Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Os fluxos de dados estão disponíveis em os pipelines do Azure Data Factory e os pipelines do Azure Synapse Analytics. Este artigo se aplica ao fluxo de dados de mapeamento. Se você for novo em transformações, consulte o artigo introdutório Transformar dados usando fluxos de dados de mapeamento.
Dica
Para a transformação equivalente (consultas de mesclagem) no Dataflow Gen2, consulte um guia para o Dataflow Gen2 para mapear usuários de fluxo de dados.
Use a transformação de junção para combinar dados de duas fontes ou fluxos em um fluxo de dados de mapeamento. O fluxo de saída inclui todas as colunas das duas fontes que foram combinadas com base em uma condição de união.
Tipos de junção
Os fluxos de dados de mapeamento atualmente são compatíveis com cinco tipos diferentes de junção.
Junção interna
A junção interna só gera linhas que têm valores correspondentes em ambas as tabelas.
Externa esquerda
A junção externa esquerda retorna todas as linhas do fluxo à esquerda e os registros correspondentes do fluxo à direita. Se uma linha do fluxo à esquerda não tiver correspondência, as colunas de saída do fluxo à direita serão definidas como NULL. A saída são as linhas retornadas por uma junção interna mais as linhas não correspondentes do fluxo da esquerda.
Observação
O mecanismo Spark usado pelos fluxos de dados ocasionalmente falha devido a possíveis produtos cartesianos em suas condições de junção. Se isso ocorrer, você poderá alternar para uma junção cruzada personalizada e inserir manualmente sua condição de junção. Isso pode resultar em um desempenho mais lento em seus fluxos de dados, pois o mecanismo de execução pode precisar calcular todas as linhas de ambos os lados da relação e filtrar linhas.
Externa direita
A junção direita esquerda retorna todas as linhas do fluxo à direita e os registros correspondentes do fluxo à esquerda. Se uma linha do fluxo à direita não tiver correspondência, as colunas de saída do fluxo à esquerda serão definidas como NULL. A saída são as linhas retornadas por uma junção interna mais as linhas não correspondentes do fluxo da direita.
Externa completa
A junção externa completa exibe todas as colunas e linhas de ambos os lados, utilizando valores NULL para as colunas que não possuem correspondência.
União cruzada personalizada
A união cruzada gera o produto cruzado dos dois fluxos com base em uma condição. Se você estiver usando uma condição que não seja de igualdade, especifique uma expressão personalizada como condição de junção cruzada. O fluxo de saída são todas as linhas que atendem à condição de junção.
Você pode usar esse tipo de junção nas junções não equivalentes e nas condições OR.
Para produzir explicitamente um produto cartesiano completo, use a transformação Coluna Derivada em cada um dos dois fluxos independentes, antes da junção, para criar uma chave sintética na qual corresponder. Por exemplo, crie uma nova coluna na Coluna Derivada em cada fluxo chamado SyntheticKey e defina-a como 1. Em seguida, use a.SyntheticKey == b.SyntheticKey como sua expressão de junção personalizada.
Observação
Não se esqueça de incluir pelo menos uma coluna de cada lado do relacionamento esquerda e direita de uma união cruzada personalizada. A execução de uniões cruzadas com valores estáticos, em vez de colunas de cada lado, resulta em exames completos de todo o conjunto de dados, fazendo com que o seu fluxo de dados tenha um desempenho inadequado.
Junção difusa
Você pode optar por fazer a junção com base na lógica de junção difusa em vez da correspondência exata do valor da coluna, marcando a caixa de seleção "Usar correspondência difusa".
- Combinar partes de texto: use essa opção para localizar correspondências removendo espaço entre palavras. Por exemplo, o Data Factory será compatível com o DataFactory se essa opção estiver habilitada.
- Coluna de pontuação de similaridade: opcionalmente, você pode optar por armazenar a pontuação correspondente para cada linha em uma coluna inserindo um novo nome de coluna aqui para armazenar esse valor.
- Limite da similaridade: escolha um valor entre 60 e 100 como uma correspondência percentual entre os valores nas colunas selecionadas.
