Criar uma conexão de dados de Hubs de Eventos para o Azure Data Explorer
O Azure Data Explorer oferece ingestão de Hubs de Eventos, uma plataforma de streaming de Big Data e serviços de ingestão de eventos. Os Hubs de Eventos podem processar milhões de eventos por segundo quase em tempo real.
Neste artigo, você se conectará a um hub de eventos e fará ingestão de dados no Azure Data Explorer. Para obter uma visão geral sobre a ingestão dos Hubs de Eventos, consulte Conexão de dados dos Hubs de Eventos do Azure.
Para saber como criar a conexão usando os SDKs do Kusto, consulte Criar uma conexão de dados dos Hubs de Eventos com SDKs.
Para exemplos de código baseados em versões anteriores do SDK, consulte o artigo arquivado.
Criar uma conexão de dados do hub de eventos
Nesta seção, você estabelecerá uma conexão entre o hub de eventos e a tabela do Azure Data Explorer. Enquanto essa conexão estiver em vigor, os dados serão transmitidos do hub de eventos para a tabela de destino. Se o hub de eventos for movido para um recurso ou assinatura diferente, será necessário atualizar ou recriar a conexão.
- Obter dados
- Portal – página do Azure Data Explorer
- Portal – Página Hubs de Eventos do Azure
- Modelo de ARM
Pré-requisitos
- Uma conta Microsoft ou uma identidade de usuário do Microsoft Entra. Uma assinatura do Azure não é necessária.
- Um cluster e um banco de dados do Azure Data Explorer. Criar um cluster e um banco de dados.
- A ingestão de streaming deve ser configurada no cluster do Azure Data Explorer.
Obter dados
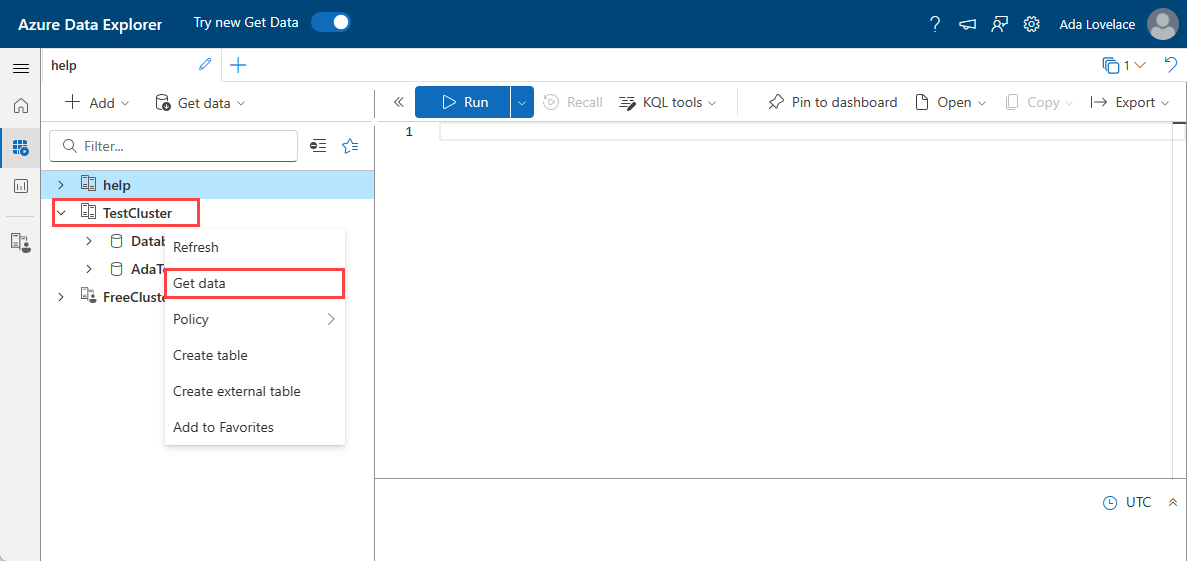
No menu à esquerda, selecione Consulta.
Clique com o botão direito do mouse no banco de dados em que deseja ingerir os dados. Selecione Obter dados.

Origem
Na janela Obter dados, a guia Origem será selecionada.
Selecione a fonte de dados na lista disponível. Neste exemplo, você está ingerindo dados dos Hubs de Eventos.

Configurar
Selecione um banco de dados e uma tabela de destino. Se você quiser ingerir dados em uma nova tabela, selecione + Nova tabela e insira o nome de uma tabela.
Observação
Os nomes de tabelas podem ter até 1024 caracteres, incluindo espaços, caracteres alfanuméricos, hifens e sublinhados. Não há suporte para caracteres especiais.

