Solucionar problemas de conector e formato nos fluxos de dados de mapeamento no Azure Data Factory
Este artigo explora os métodos de solução de problemas relacionados ao conector e ao formato para fluxos de dados de mapeamento no ADF (Azure Data Factory).
Armazenamento do Blobs do Azure
O tipo de armazenamento da conta (uso geral v1) não dá suporte à autenticação de MI e à entidade de serviço
Sintomas
Em fluxos de dados, caso use o Armazenamento de Blobs do Azure (uso geral v1) com a entidade de serviço ou a autenticação de Identidade Gerenciada, poderá encontrar a seguinte mensagem de erro:
com.microsoft.dataflow.broker.InvalidOperationException: ServicePrincipal and MI auth are not supported if blob storage kind is Storage (general purpose v1)
Causa
Ao usar o serviço vinculado de Blobs do Azure no fluxo de dados, a identidade gerenciada ou a autenticação da entidade de serviço não tem suporte quando o tipo de conta está vazio ou definido como Armazenamento. Essa situação é mostrada nas Imagens 1 e 2 abaixo.
Imagem 1: O tipo de conta no serviço vinculado do Armazenamento de Blobs do Azure
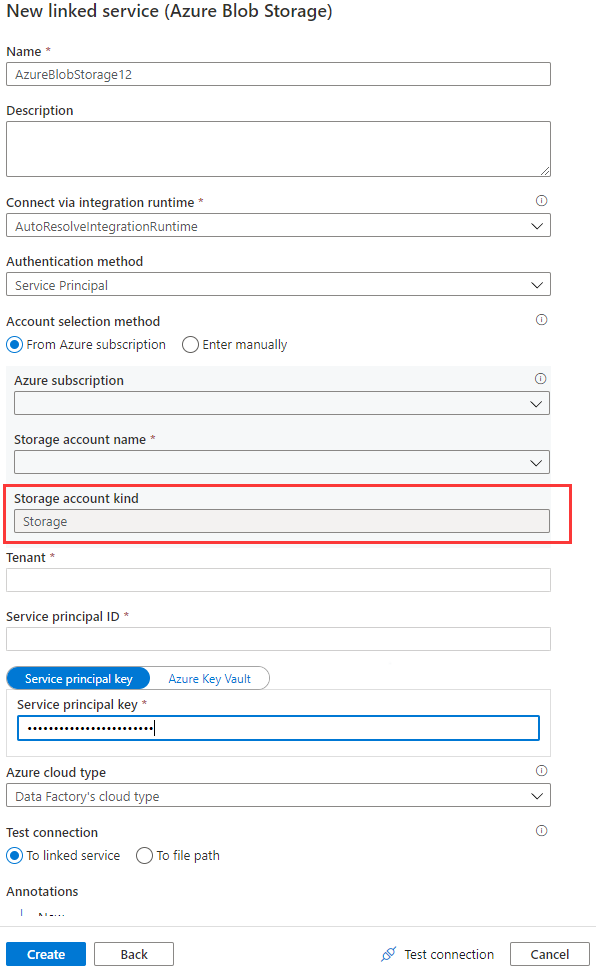
Imagem 2: Página da conta de armazenamento

Recomendação
Para resolver este problema, siga as seguintes recomendações:
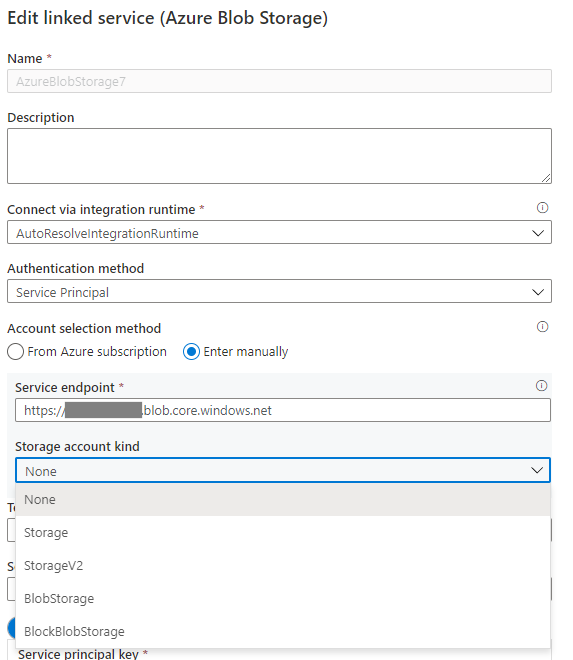
Se o tipo de conta de armazenamento for definido como Nenhum no serviço vinculado de Blob do Azure, especifique o tipo de conta adequado e consulte a Imagem 3 a seguir para realizá-lo. Além disso, consulte a Imagem 2 para obter o tipo de conta de armazenamento, e verifique e confirme se o tipo de conta não está definido como Armazenamento (uso geral v1).
Imagem 3: Especifique o tipo de conta de armazenamento no serviço vinculado do Armazenamento de Blobs do Azure
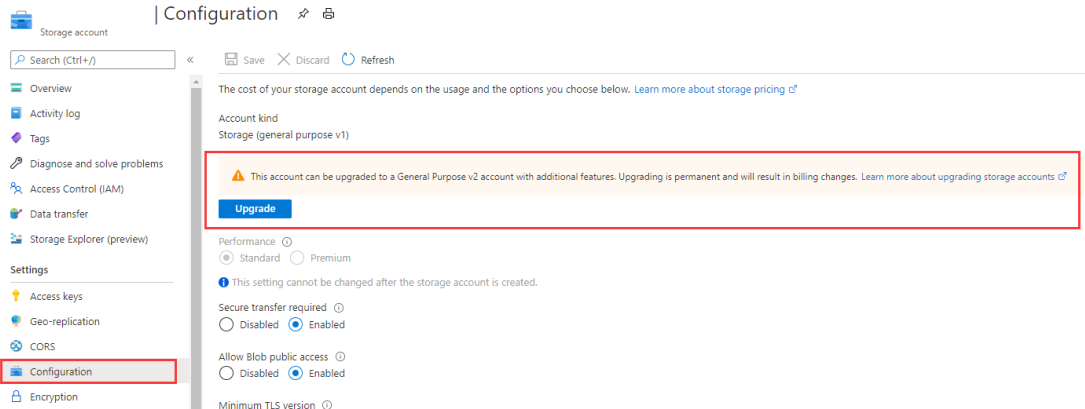
Se o tipo de conta estiver definida como Armazenamento (uso geral v1), atualize sua conta de armazenamento para a finalidade uso geral v2, ou escolha uma autenticação diferente.
Imagem 4: Atualizar a conta de armazenamento para uso geral v2

Formato JSON e Azure Cosmos DB
Suporte a esquemas personalizados na origem
Sintomas
Ao usar o fluxo de dados do ADF para mover ou transferir dados do Azure Cosmos DB/do JSON para outros armazenamentos de dados, algumas colunas dos dados de origem poderão ser perdidas.
Causa
Para os conectores sem esquema (o número da coluna, o nome da coluna e o tipo de dados da coluna de cada linha podem ser diferentes ao comparar com os outros), por padrão, o ADF usa linhas de amostra (por exemplo, dados das 100 ou mil primeiras linhas) para inferir o esquema, e o resultado inferido é usado como um esquema para ler os dados. Portanto, se os armazenamentos de dados tiverem colunas adicionais que não são exibidas nas linhas de amostra, os dados dessas colunas adicionais não serão lidos, movidos nem transferidos para os armazenamentos de dados do coletor.
Recomendação
Para substituir o comportamento padrão e inserir outros campos, o ADF fornece opções para personalizar o esquema de origem. Você pode especificar colunas adicionais/ausentes que podem estar ausentes no schema-infer-result na projeção de origem do fluxo de dados para ler os dados e você pode aplicar uma das opções a seguir para definir o esquema personalizado. Normalmente, Option-1 é preferencial.
Opção 1: em comparação aos dados de origem originais que podem ser um arquivo grande, uma tabela ou um contêiner com milhões de linhas com esquemas complexos, é possível criar uma tabela/contêiner temporário com algumas linhas que contêm todas as colunas que você deseja fazer a leitura e, em seguida, passar para a seguinte operação:
Use as configurações de depuração da fonte de fluxo de dados para Importar projeção com arquivos/tabelas de exemplo para obter o esquema completo. Você pode seguir as etapas na imagem abaixo:
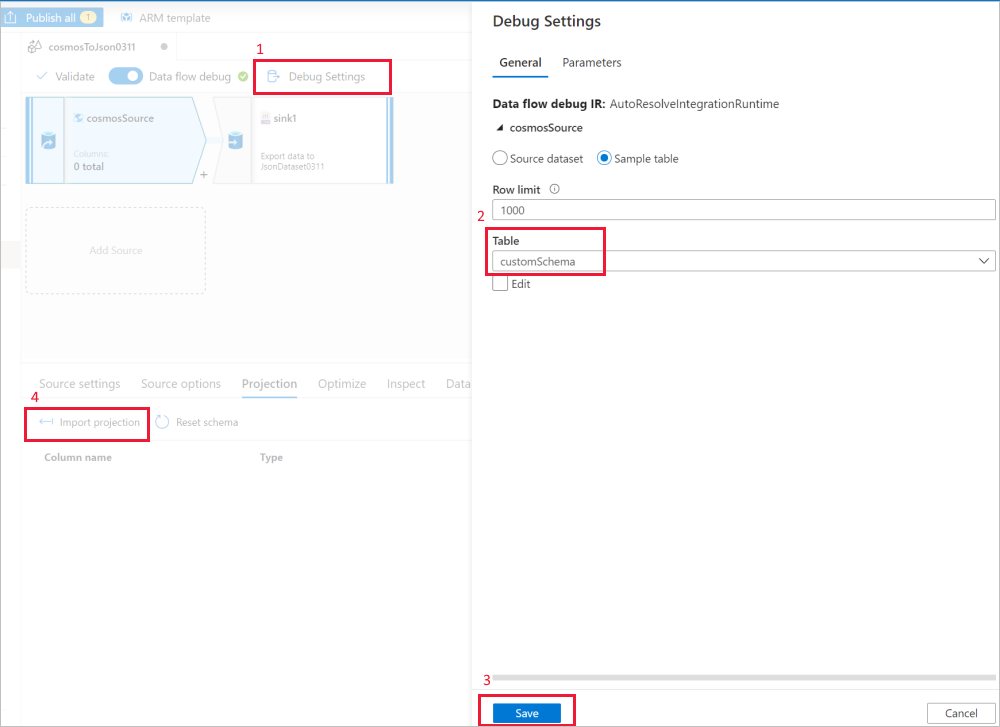
- Selecione Configurações de depuração na tela de fluxo de dados.
