação
Se o repositório analítico do Azure Cosmos DB seguir a representação de esquema bem definida e a especificação acima for violada por determinados itens, esses itens não serão incluídos no repositório analítico.
Espere um comportamento diferente em tipos diferentes no esquema bem-definido:
- Os pools do Spark no Azure Synapse representam esses valores como
undefined. - Os pools sem servidor SQL no Azure Synapse representam esses valores como
NULL.
- Os pools do Spark no Azure Synapse representam esses valores como
Espere um comportamento diferente em relação aos
NULLvalores explícitos:- Os pools do Spark no Azure Synapse lêem esses valores como
0(zero) eundefinedassim que a coluna tiver um valor não nulo. - Os pools sem servidor SQL no Azure Synapse lêem esses valores como
NULL.
- Os pools do Spark no Azure Synapse lêem esses valores como
Espere um comportamento diferente em relação às colunas ausentes:
- Os pools do Spark no Azure Synapse representam essas colunas como
undefined. - Os pools sem servidor SQL no Azure Synapse representam essas colunas como
NULL.
- Os pools do Spark no Azure Synapse representam essas colunas como
Soluções alternativas para os desafios de declaração
É possível que um documento antigo, com um esquema incorreto, tenha sido usado para criar o esquema base do repositório analítico do contêiner. Com base em todas as regras apresentadas acima, você pode estar recebendo NULL de determinadas propriedades ao consultar seu repositório analítico usando o Link do Azure Synapse. Excluir ou atualizar os documentos problemáticos não ajuda porque atualmente não há suporte para a redefinição de esquema base. Entre as soluções possíveis estão:
- Migrar os dados para um novo contêiner, verificando se todos os documentos têm o esquema correto.
- Para abandonar a propriedade com o esquema errado e adicionar uma nova com outro nome que tenha o esquema correto em todos os documentos. Exemplo: você tem bilhões de documentos no contêiner Pedidos em que a propriedade status é uma cadeia de caracteres. Mas o primeiro documento nesse contêiner tem o status definido com inteiro. Portanto, um documento terá o status representado corretamente e todos os outros documentos terão
NULL. Você pode adicionar a propriedade status2 a todos os documentos e começar a usá-la, em vez da propriedade original.
Representação de esquema com fidelidade total
A representação de esquema de fidelidade total foi projetada para lidar com toda a amplitude de esquemas polimórficos nos dados operacionais independentes de esquema. Nessa representação de esquema, nenhum item é removido do repositório analítico, mesmo que as restrições de esquema bem-definido (que não sejam campos de tipo de dados mistos nem matrizes de tipos de dados mistos) sejam violadas.
Isso é obtido traduzindo as propriedades folha dos dados operacionais para o repositório analítico como pares JSON key-value , em que o tipo de dados é o key e o conteúdo da propriedade é o value. Essa representação de objeto JSON permite consultas sem ambiguidade e você pode analisar individualmente cada tipo de dados.
Em outras palavras, na representação de esquema de fidelidade total, cada tipo de dados de cada propriedade de cada documento gerará um key-valuepar em um objeto JSON para essa propriedade. Cada uma delas conta como uma das 1000 propriedades máximas.
Por exemplo, vamos pegar o seguinte documento de exemplo no repositório transacional:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
O objeto address aninhado é uma propriedade no nível raiz do documento e será representado como uma coluna. Cada propriedade folha no objeto address será representada como um objeto JSON: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
Ao contrário da representação de esquema bem definida, o método de fidelidade total permite variação em tipos de dados. Se o próximo documento nesta coleção do exemplo acima tiver streetNo como uma cadeia de caracteres, ele será representado no repositório analítico como "streetNo":{"string":15850}. No método de esquema bem definido, ele não seria representado.
