Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Às vezes, você deseja executar uma migração de dados em larga escala do Data Lake ou do EDW (Enterprise Data Warehouse) para Azure. Outras vezes você deseja ingerir grandes quantidades de dados, de diferentes fontes em Azure, para análise de Big Data. Em cada caso, é fundamental alcançar o desempenho e a escalabilidade ideais.
os pipelines Azure Data Factory e Azure Synapse Analytics fornecem um mecanismo para ingerir dados, com as seguintes vantagens:
- Transfere grandes quantidades de dados
- Tem alto desempenho
- É econômico
Essas vantagens são uma ótima opção para engenheiros de dados que desejam criar pipelines de ingestão de dados escalonáveis com alto desempenho.
Após ler este artigo, você poderá responder as perguntas a seguir:
- Que nível de desempenho e escalabilidade posso conseguir usando a atividade de cópia para cenários de migração de dados e de ingestão de dados?
- Quais etapas devo tomar para ajustar o desempenho da atividade de cópia?
- Quais otimizações de desempenho posso utilizar para uma única execução de atividade de cópia?
- Quais outros fatores externos devo considerar ao otimizar o desempenho da cópia?
Note
Se você não estiver familiarizado com a atividade de cópia em geral, consulte a visão geral da atividade de cópia antes de ler este artigo.
Desempenho de cópia e escalabilidade alcançáveis usando pipelines do Azure Data Factory e do Azure Synapse
os pipelines Azure Data Factory e Synapse oferecem uma arquitetura sem servidor que permite paralelismo em diferentes níveis.
Essa arquitetura permite que você desenvolva pipelines que maximizam a taxa de transferência de movimentação de dados para seu ambiente. Esses pipelines utilizam totalmente os seguintes recursos:
- Largura de banda de rede entre os armazenamentos de dados de origem e de destino
- Operações de entrada/saída de armazenamento de dados de origem ou destino por segundo (IOPS) e largura de banda
Essa utilização completa significa que você pode estimar a taxa de transferência geral medindo a taxa de transferência mínima disponível com os seguintes recursos:
- Armazenamento de dados de origem
- Armazenamento de dados de destino
- Largura de banda de rede entre os armazenamentos de dados de origem e de destino
A tabela a seguir mostra o cálculo de duração da movimentação de dados. A duração em cada célula é calculada com base em determinada largura de banda de armazenamento de dados e rede e em determinado tamanho de conteúdo de dados.
Note
A duração fornecida abaixo é destinada a representar o desempenho viável em uma solução de integração de dados de ponta a ponta usando uma ou mais técnicas de otimização de desempenho descritas em Copiar recursos de otimização de desempenho, incluindo o uso de ForEach para particionar e gerar várias atividades de cópia simultâneas. Recomendamos que você siga as etapas fornecidas em Etapas de ajuste de desempenho para otimizar o desempenho da cópia para o seu conjunto de dados específico e a configuração do sistema. Você deve usar os números obtidos em seus testes de ajuste de desempenho para planejamento de implantação de produção, planejamento de capacidade e projeção de cobrança.
