Eventos
Junte-se a nós na FabCon Vegas
31 de mar., 23 - 2 de abr., 23
O melhor evento liderado pela comunidade Microsoft Fabric, Power BI, SQL e AI. 31 de março a 2 de abril de 2025.
Registre-se hoje mesmoNão há mais suporte para esse navegador.
Atualize o Microsoft Edge para aproveitar os recursos, o suporte técnico e as atualizações de segurança mais recentes.
Este artigo descreve como acessar um banco de dados do Azure Data Explorer por meio do Synapse Studio com o Apache Spark para Azure Synapse Analytics.
Em um workspace do Azure Synapse, selecione Inicializar o Synapse Studio. Na home page do Synapse Studio, selecione Dados para acessar o Pesquisador de Objetos de Dados.
A conexão de um banco de dados do Azure Data Explorer com um workspace é feita por meio de um serviço vinculado. Com um serviço vinculado do Azure Data Explorer, você pode procurar e explorar dados, além de fazer leituras e gravações do Apache Spark para o Azure Synapse. Você também pode executar trabalhos de integração em um pipeline.
No Pesquisador de Objetos de Dados, siga estas etapas para conectar diretamente um cluster do Azure Data Explorer:
Selecione o ícone + perto de Dados.
Escolha Conectar para se conectar aos dados externos.
Selecione Azure Data Explorer (Kusto) .
Selecione Continuar.
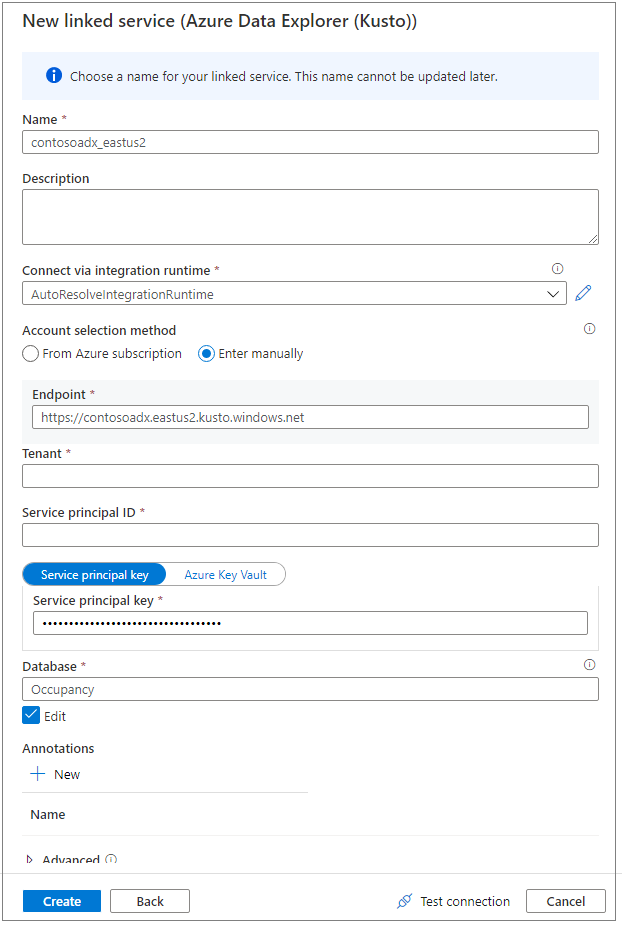
Use um nome amigável para nomear o serviço vinculado. O nome será exibido no Pesquisador de Objetos de Dados e será usado pelos runtimes do Azure Synapse para se conectar ao banco de dados.
Selecione o cluster do Azure Data Explorer na sua assinatura ou insira o URI.
Insira a ID da entidade de serviço e a Chave da entidade de serviço. Verifique se essa entidade de serviço tem acesso de exibição no banco de dados para a operação de leitura e acesso de ingestão para a ingestão de dados.
Insira o nome do banco de dados do Azure Data Explorer.
Selecione Testar conectividade para verificar se você tem as permissões corretas.
Selecione Criar.
Observação
(Opcional) Testar conectividade não valida o acesso de gravação. Verifique se a ID da entidade de serviço tem acesso de gravação ao banco de dados do Azure Data Explorer.
Os clusters e os bancos de dados do Azure Data Explorer são exibidos na guia Vinculados da seção Azure Data Explorer.

Antes de poder interagir com o serviço vinculado de um notebook, ele deve ser publicado no Workspace. Clique em Publicar na barra de ferramentas, revise as alterações pendentes e clique em OK.
Observação
Na versão atual, os objetos do banco de dados são preenchidos com base nas permissões da sua conta do Microsoft Entra nos bancos de dados do Azure Data Explorer. Quando você executar notebooks ou trabalhos de integração do Apache Spark, a credencial do serviço de link será usada (por exemplo, entidade de serviço).
Quando você clicar com o botão direito do mouse em um banco de dados ou uma tabela, uma lista de notebooks de exemplo do Spark será exibida. Selecione uma opção para ler, gravar ou transmitir dados para o Azure Data Explorer.

Veja um exemplo de leitura de dados. Anexe o notebook ao Pool do Spark e execute a célula.

Observação
A primeira execução pode levar mais de três minutos para iniciar a sessão do Spark. As execuções subsequentes serão significativamente mais rápidas.
Atualmente, o conector do Azure Data Explorer não é compatível com redes virtuais gerenciadas do Azure Synapse.
Eventos
Junte-se a nós na FabCon Vegas
31 de mar., 23 - 2 de abr., 23
O melhor evento liderado pela comunidade Microsoft Fabric, Power BI, SQL e AI. 31 de março a 2 de abril de 2025.
Registre-se hoje mesmoTreinamento
Módulo
Analisar dados com o Apache Spark no Azure Synapse Analytics - Training
<div|Apache Spark is a core technology for large-scale data analytics. Learn how to use Spark in Azure Synapse Analytics to analyze and visualize data in a data lake. </div|
Certificação
Microsoft Certified: Azure Data Engineer Associate - Certifications
Demonstre a compreensão das tarefas comuns de engenharia de dados para implementar e gerenciar cargas de trabalho de engenharia de dados no Microsoft Azure, usando vários serviços do Azure.
Documentação
Azure Data Explorer (Kusto) - Azure Synapse Analytics
Este artigo fornece informações sobre como usar o conector para mover dados entre os pools do Azure Data Explorer (Kusto) e os do Apache Spark sem servidor.
Este artigo descreve as diferenças entre o Azure Data Explorer e o Azure Synapse Data Explorer.
Copiar e transformar dados no Azure Data Explorer - Azure Data Factory & Azure Synapse
Saiba como copiar ou transformar dados no Azure Data Explorer usando o Data Factory ou o Azure Synapse Analytics.