- No painel pop-up, selecione Tabela de exemplo na guia cosmosSource e insira o nome da tabela no bloco Tabela.
- Selecione salvar para salvar suas configurações.
- Selecione Importar projeção.
Altere as Configurações de Depuração novamente para usar o conjunto de dados de origem para a movimentação/transformação de dados restantes. Você pode prosseguir com as etapas na imagem abaixo:
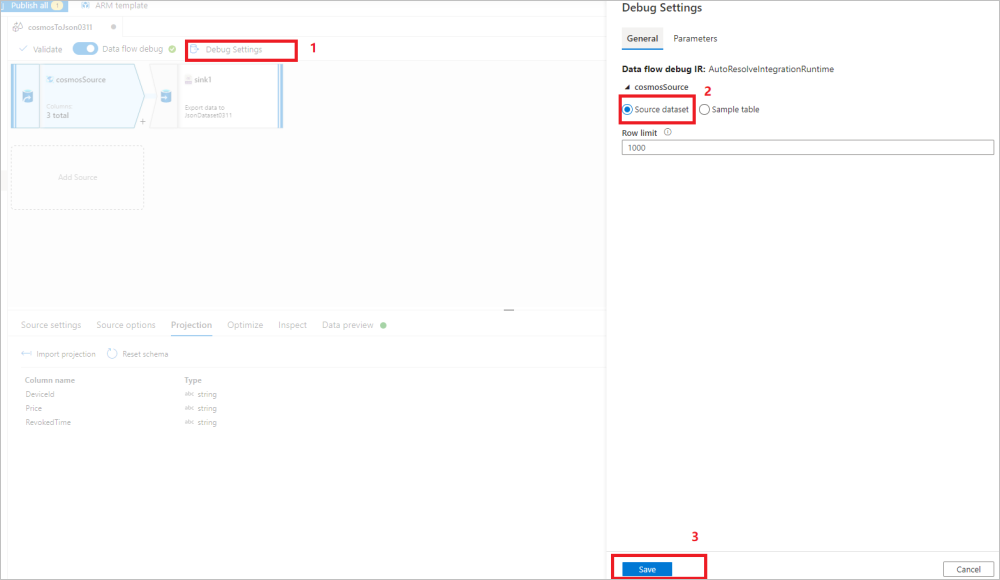
- Selecione Configurações de depuração na tela de fluxo de dados.
- No painel pop-up, selecione Conjunto de fonte de origem na guia cosmosSource.
- Selecione salvar para salvar suas configurações.
Posteriormente, o runtime do fluxo de dados do ADF honrará e usará o esquema personalizado para ler os dados do armazenamento de dados original.
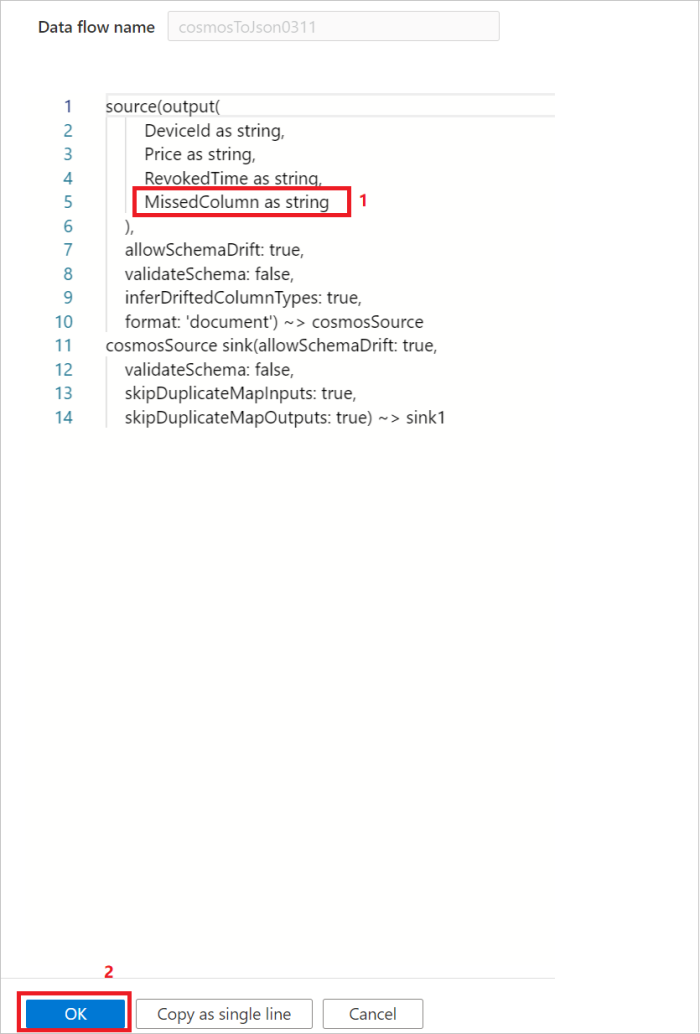
Opção 2: caso esteja familiarizado com o esquema e a linguagem DSL dos dados de origem, você poderá atualizar manualmente o script de origem do fluxo de dados para incluir colunas adicionais/ausentes para ler os dados. Um exemplo é mostrado na imagem a seguir:
Tipo de mapa de suporte na origem
Sintomas
Em fluxos de dados do ADF, o tipo de dados de mapa não pode ter suporte diretamente na fonte JSON ou Azure Cosmos DB. Portanto, não é possível obter o tipo de dados de mapa em “Importar projeção”.
Causa
Para o Azure Cosmos DB e o JSON, eles usam uma conectividade livre de esquema, e o conector do Spark relacionado usa dados de amostra para inferir o esquema, que é usado como o esquema de origem do Azure Cosmos DB/do JSON. Ao inferir o esquema, o conector do Spark do Azure Cosmos DB/do JSON só poderá inferir os dados de objeto como um struct, em vez de um tipo de dados de mapa. É por isso que não há suporte direto para o tipo de dados de mapa.
Recomendação
Para resolver esse problema, veja os exemplos e as etapas a seguir para atualizar manualmente o script (DSL) da fonte Azure Cosmos DB/JSON e obter o suporte ao tipo de dados de mapa.
Exemplos:

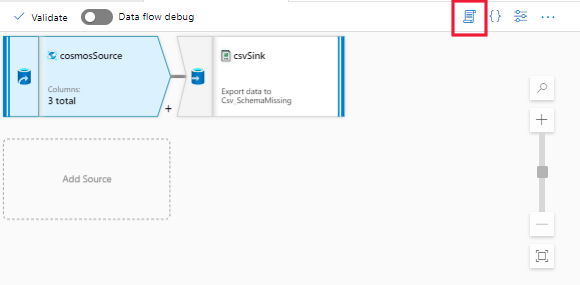
Etapa 1: abra o script da atividade de fluxo de dados.
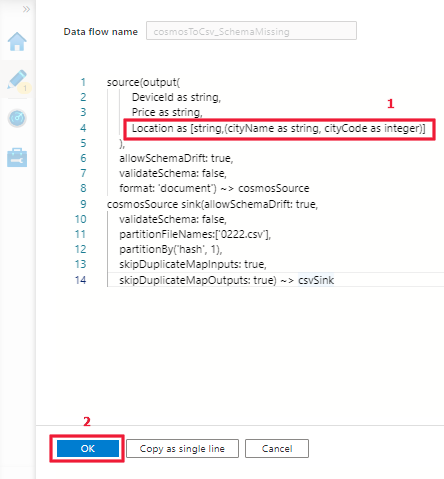
Etapa 2: atualize o DSL para obter o suporte do tipo de mapa conferindo os exemplos acima.
O suporte do tipo de mapa:
| Tipo | O tipo de mapa tem suporte? | Comentários |
|---|---|---|
| Excel, CSV | Não | Ambos são fontes de dados tabulares com o tipo primitivo. Portanto, não há necessidade de dar suporte ao tipo de mapa. |
| Orc, Avro | Sim | Nenhum. |
| JSON | Yes | Não há suporte para o tipo de mapa diretamente. Siga a parte de recomendação nesta seção para atualizar o script (DSL) na projeção de origem. |
| Azure Cosmos DB | Yes | Não há suporte para o tipo de mapa diretamente. Siga a parte de recomendação nesta seção para atualizar o script (DSL) na projeção de origem. |
| Parquet | Yes | Atualmente, não há suporte para o tipo de dados complexo no conjunto de dados parquet. Portanto, use “Importar projeção” na origem do parquet do fluxo de dados para obter o tipo de mapa. |
| XML | Não | Nenhum. |
Consumir arquivos JSON gerados por atividades Copy
Sintomas
Se você usar a atividade Copy para gerar alguns arquivos JSON e tentar lê-los em fluxos de dados, ocorrerá uma falha com a mensagem de erro: JSON parsing error, unsupported encoding or multiline
Causa
O JSON para fluxos de dados e cópia apresenta as seguintes limitações, respectivamente:
Para codificações de arquivos JSON Unicode (utf-8, utf-16, utf-32), as atividades Copy sempre geram os arquivos JSON com marca de ordem de byte.
A fonte JSON do fluxo de dados com "Documento único" habilitado não dá suporte à codificação Unicode com marca de ordem de byte.
