Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Os fluxos de dados estão disponíveis em os pipelines do Azure Data Factory e os pipelines do Azure Synapse Analytics. Este artigo se aplica ao fluxo de dados de mapeamento. Se você for novo em transformações, consulte o artigo introdutório Transformar dados usando fluxos de dados de mapeamento.
Dica
Para a transformação equivalente (coluna dinâmica) no Dataflow Gen2, consulte um guia para o Dataflow Gen2 para mapear usuários de fluxo de dados.
Use a transformação dinâmica para criar várias colunas com origem em valores de linha exclusivos de uma única coluna. A dinamização é uma transformação de agregação em que você escolhe colunas agrupar por e gera colunas dinâmicas usando funções de agregação.
Configuração
A transformação dinâmica requer três entradas diferentes: colunas agrupar por, a chave dinâmica e como gerar as colunas dinamizadas.
Agrupar por
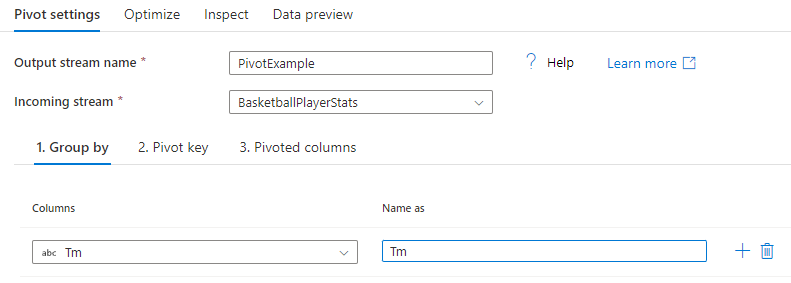
Selecione as colunas nas quais as colunas dinamizadas devem ser agregadas. Os dados de saída agrupam todas as linhas com o mesmo grupo por valores em uma linha. A agregação feita na coluna pivotada ocorre em cada grupo.
Esta seção é opcional. Se nenhum grupo por colunas for selecionado, todo o fluxo de dados será agregado e apenas uma linha será gerada como saída.
Chave dinâmica
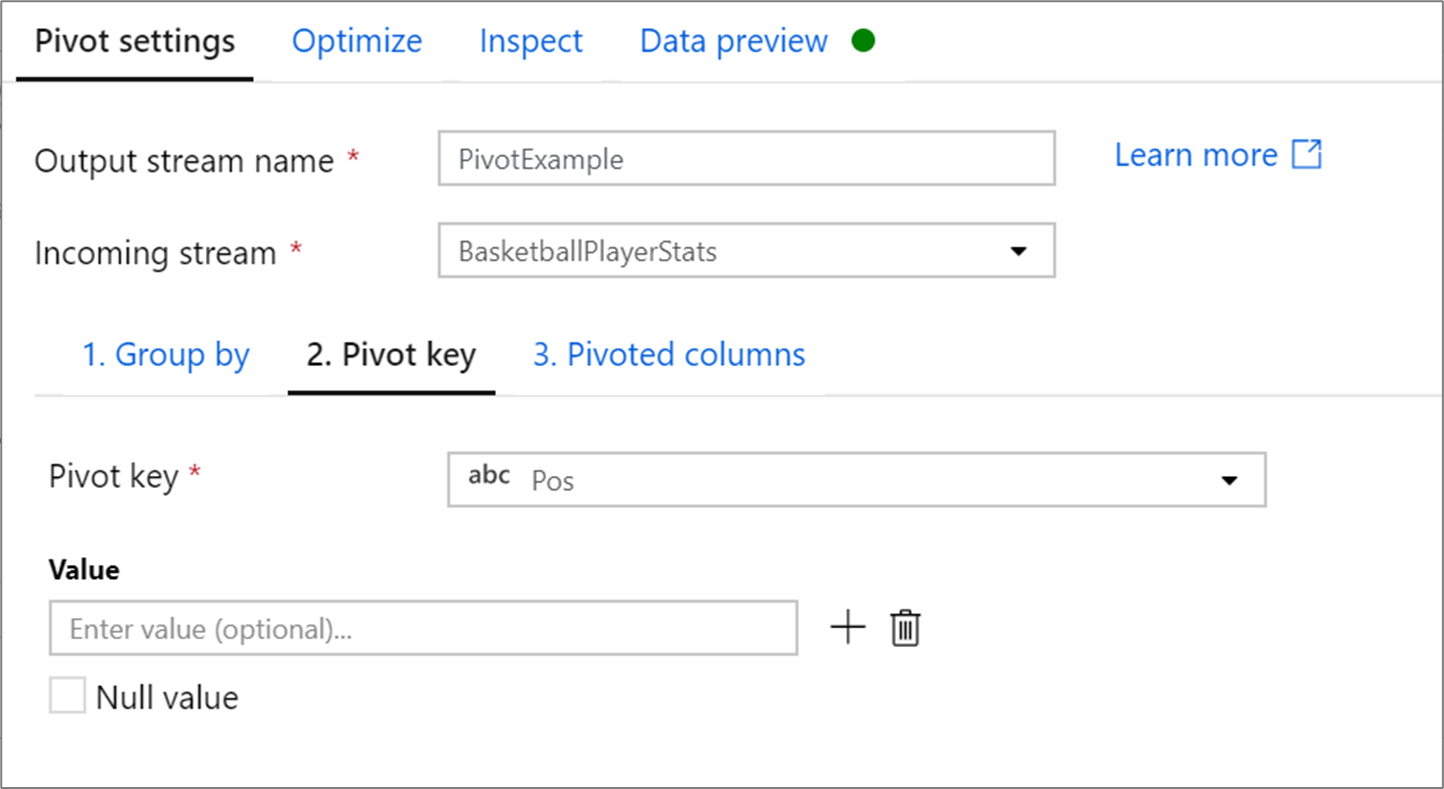
A chave dinâmica é a coluna cujos valores de linha são dinamizados em novas colunas. Por padrão, a transformação de pivô cria uma nova coluna para cada valor de linha exclusivo.
Na seção chamada Valor, você pode inserir valores de linha específicos a serem pivotados. Somente os valores das linhas inseridos nesta seção são pivotados. Habilitar o valor Nulo cria uma coluna pivotada para os valores nulos dessa coluna.