Mapa de tipos de dados para esquema de fidelidade total
Aqui está um mapa dos tipos de dados do MongoDB e suas representações no armazenamento analítico em uma representação de esquema de fidelidade total. O mapa abaixo não é válido para as contas da API NoSQL.
| Tipo de dados original | Sufixo | Exemplo |
|---|---|---|
| Double | ".float64" | 24.99 |
| Array | ".array" | ["a", "b"] |
| Binário | ".binary" | 0 |
| Boolean | ".bool" | True |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULO | ".NULL" | NULO |
| String | ".string" | "ABC" |
| Timestamp | ".timestamp" | Timestamp(0, 0) |
| ObjectId | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Documento | ".object" | {"a": "a"} |
Espere um comportamento diferente em relação aos
NULLvalores explícitos:- Os pools do Spark no Azure Synapse lerá esses valores como
0(zero). - Os pools sem servidor SQL no Azure Synapse lerão esses valores como
NULL.
- Os pools do Spark no Azure Synapse lerá esses valores como
Espere um comportamento diferente em relação às colunas ausentes:
- Os pools do Spark no Azure Synapse representarão essas colunas como
undefined. - Os pools sem servidor SQL no Azure Synapse representarão essas colunas como
NULL.
- Os pools do Spark no Azure Synapse representarão essas colunas como
Espere um comportamento diferente com relação aos valores
timestamp:- Os pools do Spark no Azure Synapse farão a leitura desses valores como
TimestampType,DateTypeouFloat. Isso depende do intervalo e de como o carimbo de data/hora foi gerado. - Os pools SQL Sem servidor no Azure Synapse lerão esses valores como
DATETIME2, variando de0001-01-01a9999-12-31. Valores além desse intervalo não são suportados e causarão falha na execução de suas consultas. Se este é o seu caso, você pode:- Remova a coluna da consulta. Para manter a representação, você pode criar uma nova propriedade espelhando essa coluna, mas dentro do intervalo suportado. E use-o em suas consultas.
- Use Altere a Captura de dados do armazenamento analítico, sem custo de RUs, para transformar e carregar os dados em um novo formato, dentro de um dos coletores suportados.
- Os pools do Spark no Azure Synapse farão a leitura desses valores como
Usar o esquema de fidelidade total com o Spark
O Spark gerenciará cada tipo de dados como uma coluna ao carregar em um DataFrame. Vamos supor uma coleção com os documentos abaixo.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
Embora o primeiro documento tenha rating como número e timestamp no formato utc, o segundo documento tem rating e timestamp como cadeias de caracteres. Supondo que essa coleção tenha sido carregada DataFrame sem nenhuma transformação de dados, a saída do df.printSchema() é:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
Na representação de esquema bem definida, tanto rating quanto timestamp do segundo documento não seriam representados. Em esquema de fidelidade total, você pode usar os exemplos a seguir para acessar individualmente cada valor de cada tipo de dados.
No exemplo abaixo, podemos usar PySpark para executar uma agregação:
df.groupBy(df.item.string).sum().show()
No exemplo abaixo, podemos usar PySQL para executar outra agregação:
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
Usar o esquema de fidelidade total com o SQL
Use o seguinte exemplo de sintaxe com os mesmos documentos do exemplo do Spark acima:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
Você pode implementar transformações usando cast, convert ou qualquer outra função T-SQL para manipular seus dados. Você também pode ocultar estruturas de tipo de dados complexas usando exibições.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
Como trabalhar com o campo _id do MongoDB
O campo _id do MongoDB é fundamental para toda coleção no MongoDB e originalmente tem uma representação hexadecimal. Como você pode ver na tabela acima, o esquema de fidelidade total preservará as próprias características, criando um desafio para a própria visualização no Azure Synapse Analytics. Para uma visualização correta, você precisa converter o tipo de dados _id como mostrado abaixo:
Como trabalhar com o campo _id do MongoDB no Spark
O exemplo abaixo funciona nas versões 2.x e 3.x do Spark:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
Como trabalhar com o campo _id do MongoDB no SQL
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET('CosmosDB',
'Your-account;Database=your-database;Key=your-key',
HTAP) WITH (_id VARCHAR(1000)) as HTAP
Como trabalhar com o campo id do MongoDB
A propriedade id nos contêineres MongoDB é substituída automaticamente pela representação Base64 da propriedade "_id" no repositório analítico. O campo "id" destina-se ao uso interno por aplicativos MongoDB. Atualmente, a única solução alternativa é renomear a propriedade "id" para algo diferente de "id".
