Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Azure Data Explorer fornece uma calculadora de preços para estimar o custo do cluster. A estimativa é baseada em especificações como ingestão de dados estimada e carga de trabalho do mecanismo. À medida que você faz alterações na configuração, a estimativa de preço também muda para que você possa entender as implicações de custo de suas opções de configuração.
Este artigo explica cada um dos componentes da calculadora e fornece dicas ao longo do caminho para ajudá-lo a tomar melhores decisões sobre como configurar seu cluster.
Como ele funciona
Você define a região, o ambiente e a ingestão de dados estimada do cluster. Em seguida, a calculadora estima um custo mensal com base nas especificações selecionadas automaticamente ou manualmente em cada um dos seguintes componentes:
- Instâncias de mecanismo
- Instâncias de gerenciamento de dados
- Armazenamento e transações
- Rede
- Marcação do Azure Data Explorer
Na parte inferior do formulário, as estimativas de componentes individuais são somadas para criar uma estimativa mensal total. As estimativas do componente e a atualização total à medida que você faz alterações na configuração.
Introdução
- Acesse a calculadora de preços.
- Role a página para baixo até ver uma guia intitulada Sua estimativa.
- Verifique se o Azure Data Explorer aparece na guia. Caso contrário, faça o seguinte:
- Role de volta para o topo da página.
- Na caixa de pesquisa, digite o Azure Data Explorer.
- Selecione o widget do Azure Data Explorer .
- Inicie a configuração.
As seções deste artigo correspondem aos componentes da calculadora e destacam o que você precisa saber.
Região e ambiente
A região e o ambiente escolhidos para o cluster afetarão o custo de cada componente. Isso ocorre porque as diferentes regiões e ambientes não fornecem exatamente os mesmos serviços ou capacidade.
Escolha o Ambiente para o cluster.
Os clusters de produção contêm dois ou mais nós para gerenciamento de dados e mecanismo e operam sob o SLA do Azure Data Explorer.
Os clusters de desenvolvimento/teste são a opção de menor custo, o que os torna ótimos para avaliação de serviço, realização de PoCs e validações de cenário. Eles são limitados em tamanho e não podem crescer além de um único nó. Não há nenhum encargo de marcação do Azure Data Explorer ou SLA do produto para esses clusters.
Selecione a região desejada para o cluster.
Use o guia de decisão de regiões para encontrar a região certa para você. Sua escolha pode depender de requisitos como:
Ingestão de dados estimada
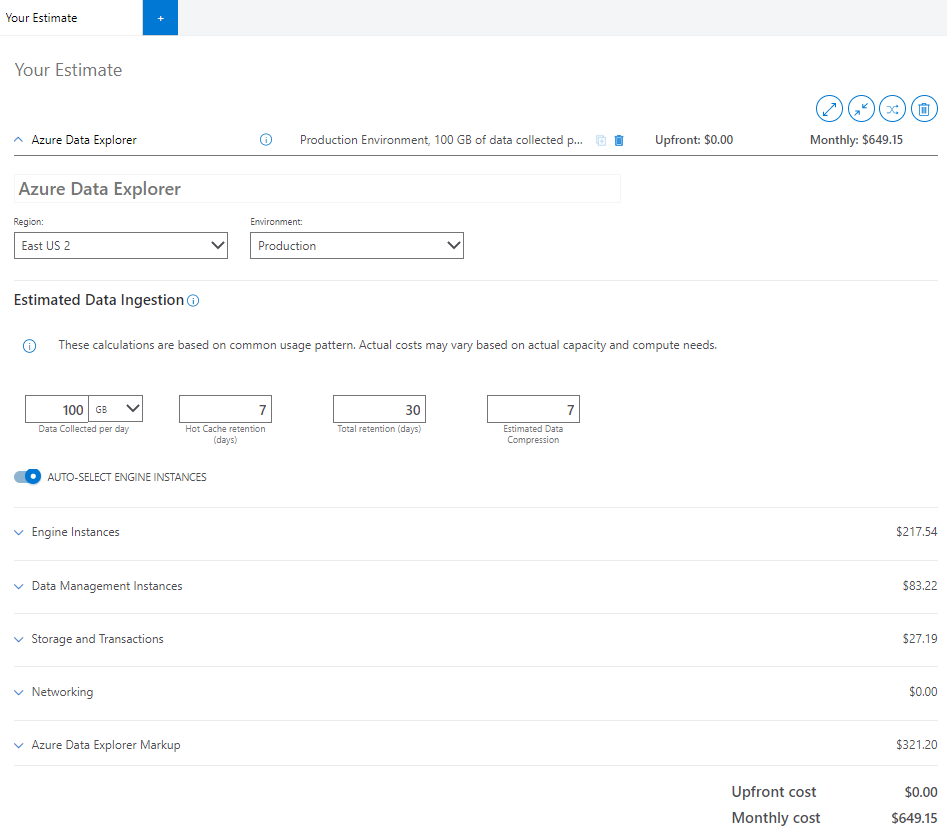
As informações fornecidas na seção Ingestão de dados estimada da calculadora influenciam o preço de todos os componentes do cluster.
