Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Embora os bancos de dados sem esquema, como o Azure Cosmos DB, facilitem o armazenamento e a consulta de dados não estruturados e semiestruturados, pense no modelo de dados para otimizar o desempenho, a escalabilidade e o custo.
Como os dados são armazenados? Como seu aplicativo recupera e consulta dados? O aplicativo realizará grandes volumes de leitura e gravação?
Depois de ler este artigo, você pode responder às seguintes perguntas:
- O que é modelagem de dados e como ele me afeta?
- Como a modelagem de dados no Azure Cosmos DB é diferente de um banco de dados relacional?
- Como você expressa relações de dados em um banco de dados não relacional?
- Quando eu insiro dados e quando vinculo a eles?
Números em JSON
O Azure Cosmos DB salva documentos em JSON, portanto, é importante determinar se os números devem ser convertidos em cadeias de caracteres antes de armazená-los no JSON. Converta todos os números em um String se eles podem exceder os limites de números de precisão dupla, conforme definido pelo Instituto de Engenheiros Elétricos e Eletrônicos (IEEE) 754 binary64. A especificação JSON explica por que usar números fora desse limite é uma má prática devido a problemas de interoperabilidade. Essas preocupações são especialmente relevantes para a coluna de chave de partição porque ela é imutável e requer que a migração de dados seja alterada posteriormente.
Inserir dados
Quando você começar a modelar dados no Azure Cosmos DB, tente tratar suas entidades como itens autossuficientes representados como documentos JSON.
Para fins de comparação, vejamos primeiro como podemos modelar dados em um banco de dados relacional. O exemplo a seguir mostra como uma pessoa poderia ser armazenada em um banco de dados relacional.
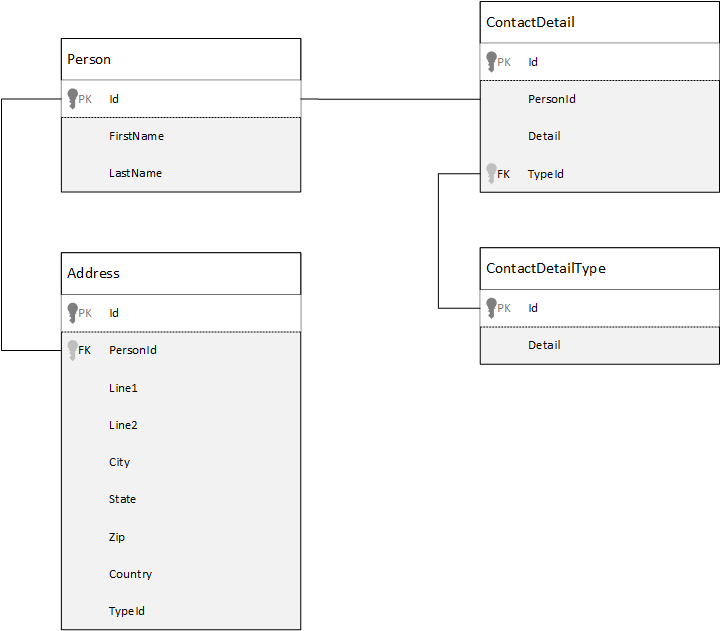
A estratégia, quando se trabalha com bancos de dados relacionais, é normalizar todos os dados. Normalizar seus dados geralmente envolve pegar uma entidade, como uma pessoa, e dividi-la em componentes discretos. No exemplo, uma pessoa pode ter diversos registros de detalhes de contato, bem como vários registros de endereço. Você pode dividir ainda mais os detalhes de contato extraindo campos comuns, como tipo. A mesma abordagem se aplica a endereços. Cada registro pode ser classificado como Home ou Business.