| Tamanho dos dados / largura de banda |
50 Mbps | 100 Mbps | 500 Mbps | 1 Gbps | 5 Gbps | 10 Gbps | 50 Gbps |
|---|---|---|---|---|---|---|---|
| 1 GB | 2,7 min | 1,4 min | 0,3 min | 0,1 min | 0,03 min | 0,01 min | 0,0 min |
| 10 GB | 27,3 min | 13,7 min | 2,7 min | 1,3 min | 0,3 min | 0,1 min | 0,03 min |
| 100 GB | 4,6 horas | 2,3 horas | 0,5 horas | 0,2 horas | 0,05 horas | 0,02 horas | 0,0 horas |
| 1 TB | 46,6 horas | 23:3 horas | 4,7 horas | 2,3 horas | 0,5 horas | 0,2 horas | 0,05 horas |
| 10 TB | 19,4 dias | 9,7 dias | 1,9 dias | 0,9 dias | 0,2 dias | 0,1 dias | 0,02 dias |
| 100 TB | 194,2 dias | 97,1 dias | 19,4 dias | 9,7 dias | 1,9 dias | 1 dia | 0,2 dias |
| 1 PB | 64,7 mo | 32.4 mo | 6.5 mo | 3.2 mo | 0,6 mo | 0,3 mo | 0,06 mo |
| 10 PB | 647,3 mo | 323,6 mo | 64,7 mo | 31.6 mo | 6.5 mo | 3.2 mo | 0,6 mo |
A cópia é escalonável em diferentes níveis:
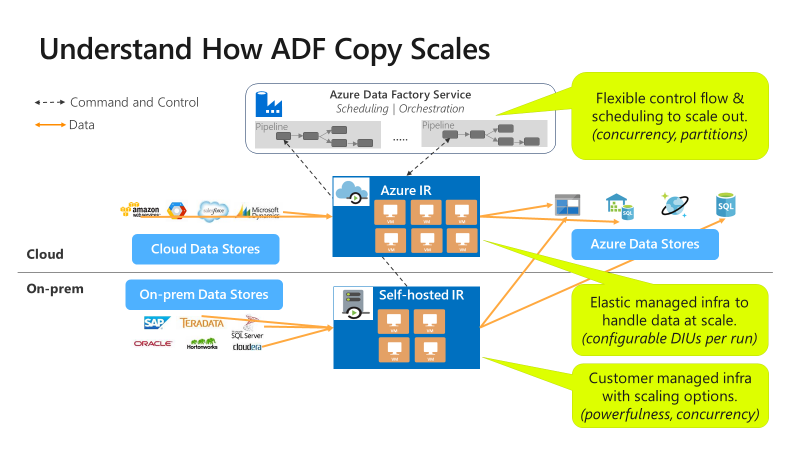
O fluxo de controle pode iniciar várias atividades de cópia em paralelo, por exemplo, usando o loop For Each.
Uma atividade de cópia individual pode aproveitar os recursos de computação escalonáveis.
- Ao usar Azure IR (integration runtime), você pode especificar até 256 DIUs (unidades de integração de dados) para cada atividade de cópia, de maneira sem servidor.
- Ao usar o IR auto-hospedado, você pode adotar uma das seguintes abordagens:
- Escalar verticalmente o computador manualmente.
- Escalar horizontalmente para vários computadores (até 4 nós) e uma única atividade de cópia particionará seu conjunto de arquivos em todos os nós.
Uma só atividade de cópia faz leituras e gravações no armazenamento de dados usando vários threads em paralelo.
Etapas de ajuste do desempenho
Execute as seguintes etapas para ajustar o desempenho do seu serviço com a atividade de cópia:
Pegue um conjunto de dados de teste e estabeleça uma linha de base.
Durante o desenvolvimento, teste seu pipeline com a atividade de cópia em relação a um exemplo de dados representativo. O conjunto de dados que você escolher deve representar seus padrões de dado típicos ao longo dos seguintes atributos:
- Estrutura de pastas
- Padrão do arquivo
- Esquema de dados
E seu conjunto de dados deve ser grande o suficiente para avaliar o desempenho da cópia. Um bom tamanho leva pelo menos 10 minutos para que a atividade de cópia seja concluída. Colete detalhes de execução e características de desempenho após o monitoramento da atividade de cópia.
Como maximizar o desempenho de uma única atividade de cópia:
recomendamos que você primeiro maximize o desempenho usando uma única atividade de cópia.
Se a atividade de cópia estiver sendo executada em um Azure integration runtime:
Comece com valores padrão para DIU (unidades de integração de dados) e configurações de cópia paralelas.
Se a atividade de cópia estiver sendo executada em um runtime de integração auto-hospedada:
recomenda-se usar um computador dedicado para hospedar o IR. O computador deve ser separado do servidor que hospeda o armazenamento de dados. Comece com valores padrão para a configuração de cópia paralela e use um único nó para o IR auto-hospedado.
