Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este artigo descreve um modelo de solução que você pode usar para extrair dados de uma fonte PDF usando o Azure Data Factory e a IA do Azure para Informação de Documentos.
Sobre o modelo de solução
Este modelo analisa dados de uma fonte de URL PDF usando duas chamadas de IA do Azure para Informação de Documentos. Em seguida, ele transforma a saída em tabelas legíveis em um fluxo de dados e envia os dados para um coletor de armazenamento.
Este modelo contém duas atividades:
- Atividade da Web para chamar a API do modelo de layout da Inteligência de Documento de IA do Azure
- Fluxo de dados para transformar dados extraídos de PDF
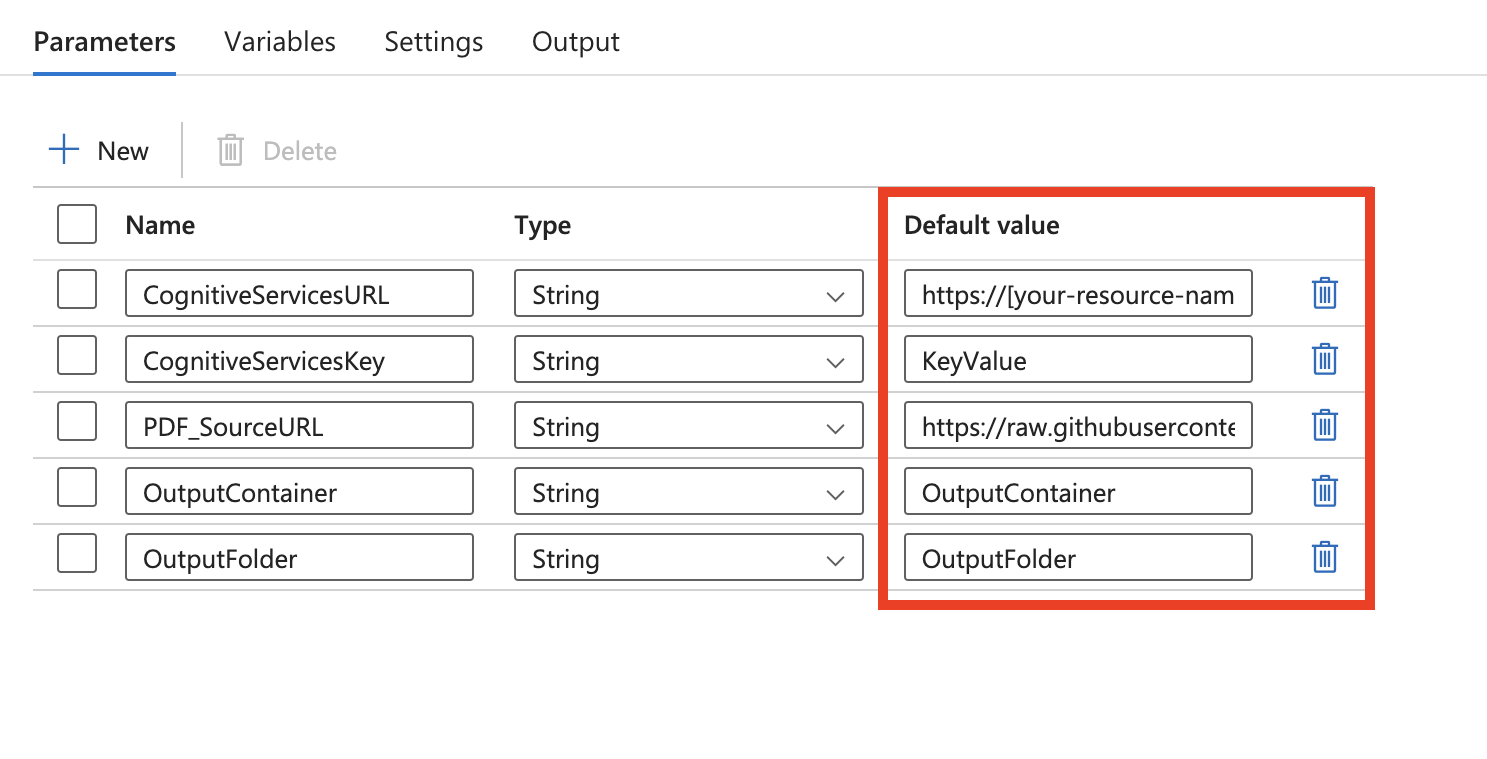
Este modelo define cinco parâmetros:
- cognitiveServicesURL é a URL de Inteligência de Documento de IA do Azure ("https://{ponto de extremidade}/formrecognizer/v2.1/layout/analyze"). Substitua {endpoint} pelo valor do ponto de extremidade que você obteve com sua assinatura da IA do Azure para Informação de Documentos. Você precisa substituir o valor padrão pela sua própria URL.