O local de orientação ao normalizar dados é evitar o armazenamento de dados redundantes em cada registro e, em vez disso, fazer referência aos dados. Neste exemplo, para ler uma pessoa, com todos os detalhes de contato e endereços, você precisará usar JOINS para recompor (ou desnormalizar) os dados de modo eficaz em tempo de execução.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Atualizar os detalhes e endereços de contato de uma única pessoa requer operações de gravação em várias tabelas individuais.
Agora, vejamos como modelaríamos os mesmos dados como uma entidade autossuficiente no Azure Cosmos DB.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
Ao usar essa abordagem, desnormalizamos o registro da pessoa integrando todas as informações relacionadas a ela, como seus detalhes de contato e endereços, em um documento único do JSON. Além disso, como não estamos restritos a um esquema fixo, temos a flexibilidade de, por exemplo, ter detalhes de contato em formatos totalmente diferentes.
Recuperar um registro de pessoa completo do banco de dados agora é uma única operação de leitura em um único contêiner para um único item. A atualização dos detalhes de contato e endereços do registro de uma pessoa também é uma única operação de gravação de um só item.
Desnormalizar dados pode reduzir o número de consultas e atualizações que seu aplicativo precisa para concluir operações comuns.
Quando inserir
De modo geral, use modelos de dados inseridos quando:
- Há relações contidas entre entidades.
- Há relações de um para poucos entre entidades.
- Os dados são alterados com pouca frequência.
- Os dados não crescem sem limite.
- Os dados são consultados com frequência.
Observação
De modo geral, modelos de dados desnormalizados oferecem melhor desempenho de leitura .
Quando não inserir
Embora a regra geral no Azure Cosmos DB seja desnormalizar tudo e inserir todos os dados em um único item, essa abordagem pode levar a situações a serem evitadas.
Dê uma olhada neste trecho de JSON.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
Este exemplo pode ser a aparência de uma entidade de postagem com comentários inseridos se estivéssemos modelando um blog típico ou um CMS (sistema de gerenciamento de conteúdo). O problema com este exemplo é que a matriz de comentários é ilimitada, o que significa que não há limite (prático) para o número de comentários que qualquer postagem pode ter. Esse design pode causar problemas, pois o tamanho do item pode crescer infinitamente grande, portanto, evite-o.
À medida que o tamanho do item aumenta, a transmissão, a leitura e a atualização dos dados em escala tornam-se mais desafiadoras.
Nesse caso, seria melhor considerar o modelo de dados a seguir.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
Esse modelo tem um item para cada comentário com uma propriedade que contém o identificador de postagem. Esse modelo permite que as postagens contenham qualquer número de comentários e cresçam com eficiência. Os usuários que desejam ver mais do que os comentários mais recentes consultariam esse contêiner com a transmissão do postID, que deve ser a chave de partição do contêiner de comentários.
Outro caso em que não é uma boa ideia incorporar dados é quando os dados incorporados são usados com frequência em vários itens e mudam muito.
Dê uma olhada neste trecho de JSON.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
Este exemplo pode representar a carteira de ações de uma pessoa. Optamos por inserir as informações de ações em cada documento de portfólio. Em um ambiente em que os dados relacionados estão mudando frequentemente inserindo dados que as alterações frequentemente significam que você está constantemente atualizando cada portfólio. Usando um exemplo de um aplicativo de negociação de ações, você está atualizando cada item de portfólio sempre que uma ação é negociada.
As ações zbzb podem ser negociadas centenas de vezes em um único dia, e milhares de usuários podem ter zbzb em seus portfólios. Com um modelo de dados como o exemplo, o sistema deve atualizar milhares de documentos de portfólio muitas vezes por dia, o que não é bem dimensionado.
Dados de referência
A inserção de dados funciona bem em muitos casos, mas há cenários em que desnormalizar seus dados causa mais problemas do que vale a pena. O que você pode fazer agora?
Você pode criar relações entre entidades em bancos de dados de documentos, não apenas em bancos de dados relacionais. Em um banco de dados de documento, um item pode incluir informações que se conectam a dados em outros documentos. O Azure Cosmos DB não foi projetado para relações complexas como as de bancos de dados relacionais, mas links simples entre itens são possíveis e podem ser úteis.