Esquema de fidelidade total para contas da API para NoSQL ou Gremlin
É possível usar o esquema de fidelidade total para contas da API para NoSQL, em vez da opção padrão, definindo o tipo de esquema ao habilitar o Link do Synapse em uma conta do Azure Cosmos DB pela primeira vez. Estas são as considerações sobre como alterar o tipo de representação do esquema padrão:
- Atualmente, se você habilitar o Link do Synapse na conta da API de NoSQL usando o portal do Azure, ela será habilitada como um esquema bem definido.
- Atualmente, para usar o esquema de fidelidade total com contas da API do Gremlin ou do NoSQL, é necessário defini-lo no nível da conta no mesmo comando da CLI ou do PowerShell que habilitará o Link do Synapse no nível da conta.
- Atualmente, o Azure Cosmos DB for MongoDB não é compatível com essa possibilidade de alterar a representação do esquema. Todas as contas do MongoDB têm o tipo de representação de esquema de fidelidade total.
- O mapa de tipos de dados do esquema de Fidelidade Total mencionado acima não é válido para contas da API do NoSQL que usam tipos de dados JSON. Por exemplo, os valores
floateintegersão representados comonumno armazenamento analítico. - Não é possível redefinir o tipo de representação do esquema de bem definido para a fidelidade completa ou vice-versa.
- Atualmente, o esquema de contêineres no repositório analítico é definido quando o contêiner é criado, mesmo que o Link do Synapse não tenha sido habilitado na conta do banco de dados.
- Os contêineres ou grafos criados antes da habilitação do Link do Synapse com o esquema de fidelidade total no nível da conta terão um esquema bem definido.
- Os contêineres ou grafos criados após a habilitação do Link do Synapse com o esquema de fidelidade total no nível da conta terão um esquema de fidelidade total.
A decisão do tipo de representação do esquema deve ser feita ao mesmo tempo em que o Link do Synapse é habilitado na conta, usando a CLI do Azure ou o PowerShell.
Com a CLI do Azure:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Observação
No comando acima, substitua create por update para as contas existentes.
Com o PowerShell:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Observação
No comando acima, substitua New-AzCosmosDBAccount por Update-AzCosmosDBAccount para as contas existentes.
TTL (vida útil) analítica
A ATTL (TTL analítica) indica por quanto tempo os dados devem ser retidos no seu repositório analítico para um contêiner.
O repositório analítico é habilitado quando a ATTL é definida com um valor diferente de NULL e 0. Quando habilitado, as inserções, atualizações, exclusões de dados operacionais são sincronizadas automaticamente do repositório transacional para o repositório analítico, independentemente da configuração de TTTL (TTL transacional). A retenção desses dados transacionais no repositório analítico pode ser controlada no nível do contêiner pela propriedade AnalyticalStoreTimeToLiveInSeconds.
As configurações possíveis de ATTL são:
Se o valor for definido como
0ouNULL: o repositório analítico será desabilitado e nenhum dado será replicado do repositório transacional para o repositório analíticoSe o valor for definido como
-1: o repositório analítico manterá todos os dados históricos, independentemente da retenção dos dados no repositório transacional. Essa configuração indica que o repositório analítico tem retenção infinita dos seus dados operacionaisSe o valor é definido como qualquer número inteiro positivo
n: os itens expiram no repositório analíticonsegundos após a hora da última modificação no repositório transacional. Essa configuração poderá ser usada se você quiser manter seus dados operacionais por um período de tempo limitado no repositório analítico, independentemente da retenção dos dados no repositório transacional.
Considere o seguinte:
- Depois que o repositório analítico for habilitado com um valor de ATTL, ele poderá ser atualizado posteriormente com um valor válido diferente.
