Copiar dados do Cassadra utilizando o Azure Data Factory ou Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este artigo descreve como usar a atividade de cópia nos pipelines do Azure Data Factory ou do Azure Synapse Analytics para copiar dados de uma tabela do Cassandra. Ele amplia o artigo Visão geral da atividade de cópia que apresenta uma visão geral da atividade de cópia.
Funcionalidades com suporte
O conector Cassandra tem suporte para as seguintes funcionalidades:
| Funcionalidades com suporte | IR |
|---|---|
| Atividade de cópia (origem/-) | ① ② |
| Atividade de pesquisa | ① ② |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
Para obter uma lista de armazenamentos de dados com suporte como origens e coletores, confira a tabela Armazenamentos de dados com suporte.
Especificamente, este conector do Cassandra dá suporte:
- Cassandra versões 2.x e 3.x.
- À cópia de dados usando a autenticação Básica ou Anônima.
Observação
Para a atividade em execução no Integration Runtime Auto-hospedado, o Cassandra 3.x tem suporte desde o IR versão 3.7 e acima.
Pré-requisitos
Se o armazenamento de dados estiver localizado dentro de uma rede local, em uma rede virtual do Azure ou na Amazon Virtual Private Cloud, você precisará configurar um runtime de integração auto-hospedada para se conectar a ele.
Se o armazenamento de dados for um serviço de dados de nuvem gerenciado, você poderá usar o Azure Integration Runtime. Se o acesso for restrito aos IPs que estão aprovados nas regras de firewall, você poderá adicionar IPs do Azure Integration Runtime à lista de permissões.
Você também pode usar o recurso de runtime de integração da rede virtual gerenciada no Azure Data Factory para acessar a rede local sem instalar e configurar um runtime de integração auto-hospedada.
Para obter mais informações sobre os mecanismos de segurança de rede e as opções compatíveis com o Data Factory, consulte Estratégias de acesso a dados.
O Integration Runtime fornece um driver do Cassandra interno, portanto, não será necessário instalar manualmente nenhum driver ao copiar dados do/para o Cassandra.
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao Cassandra usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao Cassandra na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar em seu workspace do Azure Data Factory ou do Synapse, selecione Serviços Vinculados e clique em Novo:
Procure por Cassandra e selecione o conector do Cassandra.
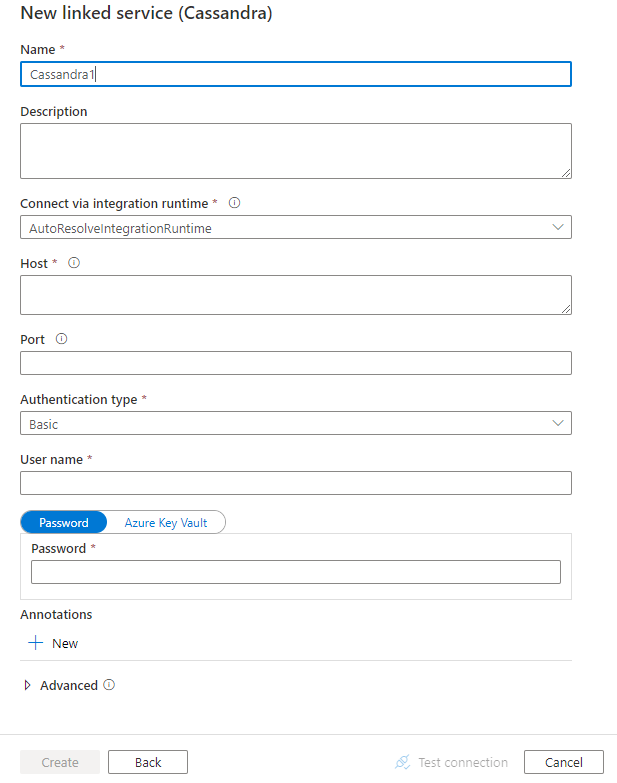
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes da configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades do Data Factory específicas ao Cassandra.