No JSON, usamos o exemplo de uma carteira de ações anteriormente, mas desta vez nos referimos ao item de ações no portfólio em vez de inseri-lo. Dessa forma, quando o item de estoque é alterado com frequência ao longo do dia, o único item que precisa ser atualizado é o documento de estoque único.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
Uma desvantagem dessa abordagem é que seu aplicativo deve fazer várias solicitações de banco de dados para obter informações sobre cada ação no portfólio de uma pessoa. Esse design torna a gravação de dados mais rápida, já que as atualizações ocorrem com frequência. No entanto, isso torna a leitura ou a consulta de dados mais lenta, o que é menos importante para esse sistema.
Observação
Modelos de dados normalizados podem demandar mais viagens de ida e volta ao servidor .
E as chaves estrangeiras?
Como não há nenhum conceito de restrição, como uma chave estrangeira, o banco de dados não verifica nenhuma relação entre documentos em documentos; esses links são efetivamente "fracos". Se você quiser garantir que os dados aos quais um item está se referindo realmente existam, faça essa etapa em seu aplicativo ou usando gatilhos do lado do servidor ou procedimentos armazenados no Azure Cosmos DB.
Quando fazer referência
De modo geral, use modelos de dados normalizados quando:
- Representando relações de um para muitos.
- Representando relações de muitos para muitos.
- Os dados relacionados mudam com frequência.
- Dados referenciados podem ser ilimitados.
Observação
De moro geral, normalizar traz melhor desempenho de gravação .
Onde eu coloco a relação?
O crescimento da relação ajuda a determinar em qual item armazenar a referência.
Se observarmos o JSON que modela editoras e livros.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
Se o número de livros por editor for pequeno e o crescimento for limitado, armazenar a referência de livro dentro do item do editor poderá ser útil. No entanto, se o número de livros por editora for ilimitado, esse modelo de dados levaria a matrizes crescentes e mutáveis, como no exemplo de documento de editora.
Alternar a estrutura resulta em um modelo que representa os mesmos dados, mas evita grandes coleções mutáveis.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
Neste exemplo, o documento do editor não contém mais uma coleção não associado. Em vez disso, cada documento de livro inclui uma referência ao seu editor.
Como fazer para modelar relações de muitos para muitos?
Em um banco de dados relacional, as relações muitos para muitos geralmente são modeladas com tabelas de junção. Essas relações unem apenas registros de outras tabelas.
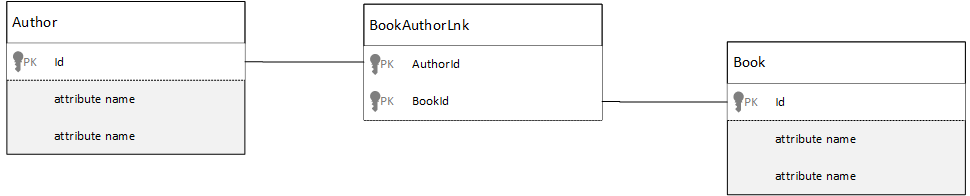
Você pode ficar tentado a fazer a mesma coisa usando documentos e produzir um modelo de dados semelhante ao seguinte.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
Essa abordagem funciona, mas carregar um autor com seus livros ou um livro com seu autor sempre requer pelo menos duas consultas extras de banco de dados. Uma consulta ao item de junção e outra consulta para buscar o item real que está sendo unido.
Se esta junção está apenas unindo dois pedaços de dados, por que não simplesmente removê-la? Considere o exemplo a seguir.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
Com esse modelo, você pode ver facilmente quais livros um autor escreveu examinando seu documento. Você também pode ver quais autores escreveram um livro verificando o documento do livro. Você não precisa usar uma tabela de junção separada ou fazer consultas extras. Esse modelo torna mais rápido e simples para o aplicativo obter os dados necessários.