- Embora a TTTL possa ser definida no nível de contêiner ou de item, atualmente, a ATTL só pode ser definida no nível de contêiner.
- Você pode obter uma retenção mais longa dos seus dados operacionais no repositório analítico definindo ATTL >= TTTL no nível de contêiner.
- O repositório analítico pode ser configurado para espelhar o repositório transacional definindo ATTL = TTTL.
- Se você tiver uma ATTL maior que a TTTL, em algum momento você terá dados que só existem no repositório analítico. Todos os dados são somente leitura.
- Atualmente, não excluímos nenhum dado do repositório analítico. Se você definir a ATTL como qualquer inteiro positivo, os dados não serão incluídos em suas consultas e você não será cobrado por ele. Mas se você alterar a ATTL de volta para
-1, todos os dados serão exibidos novamente, você começará a ser cobrado por todo o volume de dados.
Como habilitar o repositório analítico em um contêiner:
No portal do Azure, quando a opção ATTL está ativada, ela é definida com o valor padrão de -1. Você pode alterar esse valor para “n” segundos, navegando para configurações de contêiner em Data Explorer.
No SDK de Gerenciamento do Azure, nos SDKs do Azure Cosmos DB, no PowerShell ou na CLI do Azure, a opção de ATTL pode ser habilitada ao defini-la como -1 ou ' n' segundos.
Para saber mais, confira Como configurar a TTL analítica em um contêiner.
Análise econômica em dados históricos
Uma camada de dados se refere à separação de dados entre as infraestruturas de armazenamento otimizadas para cenários diferentes. Dessa forma, melhora o desempenho geral e a economia da pilha de dados de ponta a ponta. Com o repositório analítico, agora o Azure Cosmos DB tem suporte para camadas automáticas de dados do repositório transacional para o repositório analítico com diferentes layouts de dados. Com o repositório analítico otimizado em termos de custo de armazenamento em comparação ao repositório transacional, você pode reter horizontes muito maiores de dados operacionais para análise histórica.
Depois que o repositório analítico estiver habilitado e com base nas necessidades de retenção de dados das cargas de trabalho transacionais, você poderá configurar a propriedade transactional TTL para que os registros sejam excluídos automaticamente do repositório transacional após um determinado período. De modo semelhante, a analytical TTL permite que você gerencie o ciclo de vida dos dados retidos no repositório analítico independentemente do repositório transacional. Ao habilitar o repositório analítico e configurar as propriedades TTL transacionais e analíticas, você pode criar camadas e definir o período de retenção de dados para os dois repositórios perfeitamente.
Observação
Quando analytical TTL for definido como um valor maior que o valor transactional TTL, o contêiner terá dados que existem apenas no repositório analítico. Esses dados são somente leitura e atualmente não oferecemos suporte no nível TTL do documento no repositório analítico. Se os dados do contêiner precisarem de uma atualização ou uma exclusão em algum momento no futuro, não use analytical TTL maior que transactional TTL. Essa capacidade é recomendada para dados que não precisarão de atualizações ou exclusões no futuro.
Observação
Se o cenário não exigir exclusões físicas, você poderá adotar uma abordagem lógica de exclusão/atualização. Insira no repositório transacional outra versão do mesmo documento que só existe no repositório analítico, mas precisa de uma exclusão/atualização lógica. Talvez com um sinalizador indicando que é uma exclusão ou uma atualização de um documento expirado. Ambas as versões do mesmo documento coexistirão no repositório analítico e seu aplicativo deve considerar apenas a última.
Resiliência
O repositório analítico depende do Armazenamento do Microsoft Azure e oferece a seguinte proteção contra falhas físicas:
- Por padrão, as contas de banco de dados do Azure Cosmos DB alocam o repositório analítico nas contas de LRS (Armazenamento com Redundância Local). O armazenamento com redundância local (LRS) fornece pelo menos 99,999999999% (11 noves) de durabilidade dos objetos em um determinado ano.