Na calculadora, insira estimativas para os seguintes campos:
Dados coletados por dia (GB/TB): dados que você planeja ingerir sem compactação no cluster do Azure Data Explorer todos os dias. Calcule essa estimativa com base no número de arquivos e no tamanho médio de um arquivo que está sendo processado. Se você estiver transmitindo os dados usando mensagens, revise o tamanho médio de uma única mensagem e quantas mensagens você está ingerindo.
Retenção de cache frequente (dias): período durante o qual seus dados são armazenados no cache para acesso rápido à consulta. Dados ingeridos armazenados em cache de acordo com nossa política de cache no SSD local do serviço Mecanismo. Seu requisito de desempenho de consulta determina a quantidade de nós de computação e armazenamento SSD local necessários.
Retenção total (dias): Período durante o qual seus dados são armazenados e disponíveis para consulta. Após a janela de retenção, seus dados serão removidos automaticamente. Escolha a janela de retenção de dados com base na conformidade ou em outros requisitos regulamentares. Aplique o recurso de janela quente para aquecer os dados com base na janela de tempo para consultas mais rápidas.
Compactação de dados estimada: proporção entre o tamanho dos dados não compactados e o tamanho compactado. A compactação de dados varia de acordo com a cardinalidade dos valores e sua estrutura. Por exemplo, os dados de logs ingeridos em colunas estruturadas têm maior compactação em comparação com colunas dinâmicas ou GUID. Todos os dados ingeridos são compactados por padrão.
Seleção automática de instâncias de mecanismo
Se você quiser configurar individualmente os componentes restantes, desative AUTO-SELECT ENGINE INSTANCES. Quando ativada, a calculadora seleciona a SKU (Unidade de Manutenção de Estoque) mais ideal com base nas entradas de ingestão.
Instâncias de mecanismo
As instâncias do mecanismo são responsáveis pela indexação, armazenamento em cache de dados em SSDs locais, armazenamento premium como discos gerenciados e atendimento a consultas. O serviço do mecanismo requer um mínimo de duas instâncias de computação.
Opções de carga de trabalho
Veja a seguir as opções de carga de trabalho do mecanismo:
- Todos: seleciona automaticamente o SKU ideal com base na entrada fornecida
-
SKUs otimizados para computação:
- Fornece alta proporção de núcleos para cache quente
- Adequado para altas taxas de consulta
- SSD local para E/S de baixa latência
-
SKUs otimizados para armazenamento:
- Oferece opções de armazenamento maiores de 1 TB a 4 TB por nó do mecanismo
- Adequado para cargas de trabalho que exigem armazenamento em cache de grandes tamanhos de dados
- Em alguns SKUs, o armazenamento em disco gerenciado premium é anexado ao nó do mecanismo em vez do SSD local para armazenamento de dados frequente
Para obter uma estimativa para instâncias de mecanismo:
- Escolha entre as opções de carga de trabalho. A instância do mecanismo será ajustada de acordo. Se você desativou AUTO-SELECT ENGINE INSTANCES, ESCOLHA A INSTÂNCIA DE MECANISMO ESPECÍFICA E A SÉRIE DE VMs.
- Especifique o número de horas, dias ou meses que você gostaria de executar o mecanismo.
- (Opcional) Selecione um plano de Opções de Poupança.
O componente Premium Managed Disk é baseado no SKU selecionado.
Observação
Nem todas as séries de VM são oferecidas em cada região. Se você estiver procurando um SKU que não esteja listado na região selecionada, escolha uma região diferente.
Instâncias de gerenciamento de dados
O serviço de gerenciamento de dados (DM) é responsável pela ingestão de dados de pipelines de dados gerenciados, como o Armazenamento de Blobs do Azure, os Hubs de Eventos, o Hub IoT e outros serviços, como o Azure Data Factory, o Azure Stream Analytics e o Kafka. O serviço requer um mínimo de duas instâncias de computação que são configuradas e gerenciadas automaticamente com base no tamanho da instância do mecanismo.