Modelos de dados híbridos
Exploramos a inserção (ou desnormalização) e a referência (ou normalização) de dados. Cada abordagem oferece benefícios e envolve compensações.
Nem sempre precisa ser um ou outro. Não hesite em misturar as coisas um pouco.
Com base nos padrões de uso e cargas de trabalho específicos do seu aplicativo, a combinação de dados inseridos e referenciados pode fazer sentido. Essa abordagem pode simplificar a lógica do aplicativo, reduzir as viagens de ida e volta do servidor e manter um bom desempenho.
Considere o JSON a seguir.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Aqui, seguimos (principalmente) o modelo inserido, em que os dados de outras entidades são inseridos no documento de nível superior, mas outros dados são referenciados.
Ao olhar o documento do livro, podemos ver alguns campos interessantes na lista de autores. Há um campo id que é o que usamos para fazer referência a um documento de autor, prática padrão em um modelo normalizado, mas também temos name e thumbnailUrl. Poderíamos usar apenas o id aplicativo e permitir que o aplicativo recuperasse as informações adicionais necessárias do item de autor correspondente usando o "link". No entanto, como o aplicativo exibe o nome do autor e uma imagem em miniatura com cada livro, desnormalizar alguns dados do autor reduz o número de viagens de ida e volta do servidor por livro em uma lista.
Se o nome do autor for alterado ou eles atualizarem a foto, você precisará atualizar todos os livros que eles publicaram. No entanto, para este aplicativo, supondo que os autores raramente alterem seus nomes, esse comprometimento é uma decisão de design aceitável.
No exemplo, há valores agregados pré-calculados para economizar o processamento caro durante uma operação de leitura. No exemplo, alguns dos dados inseridos no item de autor são dados calculados em tempo de execução. Sempre que um novo livro é publicado, um item de livro é criado e o campo countOfBooks é definido como um valor calculado com base no número de documentos de livro que existem para um autor específico. Essa otimização seria útil em sistemas com grandes volumes de leitura nos quais podemos computar as gravações para otimizar as leituras.
A capacidade de ter um modelo com campos calculados previamente é possibilitada porque o Azure Cosmos DB dá suporte a transações de vários documentos. Muitos repositórios NoSQL não podem executar transações em documentos e, portanto, defendem decisões de design como "sempre inserir tudo" devido a essa limitação. Com o Azure Cosmos DB, você pode usar gatilhos do lado do servidor ou procedimentos armazenados, que inserem manuais e atualizam autores, tudo isso em uma transação ACID. Agora você não precisa inserir tudo em um item apenas para ter certeza de que seus dados permanecem consistentes.
Distinguir entre diferentes tipos de item
Em alguns cenários, talvez você queira misturar diferentes tipos de item na mesma coleção; essa opção de design geralmente é o caso quando você deseja que vários documentos relacionados fiquem na mesma partição. Por exemplo, você pode colocar livros e resenhas de livros na mesma coleção e particioná-los por bookId. Em tal situação, você geralmente deseja adicionar um campo aos seus documentos que identifica seu tipo para diferenciá-los.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
}
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Modelagem de dados para espelhamento do Microsoft Fabric e do Azure Cosmos DB
O Espelhamento do Azure Cosmos DB é um recurso HTAP (processamento transacional e analítico) híbrido nativo de nuvem que permite executar análises quase em tempo real em dados operacionais no Azure Cosmos DB. O Fabric Mirroring cria uma integração perfeita entre o Azure Cosmos DB e o OneLake no Microsoft Fabric.
Essa integração permite executar consultas rápidas e acessíveis em grandes conjuntos de dados. Você não precisa copiar os dados nem se preocupar em afetar sua carga de trabalho transacional. Quando você ativa o Espelhamento para um contêiner, cada alteração que você faz em seus dados é copiada para o OneLake quase imediatamente. Você não precisa configurar o Feed de Alterações ou executar trabalhos de ETL (extração, transformação e carregamento). O sistema mantém os dois repositórios em sincronia para você.