Colunas pivoteadas
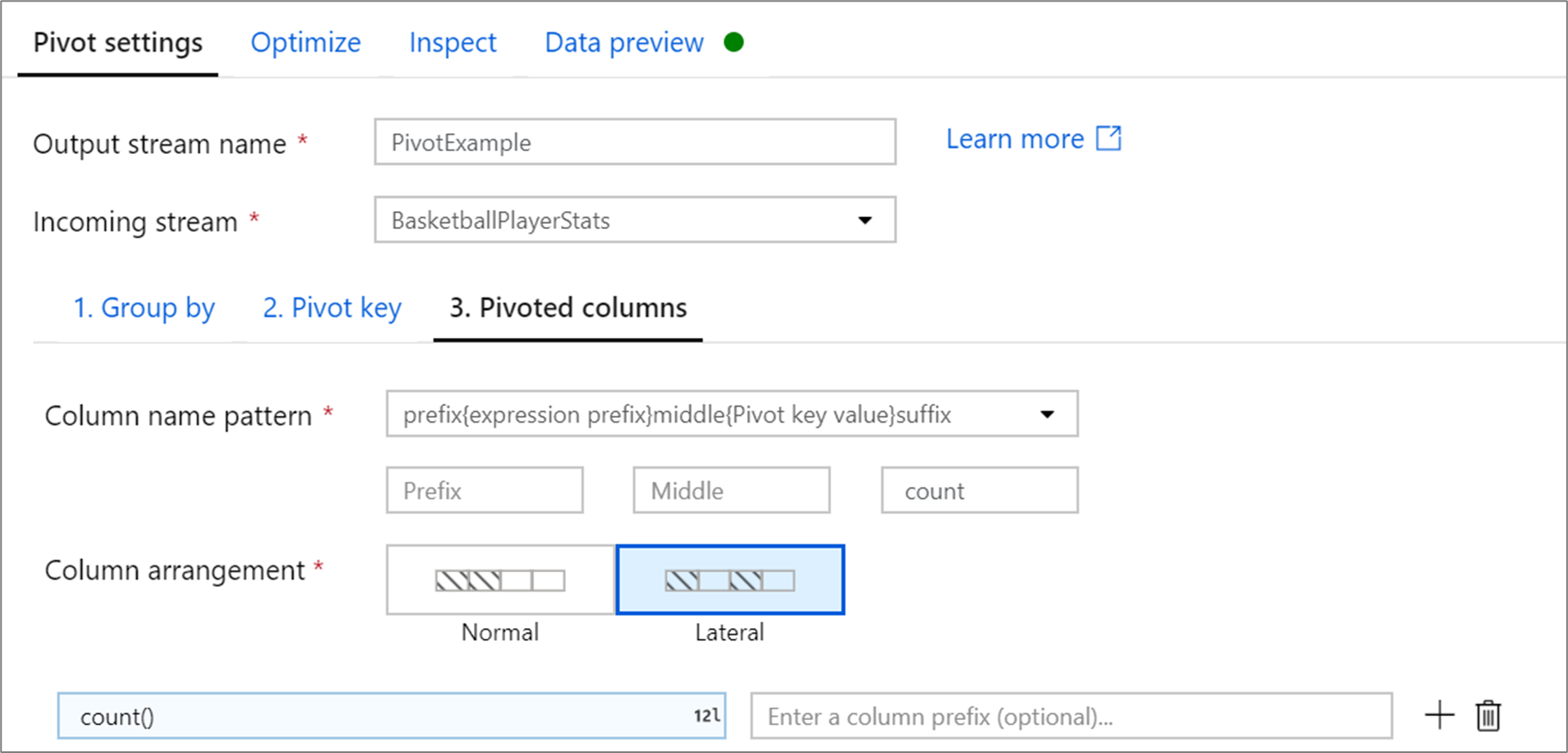
Para cada valor de chave dinâmica exclusivo que se torna uma coluna, gerar um valor de linha agregado para cada grupo. Você pode criar várias colunas por chave dinâmica. Cada coluna de pivô deve conter pelo menos uma função de agregação.
Padrão de nome de coluna: selecione como formatar o nome de cada coluna dinâmica. O nome da coluna de saída é uma combinação do valor da chave de pivô, prefixo da coluna e caracteres opcionais de prefixo, sufixo e intermediário.
Disposição da coluna: se você gerar mais de uma coluna dinâmica por chave dinâmica, escolha como deseja que as colunas sejam ordenadas.
Prefixo da coluna: Se você gerar mais de uma coluna de pivô por chave de pivô, insira um prefixo de coluna para cada coluna. Essa configuração será opcional se você tiver apenas uma coluna dinâmica.