- FormRecognizerKey é a chave de assinatura da Inteligência de Documento de IA do Azure. Você precisa substituir o valor padrão por sua própria chave de assinatura.
- PDF_SourceURL é a URL da sua fonte PDF. Você precisa substituir o valor padrão pela sua própria URL.
- OutputContainer é o nome do caminho do contêiner no que você quer que seus arquivos estejam no repositório de destino. Você precisa substituir o valor padrão pelo seu próprio contêiner.
- OutputFolder é o nome do caminho da pasta no que você quer que seus arquivos estejam no repositório de destino. Você precisará substituir o valor padrão por um caminho de pasta próprio.
Pré-requisitos
- O URL e a Chave do ponto de extremidade do recurso da IA do Azure para Informação de Documentos (crie um novo recurso aqui)
Como usar este modelo de solução
Vá para o modelo Extrair dados de PDF. Crie uma Nova conexão com a sua IA do Azure para Informação de Documentos ou escolha uma conexão existente.
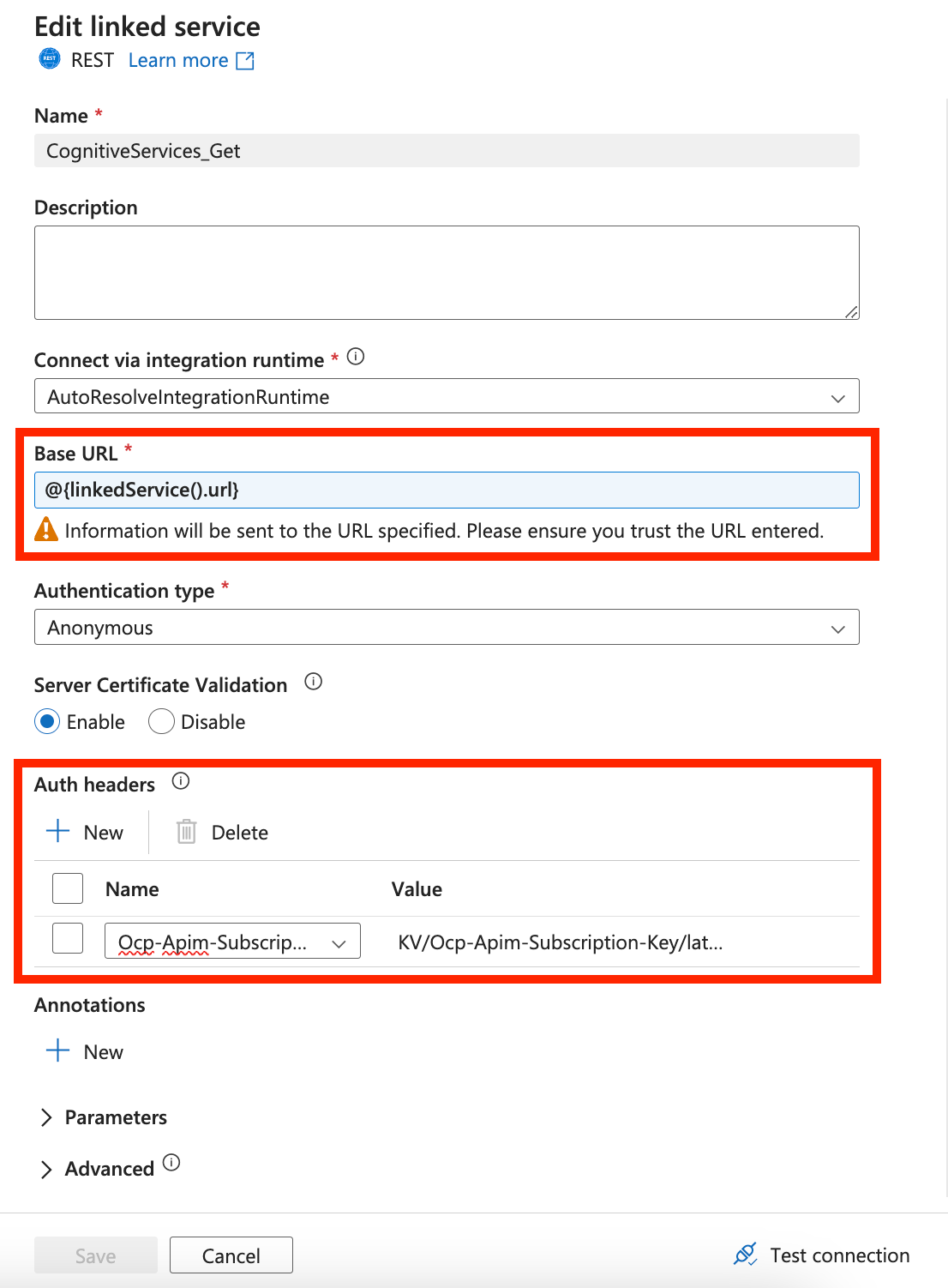
Em sua conexão com a IA do Azure para Informação de Documentos, adicione um parâmetro de serviço vinculado. Você precisará usar esse parâmetro de url como sua URL base dinâmica. Você também precisará adicionar um novo Cabeçalho de autenticação nos Cabeçalhos de autenticação. O nome deve ser Ocp-Apim-Subscription-Key e o valor deve ser o valor de chave que você encontra no recurso do Azure.