Com o espelhamento do Azure Cosmos DB, agora você pode se conectar diretamente aos seus contêineres do Azure Cosmos DB a partir do Microsoft Fabric e acessar seus dados sem custos de Unidades de Solicitação (request units), usando consultas T-SQL por meio do endpoint SQL para seus dados ou Spark diretamente do OneLake.
Inferência de esquema automática
O repositório transacional do Azure Cosmos DB é orientado a linhas para dados semiestruturados, enquanto o OneLake no Microsoft Fabric usa um formato colunar e estruturado. Essa conversão é feita automaticamente para os clientes. Há limites no processo de conversão: número máximo de níveis aninhados, número máximo de propriedades, tipos de dados sem suporte e muito mais.
Observação
No contexto do armazenamento analítico, consideramos as seguintes estruturas como propriedade:
- Os "elements" do JSON ou o "string-value pairs separated by a
:" - Objetos JSON, delimitados por
{e} - Matrizes JSON, delimitadas por
[e]
Você pode minimizar o efeito das conversões de inferência de esquema e maximizar seus recursos analíticos usando as técnicas a seguir.
Normalização
A normalização torna-se menos relevante porque o Microsoft Fabric permite que você ingresse em contêineres usando o T-SQL ou o Spark SQL. Os benefícios esperados da normalização são:
- Volume de dados menor.
- Transações menores.
- Menos propriedades por documento.
- Estruturas de dados com menos níveis aninhados.
Ter menos propriedades e menos níveis em seus dados torna as consultas analíticas mais rápidas. Ele também ajuda a garantir que todas as partes de seus dados estejam incluídas no OneLake. Há limites para o número de níveis e propriedades que são representados no OneLake.
Outro fator importante para a normalização é que o OneLake dá suporte a conjuntos de resultados com até 1.000 colunas e expor colunas aninhadas também conta para esse limite. Em outras palavras, os pontos de extremidade SQL no Fabric têm um limite de 1.000 propriedades.
Mas o que fazer, já que a desnormalização é uma técnica de modelagem de dados importante para o Azure Cosmos DB? A resposta é que você deve encontrar o equilíbrio certo para suas tarefas transacionais e analíticas.
Chave de Partição
A PK (chave de partição) do Azure Cosmos DB não é usada no Microsoft Fabric. Graças a esse isolamento, você pode escolher uma chave primária (PK) para seus dados transacionais, com foco na ingestão de dados e em leituras pontuais, enquanto as consultas entre partições podem ser feitas no Microsoft Fabric. Vejamos um exemplo:
Em um cenário de IoT global hipotético, device id serve como uma boa chave de partição porque todos os dispositivos geram um volume semelhante de dados, o que impede problemas de partição ativa. Mas se você quiser analisar os dados de mais de um dispositivo, como "todos os dados de ontem" ou "totais por cidade", poderá ter problemas, pois essas consultas são consultas de partição cruzada. Essas consultas podem prejudicar seu desempenho transacional, pois usam parte da sua taxa de transferência em unidades de solicitação para execução. Mas, com o Microsoft Fabric, você pode executar essas consultas analíticas sem custos de unidades de solicitação. O formato delta no OneLake é otimizado para consultas analíticas.
Tipos de dados e nomes de propriedades
O artigo regras de inferência de esquema automático lista quais são os tipos de dados com suporte. Embora os runtimes do Microsoft Fabric possam processar tipos de dados compatíveis de forma diferente, tipos de dados sem suporte bloqueiam a representação no repositório analítico. Um exemplo é: ao usar cadeias de caracteres DateTime que seguem o padrão ISO 8601 UTC, os pools do Spark no Microsoft Fabric representam essas colunas como string, e o SQL serverless representa essas colunas como varchar(8000).