- Se qualquer região geográfica da conta do banco de dados estiver configurada para redundância de zona, ela será alocada em contas ZRS (armazenamento com redundância de zona). Você precisa habilitar zonas de disponibilidade em uma região da conta de banco de dados do Azure Cosmos DB para ter dados analíticos dessa região armazenados no armazenamento com redundância de zona. O ZRS oferece durabilidade para recursos de armazenamento de, pelo menos, 99,9999999999% (doze noves) ao ano.
Para obter mais informações sobre a durabilidade do Armazenamento do Azure, confira este link.
Backup
Embora o repositório analítico tenha proteção interna contra falhas físicas, o backup pode ser necessário para exclusões ou atualizações acidentais no repositório transacional. Nesses casos, você pode restaurar um contêiner e usar o contêiner restaurado para provisionar os dados no contêiner original ou recompilar totalmente o repositório analítico, se necessário.
Observação
No momento, o backup do repositório analítico não é feito. Portanto, não é possível restaurá-lo. A política de backup não pode ser planejada com base nisso.
O Link do Synapse, e o repositório analítico, por consequência, tem diferentes níveis de compatibilidade com os modos de backup do Azure Cosmos DB:
- O modo de backup periódico é totalmente compatível com o Link do Synapse e esses dois recursos podem ser usados na mesma conta de banco de dados.
- O Link do Synapse para contas de banco de dados usando o modo de backup contínuo está em disponibilidade geral.
- O modo de backup contínuo para contas habilitadas para Link do Synapse está em versão prévia pública. Atualmente, você não poderá migrar para o backup contínuo se desabilitar o Link do Synapse em qualquer uma de suas coleções de uma conta do Cosmos DB.
Políticas de backup
Existem duas políticas de backup possíveis e, para entender como utilizá-las, os seguintes detalhes sobre os backups do Azure Cosmos DB são muito importantes:
- O contêiner original é restaurado sem o repositório analítico em ambos modos de backup.
- O Azure Cosmos DB não dá suporte à substituição de contêineres de uma restauração.
Agora veremos como usar o backup e as restaurações da perspectiva do repositório analítico.
Restaurando um contêiner com TTTL >= ATTL
Quando transactional TTL for igual a ou maior que analytical TTL, todos os dados no repositório analítico ainda existem no repositório transacional. No caso de uma restauração, duas situações são possíveis:
- Usar o contêiner restaurado como uma substituição para o contêiner original. Para recompilar o repositório analítico, habilite o Link do Synapse no nível da conta e no nível do contêiner.
- Usar o contêiner restaurado como uma fonte de dados para provisionamento ou atualizar os dados no contêiner original. Nesse caso, o repositório analítico refletirá automaticamente as operações de dados.
Restaurando um contêiner com TTTL <= ATTL
Quando transactional TTL for menor que analytical TTL, alguns dados só existem no repositório analítico e não estarão no contêiner restaurado. Novamente, duas situações são possíveis:
- Usar o contêiner restaurado como uma substituição para o contêiner original. Nesse caso, ao habilitar o Link do Synapse no nível do contêiner, somente os dados que estavam no repositório transacional serão incluídos no novo repositório analítico. Mas observe que o repositório analítico do contêiner original permanece disponível para consultas durante a existência do contêiner original. Talvez você queira alterar seu aplicativo para consultar ambos.
- Usar o contêiner restaurado como uma fonte de dados para provisionamento ou atualizar os dados no contêiner original:
- O repositório analítico refletirá automaticamente as operações de dados dos dados que estão no repositório transacional.
- Se você inserir novamente os dados removidos anteriormente do repositório transacional devido a
transactional TTL, esses dados serão duplicados no repositório analítico.
Exemplo:
- O contêiner
OnlineOrderstem TTTL definida como um mês e ATTL definida como um ano. - Ao restaurá-lo para
OnlineOrdersNewe ativar o repositório analítico para recompilá-lo, haverá apenas um mês de dados no repositório transacional e analítico. - O contêiner
OnlineOrdersoriginal não é excluído e o repositório analítico ainda está disponível. - Novos dados são ingeridos somente em
OnlineOrdersNew. - As consultas analíticas realizam UNION ALL dos repositórios analíticos enquanto os dados originais ainda são relevantes.