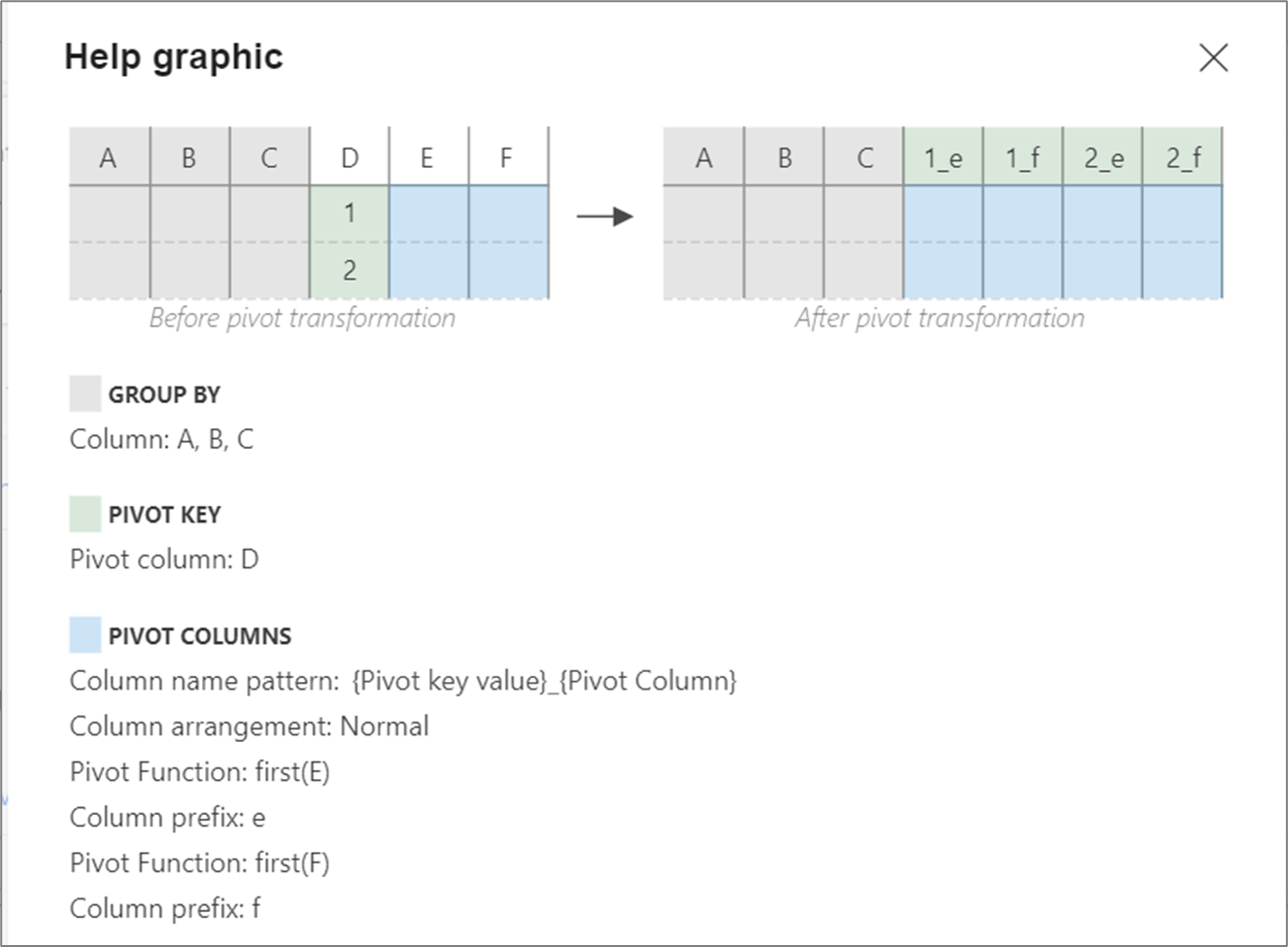
Gráfico de ajuda
O gráfico de ajuda mostra como os diferentes componentes do pivô interagem entre si
Metadados dinâmicos
Se nenhum valor for especificado na configuração da chave de pivot, as colunas pivotadas serão geradas dinamicamente em tempo de execução. O número de colunas pivotadas é igual ao número de valores de chave de pivô exclusivos multiplicado pelo número de colunas de pivô. Como esse número pode mudar, a experiência do usuário não exibe os metadados da coluna na guia Inspecionar e não há propagação de coluna. Para transformar essas colunas, use os recursos de padrão de coluna do fluxo de dados mapeados.
Se valores específicos de chave dinâmica forem definidos, as colunas dinâmicas aparecerão nos metadados. Os nomes das colunas estão disponíveis para você no mapeamento Inspecionar e Destino.
Gerar metadados de colunas descompassadas
Pivot gera novos nomes de colunas com base nos valores de linha de forma dinâmica. Você pode adicionar essas novas colunas aos metadados que podem ser referenciadas posteriormente no fluxo de dados. Para isso, use a ação rápida map drifted (mapa descompassado) na visualização de dados.