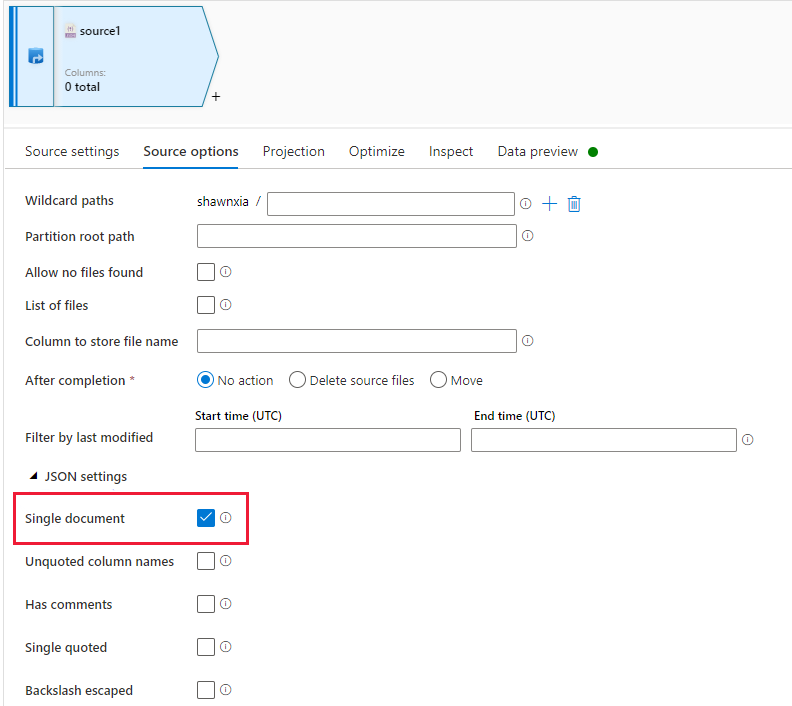
Problemas poderão surgir caso os seguintes critérios sejam atendidos:
O conjunto de dados do coletor usado pela atividade Copy esteja definido como codificação Unicode (utf-8, utf-16, utf-16be, utf-32, utf-32be) ou o padrão seja usado.
O coletor do Copy está definido para usar o padrão de arquivo "Matriz de objetos", conforme mostrado na imagem a seguir, independentemente se "Documento único" esteja ou não habilitado na fonte JSON do fluxo de dados.
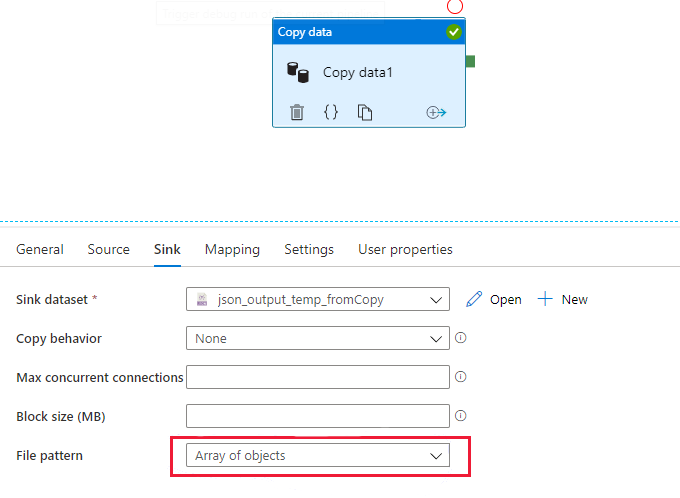
Recomendação
- Sempre use o modelo de arquivo padrão ou o padrão "Conjunto de objetos" explícito no coletor do Copy caso os arquivos gerados sejam usados em fluxos de dados.
- Desabilite a opção "Documento único" na fonte JSON do fluxo de dados.
Observação
Usar "Conjunto de objetos" também é a prática recomendada pela perspectiva do desempenho. Como o JSON do "Documento único" no fluxo de dados não pode habilitar a leitura paralela para arquivos únicos grandes, essa recomendação não traz nenhum impacto negativo.
A consulta com parâmetros não funciona
Sintomas
Os fluxos de dados de mapeamento no Azure Data Factory dão suporte ao uso de parâmetros. Os valores de parâmetro são definidos pelo pipeline de chamada via atividade Executar Fluxo de Dados. O uso de parâmetros é uma boa maneira de tornar os fluxos de dados de uso geral, flexíveis e reutilizáveis. É possível parametrizar configurações e expressões de fluxo de dados com os estes parâmetros: Parametrizando fluxos de dados de mapeamento.
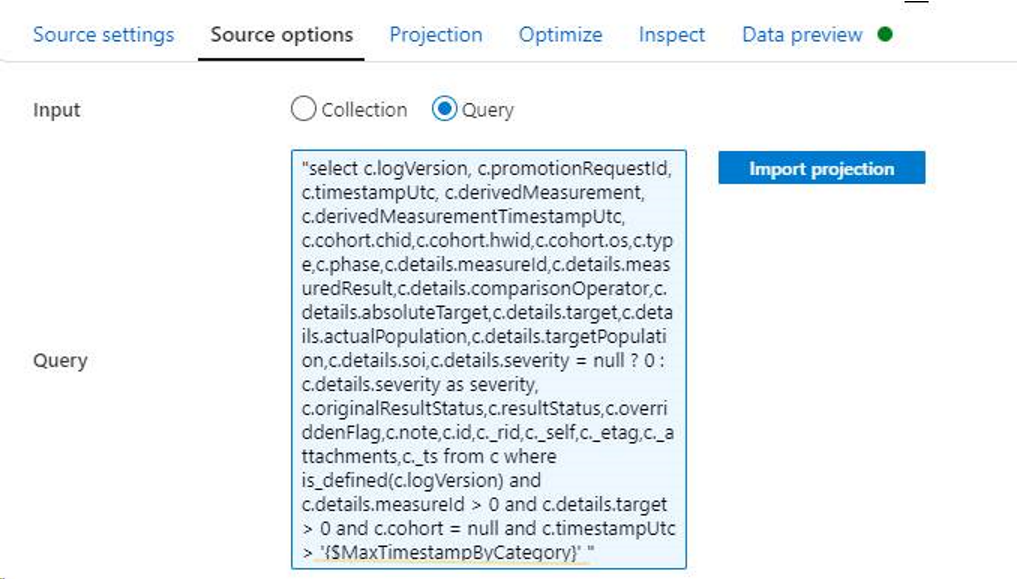
Após definir parâmetros e utilizá-los na consulta da fonte do fluxo de dados, eles não produzem efeito.
Causa
Esse erro ocorre devido a configurações incorretas.
Recomendação
Use as regras a seguir para definir parâmetros na consulta e, para obter informações mais detalhadas, confira Criar expressões no fluxo de dados de mapeamento.
- Insira aspas duplas no início da instrução SQL.
- Coloque o parâmetro entre aspas simples.
- Use letras minúsculas para toda instrução de CLÁUSULA.
Por exemplo:
Azure Data Lake Storage Gen1
Falha ao criar arquivos com autenticação de princípio de serviço
Sintomas
Ao tentar mover ou transferir dados de fontes diferentes para o coletor do ADLS gen1, se o método de autenticação do serviço vinculado for autenticação de princípio de serviço, poderá ocorrer falha no trabalho com a seguinte mensagem de erro:
org.apache.hadoop.security.AccessControlException: CREATE failed with error 0x83090aa2 (Forbidden. ACL verification failed. Either the resource does not exist or the user is not authorized to perform the requested operation.). [2b5e5d92-xxxx-xxxx-xxxx-db4ce6fa0487] failed with error 0x83090aa2 (Forbidden. ACL verification failed. Either the resource does not exist or the user is not authorized to perform the requested operation.)
Causa
A permissão do RWX ou a propriedade do conjunto de dados não está definida corretamente.
Recomendação
Se a pasta de destino não tiver as permissões corretas, consulte este documento para atribuir a permissão correta em Gen1: Usar autenticação de entidade de serviço.
Se a pasta de destino tiver a permissão correta e você usar a propriedade de nome de arquivo no fluxo de dados para direcionar para a pasta e para o nome do arquivo corretos, mas a propriedade caminho do arquivo do conjunto de dados não estiver definida como o caminho do arquivo de destino (geralmente deixada sem definir), como mostra o exemplo nas imagens a seguir, você encontrará essa falha porque o sistema de back-end tenta criar arquivos com base no caminho do arquivo do conjunto de dados, e ele não possui a permissão correta.
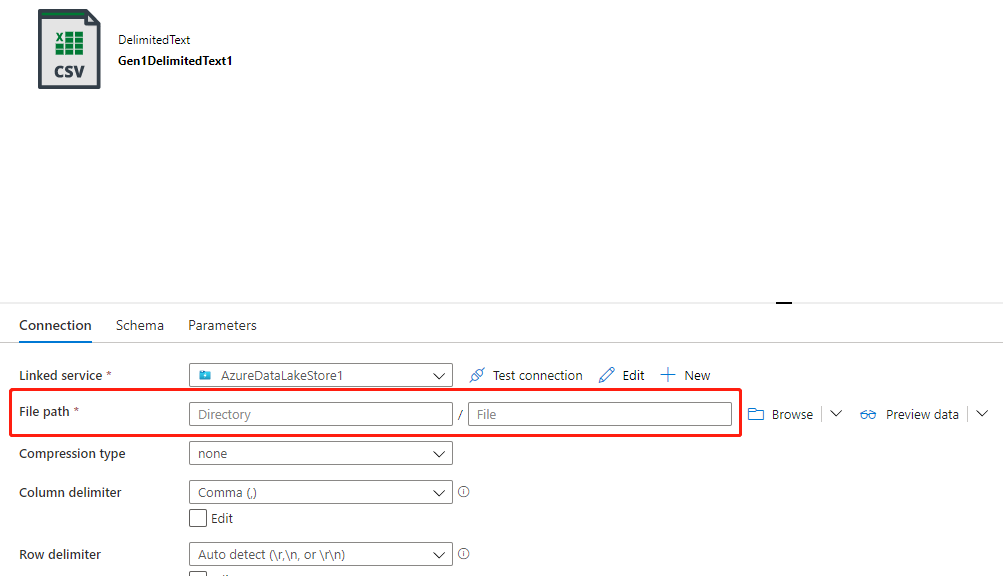
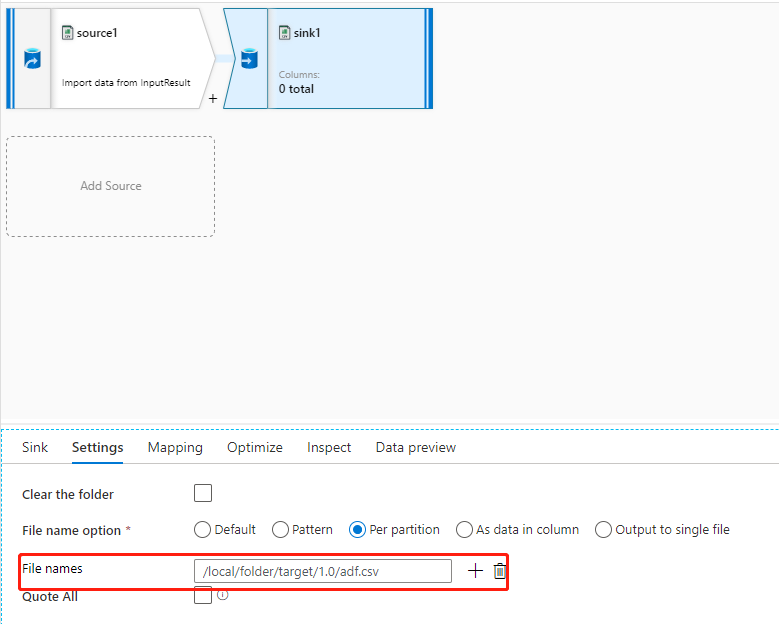
Há dois métodos para resolver este problema:
- Atribua a permissão WX ao caminho do arquivo do conjunto de dados.
