Migrar dados do Cassandra para uma conta do Azure Cosmos DB for Apache Cassandra usando o Azure Databricks
APLICA-SE A: ![]() Cassandra
Cassandra
A API do Cassandra no Azure Cosmos DB se tornou uma ótima opção para cargas de trabalho corporativas em execução no Apache Cassandra por vários motivos:
Nenhuma sobrecarga de gerenciamento e monitoramento: elimina a sobrecarga de gerenciar e monitorar configurações em arquivos de SO, JVM e YAML e suas interações.
Economia de custos significativa: é possível economizar custos com o Azure Cosmos DB, incluindo os custos de VMs, largura de banda e todas as licenças aplicáveis. Você não precisa gerenciar os custos de data centers, servidores, armazenamento de SSD, rede e eletricidade.
Capacidade de usar o código e as ferramentas existentes: o Azure Cosmos DB oferece compatibilidade no nível de protocolo com as ferramentas e os SDKs existentes do Cassandra. Essa compatibilidade garante que seja possível usar a base de código existente com o Azure Cosmos DB for Apache Cassandra mediante alterações básicas.
Há muitas formas de migrar cargas de trabalho de banco de dados de uma plataforma para outra. Azure Databricks é uma oferta de plataforma como serviço (PaaS) para o Apache Spark que oferece um modo de realizar migrações offline em grande escala. Este artigo descreve as etapas necessárias para migrar dados de keyspaces e tabelas nativos do Apache Cassandra para o Azure Cosmos DB for Apache Cassandra usando o Azure Databricks.