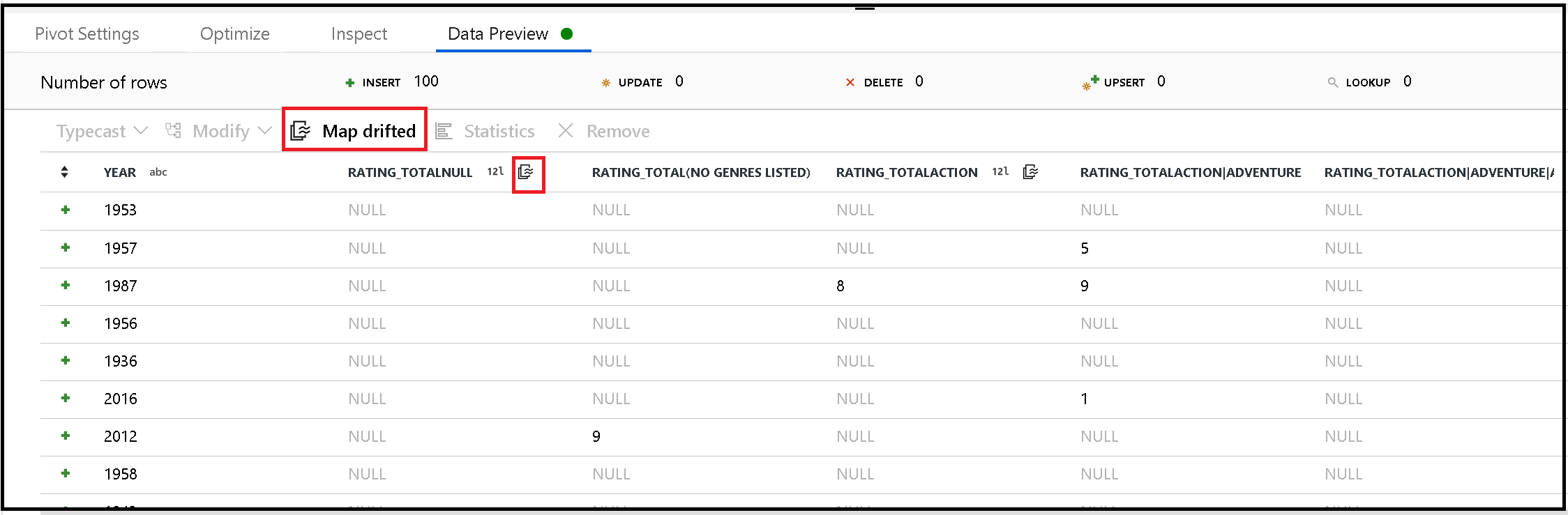
Colunas dinamizadas no coletor
Embora as colunas pivotadas sejam dinâmicas, elas ainda podem ser gravadas no seu armazenamento de dados de destino. Habilite Allow schema drift (Permitir descompasso de esquema) nas configurações do coletor. Isso permite que você escreva colunas que não estão incluídas nos metadados. Você não verá os novos nomes dinâmicos nos metadados da coluna, mas a opção de desvio de esquema permite que você insira os dados.
Reingressar nos campos originais
A transformação de pivô projeta apenas as colunas de agrupamento e as colunas pivotadas. Para que os dados de saída incluam outras colunas de entrada, use um padrão de autojunção.
Script de fluxo de dados
Sintaxe
<incomingStreamName>
pivot(groupBy(Tm),
pivotBy(<pivotKeyColumn, [<specifiedColumnName1>,...,<specifiedColumnNameN>]),
<pivotColumnPrefix> = <pivotedColumnValue>,
columnNaming: '< prefix >< $N | $V ><middle >< $N | $V >< suffix >',
lateral: { 'true' | 'false'}
) ~> <pivotTransformationName
Exemplo
As telas mostradas na seção de configuração têm o seguinte script de fluxo de dados:
BasketballPlayerStats pivot(groupBy(Tm),
pivotBy(Pos),
{} = count(),
columnNaming: '$V$N count',
lateral: true) ~> PivotExample
Conteúdo relacionado
Experimente a transformação unpivot para transformar valores de coluna em valores de linha.