Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Apache Spark é um mecanismo de análise unificado para processamento de dados em grande escala. O Azure Data Explorer é um serviço de análise de dados rápido e totalmente gerenciado para análise em tempo real de grandes volumes de dados.
O conector do Kusto para Spark é um projeto de código aberto que pode ser executado em qualquer cluster do Spark. Ele implementa a fonte de dados e o coletor de dados para mover dados entre o Azure Data Explorer e os clusters do Spark. Usando o Azure Data Explorer e o Apache Spark, você pode criar aplicativos rápidos e escalonáveis direcionados a cenários baseados em dados. Por exemplo, ML (aprendizado de máquina), ETL (Extração, Transformação e Carregamento) e Log Analytics. Com o conector, o Azure Data Explorer se torna um armazenamento de dados válido para operações de origem e coletor padrão do Spark, como gravação, leitura e writeStream.
Você pode gravar para o Azure Data Explorer por meio da ingestão em fila ou ingestão de fluxo. A leitura do Azure Data Explorer dá suporte à poda de colunas e ao pushdown de predicado, que filtra os dados no Azure Data Explorer, reduzindo o volume de dados transferidos.
Observação
Para obter informações sobre como trabalhar com o conector do Synapse Spark para o Azure Data Explorer, confira Conectar-se ao Azure Data Explorer usando o Apache Spark para o Azure Synapse Analytics.
Este tópico descreve como instalar e configurar o conector Spark do Azure Data Explorer e mover dados entre os clusters do Azure Data Explorer e Apache Spark.
Observação
Embora alguns dos exemplos abaixo se refiram a um cluster Spark do Azure Databricks, o conector Spark do Azure Data Explorer não tem dependências diretas do Databricks ou qualquer outra distribuição do Spark.
Pré-requisitos
- Uma assinatura do Azure. Criar uma conta gratuita do Azure.
- Um cluster e um banco de dados do Azure Data Explorer. Criar um cluster e um banco de dados.
- Um cluster do Spark
- Instalar a biblioteca do conector:
- Bibliotecas pré-compiladas para Spark 2.4+Scala 2.11 ou Spark 3+scala 2.12
- Repositório Maven
- Maven 3.x instalado
Dica
As versões do Spark 2.3. x também têm suporte, mas podem exigir algumas alterações nas dependências de pom.xml.
Como construir o conector Spark
A partir da versão 2.3.0, apresentamos novas IDs de artefato substituindo spark-kusto-connector: kusto-spark_3.0_2.12 visando Spark 3.x e Scala 2.12.
Observação
As versões anteriores à 2.5.1 não funcionam mais para ingestão em uma tabela existente, atualize para uma versão posterior. Esta etapa é opcional. Se você estiver usando bibliotecas pré-compiladas, por exemplo, Maven, confira Configuração do cluster do Spark.
Pré-requisitos de compilação
Consulte esta fonte para compilar o conector Spark.
Para aplicativos Scala/Java que usam definições de projeto Maven, vincule seu aplicativo ao artefato mais recente. Localize o artefato mais recente em Maven Central.
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).Se você não estiver usando bibliotecas pré-compiladas, precisará instalar as bibliotecas listadas em dependências, incluindo as seguintes bibliotecas do SDK do Java do Kusto. Para encontrar a versão correta a ser instalada, examine o POM da versão relevante:
Para criar o jar e executar todos os testes:
mvn clean package -DskipTestsPara criar o jar, execute todos os testes e instale o jar no seu repositório Maven local:
mvn clean install -DskipTests
Para obter mais informações, confira uso do conector.
Instalação de cluster do Spark
Observação
É recomendável usar a versão mais recente do conector Spark do Kusto ao executar as etapas a seguir.