Se você quiser excluir o contêiner original, mas não quiser perder os dados do repositório analítico, poderá persistir o repositório analítico do contêiner original em outro serviço de dados do Azure. O Synapse Analytics tem a capacidade de realizar o ingresso de dados armazenados em localizações diferentes. Por exemplo: uma consulta do Synapse Analytics ingressa os dados de repositório analítico com tabelas externas localizadas no Armazenamento de Blobs do Azure, no Azure Data Lake Storage etc.
É importante observar que os dados no repositório analítico têm um esquema diferente do que aquele existente no repositório transacional. Embora você possa gerar instantâneos dos seus dados de repositório analítico e exportá-los para qualquer serviço de dados do Azure, sem nenhum custo de RUs, não podemos garantir o uso desse instantâneo para alimentar o repositório transacional. Esse processo não tem suporte.
Distribuição global
Se você tiver uma conta do Azure Cosmos DB distribuída globalmente, depois de habilitar o repositório analítico para um contêiner, ele ficará disponível em todas as regiões dessa conta. Quaisquer alterações nos dados operacionais são replicadas globalmente em todas as regiões. Você pode executar consultas analíticas efetivamente na cópia regional mais próxima dos seus dados no Azure Cosmos DB.
Particionamento
O particionamento do armazenamento analítico é completamente independente do particionamento no armazenamento transacional. Por padrão, os dados no repositório analítico não são particionados. Se suas consultas analíticas têm filtros usados com frequência, você tem a opção de particionar com base nesses campos para melhorar o desempenho da consulta. Para saber mais, confira Introdução ao particionamento personalizado e Como configurar o particionamento personalizado.
Segurança
A autenticação com o repositório analítico é igual a de um repositório transacional para um determinado banco de dados. Você pode usar chaves primárias, secundárias ou somente leitura para a autenticação. Você pode usar o serviço vinculado no Synapse Studio para evitar colar as chaves do Azure Cosmos DB nos notebooks do Spark. No SQL do Azure Synapse sem servidor, você pode usar as credenciais de SQL para também evitar colar as chaves do Azure Cosmos DB nos notebooks SQL. O acesso a estes Serviços Vinculados ou a estas credenciais está disponível para qualquer pessoa que tenha acesso ao workspace. Observe que a tecla somente leitura do Azure Cosmos DB também pode ser usada.
Isolamento de rede usando pontos de extremidade privados: você pode controlar o acesso à rede para os dados nos armazenamentos transacionais e analíticos de forma independente. O isolamento de rede é feito usando pontos de extremidade privados gerenciados separados para cada armazenamento, em redes virtuais gerenciadas nos espaços de trabalho do Azure Synapse. Para saber mais, consulte o artigo sobre como Configurar pontos de extremidade privados para o armazenamento analítico.
Criptografia de dados em repouso – a criptografia do repositório analítico está habilitada por padrão.
Criptografia de dados com chaves gerenciadas pelo cliente: você pode criptografar diretamente os dados entre os armazenamentos transacional e analítico usando as mesmas chaves gerenciadas pelo cliente de maneira automática e transparente. O Link do Azure Synapse só dá suporte à configuração de chaves gerenciadas pelo cliente usando a identidade gerenciada da sua conta do Azure Cosmos DB. Você deve configurar a identidade gerenciada da sua conta em sua política de acesso do Azure Key Vault antes de habilitar o Link do Azure Synapse em sua conta. Para saber mais, confira o artigo Configurar chaves gerenciadas pelo cliente com identidades gerenciadas de contas do Azure Cosmos DB.
Observação
Se você alterar sua conta de banco de dados Original para Sistema ou Identidade Atribuída pelo Usuário e habilitar o Link do Azure Synapse na sua conta de banco de dados, você não poderá retornar à identidade Original, pois não poderá desabilitar o Link do Synapse na sua conta de banco de dados.