Crie uma nova conexão com seu repositório de armazenamento de destino ou escolha uma conexão existente. O destino escolhido é onde os dados de PDF extraídos são armazenados.

Selecione Usar este modelo.

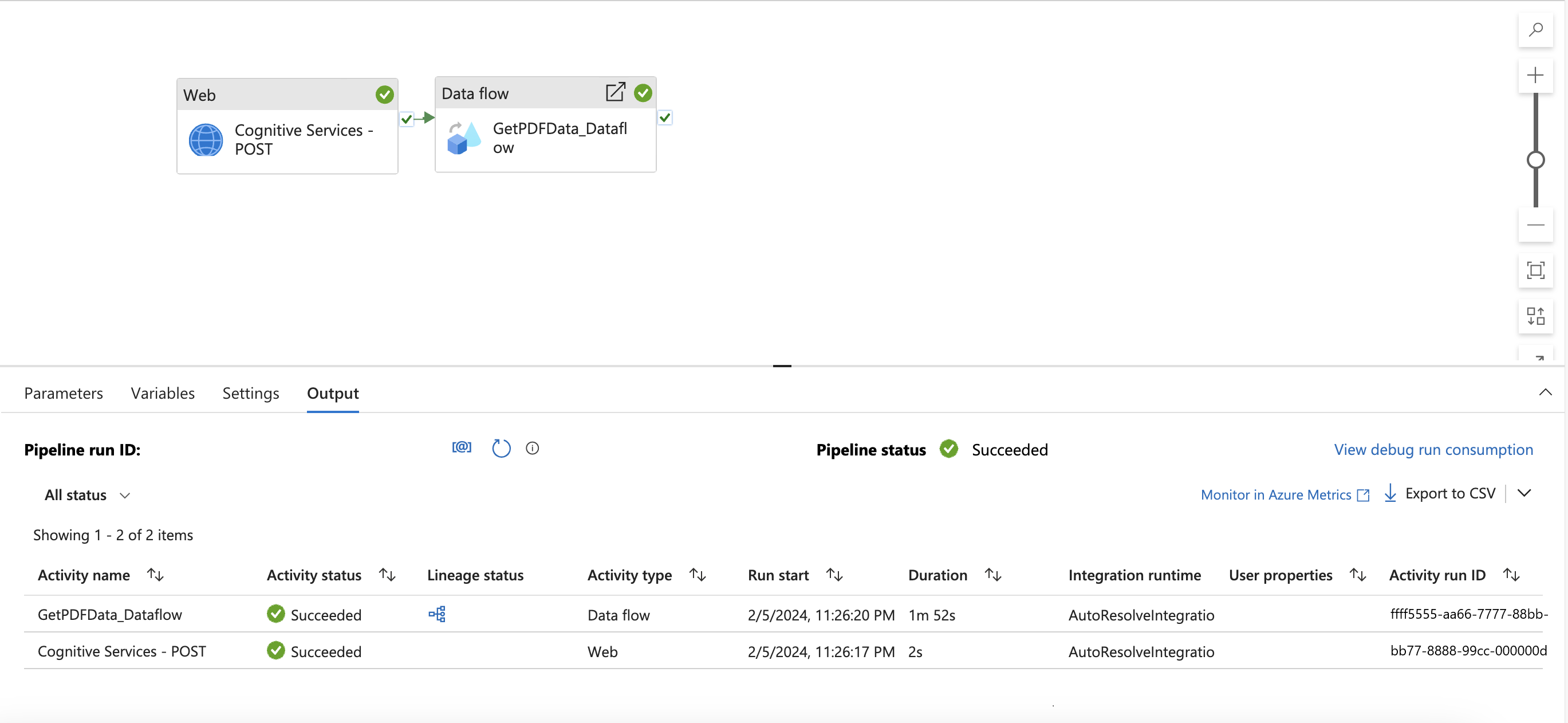
Você deverá ver o pipeline a seguir.