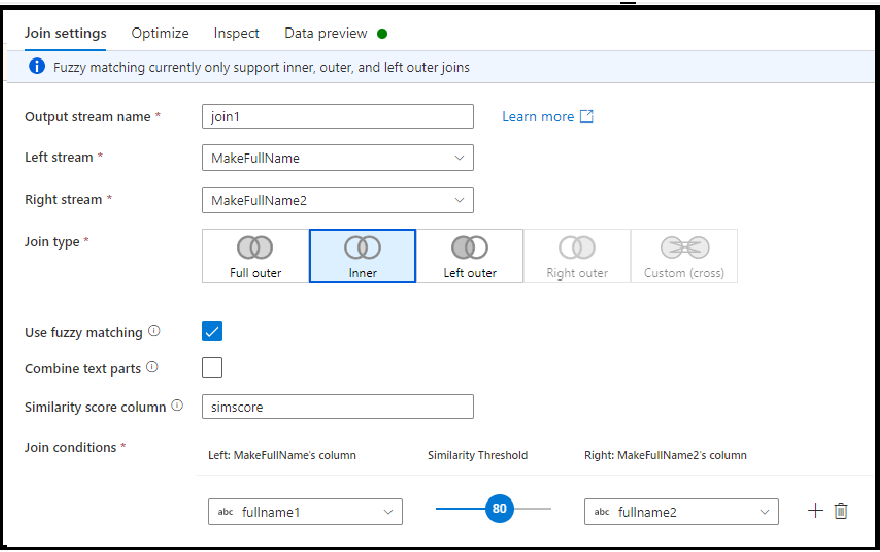
Observação
Atualmente, a correspondência difusa funciona apenas com tipos de coluna de cadeia de caracteres e com tipos de junção interna, externa esquerda e externa completa. Você deve desativar a otimização difundida ao usar junções de correspondência de fuzzing.
Configuração
- Escolha o fluxo de dados com o qual você está fazendo a junção, na lista suspensa Fluxo à direita.
- Selecione seu Tipo de junção
- Escolha as colunas de chave que você deseja corresponder à sua condição de junção. Por padrão, o fluxo de dados procura igualdade entre uma coluna em cada fluxo. Para comparar por meio de um valor calculado, passe o mouse sobre a lista suspensa da coluna e selecione Coluna computada.
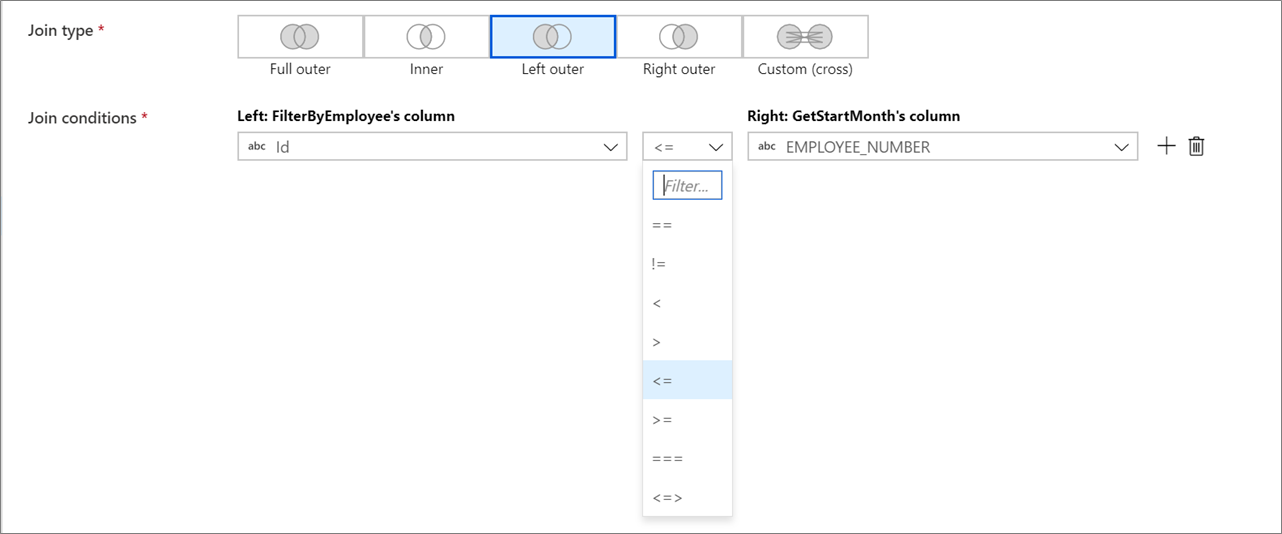
Uniões não equivalentes
Para usar um operador condicional como diferente de (!=) ou maior que (>) em suas condições de junção, altere a lista suspensa do operador entre as duas colunas. Uniões não equivalentes exigem que pelo menos um dos dois fluxos sejam transmitidos usando a transmissão Fixa na guia Otimizar.