Suporte para vários runtimes do Azure Synapse Analytics
O repositório analítico é otimizado para fornecer escalabilidade, elasticidade e desempenho para cargas de trabalho analíticas sem qualquer dependência dos tempos de execução de computação. A tecnologia de armazenamento é autogerenciada para otimizar suas cargas de trabalho de análise se esforços manuais.
Os dados do repositório analítico do Azure Cosmos DB podem ser consultados simultaneamente nos diferentes runtimes de análise com suporte no Azure Synapse Analytics. O Azure Synapse Analytics dá suporte ao Apache Spark e ao pool de SQL sem servidor com o repositório analítico do Azure Cosmos DB.
Observação
Você só pode ler o repositório analítico usando os runtimes do Azure Synapse Analytics. E o oposto também é verdadeiro, os runtimes do Azure Synapse Analytics só podem ler do repositório analítico. Somente o processo de sincronização automática pode alterar os dados no repositório analítico. Você pode gravar dados de volta no armazenamento transacional do Azure Cosmos DB usando o pool do Spark no Azure Synapse Analytics, usando o SDK Azure Cosmos DB OLTP interno.
Preços
O repositório analítico segue um modelo de preço baseado em consumo no qual você é cobrado por:
Armazenamento: o volume dos dados retidos no repositório analítico todos os meses, incluindo os dados históricos, conforme definido pela TTL analítica.
Operações de gravação analítica: a sincronização totalmente gerenciada de atualizações de dados operacionais para o repositório analítico a partir do repositório transacional (sincronização automática).
Operações de leitura analítica: as operações de leitura executadas no repositório analítico do pool do Azure Synapse Analytics Spark e os tempos de execução do pool SQL sem servidor.
O preço do repositório analítico é separado do modelo de preços do repositório transacional. Não há nenhum conceito de RUs provisionadas no repositório analítico. Confira a página de preços do Azure Cosmos DB para obter detalhes completos sobre o modelo de preços do repositório analítico.
Os dados no repositório de análise só podem ser acessados por meio do Link do Azure Synapse, o que é realizado nos runtimes do Azure Synapse Analytics: pools do Apache Spark do Azure Synapse e pools de SQL sem servidor do Azure Synapse. Confira a página de preços do Azure Synapse Analytics para obter detalhes completos sobre o modelo de preços para acessar dados no repositório analítico.
Para obter uma estimativa geral do custo para habilitar o armazenamento analítico em um contêiner do Azure Cosmos DB, da perspectiva do repositório analítico, você pode usar o Planejador de capacidade do Azure Cosmos DB e obter uma estimativa do armazenamento analítico e dos custos das operações de gravação.
As estimativas de operações de leitura do repositório analítico não estão incluídas na calculadora de custos do Azure Cosmos DB, pois são uma função da sua carga de trabalho analítica. Mas como uma estimativa de alto nível, o exame de 1 TB de dados no repositório analítico geralmente resulta em 130.000 operações de leitura analítica e em um custo de US$ 0,065. Por exemplo, se você usar Azure Synapse pools de SQL sem servidor para executar essa verificação de 1 TB, ela custará US$ 5,00 de acordo com a Página de preços do Azure Synapse Analytics. O custo total final para este exame de 1 TB seria de US$ 5,065.
Embora a estimativa acima seja para a verificação de 1 TB de dados no repositório analítico, a aplicação de filtros reduz o volume de dados verificados e determina o número exato de operações de leituras analíticas dado o modelo de preços de consumo. Uma prova de conceito em relação à carga de trabalho analítica forneceria uma estimativa mais refinada das operações de leitura analítica. Essa estimativa não inclui o custo do Azure Synapse Analytics.
Próximas etapas
Para saber mais, consulte a seguinte documentação:
Confira o módulo de treinamento sobre como Projetar o processamento transacional e analítico híbrido usando o Azure Synapse Analytics
Perguntas frequentes sobre o Link do Synapse para Azure Cosmos DB
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de