- Defina o caminho do arquivo do conjunto de dados como a pasta com permissão WX, e defina o caminho da pasta rest e o nome do arquivo em fluxos de dados.
Azure Data Lake Storage Gen2
Falha com um erro: "Erro ao ler o arquivo XXX. É possível que os arquivos subjacentes tenham sido atualizados.”
Sintomas
Ao usar o ADLS Gen2 como um coletor no fluxo de dados (para pré-visualizar dados, depurar/executar gatilhos etc.) e a configuração de partição no guia Otimizar no preparo do Coletor não for padrão, você poderá encontrar falha no trabalho com a seguinte mensagem de erro:
Job failed due to reason: Error while reading file abfss:REDACTED_LOCAL_PART@prod.dfs.core.windows.net/import/data/e3342084-930c-4f08-9975-558a3116a1a9/part-00000-tid-7848242374008877624-5df7454e-7b14-4253-a20b-d20b63fe9983-1-1-c000.csv. It is possible the underlying files have been updated. You can explicitly invalidate the cache in Spark by running 'REFRESH TABLE tableName' command in SQL or by recreating the Dataset/DataFrame involved.
Causa
- Você não atribui uma permissão adequada à autenticação MI/SP.
- Você pode ter um trabalho personalizado para lidar com arquivos indesejados, o que afetará a saída intermediária do fluxo de dados.
Recomendação
- Verifique se o serviço vinculado tem a permissão R/W/E para Gen2. Se você usar a autenticação MI/SP, conceda ao menos a função Colaborador de Dados do Blob de Armazenamento no controle de Acesso (IAM).
- Confirme se há trabalhos específicos que movem/excluem arquivos para outro lugar cujo nome não corresponder à regra. Como os fluxos de dados primeiro gravam os arquivos de partição na pasta de destino e, em seguida, fazem as operações de mesclagem e renomeação, o nome do arquivo do meio poderá não corresponder à regra.
Banco de Dados do Azure para PostgreSQL
Encontrar um erro: Falha com a exceção: handshake_failure
Sintomas
Você usa o PostgreSQL do Azure como uma fonte ou um coletor no fluxo de dados, como na pré-visualização de dados e na depuração/execução de gatilho, e você poderá encontrar falha no trabalho com a seguinte mensagem de erro:
PSQLException: SSL error: Received fatal alert: handshake_failure
Caused by: SSLHandshakeException: Received fatal alert: handshake_failure.
Causa
Caso use o servidor flexível ou a Hiperescala (Citus) para o servidor PostgreSQL do Azure, como o sistema é criado via Spark no cluster do Azure Databricks, há uma limitação no Azure Databricks que bloqueia o nosso sistema para se conectar ao servidor flexível ou à Hiperescala (Citus). Você pode revisar os dois links a seguir como referências.
Falha no handshake ao tentar se conectar do Azure Databricks ao Azure PostgreSQL com SSL
Dados-MCW-em-tempo-real-com-o-Azure-Database-para-Hiperescala-PostgreSQL
Consulte o conteúdo na imagem a seguir neste artigo: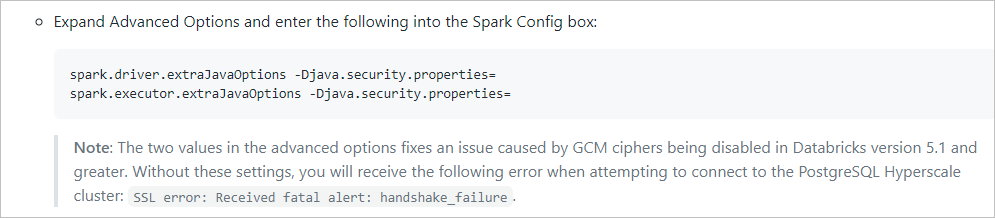
Recomendação
Você pode tentar usar as atividades Copy para desbloquear esse problema.
Banco de Dados SQL do Azure
Não é possível conectar-se ao Banco de Dados SQL
Sintomas
O Banco de Dados SQL do Azure pode funcionar bem na cópia de dados, na preview-data dos conjuntos de dados e no test-connection do serviço vinculado, mas falhará quando o mesmo Banco de Dados SQL do Azure for usado como uma origem ou um coletor no fluxo de dados com erro como: Cannot connect to SQL database: 'jdbc:sqlserver://powerbasenz.database.windows.net;..., Please check the linked service configuration is correct, and make sure the SQL database firewall allows the integration runtime to access.'
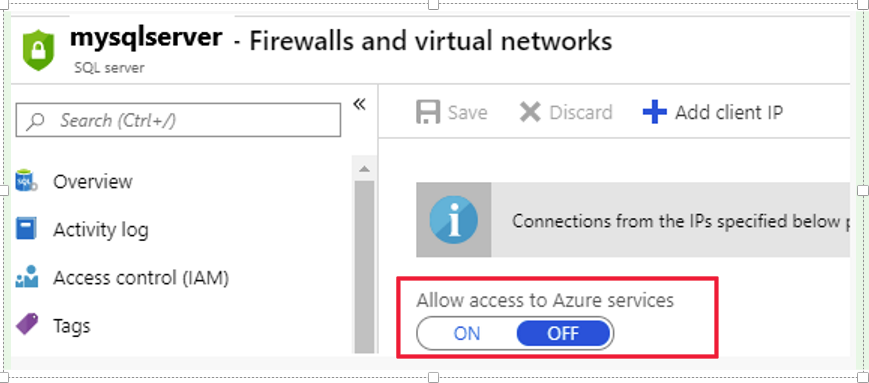
Causa
Há configurações de firewall incorretas no servidor do Banco de Dados SQL do Azure, impedindo-o de ser conectado pelo runtime do fluxo de dados. Atualmente, ao tentar usar o fluxo de dados para fazer leitura/gravar no Banco de Dados SQL do Azure, o Azure Databricks é usado para criar um cluster do Spark para executar o trabalho, mas não dá suporte a intervalos de IP fixos. Para obter mais detalhes, consulte Endereços de IP do Azure Integration Runtime.
Recomendação
Verifique as configurações de firewall do seu Banco de Dados SQL do Azure, e configure-o para "Permitir acesso aos serviços do Azure" em vez de definir o intervalo de IP fixo.
Erro de sintaxe ao usar consultas como entrada
Sintomas
Ao usar consultas como entrada na fonte do fluxo de dados com o SQL do Azure, ocorre uma falha com a seguinte mensagem de erro:
at Source 'source1': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: Incorrect syntax XXXXXXXX.
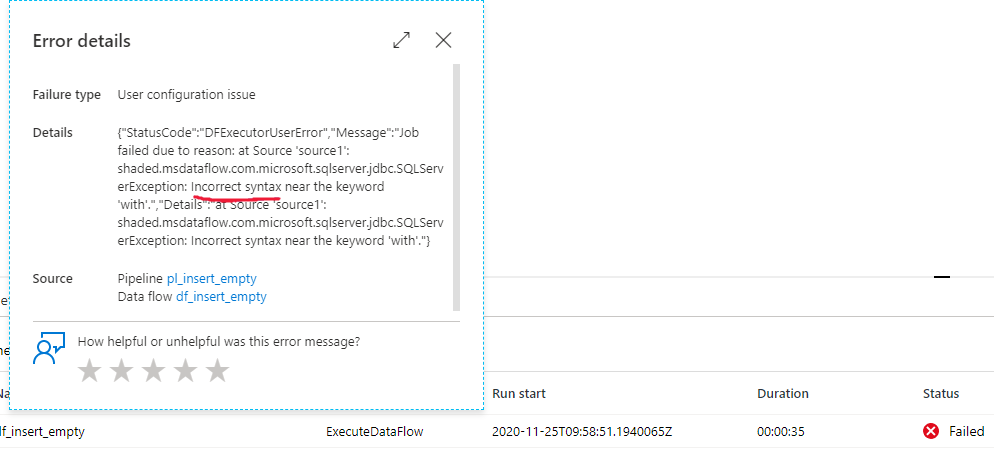
Causa
A consulta usada na fonte do fluxo de dados deve ser capaz de ser executado como uma subconsulta. O motivo da falha é que a sintaxe de consulta está incorreta ou não pode ser executada como uma subconsulta. Você pode executar a seguinte consulta no SSMS para verificar:
SELECT top(0) * from ($yourQuery) as T_TEMP
Recomendação
Forneça uma consulta correta e teste-a primeiro no SSMS.
Falha com um erro: “SQLServerException: 111212; A operação não pode ser executada em uma transação.”