Otimizando o desempenho da junção
Ao contrário da junção de mesclagem em ferramentas como o SSIS, a transformação de junção não é uma operação de junção de mesclagem obrigatória. As chaves de junção não exigem classificação. A operação de junção ocorre com base na operação de junção ideal no Spark, seja junção de difusão ou do lado do mapa.
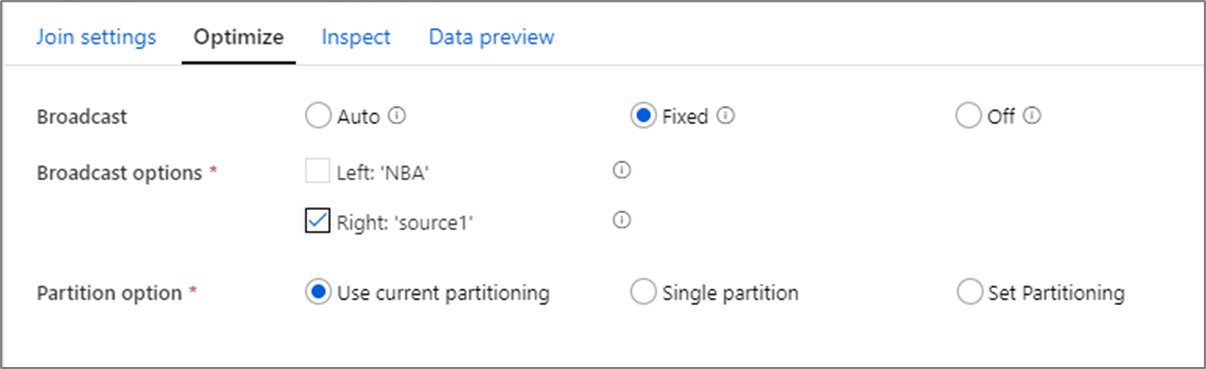
Em transformação de junções, pesquisas e ocorrências, se um ou ambos os fluxos de dados se ajustarem à memória do nó de trabalho, você poderá otimizar o desempenho habilitando a Difusão. Por padrão, o mecanismo Spark decide automaticamente se deve ou não transmitir um dos lados. Para escolher manualmente o lado a ser transmitido, selecione Fixo.
Não é recomendável desabilitar a transmissão por meio da opção Desativar, a menos que suas uniões estejam tendo erros de tempo limite.
Autojunção
Para fazer a autojunção de um fluxo de dados, atribua um alias a um fluxo existente com uma transformação de seleção. Crie um novo branch clicando no ícone de adição ao lado de uma transformação e selecionando Novo branch. Adicione uma transformação de seleção para atribuir o alias ao fluxo original. Adicione uma transformação de junção e escolha o fluxo original como Fluxo à esquerda e a transformação de seleção como Fluxo à direita.