Defina as seguintes configurações de cluster do Spark, com base no cluster do Azure Databricks Spark 3.0.1 e Scala 2.12:
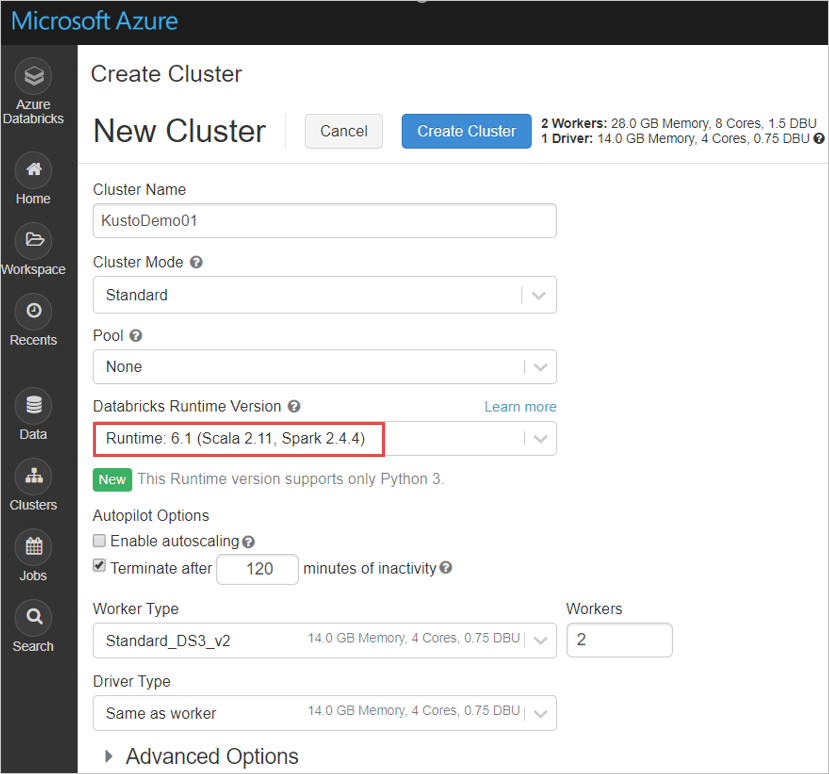
Instale a biblioteca spark-kusto-connector mais recente do Maven:
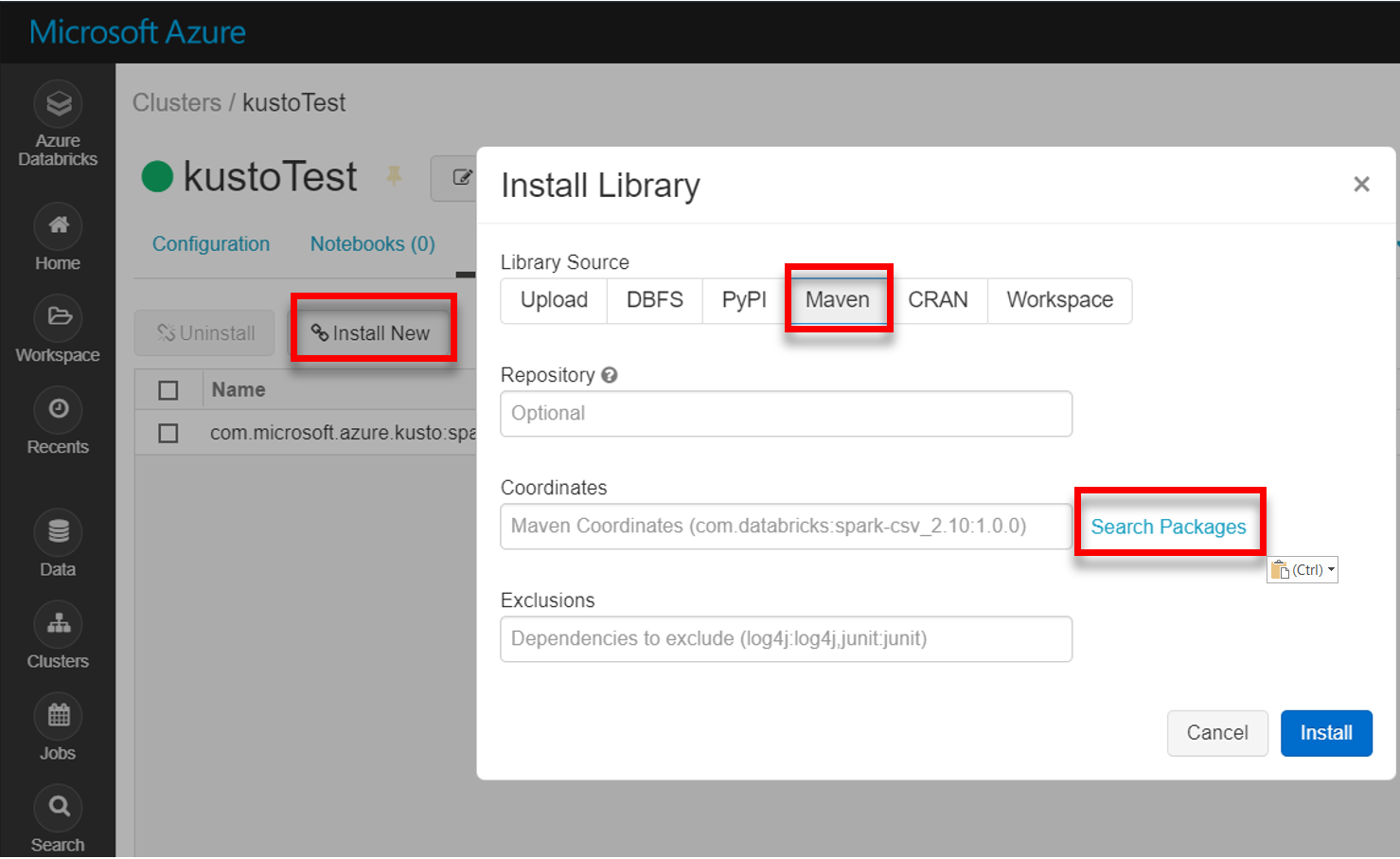
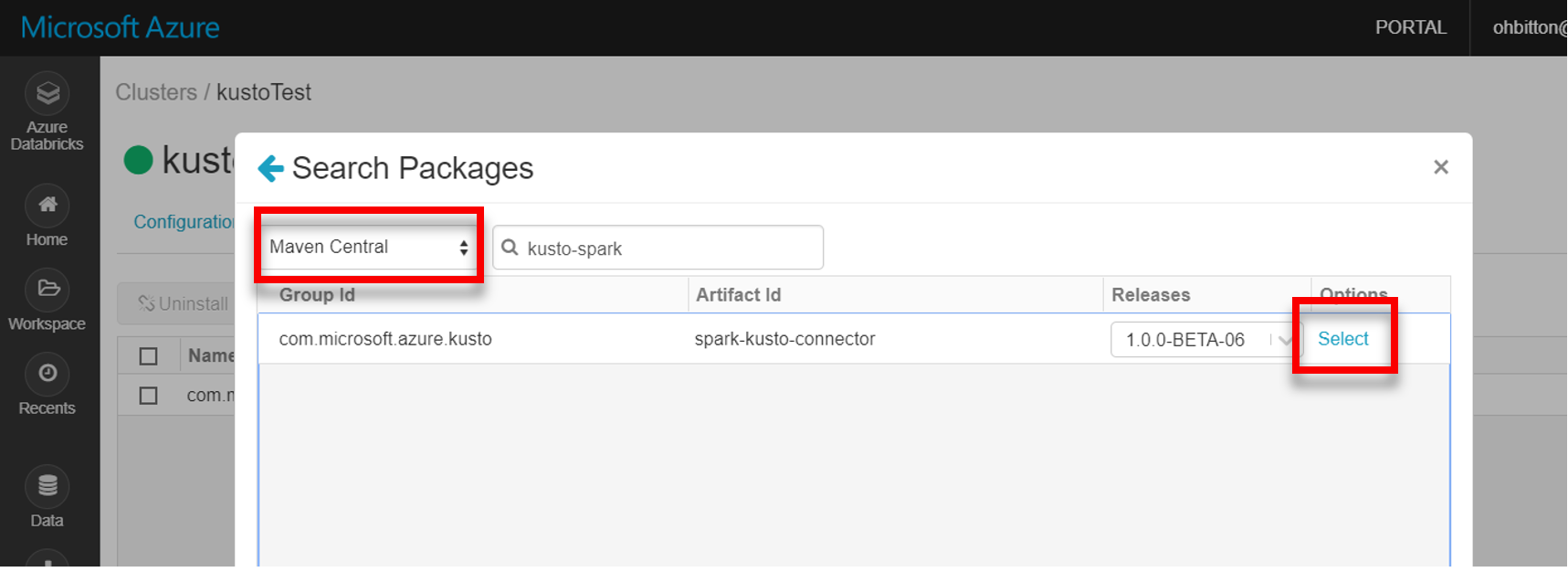
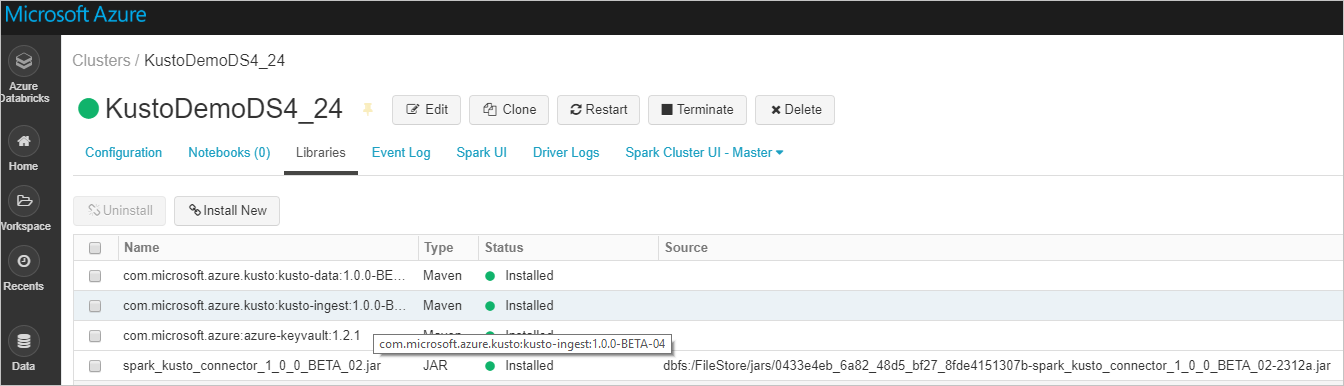
Verifique se todas as bibliotecas necessárias estão instaladas:
Para instalação usando um arquivo JAR, verifique se outras dependências foram instaladas:
Autenticação
O conector Spark do Kusto permite que você se autentique com o Microsoft Entra ID usando um dos seguintes métodos:
- Um aplicativo Microsoft Entra
- Um token de acesso do Microsoft Entra
- Autenticação do dispositivo (para cenários de não produção)
- Para acessar o recurso do Azure Key Vault, instale o pacote azure-keyvault e forneça as credenciais do aplicativo.