Pré-requisitos
Provisionar uma conta do Azure Cosmos DB for Apache Cassandra.
Examinar os conceitos básicos da conexão com um Azure Cosmos DB for Apache Cassandra.
Examinar os recursos com suporte no Azure Cosmos DB for Apache Cassandra para garantir a compatibilidade.
Garantir que tabelas e keyspaces vazios já tenham sido criados na conta do Azure Cosmos DB for Apache Cassandra de destino.
Provisionar um cluster do Azure Databricks
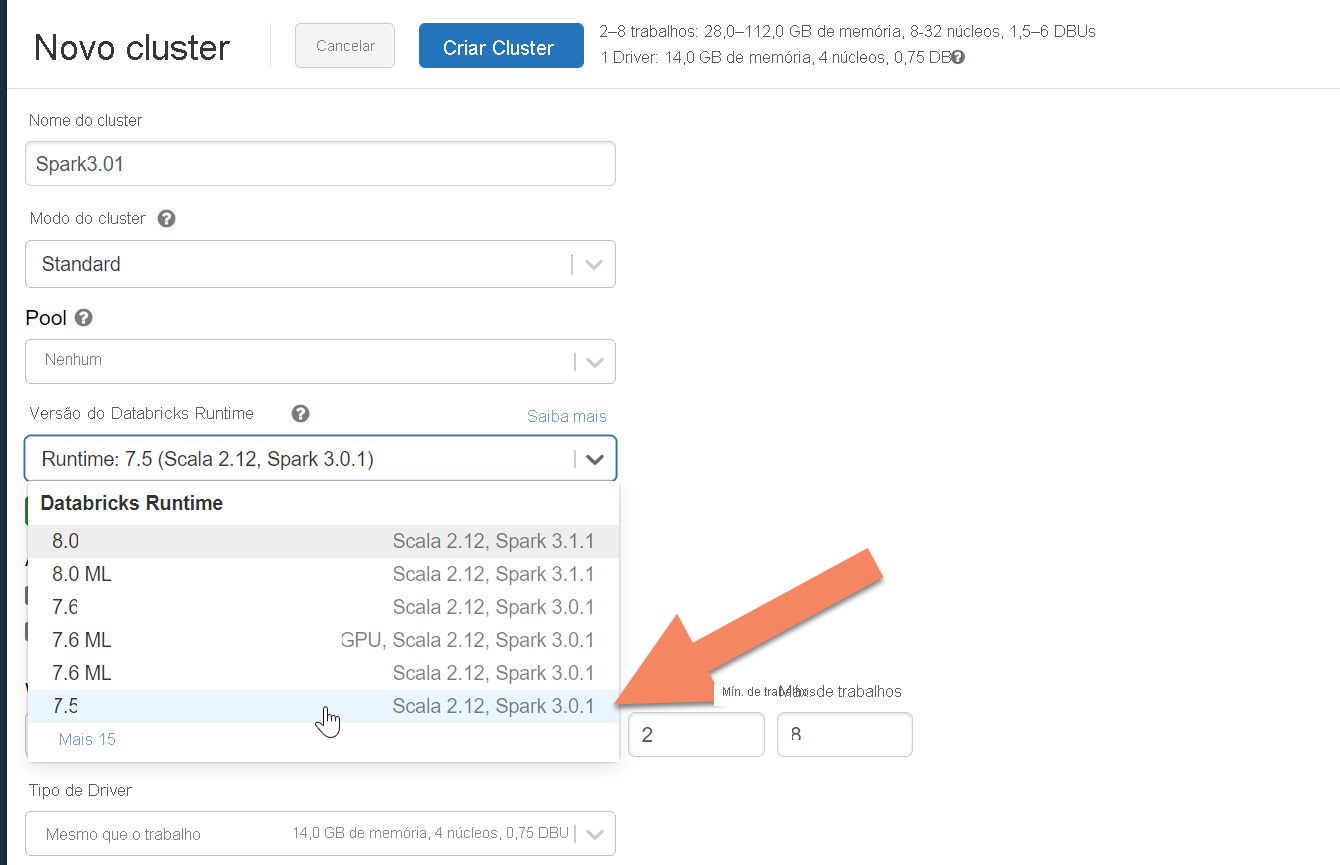
Você pode seguir as instruções para provisionar um cluster Azure Databricks. Recomendamos a seleção do Databricks runtime versão 7.5, que oferece suporte ao Spark 3.0.
Adicionar dependências
Você precisa adicionar a biblioteca do Conector do Apache Spark Cassandra ao cluster para se conectar aos pontos de extremidade nativos e do Cassandra do Azure Cosmos DB. No cluster, selecione Bibliotecas>Instalar novo>Maven e, em seguida, adicione com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 nas coordenadas do Maven.
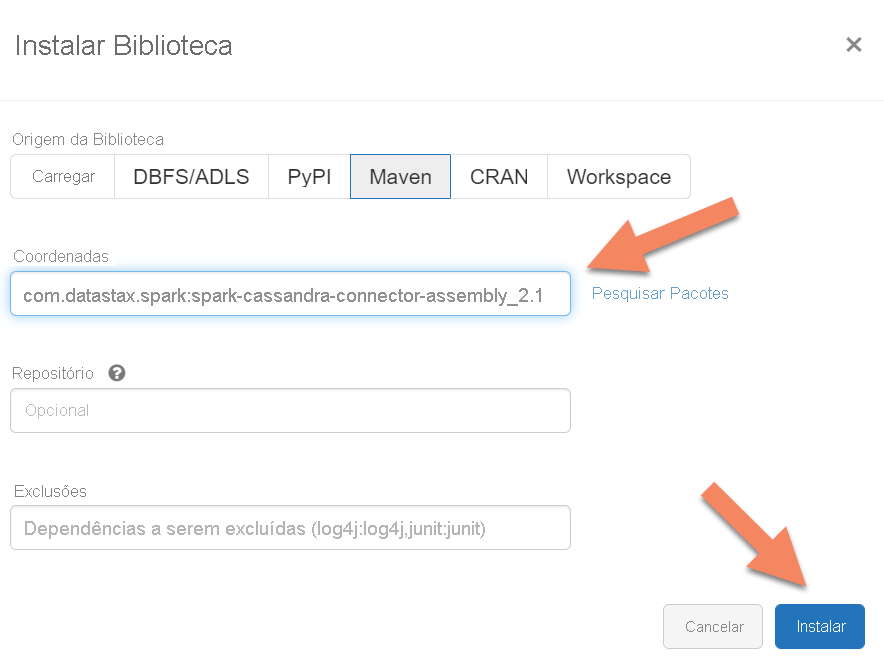
Selecione Instalar e reinicie o cluster quando a instalação for concluída.