Sintomas
Ao usar o Banco de Dados SQL do Azure como um coletor no fluxo de dados para pré-visualizar dados, depurar/executar gatilhos e executar outras atividades, poderá encontrar falha no trabalho com a seguinte mensagem de erro:
{"StatusCode":"DFExecutorUserError","Message":"Job failed due to reason: at Sink 'sink': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: 111212;Operation cannot be performed within a transaction.","Details":"at Sink 'sink': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: 111212;Operation cannot be performed within a transaction."}
Causa
O erro "111212;Operation cannot be performed within a transaction." ocorre apenas no pool de SQL dedicado do Synapse. Mas, por engano, você usa o Banco de Dados SQL do Azure como o conector.
Recomendação
Confirme se o Banco de Dados SQL é um pool de SQL dedicado do Synapse. Nesse caso, use o Azure Synapse Analytics como um conector mostrado na imagem seguinte.
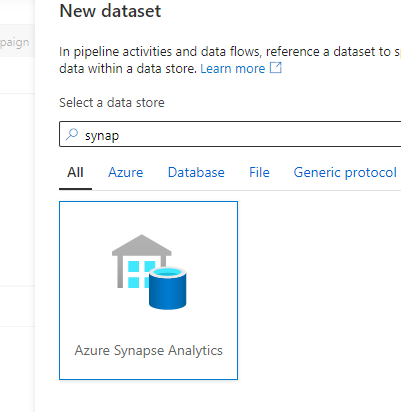
Os dados com o tipo decimal tornam-se nulos
Sintomas
Você deseja inserir dados em uma tabela no banco de dados SQL. Se os dados contiverem o tipo decimal e precisarem ser inseridos em uma coluna com o tipo decimal no banco de dados SQL, o valor dos dados poderá ser alterado para nulo.
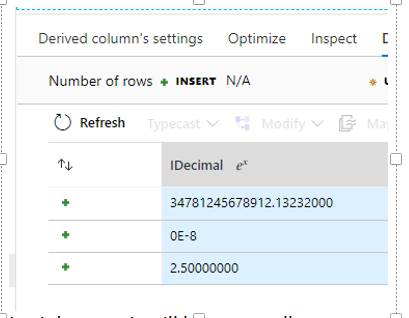
Caso faça a pré-visualização, nos preparos anteriores, ela mostrará o valor como na imagem a seguir:
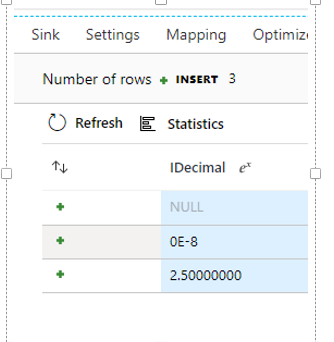
No estágio do coletor, ele se torna nulo, que é mostrado na imagem a seguir.
Causa
O tipo decimal tem propriedades de escala e precisão. Se o tipo de dados não corresponder a isso na tabela do coletor, o sistema validará se o decimal de destino é maior que o decimal original e o valor original não estoura no decimal de destino. Portanto, o valor é convertido em nulo.
Recomendação
Verifique e compare o tipo decimal entre dados e tabela no banco de dados SQL, e altere a escala e a precisão para o mesmo.
Você pode usar o toDecimal (IDecimal, escala, precisão) para descobrir se os dados originais podem ser convertidos para a escala e a precisão de destino. Se retornar nulo, isso significa que os dados não podem ser convertidos e impulsionado durante a inserção.
Azure Synapse Analytics
Problemas relacionados ao pool sem servidor (SQL sob demanda)
Sintomas
Você usa o Azure Synapse Analytics e o serviço vinculado é, na verdade, um pool sem servidor Synapse. Seu nome anterior é pool de SQL sob demanda e é possível distingui-lo encontrando o nome do servidor que contém ondemand, por exemplo, space-ondemand.sql.azuresynapse.net. Você poderá enfrentar várias falhas exclusivas, como estas:
- Quando quiser usar o pool sem servidor do Synapse como um coletor, você encontrará o seguinte erro:
Sink results in 0 output columns. Please ensure at least one column is mapped - Ao selecionar ' habilitar preparo ' na Origem, você encontrará o seguinte erro:
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: Incorrect syntax near 'IDENTITY'. - Quando desejar buscar dados de uma tabela externa, você encontrará o seguinte erro:
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: External table 'dbo' is not accessible because location does not exist or it is used by another process. - Quando você quiser buscar dados do Azure Cosmos DB por meio de um pool sem servidor por consulta/por meio da exibição, você encontrará o seguinte erro:
Job failed due to reason: Connection reset. - Quando quiser buscar dados de uma exibição, poderá encontrar erros diferentes.
Causa
As causas dos sintomas são indicadas respectivamente aqui:
- O pool sem servidor não pode ser usado como coletor. Ele não dá suporte à gravação de dados no banco de dados.
- O pool sem servidor não dá suporte ao carregamento de dados preparados, portanto, não há suporte para “habilitar preparo”.
- O método de autenticação utilizado não possui uma permissão correta para a fonte de dados externa para a qual se refere a tabela externa.
- Há uma limitação conhecida no pool sem servidor do Azure Synapse que bloqueia a busca de dados do Azure Cosmos DB no fluxo de dados.
- A exibição é uma tabela virtual baseada em uma instrução SQL. A causa raiz está dentro da instrução da exibição.
Recomendação
Você pode aplicar as etapas a seguir para resolver seus problemas de forma similar.
É preferível não usar o pool sem servidor como coletor.
Não use “habilitar preparo” na Origem para o pool sem servidor.
Somente a entidade de serviço/identidade gerenciada que possui a permissão para os dados da tabela externa pode consultá-la. Conceda a permissão de “Colaborador de Dados de Blob de Armazenamento” à fonte de dados externa para o método de autenticação que você usa no ADF.
Observação
A autenticação de senha de usuário não pode consultar tabelas externas. Para saber mais, confira Modelo de segurança.
Use a atividade Copy para buscar dados do Azure Cosmos DB do pool sem servidor.
Você pode fornecer a instrução SQL que cria a exibição à equipe de suporte de engenharia e eles podem ajudar a analisar, caso a instrução tenha um problema de autenticação ou algum outro problema.
O carregamento de dados de tamanho pequeno sem preparo para o Data Warehouse está lento
Sintomas
Carregar dados pequenos sem preparo para o Data Warehouse leva muito tempo para ser concluído. Por exemplo, o tamanho dos dados é de 2 MB, mas leva mais de uma hora para ser concluído.
Causa
A contagem de linhas em vez do tamanho causa esse problema. A contagem de linhas tem alguns milhares e cada inserção precisa ser empacotada em uma solicitação independente, ir para o nó de controle, iniciar uma nova transação, obter bloqueios e ir para o nó de distribuição, repetidamente. O carregamento em massa obtém o bloqueio uma vez, e cada nó de distribuição executa a inserção enviando com eficiência o lote para a memória.
Se 2 MB forem inseridos como apenas alguns registros, seria rápido. Por exemplo, seria rápido se cada registro for 500 KB * 4 linhas.
Recomendação
Você precisa habilitar o preparo para melhorar o desempenho.
Ler o valor da cadeia de caracteres vazia ("") como NULL com a habilitação de preparo
Sintomas
Ao usar o Synapse como uma origem no fluxo de dados, como na pré-visualização de dados e na depuração/execução de gatilho e habilitar o preparo para usar o PolyBase, se o valor da coluna contiver um valor de cadeia de caracteres vazio (""), ele será alterado para null.
Causa
O back-end do fluxo de dados usa o Parquet como o formato PolyBase, e há uma limitação conhecida no pool de SQL do Synapse Gen2, que altera automaticamente o valor da cadeia de caracteres vazia para null.
Recomendação
Você pode tentar resolver esse problema pelos seguintes métodos:
- Se o tamanho dos seus dados não for muito grande, é possível desabilitar o Habilitar o preparo na Origem, mas o desempenho será afetado.
- Se for necessário habilitar o preparo, é possível usar a função iifNull () para alterar manualmente a coluna específica do valor de cadeia de caracteres de null para vazio.
Erro de identidade de serviço gerenciada
Sintomas
Quando você usa o Synapse como origem/coletor no fluxo de dados para visualizar dados, depurar/executar gatilho etc. e habilitar o preparo para usar o PolyBase, e o serviço vinculado do armazenamento de preparo (BLOB, Gen2, etc.) é criado para usar a autenticação de Identidade Gerenciada (MI), seu trabalho pode falhar com o seguinte erro mostrado na imagem:
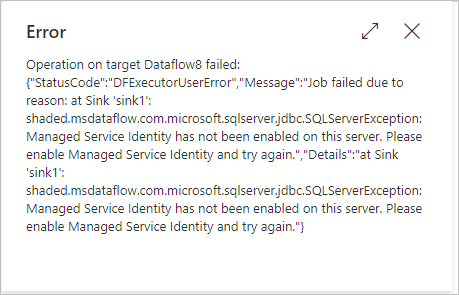
Mensagem de erro
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: Managed Service Identity has not been enabled on this server. Please enable Managed Service Identity and try again.
Causa
- Se o pool de SQL for criado do espaço de trabalho do Synapse, a autenticação da Identidade Gerenciada no armazenamento de preparo com o PolyBase não terá suporte para o pool antigo do SQL.
- Se o pool de SQL for a versão antiga do DWH (Data Warehouse), a Identidade Gerenciada do SQL Server não será atribuída ao armazenamento de preparo.
Recomendação
Confirme se o pool de SQL foi criado no workspace do Azure Synapse.
- Se o pool de SQL foi criado no espaço de trabalho do Azure Synapse, nenhuma etapa extra será necessária. Você não precisa mais registrar novamente a identidade gerenciada (MI) do workspace. A identidade gerenciada atribuída pelo sistema (SA-MI) do workspace é membro da função de Administrador do Synapse e, portanto, tem privilégios elevados nos pools de SQL dedicados do workspace.