Propriedades do serviço vinculado
As propriedades a seguir têm suporte para o serviço vinculado do Cassandra:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type deve ser definida como: Cassandra | Sim |
| host | Um ou mais endereços IP ou nomes de host dos servidores Cassandra. Especifique uma lista separada por vírgulas de endereços IP ou nomes de host para se conectar simultaneamente a todos os servidores. |
Sim |
| porta | A porta TCP usada pelo servidor Cassandra para ouvir conexões de cliente. | Não (o padrão é 9042) |
| authenticationType | Tipo de autenticação usado para se conectar ao banco de dados Cassandra. Os valores permitidos são: Básica e Anônima. |
Sim |
| Nome de Usuário | Especifique o nome de usuário da conta de usuário. | Sim, se authenticationType for definida como Básica. |
| password | Especifique a senha para a conta de usuário. Marque este campo como um SecureString para armazená-lo com segurança ou referencie um segredo armazenado no Azure Key Vault. | Sim, se authenticationType for definida como Básica. |
| connectVia | O Integration Runtime a ser usado para se conectar ao armazenamento de dados. Saiba mais na seção Pré-requisitos. Se não for especificado, ele usa o Integration Runtime padrão do Azure. | Não |
Observação
Atualmente, não há suporte para a conexão ao Cassandra usando TLS.
Exemplo:
{
"name": "CassandraLinkedService",
"properties": {
"type": "Cassandra",
"typeProperties": {
"host": "<host>",
"authenticationType": "Basic",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa das seções e propriedades disponíveis para definir os conjuntos de dados, confira o artigo sobre conjuntos de dados. Esta seção fornece uma lista das propriedades com suporte pelo conjunto de dados do Cassandra.
Para copiar dados do Cassandra, defina a propriedade type do conjunto de dados como CassandraTable. Há suporte para as seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados deve ser definida como: CassandraTable | Sim |
| keyspace | Nome do keyspace ou do esquema no banco de dados Cassandra. | Não (se a "consulta" para "CassandraSource" estiver especificada) |
| tableName | Nome da tabela no banco de dados Cassandra. | Não (se a "consulta" para "CassandraSource" estiver especificada) |
Exemplo:
{
"name": "CassandraDataset",
"properties": {
"type": "CassandraTable",
"typeProperties": {
"keySpace": "<keyspace name>",
"tableName": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Cassandra linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriedades da atividade de cópia
Para obter uma lista completa das seções e propriedades disponíveis para definir atividades, confia o artigo Pipelines. Esta seção fornece uma lista das propriedades com suporte pela fonte Cassandra.
Cassandra como fonte
Para copiar dados do Cassandra, defina o tipo de fonte na atividade de cópia como CassandraSource. As propriedades a seguir têm suporte na seção source da atividade de cópia:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type da fonte da atividade de cópia deve ser definida como: CassandraSource | Sim |
| Consulta | Utiliza a consulta personalizada para ler os dados. Consulta SQL-92 ou consulta CQL. Veja Referência ao CQL. Ao usar a consulta SQL, especifique keyspace name.table name para representar a tabela que deseja consultar. |
Não (se "tableName" e "keyspace" no conjunto de dados estiverem especificados). |
| consistencyLevel | O nível de consistência especifica quantas réplicas devem responder a uma solicitação de leitura antes de retornar dados ao aplicativo cliente. O Cassandra verifica o número especificado de réplicas de dados atender à solicitação de leitura. Confira Configuring data consistency (Configurando a consistência de dados) para obter detalhes. Os valores permitidos são: ONE, TWO, THREE, QUORUM, ALL, LOCAL_QUORUM, EACH_QUORUM e LOCAL_ONE. |
Não (o padrão é ONE) |
Exemplo:
"activities":[
{
"name": "CopyFromCassandra",
"type": "Copy",
"inputs": [
{
"referenceName": "<Cassandra input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "CassandraSource",
"query": "select id, firstname, lastname from mykeyspace.mytable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Mapeamento de tipo de dados para o Cassandra
Ao copiar dados do Cassandra, os seguintes mapeamentos são usados de tipos de dados do Cassandra para tipos de dados provisórios do Azure Data Factory para os tipos de dados provisórios usados internamente no serviço. Consulte Mapeamentos de tipo de dados e esquema para saber mais sobre como a atividade de cópia mapeia o tipo de dados e esquema de origem para o coletor.
| Tipo de dados Cassandra | Tipo de dados provisório do serviço |
|---|---|
| ASCII | String |
| bigint | Int64 |
| BLOB | Byte[] |
| BOOLEAN | Boolean |
| DECIMAL | Decimal |
| DOUBLE | Double |
| FLOAT | Single |
| INET | String |
| INT | Int32 |
| TEXT | String |
| timestamp | Datetime |
| TIMEUUID | Guid |
| UUID | Guid |
| VARCHAR | String |
| VARINT | Decimal |
Observação
Para tipos de coleção (mapa, conjunto, lista, etc.), consulte a seção Trabalhar com coleções usando tabela virtual .