Nivelamento de dados
Cada propriedade no nível superior dos dados do Azure Cosmos DB se torna uma coluna no repositório analítico. As propriedades dentro de objetos aninhados ou matrizes são armazenadas como JSON no OneLake. Estruturas aninhadas exigem processamento extra dos ambientes de execução do Spark ou do SQL para nivelar os dados. Isso pode adicionar custo e latência de computação ao lidar com grandes quantidades de dados. Onde é simples fazer isso, use um modelo de dados simples para seus dados. No mínimo, evite aninhamento excessivo de dados em seus modelos de dados.
O item tem apenas duas colunas no OneLake id e contactDetails. Todos os outros dados, emaile phone, exigem processamento extra por meio de funções SQL ou Spark para serem lidos.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
O nivelamento elimina essa necessidade. Aqui abaixo, ide emailphone todos estão diretamente acessíveis como colunas sem processamento adicional
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Camada de dados
O Microsoft Fabric permite que você reduza os custos das seguintes perspectivas:
- Menos consultas em execução no banco de dados transacional.
- Um PK otimizado para ingestão de dados e leituras de pontos, reduzindo o espaço de dados, cenários de partição quente e divisões de partições.
- Sem trabalhos ETL em execução em seu ambiente, o que significa que você não precisa provisionar unidades de solicitação para eles.
Redundância controlada
Essa técnica é uma ótima alternativa para situações em que um modelo de dados já existe e não pode ser alterado. Ou se seus dados forem muito complexos, com muitos níveis aninhados ou muitas propriedades. Se esse cenário for o seu caso, você poderá usar o Feed de Alterações do Azure Cosmos DB para replicar seus dados em outro contêiner, aplicando as transformações necessárias e configurando o Espelhamento para esse contêiner no Microsoft Fabric para análise. Vejamos um exemplo:
Scenario
O contêiner CustomersOrdersAndItems é usado para armazenar pedidos on-line, incluindo detalhes de clientes e itens: endereço de cobrança, endereço de entrega, método de entrega, status de entrega, preço dos itens etc. Somente as primeiras 1.000 propriedades são representadas e as principais informações não estão incluídas, tornando a análise no Fabric impossível. O contêiner tem petabytes de dados, portanto, não é possível alterar o aplicativo e remodelar os dados.
Outro aspecto do problema é o grande volume de dados. Bilhões de linhas são constantemente usadas pelo Departamento de Análise, o que os impede de usar tttl para exclusão de dados antigos. Manter todo o histórico de dados no banco de dados transacional devido a necessidades analíticas força o aumento constante de RU/s, impactando os custos. Cargas de trabalho transacionais e analíticas competem pelos mesmos recursos ao mesmo tempo.
o que você pode fazer?
Solução com Feed de Alterações
- A solução é usar o Feed de Alterações para preencher três novos contêineres:
Customers,OrderseItems. Com o Feed de Alterações, você pode normalizar e nivelar os dados e remover informações desnecessárias do modelo de dados. - O contêiner
CustomersOrdersAndItemsagora tem TTL definido para manter dados apenas por seis meses, o que permite outra redução no uso de unidades de solicitação, já que há um mínimo de uma unidade de solicitação por GB no Azure Cosmos DB. Menos dados, menos unidades de solicitação.
Takeaways
A maior vantagem deste artigo é que a modelagem de dados em um cenário sem esquema é tão importante como sempre.
Assim como não há apenas uma forma de representar um dado em uma tela, não há apenas uma forma de modelar seus dados. Você precisa entender seu aplicativo e como ele produz, consome e processa os dados. Aplicando as diretrizes apresentadas aqui, você pode criar um modelo que atende às necessidades imediatas do seu aplicativo. Quando o aplicativo for alterado, use a flexibilidade de um banco de dados sem esquema para adaptar e evoluir seu modelo de dados facilmente.