Para obter uma estimativa para Instâncias de Gerenciamento de Dados:
- Especifique o número de horas, dias ou meses em que você gostaria de executar a instância.
- (Opcional) Selecione um plano de Opções de Poupança.
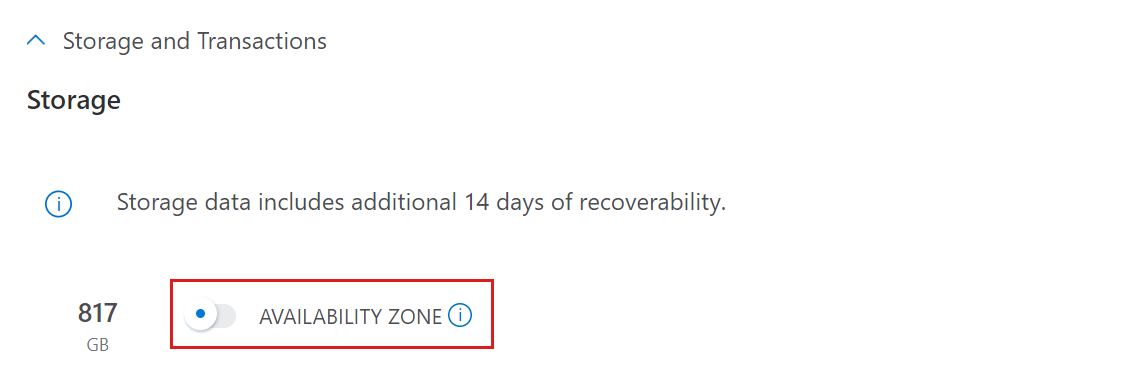
Armazenamento e transações
O componente de armazenamento é a camada persistente em que todos os dados são armazenados compactados e são cobrados como LRS padrão ou ZRS padrão. O armazenamento é calculado com base na quantidade de dados coletados, no total de dias de retenção e na compactação de dados estimada.
Para obter uma estimativa de armazenamento e transações:
- Se você precisar de suporte à zona de disponibilidade, ative a ZONA DE DISPONIBILIDADE. Quando ativado, o armazenamento será implantado como ZRS. Caso contrário, o armazenamento será implantado como LRS.
Rede
Esse componente é configurado usando o serviço de largura de banda.
Para obter uma estimativa de serviço de largura de banda:
- Role até o topo da página
- Na caixa de pesquisa, digite "largura de banda"
- Selecione o widget Produto de largura de banda
- Role para baixo até o componente Largura de banda da estimativa
- Selecione um tipo de transferência de dados
- Selecione uma região de origem
- Selecione uma região de destino
- Insira a quantidade estimada de dados de saída em GB
Observação
Selecione a mesma região em que os logs são gerados para evitar o custo entre regiões e reduzir a latência. Não há custo de transferência de dados entre os serviços do Azure implantados na mesma região.
Marcação do Azure Data Explorer
A marcação do Azure Data Explorer é cobrada pela opção de suporte premium fornecida com a ingestão de dados e os clusters do mecanismo. Ele é cobrado com base no número de vCPUs do mecanismo no cluster e não é cobrado por clusters de desenvolvimento. Seus custos mudam com base no número de horas, dias ou meses configurados no componente de instâncias do mecanismo. Opcionalmente, selecione um plano de Opções de Economia. Para obter mais informações, consulte Preços do Azure Data Explorer – Perguntas frequentes.
Suporte
Escolha um plano de suporte:
Desenvolvedor: selecione essa opção ao configurar o Azure Data Explorer em um ambiente de não produção ou para avaliação e avaliação. Para obter mais informações, consulte a página Suporte do Azure: Desenvolvedor .
Standard: selecione essa opção ao configurar o Azure Data Explorer quando precisar de dependência crítica para os negócios mínima. Para obter mais informações, consulte a página Suporte do Azure: Standard .
Professional Direct: selecione essa opção quando precisar de uma utilização comercial crítica substancial do Azure Data Explorer. Para obter mais informações, consulte a página Suporte do Azure: Professional Direct .
O que fazer com sua estimativa
- Exporte a estimativa para o Excel
- Guarde o orçamento para referência futura
- Compartilhe a estimativa – é necessário fazer login