Não há suporte para tipos definidos pelo usuário.
O comprimento da coluna Binário e os comprimentos da coluna Cadeia de Caracteres não pode ser maior que 4000.
Trabalhar com coleções usando tabela virtual
O serviço usa um driver ODBC interno para se conectar ao banco de dados Cassandra e copiar dados dele. Para tipos de coleção, incluindo mapa, conjunto e lista, o driver normaliza novamente os dados em tabelas virtuais correspondentes. Especificamente, se uma tabela contiver colunas de coleção, o driver vai gerar as seguintes tabelas virtuais:
- Uma tabela base, que contém os mesmos dados da tabela real, exceto nas colunas de coleção. A tabela base usa o mesmo nome da tabela real que ela representa.
- Uma tabela virtual para cada coluna de coleção, que expande os dados aninhados. As tabelas virtuais que representam coleções são nomeadas usando o nome da tabela real, um separador "vt" e o nome da coluna.
As tabelas virtuais se referem aos dados na tabela real, permitindo que o driver acesse dados desordenados. Confira a seção Exemplo para obter detalhes. Você pode acessar o conteúdo das coleções de Cassandra consultando e unindo as tabelas virtuais.
Exemplo
Por exemplo, a "ExampleTable" a seguir é uma tabela de banco de dados Cassandra que contém uma coluna de chave primária de inteiro chamada "pk_int", uma coluna de texto chamada valor, uma coluna de lista, uma coluna de mapa e uma coluna de conjunto (chamada "StringSet").
| pk_int | Valor | Lista | Mapeamento | StringSet |
|---|---|---|---|---|
| 1 | "valor de exemplo 1" | ["1", "2", "3"] | {"S1": "a", "S2": "b"} | {"A", "B", "C"} |
| 3 | "valor de exemplo 3" | ["100", "101", "102", "105"] | {"S1": "t"} | {"A", "E"} |
O driver geraria várias tabelas virtuais para representar essa tabela única. As colunas de chave estrangeira nas tabelas virtuais fazem referência às colunas de chave primário na tabela real e indicam à qual linha da tabela real a linha da tabela virtual corresponde.
A primeira tabela virtual é a tabela base chamada "ExampleTable" e é mostrada na tabela a seguir:
| pk_int | Valor |
|---|---|
| 1 | "valor de exemplo 1" |
| 3 | "valor de exemplo 3" |
A tabela base contém os mesmos dados da tabela de banco de dados original, exceto para as coleções, que são omitidas da tabela e expandidas em outras tabelas virtuais.
As tabelas a seguir mostram as tabelas virtuais que normalizam novamente os dados nas colunas Lista, Mapa e StringSet. As colunas com nomes que terminam com "_index" ou "_key" indicam a posição dos dados na lista ou no mapa original. As colunas com nomes que terminam com "_value" contêm os dados expandidos da coleção.
Tabela "ExampleTable_vt_List":
| pk_int | List_index | List_value |
|---|---|---|
| 1 | 0 | 1 |
| 1 | 1 | 2 |
| 1 | 2 | 3 |
| 3 | 0 | 100 |
| 3 | 1 | 101 |
| 3 | 2 | 102 |
| 3 | 3 | 103 |
Tabela "ExampleTable_vt_Map":
| pk_int | Map_key | Map_value |
|---|---|---|
| 1 | S1 | Um |
| 1 | S2 | b |
| 3 | S1 | t |
Tabela "ExampleTable_vt_StringSet":
| pk_int | StringSet_value |
|---|---|
| 1 | Um |
| 1 | B |
| 1 | C |
| 3 | A |
| 3 | E |
Pesquisar propriedades de atividade
Para saber detalhes sobre as propriedades, verifique Pesquisar atividade.
Conteúdo relacionado
Para obter uma lista de armazenamentos de dados com suporte como coletores e fontes da atividade de cópia, confira os armazenamentos de dados com suporte.