Preencha os campos a seguir:
Configuração Descrição do campo Assinatura A ID da assinatura em que o recurso do hub de eventos está localizado. Namespace do Hub de Eventos O nome que identifica o namespace. Hub de eventos O hub de eventos que você deseja Grupo de consumidores O grupo de consumidores definido em seu evento Nome da conexão de dados O nome que identifica a conexão de dados. Filtros avançados Compactação O tipo de compactação do conteúdo das mensagens do hub de eventos. Propriedades do sistema de eventos As propriedades do sistema do hub de eventos. Se houver vários registros por mensagem de evento, as propriedades do sistema serão adicionadas ao primeiro. Ao adicionar propriedades do sistema, crie ou atualize o esquema de tabela e o mapeamento de maneira a incluir as propriedades selecionadas. Data de início da recuperação do evento A conexão de dados recupera eventos existentes dos Hubs de Eventos criados após a data de início da recuperação do evento. Somente eventos retidos pelo período de retenção dos Hubs de Eventos podem ser recuperados. Se a data de início da recuperação do evento não for especificada, a hora padrão será a hora em que a conexão de dados é criada. Selecione Avançar.

Inspecionar
A guia Inspecionar será aberta com uma visualização dos dados.
Para concluir o processo de ingestão, selecione Concluir.

Se desejar:
Se os dados exibidos na janela de pré-visualização não estiverem completos, talvez você precise de mais dados para criar uma tabela com todos os campos de dados necessários. Use os seguintes comandos para buscar novos dados do hub de eventos:
Descartar e buscar novos dados: descarta os dados apresentados e procura novos eventos.
Buscar mais dados: procura mais eventos além dos eventos já encontrados.
Observação
Para ver uma pré-visualização dos dados, o hub de eventos precisa enviar os eventos.
Selecione Visualizador de comando para ver e copiar os comandos automáticos gerados com base nas entradas.
Use a lista suspensa Arquivo de definição de esquema para alterar o arquivo do qual o esquema foi inferido.
Altere o formato de dados inferido automaticamente selecionando o formato desejado na lista suspensa. Consulte Formatos de dados compatíveis com o Azure Data Explorer para ingestão.
Editar colunas
Observação
- Para formatos tabulares (CSV, TSV, PSV), você não pode mapear uma coluna duas vezes. Para mapear para uma coluna existente, primeiro exclua a nova coluna.
- Não é possível alterar um tipo de coluna existente. Se você tentar mapear para uma coluna com um formato diferente, poderá ficar com colunas vazias.
As alterações que você pode fazer em uma tabela dependem dos seguintes parâmetros:
- O tipo de tabela é novo ou existente
- O tipo de mapeamento é novo ou existente
| Tipo de tabela | Tipo de mapeamento | Ajustes disponíveis |
|---|---|---|
| Nova tabela | Novo mapeamento | Renomear coluna, alterar tipo de dados, alterar fonte de dados, transformação de mapeamento, adicionar coluna, excluir coluna |
| Tabela existente | Novo mapeamento | Adicionar coluna (na qual você pode alterar o tipo de dados, renomear e atualizar) |
| Tabela existente | Mapeamento existente | nenhum |

Transformações de mapeamento
Alguns mapeamentos de formato de dados (Parquet, JSON e Avro) dão suporte a transformações de tempo de ingestão simples. Para aplicar transformações de mapeamento, crie ou atualize uma coluna na janela Editar colunas.
As transformações de mapeamento podem ser executadas em uma coluna de cadeia de caracteres de tipo ou de datetime, com o tipo de dados int ou long selecionado em Origem. As transformações de mapeamento com suporte são:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Opções avançadas com base no tipo de dados
Tabular (CSV, TSV, PSV):
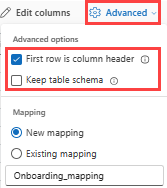
Se você estiver assimilando formatos tabulares em uma tabela existente, poderá selecionar Manter esquema de tabela atual avançado>. Os dados tabulares não incluem necessariamente os nomes de coluna usados para mapear os dados de origem para as colunas existentes. Quando essa opção é marcada, o mapeamento é feito por ordem, e o esquema da tabela permanece o mesmo. Se essa opção estiver desmarcada, novas colunas serão criadas para os dados de entrada, independentemente da estrutura de dados.
Para usar a primeira linha como nomes de coluna, selecione Avançado>A primeira linha é o cabeçalho da coluna.
JSON:
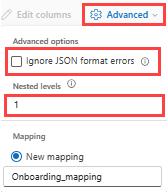
Para determinar a divisão de coluna dos dados JSON, selecione Avançado>Níveis aninhados, de 1 a 100.
Se você selecionar Ignorar erros de formato de dados avançados>, os dados serão assimilados no formato JSON. Se você deixar essa caixa de seleção desmarcada, os dados serão ingeridos no formato multijson.
Resumo
Na janela Preparação de dados, todas as três etapas serão assinaladas com marcas de seleção verdes quando a ingestão de dados for concluída com sucesso. Você pode exibir os comandos que foram usados para cada etapa ou selecionar um cartão para consultar, visualizar ou descartar os dados ingeridos.



Remover uma conexão de dados do hub de eventos
Remova a conexão de dados por meio do portal do Azure, conforme explicado na guia do portal.
Conteúdo relacionado
- Verifique a conexão com o aplicativo de mensagem de amostra do hub de eventos
- Consulta de dados na interface do usuário da Web