Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Os fluxos de dados estão disponíveis em os pipelines do Azure Data Factory e os pipelines do Azure Synapse Analytics. Este artigo se aplica ao fluxo de dados de mapeamento. Se você for novo em transformações, consulte o artigo introdutório Transformar dados usando fluxos de dados de mapeamento.
Dica
No momento, não há suporte para a transformação Assert no Dataflow Gen2. Para obter uma lista de transformações com suporte e seus equivalentes, consulte um guia do Dataflow Gen2 para mapear usuários de fluxo de dados.
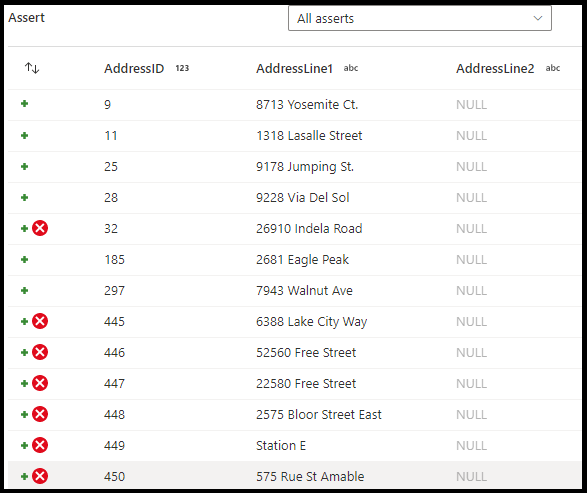
A transformação Assert permite que você crie regras personalizadas dentro dos fluxos de dados de mapeamento para a qualidade dos dados e a validação de dados. Você pode criar regras que determinam se os valores atendem a um domínio de valor esperado. Além disso, você pode criar regras que verificam a exclusividade das linhas. A transformação Assert ajuda a determinar se cada linha em seus dados atende a um conjunto de critérios. A transformação Assert também permite que você defina mensagens de erro personalizadas quando as regras de validação de dados não são atendidas.
Configuração
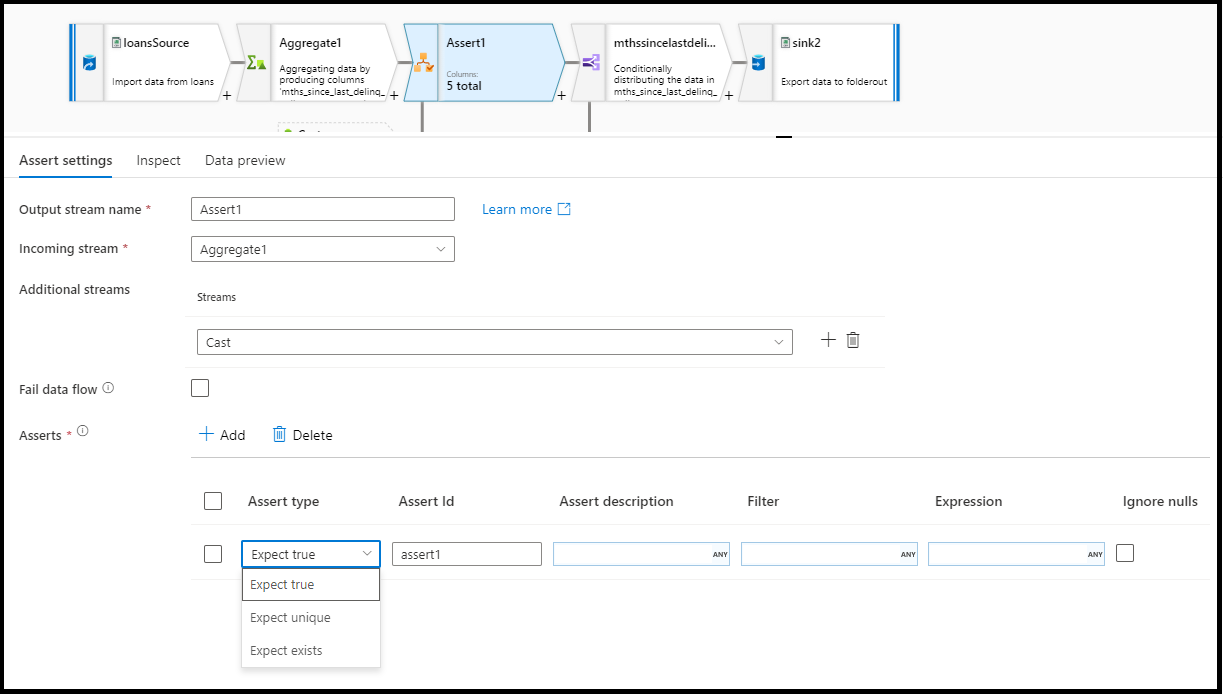
No painel de configuração da transformação Assert, você escolhe o tipo de declaração, fornece um nome exclusivo para a asserção, fornece uma descrição opcional e define a expressão e o filtro opcional. O painel de visualização de dados indica quais linhas falharam em suas asserções. Além disso, você pode testar cada marca de linha downstream usando isError() e hasError() para linhas com declarações com falha.
Tipo de declaração
- Esperar verdadeiro: o resultado da expressão deve ser avaliado como um resultado booliano verdadeiro. Use esta configuração para validar intervalos de valores de domínio em seus dados.
- Esperar único: defina uma coluna ou uma expressão como uma regra de exclusividade em seus dados. Use esta configuração para marcar linhas duplicadas.
- Verificar se existe: esta opção só está disponível quando você seleciona um segundo fluxo de entrada. Exists examina ambos os fluxos e determina se as linhas existem em ambos os fluxos com base nas colunas ou nas expressões que você especificou. Para adicionar o segundo fluxo para existir, selecione
Additional streams.
Falha no fluxo de dados
Selecione fail data flow se você deseja que sua atividade de fluxo de dados falhe imediatamente assim que a regra de asserção falhar.
ID da declaração
A "Assert ID" é uma propriedade na qual você insere um nome (string) para sua declaração. Você pode usar o identificador posteriormente no fluxo de dados utilizando hasError() ou para emitir o código de falha de afirmação. Os IDs de asserção devem ser exclusivos em cada fluxo de dados.
Descrição da asserção
Insira uma descrição da cadeia de caracteres para sua declaração aqui. Você também pode usar expressões e valores de coluna de contexto de linha aqui.
Filtrar
Filter é uma propriedade opcional em que você pode filtrar a declaração para apenas um subconjunto de linhas com base no valor da expressão.
Expressão
Insira uma expressão para avaliação para cada uma de suas asserções. Você pode ter várias asserções para cada transformação de declaração. Cada tipo de asserção requer uma expressão que o ADF precisa avaliar para testar se a declaração foi aprovada.
Ignorar NULLs
Por padrão, a transformação de verificação inclui valores NULL na avaliação da verificação de linhas. Você pode optar por ignorar os valores NULLs com essa propriedade.
Falhas de linha de declaração direta
Quando uma declaração falha, opcionalmente, você pode direcionar essas linhas de erro para um arquivo no Azure usando a guia "Erros" na transformação do coletor. Você também tem a opção, na transformação do sink, de não exibir nenhuma linha com falhas de verificação, ignorando as linhas com erros.
Exemplos
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
Script de fluxo de dados
Exemplos
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1
Conteúdo relacionado
- Use a transformação Select para selecionar e validar colunas.
- Use a Transformação de coluna derivada para transformar valores de coluna.