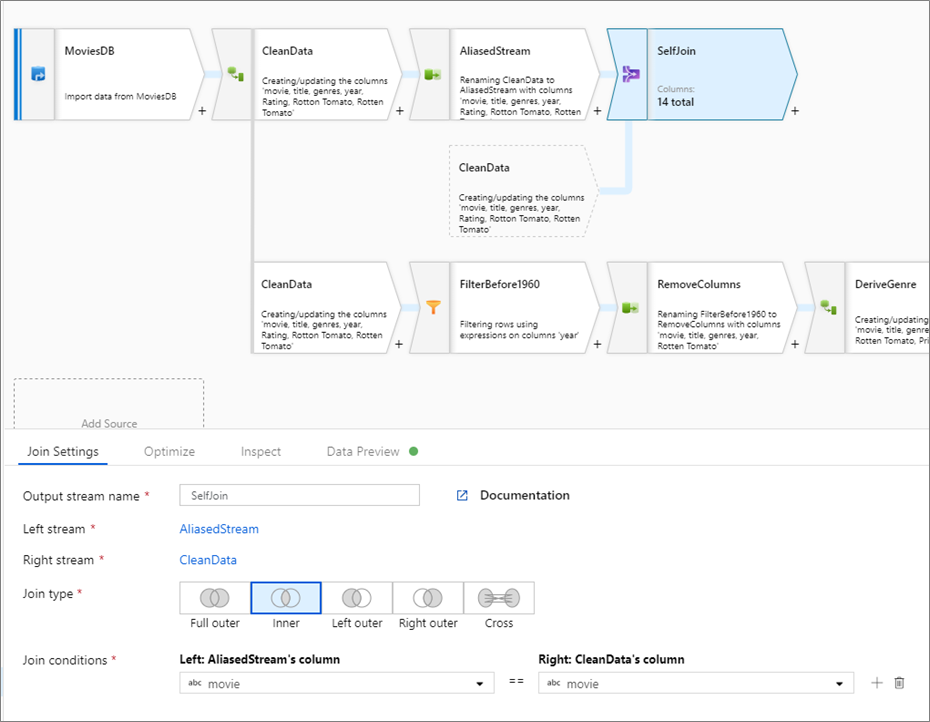
Testando condições de junção
Ao testar as transformações de junção com a visualização de dados no modo de depuração, use um pequeno conjunto de dados conhecidos. Ao amostrar linhas de um conjunto de dados grande, você não pode prever quais linhas e chaves são lidas para teste. O resultado é não determinístico, o que significa que suas condições de junção podem não retornar nenhuma correspondência.
Script de fluxo de dados
Sintaxe
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
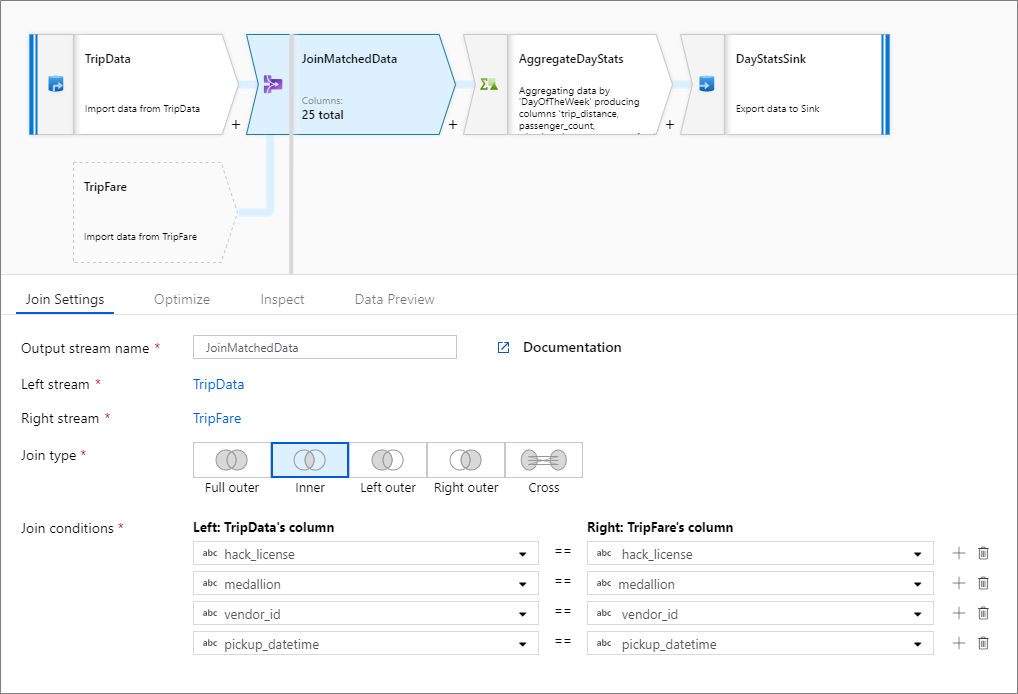
Exemplo de junção interna
Este exemplo é uma transformação de junção chamada JoinMatchedData que usa fluxo TripData esquerdo e fluxo TripFaredireito. A condição de junção é a expressão hack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime} que retorna true quando as colunas hack_license, medallion, vendor_id e pickup_datetime de cada fluxo correspondem. O joinType é 'inner'. Estamos habilitando a difusão somente no fluxo à esquerda para que broadcast tenha o valor 'left'.