- Se o pool de SQL for um pool de SQL dedicado (anteriormente SQL DW) anterior ao Azure Synapse, habilite apenas a Identidade Gerenciada para o servidor SQL e atribua a permissão do repositório de preparo à Identidade Gerenciada do SQL Server. Você pode consultar as etapas neste artigo como exemplo: Usar pontos de extremidade de serviço de rede virtual e regras para servidores no Banco de Dados SQL do Azure.
Falha com um erro: "SQLServerException: Não é possível validar o local externo porque o servidor remoto retornou um erro: (403)"
Sintomas
Ao usar o SQLDW como um coletor para disparar e executar atividades de fluxo de dados, a atividade pode falhar com erro como: "SQLServerException: Not able to validate external location because the remote server returned an error: (403)"
Causa
- Ao usar a identidade gerenciada como preparo no método de autenticação na conta de ADLS Gen2, você poderá não definir corretamente a configuração de autenticação.
- Com o runtime de integração da rede virtual é necessário usar a identidade gerenciada como preparo no método de autenticação na conta de ADLS Gen2. Se o preparo do Armazenamento do Azure estiver configurado com o ponto de extremidade de serviço de rede virtual será necessário usar a autenticação de identidade gerenciada com a opção “permitir serviço confiável da Microsoft” habilitada na conta de armazenamento.
- Verifique se o nome da pasta contém o caractere de espaço ou outros caracteres especiais, por exemplo:
Space " < > # % |. Atualmente, os nomes de pasta que contêm determinados caracteres especiais não têm suporte no comando copiar do Data Warehouse.
Recomendação
Para a Causa 1, você pode consultar o seguinte documento: Usar pontos de extremidade de serviço de rede virtual e regras para servidores no Banco de Dados SQL do Azure-Etapas para resolver esse problema.
Para a Causa 2, você pode solucionar esse problema com uma das seguintes opções:
Opção 1: caso use o runtime de integração da rede virtual, é necessário usar a identidade gerenciada como preparo no método de autenticação na conta de ADLS Gen2.
Opção 2: se o preparo do Armazenamento do Azure estiver configurado com o ponto de extremidade de serviço de rede virtual, será necessário usar a autenticação de identidade gerenciada com a opção “permitir serviço confiável da Microsoft” habilitada na conta de armazenamento. Você pode consultar o documento: Cópia em fases usando o Polybase para obter mais informações.
Para a Causa 3, você pode solucionar esse problema com uma das seguintes opções:
Opção-1: Renomeie a pasta e evite usar caracteres especiais no nome da pasta.
Opção-2: Remova a propriedade
allowCopyCommand:trueno script do fluxo de dados, por exemplo:
Falha com um erro: “shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: o usuário não tem permissão para executar esta ação.”
Sintomas
Quando você usa o Azure Synapse Analytics como uma fonte/coletor e usa o preparo do PolyBase em fluxos de dados, você recebe o seguinte erro:
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: User does not have permission to perform this action.
Causa
O PolyBase requer determinadas permissões em seu servidor do SQL do Synapse para funcionar.
Recomendação
Conceda estas permissões no servidor do SQL do Synapse ao usar o PolyBase:
ALTER ANY SCHEMA
ALTER ANY EXTERNAL DATA SOURCE
ALTER ANY EXTERNAL FILE FORMAT
CONTROL DATABASE
Formato do Common Data Model
Arquivos model.json com caracteres especiais
Sintomas
Você poderá encontrar um problema no qual o nome final do arquivo model.json contém caracteres especiais.
Mensagem de erro
at Source 'source1': java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: PPDFTable1.csv@snapshot=2020-10-21T18:00:36.9469086Z.
Recomendação
Substitua os caracteres especiais no nome do arquivo, que funcionam no Synapse, mas não no ADF.
Nenhuma saída de dados na visualização de dados ou após a execução de pipelines
Sintomas
Quando você usa o manifest.json para CDM, nenhum dado é mostrado na visualização de dados ou após a execução de um pipeline. Somente os cabeçalhos são exibidos. Você pode observar esse problema na imagem abaixo.
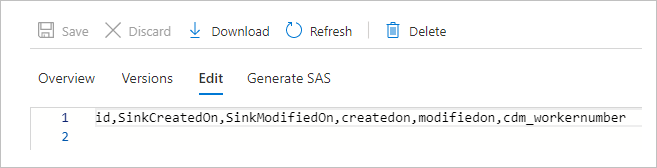
Causa
O documento de manifesto descreve a pasta CDM, por exemplo, quais entidades você tem na pasta, referências dessas entidades, e os dados que correspondem a essa instância. O documento de manifesto perde as informações dataPartitions que indicam ao ADF onde fazer a leitura dos dados e, como eles estão vazios, ele retorna zero dados.
Recomendação
Atualize o documento de manifesto para ter as informações dataPartitions, e você pode consultar este documento de manifesto de exemplo para atualizar seu documento: Metadados de Common Data Model: Introdução ao manifesto - documento de manifesto de exemplo.
Atributos de matriz JSON são inferidos como colunas separadas
Sintomas
Você poderá encontrar um problema no qual um atributo (do tipo cadeia de caracteres) da entidade CDM tenha uma matriz JSON como dados. Quando esses dados são encontrados, o ADF infere incorretamente os dados como colunas separadas. Como é possível ver nas imagens a seguir, um único atributo apresentado na fonte (msfp_otherproperties) é inferido como uma coluna separada na versão prévia do conector do CDM.
Nos dados de origem CSV (consulte a segunda coluna):

Na visualização de dados de origem do CDM:
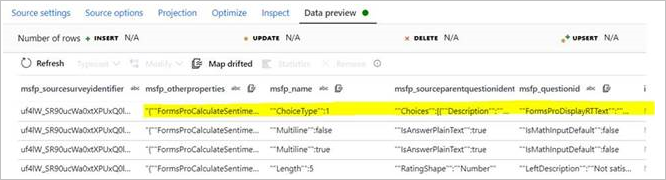
Você também poderá tentar mapear colunas descompassadas e usar a expressão de fluxo de dados para transformar esse atributo em uma matriz. Mas como esse atributo é lido como uma coluna separada durante a leitura, a transformação em matriz não funciona.
Causa
É provável que esse problema seja causado por vírgulas dentro do valor do objeto JSON para essa coluna. Como o arquivo de dados deve ser um arquivo CSV, a vírgula indica que é o fim do valor de uma coluna.
Recomendação
Para resolver esse problema, você precisa colocar a coluna JSON entre aspas duplas, e evitar qualquer uma das aspas internas com uma barra invertida (\). Dessa forma, o conteúdo do valor dessa coluna pode ser lido inteiramente como uma coluna única.
Observação
O CDM não informa que o tipo de dados do valor da coluna é JSON, mas informa que é uma cadeia de caracteres e é analisado como tal.
Não é possível buscar dados na visualização do fluxo de dados
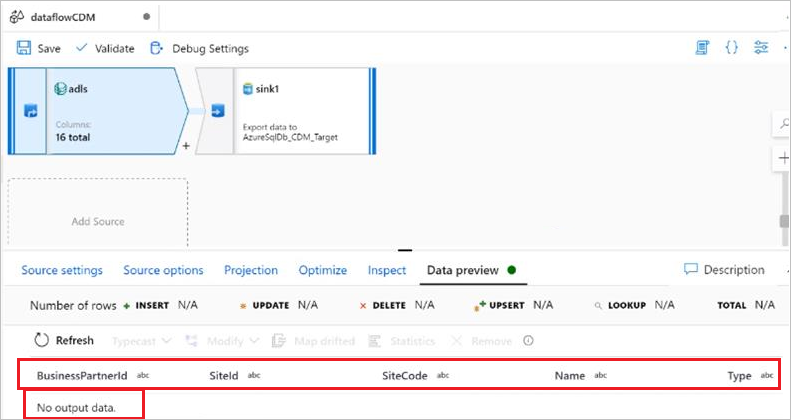
Sintomas
Você usa o CDM com o model.json gerado pelo Power BI. Ao visualizar os dados do CDM usando a visualização do fluxo de dados, ocorre um erro: No output data.
Causa
O código a seguir existe nas partições do arquivo model.json gerado pelo fluxo de dados do Power BI.
"partitions": [
{
"name": "Part001",
"refreshTime": "2020-10-02T13:26:10.7624605+00:00",
"location": "https://datalakegen2.dfs.core.windows.net/powerbi/salesEntities/salesPerfByYear.csv @snapshot=2020-10-02T13:26:10.6681248Z"
}
Para este arquivo model.json, o problema é que o esquema de nomeação do arquivo de partição de dados possui caracteres especiais, e, atualmente, os caminhos de arquivo de suporte com '@' não existem.
Recomendação
Remova a parte @snapshot=2020-10-02T13:26:10.6681248Z do nome do arquivo da partição de dados e do arquivo model.json e tente novamente.
O caminho do corpus é nulo ou está vazio
Sintomas
Ao usar o CDM no fluxo de dados com o formato do modelo, não é possível pré-visualizar os dados e ocorre o erro: DF-CDM_005 The corpus path is null or empty. O erro é mostrado na imagem a seguir:
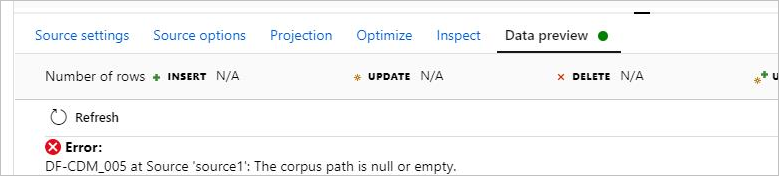
Causa
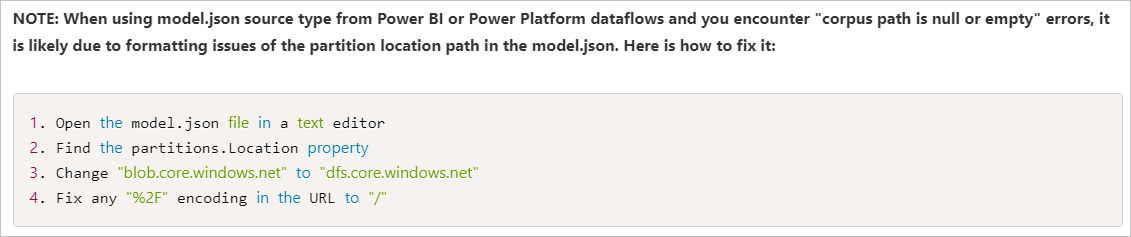
O caminho da partição de dados no model.json aponta para um local de armazenamento de Blobs, e não para o data lake. O local deve ter a URL base de .dfs.core.windows.net para o ADLS Gen2.
Recomendação
Para solucionar esse problema, você pode consultar este artigo: O ADF Adiciona Suporte para Conjuntos de Dados Embutidos e Common Data Model a Fluxos de Dados, e a imagem a seguir mostra a maneira de corrigir o erro de caminho do corpus neste artigo.
Não é possível ler arquivos de dados CSV
Sintomas
Você usa o conjunto de dados embutido como o modelo de dados comum com o manifesto como fonte e fornece o arquivo de manifesto de entrada, o caminho raiz, o nome da entidade e o caminho. No manifesto, você tem as partições de dados com o local do arquivo CSV. Enquanto isso, o esquema de entidade e o esquema CSV são idênticos, e todas as validações foram bem-sucedidas. No entanto, na visualização de dados, somente o esquema, em vez dos dados, é carregado, e os dados estão invisíveis, conforme mostra a figura a seguir:
Causa
Sua pasta CDM não está separada em modelos lógicos e físicos, e existem somente os modelos físicos na pasta CDM. Os dois artigos a seguir descrevem a diferença: Definições lógicas e Resolução de uma definição de entidade lógica.
Recomendação
Para o fluxo de dados usando CDM como uma fonte, tente usar um modelo lógico como referência de entidade, e use o manifesto que descreve o local das entidades físicas resolvidas e os locais da partição de dados. É possível visualizar alguns exemplos de definições de entidade lógica no repositório do GitHub público do CDM: CDM-schemaDocuments
Um bom ponto de partida para formar o seu corpus é copiar os arquivos da pasta de documentos de esquema (apenas esse nível dentro do repositório do GitHub) e colocá-los em uma pasta. Posteriormente, você pode usar uma das entidades lógicas predefinidas dentro do repositório (como um ponto de referência ou de início) para criar seu modelo lógico.
Após configurar o corpus, é recomendável usar o CDM como um coletor dentro de fluxos de dados, para que uma pasta CDM bem formada, possa ser criada corretamente. Você pode usar o seu conjunto de dados CSV como uma fonte e, em seguida, coletá-lo para o modelo CDM que você criou.
Formato CSV e Excel
Não há suporte no CSV para definir o caractere de aspas como 'sem caractere de aspas'
Sintomas
Há vários problemas que não têm suporte no CSV quando o caractere de aspas está definido como ' sem caractere de aspas':
- Quando o caractere de aspas é definido como 'sem caractere de aspas', o delimitador de coluna de vários caracteres não pode iniciar e terminar com as mesmas letras.
- Quando o caractere de aspas é definido como 'sem caractere de aspas', o delimitador de coluna de vários caracteres não pode conter o caractere de escape:
\. - Quando o caractere de aspas é definido como 'sem caractere de aspas', o valor da coluna não pode conter delimitador de linha.
- O caractere de aspas e o caractere de escape não podem estar ambos vazios (sem aspas e sem escape) se o valor da coluna contiver um delimitador de coluna.
Causa
As causas dos sintomas são indicadas abaixo com exemplos, respectivamente:
Início e fim com as mesmas letras.
column delimiter: $*^$*
column value: abc$*^ def
csv sink: abc$*^$*^$*def
will be read as "abc" and "^&*def"O delimitador de vários caracteres contém caracteres de escape.
column delimiter: \x
escape char:\
column value: "abc\\xdef"
O caractere de escape escapa do delimitador de coluna ou do caractere de escape.O valor da coluna contém o delimitador de linha.
We need quote character to tell if row delimiter is inside column value or not.Tanto o caractere de aspas quanto o caractere de escape estão vazios, e o valor da coluna contém delimitadores de coluna.
Column delimiter: \t
column value: 111\t222\t33\t3
It will be ambigious if it contains 3 columns 111,222,33\t3 or 4 columns 111,222,33,3.
Recomendação
O primeiro e o segundo sintomas não podem ser resolvidos no momento. Para o terceiro e o quarto sintomas, é possível aplicar os seguintes métodos:
- Para o Sintoma 3, não use o caractere 'sem caractere de aspas' para um arquivo CSV com várias linhas.
- Para o Sintoma 4, defina o caractere de aspas ou o caractere de escape como não vazio, ou remova todos os delimitadores de coluna dentro de seus dados.
Erro ao ler arquivos com esquemas diferentes
Sintomas
Ao usar fluxos de dados para fazer leitura de arquivos como arquivos CSV e do Excel com esquemas diferentes, a depuração do fluxo de dados, a área restrita ou a execução de atividade falham.
Para o CSV, existe um desalinhamento de dados quando o esquema de arquivos é diferente.
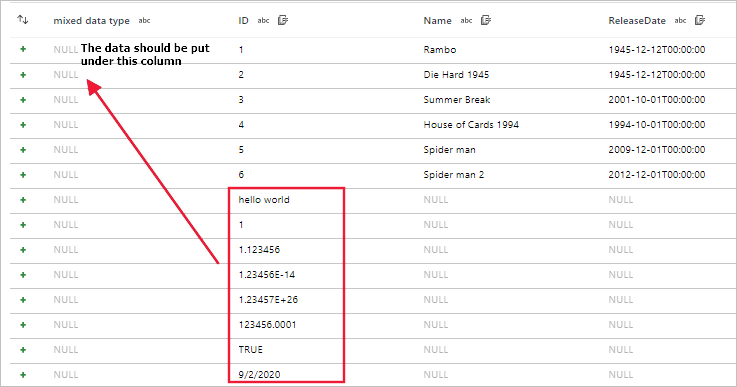
Para o Excel, ocorre um erro quando o esquema do arquivo é diferente.

Causa
Não há suporte para a leitura de arquivos com esquemas diferentes no fluxo de dados.
Recomendação
Caso ainda queira transferir arquivos como os CSV e arquivos do Excel com esquemas diferentes no fluxo de dados, poderá usar estas soluções alternativas:
Para CSV, é necessário mesclar manualmente o esquema de arquivos diferentes para obter o esquema completo. Por exemplo, file_1 possui as colunas
c_1,c_2,c_3enquanto file_2 possui as colunasc_3,c_4, ...c_10; portanto, o esquema mesclado e o completo sãoc_1,c_2e ...c_10. Em seguida, faça com que outros arquivos também tenham o mesmo esquema completo, embora ele não tenha dados. Por exemplo, file_x só possui colunasc_1,c_2,c_3,c_4, adicione colunasc_5,c_6, ...c_10ao arquivo para torná-las consistentes com outros arquivos.Para o Excel, você pode resolver esse problema aplicando uma das seguintes opções:
- Opção-1: é necessário mesclar manualmente o esquema de arquivos diferentes para obter o esquema completo. Por exemplo, file_1 possui colunas
c_1,c_2,c_3enquanto file_2 possui colunasc_3,c_4, ...c_10; portanto, o esquema mesclado e o completo sãoc_1,c_2, ...c_10. Em seguida, faça com que os outros arquivos também tenham o mesmo esquema, embora ele não tenha dados. Por exemplo, o arquivo_x com a planilha "SHEET_1" só tem colunasc_1,c_2,c_3,c_4, adicione as colunasc_5,c_6, ...c_10à planilha também e, assim, poderá funcionar. - Opção-2: use intervalo (por exemplo, A1: G100) + firstRowAsHeader = falsee, em seguida, ele pode carregar dados de todos os arquivos do Excel, mesmo que o nome da coluna e a contagem sejam diferentes.
- Opção-1: é necessário mesclar manualmente o esquema de arquivos diferentes para obter o esquema completo. Por exemplo, file_1 possui colunas
Snowflake
Não é possível se conectar ao serviço vinculado Snowflake
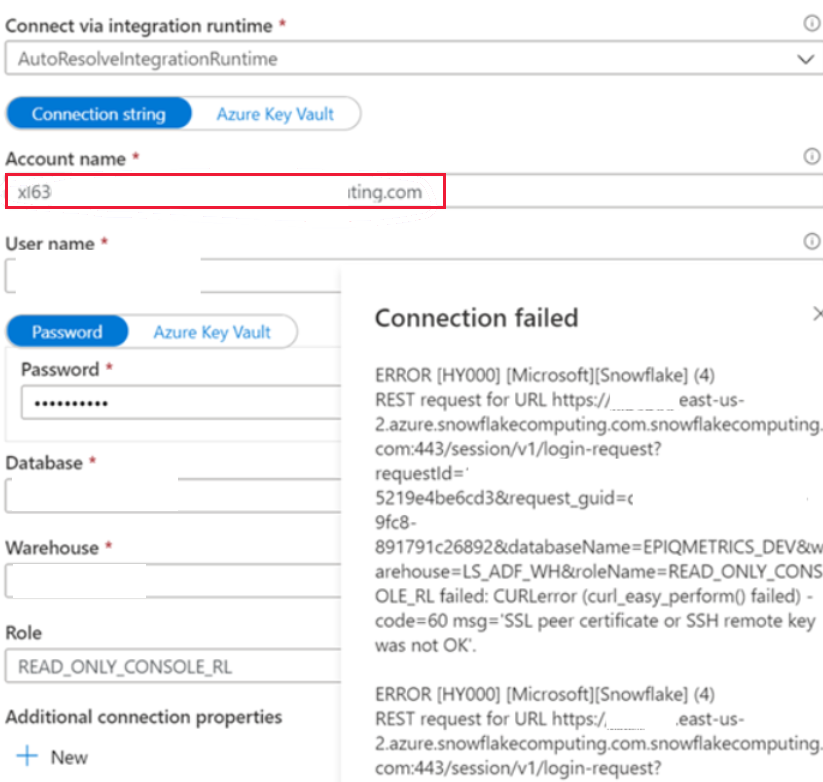
Sintomas
Você encontra o seguinte erro ao criar o serviço vinculado do Snowflake na rede pública, e usa o runtime de integração de resolução automática.
ERROR [HY000] [Microsoft][Snowflake] (4) REST request for URL https://XXXXXXXX.east-us- 2.azure.snowflakecomputing.com.snowflakecomputing.com:443/session/v1/login-request?requestId=XXXXXXXXXXXXXXXXXXXXXXXXX&request_guid=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Causa
Você não aplicou o nome da conta no formato que é dado no documento da conta do Snowflake (inclusive segmentos extras que identificam a região e a plataforma de nuvem), por exemplo, XXXXXXXX.east-us-2.azure. Você pode consultar este documento: Propriedades de serviço vinculado para obter mais informações.
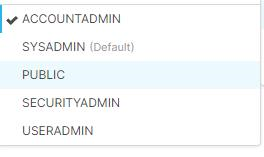
Recomendação
Para resolver o problema, altere o formato do nome da conta. A função deve ser uma dentre as mostradas na figura a seguir, mas a padrão é Public.
Erro de controle de acesso no SQL: "Privilégios insuficientes para operar no esquema"
Sintomas
Quando você tenta usar "projeção de importação", "visualização de dados" etc., na fonte Snowflake de fluxos de dados, você encontra erros como net.snowflake.client.jdbc.SnowflakeSQLException: SQL access control error: Insufficient privileges to operate on schema.
Causa
Você encontra esse erro devido a uma configuração incorreta. Ao usar o fluxo de dados para fazer leitura dos dados do Snowflake, o runtime do Azure Databricks (ADB), não seleciona diretamente a consulta para Snowflake. Em vez disso, um preparo temporário é criado, e os dados são extraídos de tabelas para o preparo e, em seguida, compactados e extraídos pelo ADB. Esse processo é mostrado na imagem abaixo.
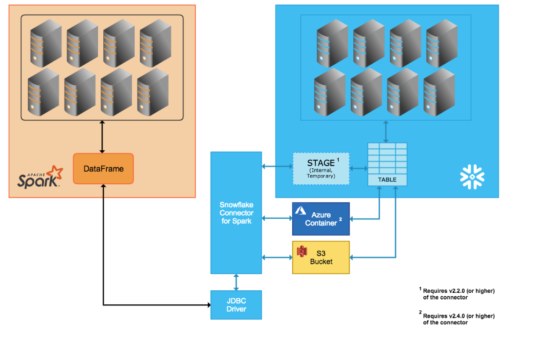
Portanto, o usuário/função usado no ADB deve ter a permissão necessária para fazer isso no Snowflake. Mas geralmente o usuário/função não tem a permissão, pois o banco de dados é criado no compartilhamento.
Recomendação
Para resolver esse problema, você pode criar um banco de dados diferente, e criar exibições na parte superior do banco de dados compartilhado para acessá-lo do ADB. Para obter mais detalhes, consulte o Snowflake.
Falha com um erro: “SnowflakeSQLException: o IP x.x.x.x não tem permissão para acessar o Snowflake”. Entre em contato com o administrador da segurança local"
Sintomas
Ao usar o Snowflake no Azure Data Factory, você pode utilizar com êxito o test-connection no serviço vinculado Snowflake, o preview-data/import-schema no conjuntos de dados Snowflake, e executar copiar/pesquisar/obter-metadados ou outras atividades com ele. Mas ao usar o Snowflake na atividade de fluxo de dados, você poderá visualizar um erro como SnowflakeSQLException: IP 13.66.58.164 is not allowed to access Snowflake. Contact your local security administrator.
Causa
O fluxo de dados do Azure Data Factory não dá suporte ao uso de intervalos de IP fixos. Para obter mais informações, confira Endereços IP do Azure Integration Runtime.
Recomendação
Para resolver esse problema, você pode alterar as configurações de firewall da conta do Snowflake com as seguintes etapas:
Você pode obter a lista de intervalos de IP de marcas de serviço do "link para download do intervalo de IP de marcas de serviço": Descobrir marcas de serviço usando arquivos JSON baixáveis.
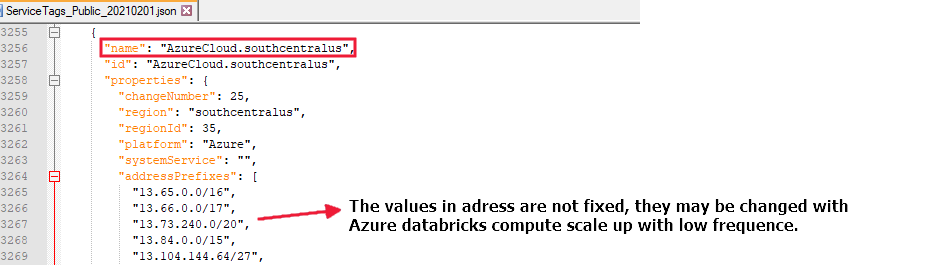
Se você executar um fluxo de dados na região "southcentralus", será necessário permitir o acesso de todos os endereços com o nome "AzureCloud.southcentralus", por exemplo:
As consultas na origem não funcionam
Sintomas
Ao tentar fazer a leitura dos dados do Snowflake com a consulta, você poderá visualizar um erro como este:
SQL compilation error: error line 1 at position 7 invalid identifier 'xxx'SQL compilation error: Object 'xxx' does not exist or not authorized.
Causa
Esse erro ocorre devido a configurações incorretas.
Recomendação
Para o Snowflake, ele aplica as seguintes regras para armazenar identificadores no momento da criação/definição e resolvê-los em consultas e outras instruções SQL:
Quando um identificador (nome da tabela, nome do esquema, nome da coluna etc.) é sem aspas, ele é armazenado e resolvido em letras maiúsculas por padrão e ele é sensível a maiúsculas e minúsculas. Por exemplo:

Como ele é sensível a maiúsculas e minúsculas, você poderá se sentir à vontade para usar a consulta a seguir para fazer a leitura dos dados do Snowflake, pois o resultado é o mesmo:
Select MovieID, title from Public.TestQuotedTable2Select movieId, title from Public.TESTQUOTEDTABLE2Select movieID, TITLE from PUBLIC.TESTQUOTEDTABLE2
Quando um identificador (nome da tabela, nome do esquema, nome da coluna, etc.) está entre aspas duplas, ele é armazenado e resolvido exatamente como inserido, incluindo as maiúsculas e minúsculas, pois ele é sensível a essa diferenciação, e você poderá visualizar um exemplo na imagem a seguir. Para obter mais detalhes, consulte este documento: Requisitos de Identificador.

Como o identificador que diferencia maiúsculas de minúsculas (nome da tabela, nome do esquema, nome da coluna etc.) possui caractere em minúsculas, você deve colocar o identificador entre aspas durante a leitura dos dados com a consulta, por exemplo:
- Selecione "movieId" , "title" de Public. "testQuotedTable2"
Se você encontrar um erro com a consulta Snowflake, verifique se alguns identificadores (nome da tabela, nome do esquema, nome da coluna etc.) diferenciam maiúsculas de minúsculas com as seguintes etapas:
Entre no servidor Snowflake (
https://{accountName}.azure.snowflakecomputing.com/, substitua {accountName} pelo nome da conta) para checar o identificador (nome da tabela, do esquema, da coluna etc.).Crie planilhas para testar e validar a consulta:
- Execute
Use database {databaseName}, substitua {databaseName} pelo nome de seu banco de dados. - Execute uma consulta com tabela, por exemplo:
select "movieId", "title" from Public."testQuotedTable2"
- Execute
Depois que a consulta SQL do Snowflake for testada e validada, você poderá usá-la diretamente na fonte do fluxo de dados do Snowflake.
O tipo de expressão não corresponde ao tipo de dados da coluna. Era esperado VARIANT, mas foi obtido VARCHAR
Sintomas
Ao tentar gravar dados na tabela do Snowflake, você poderá encontrar o seguinte erro:
java.sql.BatchUpdateException: SQL compilation error: Expression type does not match column data type, expecting VARIANT but got VARCHAR
Causa
O tipo de coluna de dados de entrada é cadeia de caracteres, que é diferente do tipo VARIANT da coluna relacionada no coletor do Snowflake.
Ao armazenar dados com esquemas complexos (matriz/mapa/struct) em uma nova tabela do Snowflake, o tipo de fluxo de dados é convertido automaticamente em sua VARIANT de tipo físico.

Os valores relacionados são armazenados como cadeias de caracteres JSON, mostrados na imagem abaixo.

Recomendação
Para a VARIANT do Snowflake, ela só pode aceitar o valor de fluxo de dados do tipo struct, mapa ou matriz. Se o valor da coluna de dados de entrada for JSON, XML ou outras cadeias de caracteres, use uma das seguintes opções para resolver esse problema:
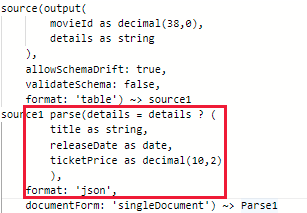
Opção 1: use transformação de análise antes de usar o Snowflake como um coletor para converter o valor da coluna de dados de entrada no tipo struct, mapa ou matriz, por exemplo:
Observação
O valor da coluna do Snowflake com o tipo VARIANT é lido como cadeia de caracteres no Spark por padrão.
Option-2: entre no servidor Snowflake (
https://{accountName}.azure.snowflakecomputing.com/, substitua {accountName} pelo nome da sua conta) para alterar o esquema da tabela de destino do Snowflake. Aplique as etapas a seguir executando a consulta em cada etapa.Crie uma coluna com VARCHAR para armazenar os valores.
alter table tablename add newcolumnname varchar;Copie o valor de VARIANT na nova coluna.
update tablename t1 set newcolumnname = t1."details"Exclua a coluna VARIANT não usada.
alter table tablename drop column "details";Renomeie a nova coluna para o nome antigo.
alter table tablename rename column newcolumnname to "details";
Conteúdo relacionado
Para obter mais ajuda com a solução de problemas, confira estes recursos:
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de