Observação
Certifique-se de reiniciar o cluster Databricks após a instalação da biblioteca do Conector do Cassandra.
Aviso
Os exemplos mostrados neste artigo foram testados com o Spark versão 3.0.1 e o Cassandra Spark Connector correspondente com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0. Versões posteriores do Spark e/ou do conector Cassandra podem não funcionar conforme o esperado.
Criar um Notebook Scala para migração
Crie um Notebook Scala no Databricks. Substitua as configurações do Cassandra de origem e de destino pelas credenciais correspondentes, e keyspaces e tabelas de origem e de destino. Em seguida, execute o código a seguir:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val nativeCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val cosmosCassandra = Map(
"spark.cassandra.connection.host" -> "<USERNAME>.cassandra.cosmos.azure.com",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
//"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1", // Spark 3.x
"spark.cassandra.connection.connections_per_executor_max"-> "1", // Spark 2.x
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from native Cassandra
val DFfromNativeCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(nativeCassandra)
.load
//Write to CosmosCassandra
DFfromNativeCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(cosmosCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Observação
Os valores spark.cassandra.output.batch.size.rows e spark.cassandra.output.concurrent.writes e o número de trabalhos em seu cluster Spark são configurações importantes a serem ajustadas a fim de evitar a limitação da taxa. A limitação de taxa ocorre quando as solicitações para o Azure Cosmos DB excedem a taxa de transferência provisionada ou as unidades de solicitação (RUs). Talvez seja necessário ajustar essas configurações, dependendo do número de executores no cluster Spark e, potencialmente, do tamanho (e portanto do custo da RU) de cada registro que está sendo gravado nas tabelas de destino.
Solucionar problemas
Limitação de taxa (erro 429)
Você talvez veja um código de erro 429 ou o texto de erro "taxa de solicitação é grande" mesmo que você tenha reduzido as configurações para os valores mínimos. Os seguintes cenários podem causar limitação de taxa:
A taxa de transferência alocada para a tabela é inferior a 6.000 unidades de solicitação . Mesmo nas configurações mínimas, o Spark pode gravar a uma taxa de aproximadamente 6.000 unidades de solicitação ou mais. Se você provisionou uma tabela em um keyspace com taxa de transferência compartilhada, é possível que essa tabela tenha menos de 6.000 RUs disponíveis em runtime.
Verifique se a tabela para a qual que você está migrando tem pelo menos 6.000 RUs disponíveis quando você executar a migração. Se necessário, aloque unidades de solicitação dedicadas para essa tabela.
Distorção de dados excessiva com grande volume de dados. Se você tiver uma grande quantidade de dados para migrar para uma determinada tabela, mas tiver uma distorção significativa nos dados (ou seja, um grande número de registros sendo gravados para o mesmo valor de chave de partição), ainda poderá enfrentar uma limitação de taxa mesmo que tenha várias unidades de solicitação provisionadas na tabela. As unidades de solicitação são divididas igualmente entre as partições físicas e a distorção de dados pesada pode causar um gargalo de solicitações para uma única partição.
Nesse cenário, reduza as configurações da taxa de transferência mínima no Spark e force a migração para execução lenta. Esse cenário pode ser mais comum quando você está migrando tabelas de referência ou de controle, em que o acesso é menos frequente e a distorção pode ser elevada. No entanto, se uma distorção significativa estiver presente em qualquer outro tipo de tabela, talvez você queira examinar seu modelo de dados para evitar problemas de partição ativa para a carga de trabalho durante operações de estado estacionário.