Autenticação de aplicativo do Microsoft Entra
A autenticação de aplicativo do Microsoft Entra é o método de autenticação mais simples e comum e é recomendado para o conector Spark do Kusto.
Faça login na sua assinatura do Azure pela CLI do Azure. Em seguida, autentique no navegador.
az loginEscolha a assinatura para hospedar a entidade de segurança. Essa etapa é necessária quando você tem várias assinaturas.
az account set --subscription YOUR_SUBSCRIPTION_GUIDCrie a entidade de serviço. Neste exemplo, a entidade de serviço é chamada
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}A partir dos dados JSON retornados, copie o
appId,passwordetenantpara uso futuro.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Você criou o aplicativo do Microsoft Entra e a entidade de serviço.
O conector Spark usa as seguintes propriedades do aplicativo Entra para autenticação:
| Propriedades | Cadeia de caracteres de opção | Descrição |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Identificador do aplicativo (cliente) Microsoft Entra. |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Autoridade de autenticação do Microsoft Entra. ID do diretório (locatário) do Microsoft Entra. Opcional – o padrão é microsoft.com. Para obter mais informações, consulte Autoridade do Microsoft Entra. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Chave de aplicativo do Microsoft Entra para o cliente. |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | Se você já tiver um accessToken criado com acesso ao Kusto, ele também poderá ser usado e passado ao conector para autenticação. |
Observação
Versões de API mais antigas (menos de 2.0.0) têm a seguinte nomenclatura: "kustoAADClientID", "kustoClientAADClientPassword", "kustoAADAuthorityID"
Privilégios do Kusto
Conceda os seguintes privilégios no lado do Kusto com base na operação do Spark que você deseja executar.
| Operação do Spark | Privilégios |
|---|---|
| Leitura – Modo Único | Leitor |
| Leitura – Modo Distribuído de Força | Leitor |
| Gravação – Modo Enfileirado com opção de criação de tabela CreateTableIfNotExist | Administrador |
| Gravação – Modo Enfileirado com opção de criação de tabela FailIfNotExist | Ingestor |
| Gravação – TransactionalMode | Administrador |
Para obter mais informações sobre as funções principais, confira controle de acesso baseado em função. Para gerenciar funções de segurança, consulte Gerenciamento de funções de segurança.
Coletor do Spark: gravação no Kusto
Configurar parâmetros do coletor:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Gravar o DataFrame do Spark no cluster do Kusto como lote:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Ou use a sintaxe simplificada:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ // Optional, for any extra options: val conf: Map[String, String] = Map() val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Grave os dados de streaming:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // As an alternative to adding .option by .option, you can provide a map: val conf: Map[String, String] = Map( KustoSinkOptions.KUSTO_CLUSTER -> cluster, KustoSinkOptions.KUSTO_TABLE -> table, KustoSinkOptions.KUSTO_DATABASE -> database, KustoSourceOptions.KUSTO_ACCESS_TOKEN -> accessToken) // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Fonte do Spark: leitura do Kusto
Ao ler pequenas quantidades de dados, defina a consulta de dados:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Opcional: se você fornecer o armazenamento de blobs transitório (e não o Kusto), os blobs serão criados sob a responsabilidade do chamador. Isso inclui o provisionamento do armazenamento, a rotação de chaves de acesso e a exclusão de artefatos transitórios. O módulo KustoBlobStorageUtils contém funções auxiliares para excluir blobs com base em coordenadas de conta e contêiner e credenciais de conta, ou uma URL SAS completa com permissões de gravação, leitura e lista. Quando o RDD correspondente não é mais necessário, cada transação armazena artefatos de blob transitórios em um diretório separado. Esse diretório é capturado como parte dos logs de informações da transação de leitura relatados no nó do driver Spark.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")No exemplo acima, o Key Vault não é acessado usando a interface do conector; é utilizado um método mais simples de usar os segredos do Databricks.
Leia do Kusto.
Se você fornecer o armazenamento de blobs transitório, leia do Kusto da seguinte maneira:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Se o Kusto fornecer o armazenamento de blobs transitório, leia do Kusto da seguinte maneira:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)