Realize uma execução de teste de desempenho. Anote o desempenho obtido. Inclua os valores reais usados, como DIUs e cópias paralelas. Consulte monitoramento de atividade de cópia sobre como coletar resultados de execução e configurações de desempenho usadas. Saiba como solucionar problemas de desempenho da atividade de cópia para identificar e resolver o gargalo.
Iterar para realizar mais execuções de teste de desempenho seguindo as diretrizes de solução de problemas e ajuste. Uma vez que execuções individuais de cópia não conseguem obter uma melhor capacidade de transmissão, considere maximizar a taxa de transferência agregada executando várias cópias simultaneamente. Essa opção é discutida no próximo item numerado.
Como maximizar a taxa de transferência agregada executando várias cópias simultaneamente:
Agora, você maximizou o desempenho de uma única atividade de cópia. Se você ainda não atingiu os limites superiores de taxa de transferência do seu ambiente, poderá executar várias atividades de cópia em paralelo. Você pode executar em paralelo usando construções de fluxo de controle. Um desses constructos é o For Each loop. Para obter mais informações, consulte os artigos a seguir sobre modelos de solução:
Expandir a configuração para todo o conjunto de dados.
Quando você estiver satisfeito com os resultados e o desempenho da execução, poderá expandir a definição e o pipeline para cobrir todo o conjunto de dados.
Solucionar problemas de desempenho da atividade de cópia
Siga as etapas de ajuste de desempenho para planejar e conduzir o teste de desempenho para seu cenário. E saiba como solucionar o problema de desempenho de cada execução da atividade de cópia na seção Solucionar problemas de desempenho da atividade de cópia.
Copiar recursos de otimização de desempenho
O serviço fornece os seguintes recursos de otimização de desempenho:
- Unidades de Integração de Dados
- Escalabilidade do Integration Runtime auto-hospedado
- Cópia paralela
- Cópia em etapas
Unidades de Integração de Dados
Uma DIU (Unidade de Integração de Dados) é uma medida que representa o poder de uma única unidade em pipelines do Azure Data Factory e do Synapse. A potência é uma combinação de CPU, memória e alocação de recursos de rede. A DIU só se aplica ao Azure integration runtime. A DIU não se aplica à runtime de integração autogerida. Saiba mais aqui.
Escalabilidade do Integration Runtime auto-hospedado
Talvez você queira hospedar uma carga de trabalho simultânea cada vez maior. Ou talvez você queira obter um desempenho maior em seu nível de carga de trabalho atual. Você pode aprimorar a escala de processamento com as seguintes abordagens:
- Você pode escalar verticalmente o IR auto-hospedado, aumentando o número de trabalhos simultâneos que podem ser executados em um nó.
Escalar verticalmente funcionará somente se o processador e a memória do nó estiverem sendo menores que totalmente utilizados. - Você pode escalar horizontalmente o IR auto-hospedado adicionando mais nós (computadores).
Para obter mais informações, consulte:
- Recursos de otimização de desempenho da atividade Copy: escalabilidade dIntegration Runtime auto-hospedado
- Criar e configurar um runtime de integração auto-hospedada: considerações de escala
Cópia paralela
Você pode definir a propriedade parallelCopies para indicar o paralelismo que deseja que a atividade de cópia use. Considere essa propriedade como o número máximo de threads na atividade de cópia. Os threads operam em paralelo. Os threads leem da origem ou gravam em seus armazenamentos de dados do coletor.
Saiba mais.
Cópia em etapas
Uma operação de cópia de dados pode enviar os dados diretamente para o armazenamento de dados do coletor. Como alternativa, você pode optar por usar o armazenamento de Blobs como um armazenamento de preparo provisório. Saiba mais.
Conteúdo relacionado
Confira os outros artigos sobre atividade de cópia: