Eliminar linhas duplicadas e encontrar nulos usando snippets de fluxo de dados
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Usando snippets de código nos fluxos de dados de mapeamento, você pode facilmente executar tarefas comuns, como a eliminação de duplicação de dados e a filtragem de nulos. Este artigo explica como adicionar facilmente essas funções aos seus pipelines usando snippets de script do fluxo de dados.
Criar um pipeline
Selecione Novo Pipeline.
Adicione uma atividade de fluxo de dados.
Selecione a guia Configurações de origem, adicione uma transformação de origem e conecte-a a um dos seus conjuntos de dados.
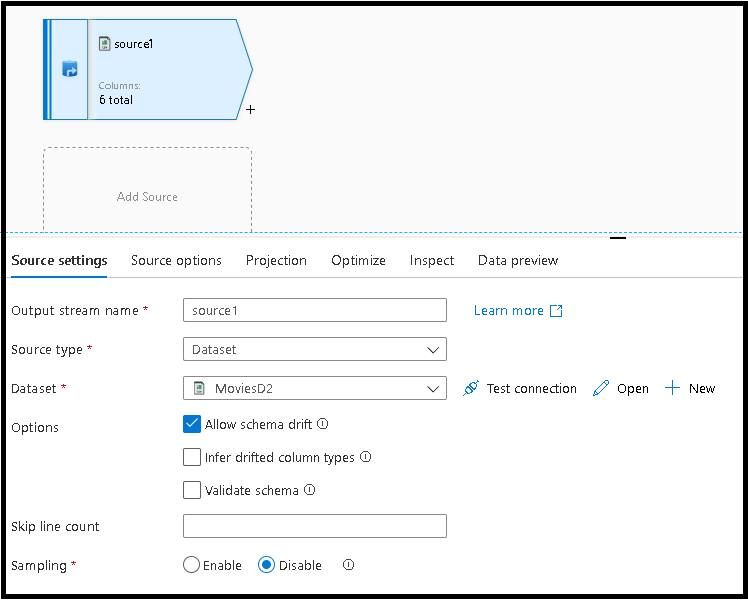
Os snippets de verificação de eliminação de duplicação e de nulos usam padrões genéricos que aproveitam o descompasso de esquema do fluxo de dados. Os snippets funcionam com qualquer esquema do seu conjuntos de dados ou com conjuntos de dados que não têm nenhum esquema pré-definido.
Na seção "Linha distinta usando todas as colunas" do DFS (Script do fluxo de dados), copie o snippet de código para DistinctRows.
-
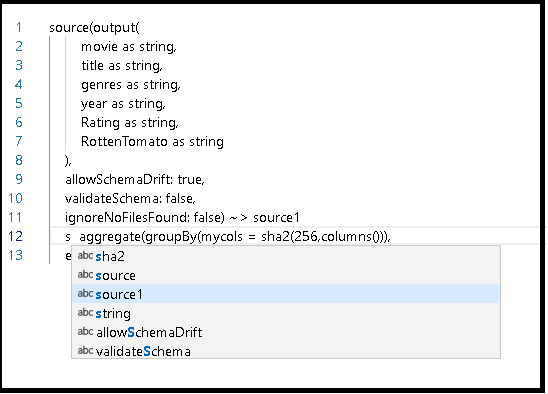
No script, após a definição de
source1, digite Enter e, em seguida, cole o snippet de código.Siga um destes procedimentos:
Conecte esse snippet de código colado à transformação de origem que você criou anteriormente no gráfico digitando source1 na frente do código colado.
Como alternativa, você pode conectar a nova transformação no designer selecionando o fluxo de entrada do novo nó de transformação no gráfico.
Agora, seu fluxo de dados removerá linhas duplicadas da sua origem usando a transformação de agregação, que se agrupa por todas as linhas usando um hash geral em todos os valores de coluna.
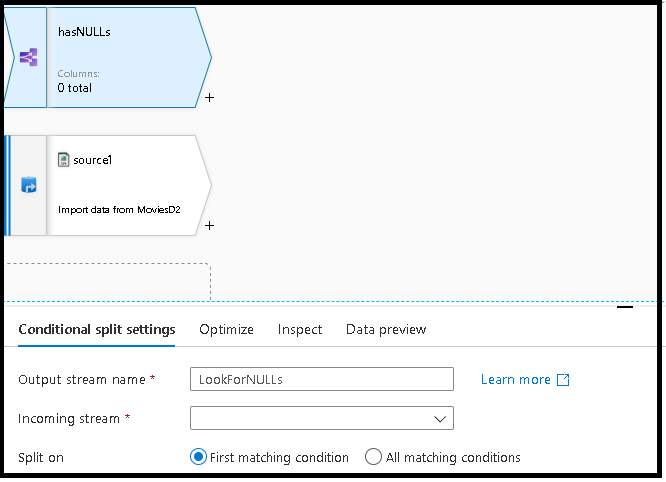
Adicione um snippet de código para dividir seus dados em um fluxo que contém linhas com nulos e outro fluxo sem nulos. Para fazer isso:
Vá para a biblioteca de Snippets e, desta vez, copie o código para as verificações de NULO.
b. No designer do fluxo de dados, selecione Script novamente e cole esse novo código de transformação na parte inferior. Essa ação conecta o script à transformação anterior colocando o nome dessa transformação na frente do snippet colado.
Seu gráfico de fluxo de dados agora deve ser semelhante a este:
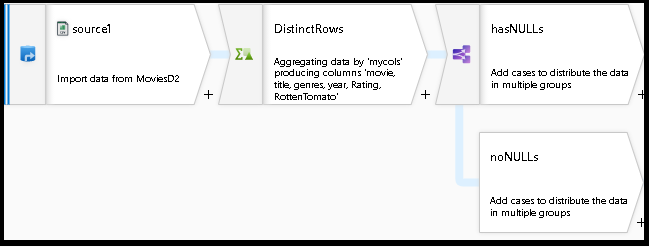
Agora você criou um fluxo de dados de trabalho com eliminação de duplicação genérica e verificações de nulos usando snippets de código existentes da biblioteca de Script do Fluxo de Dados e adicionando-os ao seu design existente.
Conteúdo relacionado
- Compile o restante da lógica de fluxo de dados usando as transformações de fluxos de dados de mapeamento.