Na interface do usuário, essa transformação tem esta aparência:
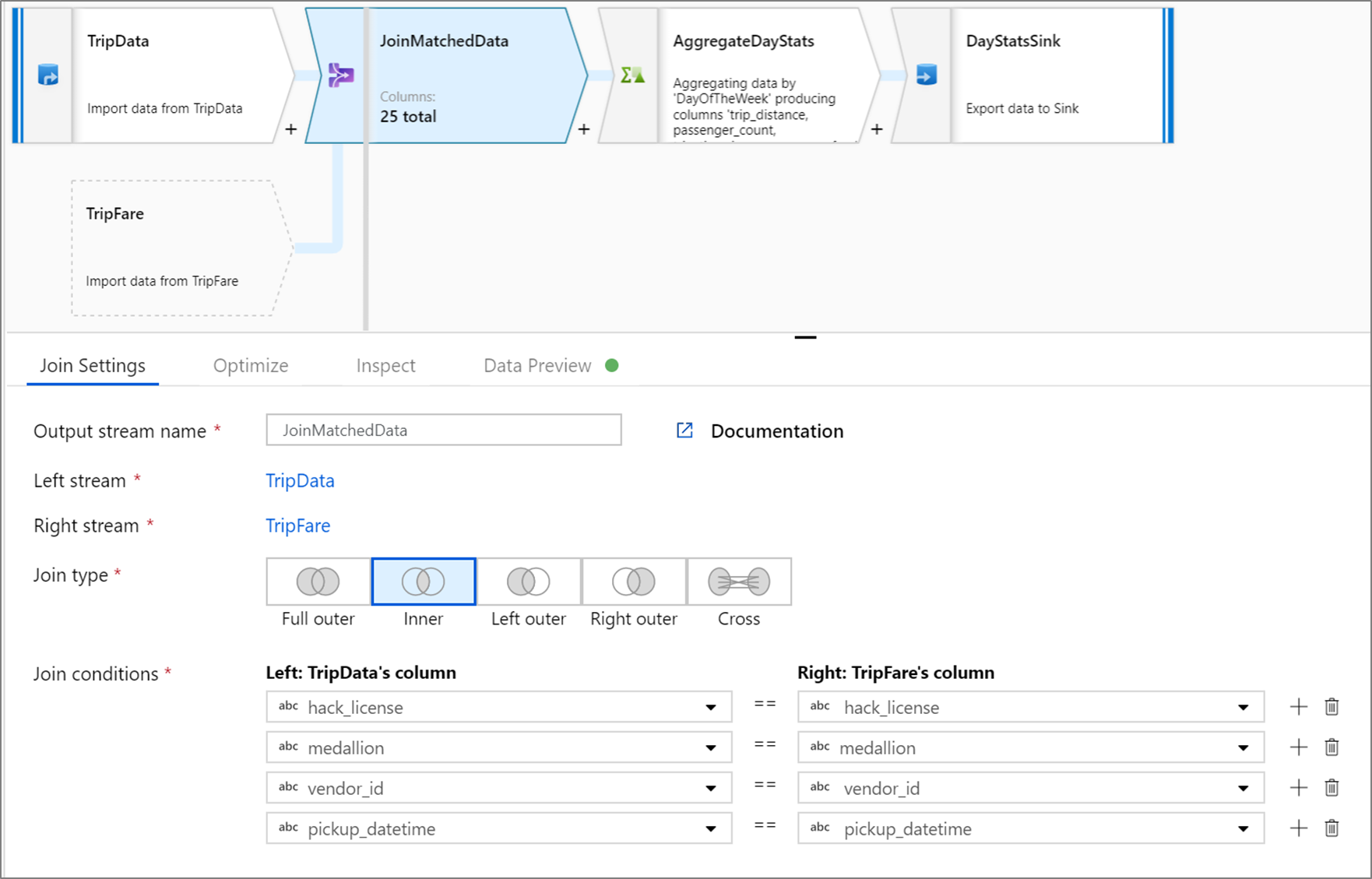
O script de fluxo de dados para essa transformação está neste snippet:
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
Exemplo de união cruzada personalizada
Este exemplo é uma transformação de junção chamada JoiningColumns que usa fluxo LeftStream esquerdo e fluxo RightStreamdireito. Essa transformação usa dois fluxos e une todas as linhas nas quais a coluna leftstreamcolumn é superior à coluna rightstreamcolumn. O joinType é cross. A transmissão não está habilitada broadcast tem o valor 'none'.
Na interface do usuário, essa transformação tem esta aparência:
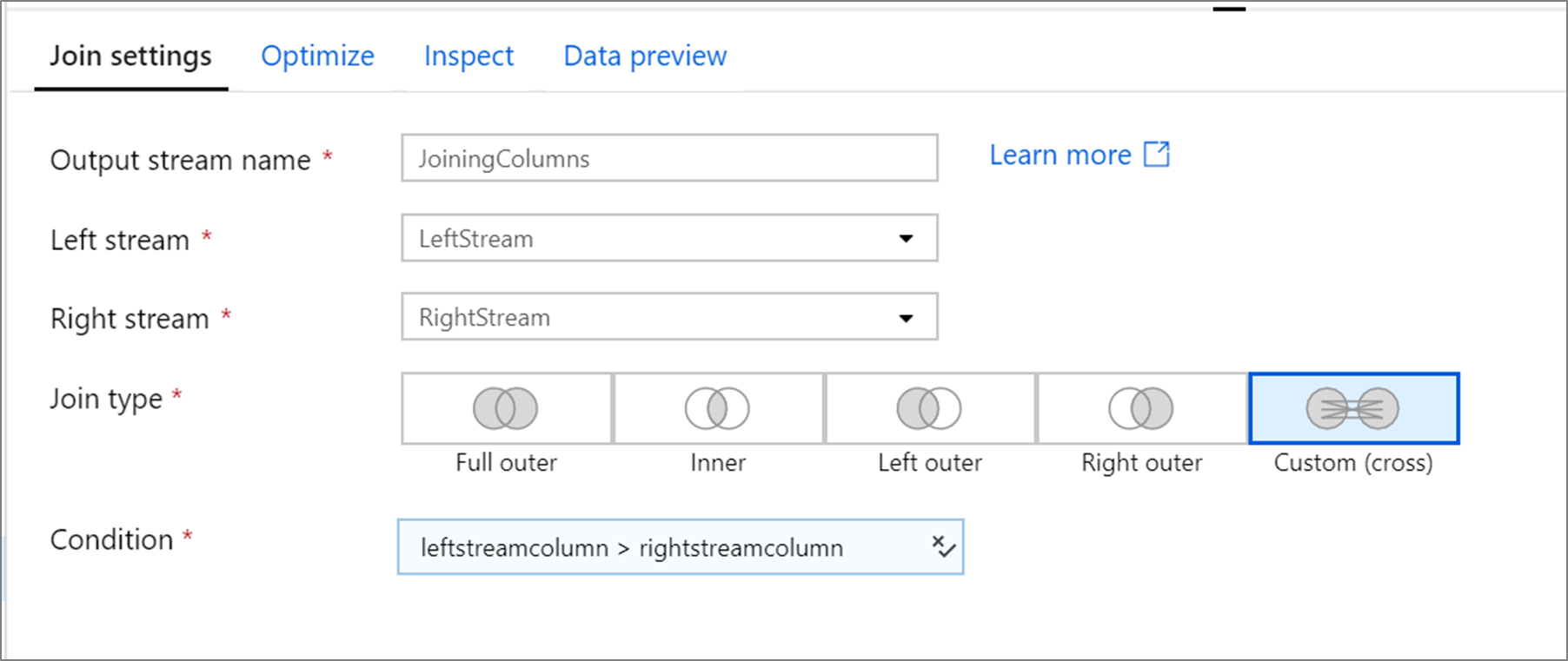
O script de fluxo de dados para essa transformação está no snippet:
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns
Conteúdo relacionado
Depois de unir os dados, crie uma coluna derivada e envie seus dados para um armazenamento de dados de destino.