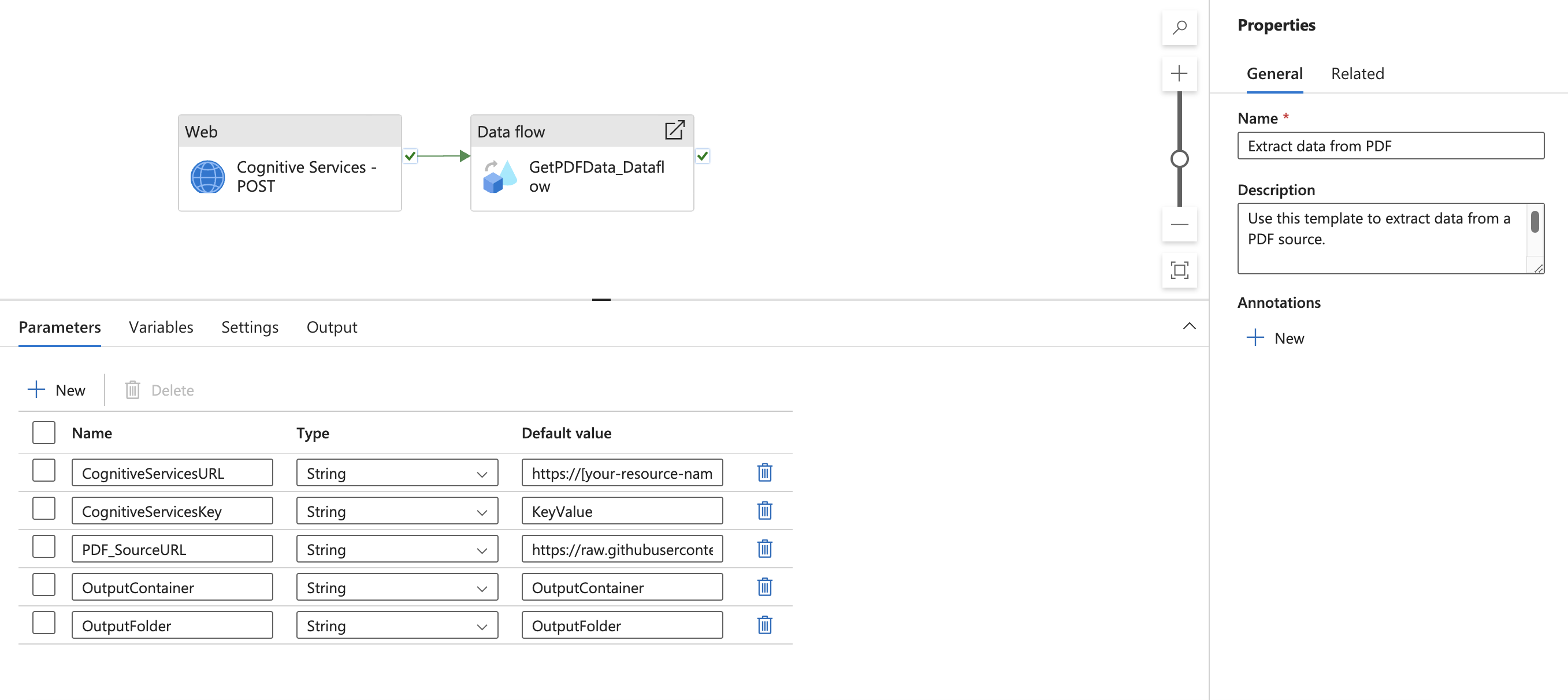
Navegue até a atividade de Fluxo de dados e localize Configurações. Aqui você precisa adicionar conteúdo dinâmico para o parâmetro de url do serviço vinculado. Depois de clicar em Adicionar conteúdo dinâmico, o construtor de expressões do pipeline será aberto. Selecione Serviços Cognitivos - Saída da atividades do POST. Em seguida, digite ou copie e cole ".output. ADFWebActivityResponseHeaders['Operation-Location']." Você deverá ver a expressão a seguir no seu construtor de expressões.
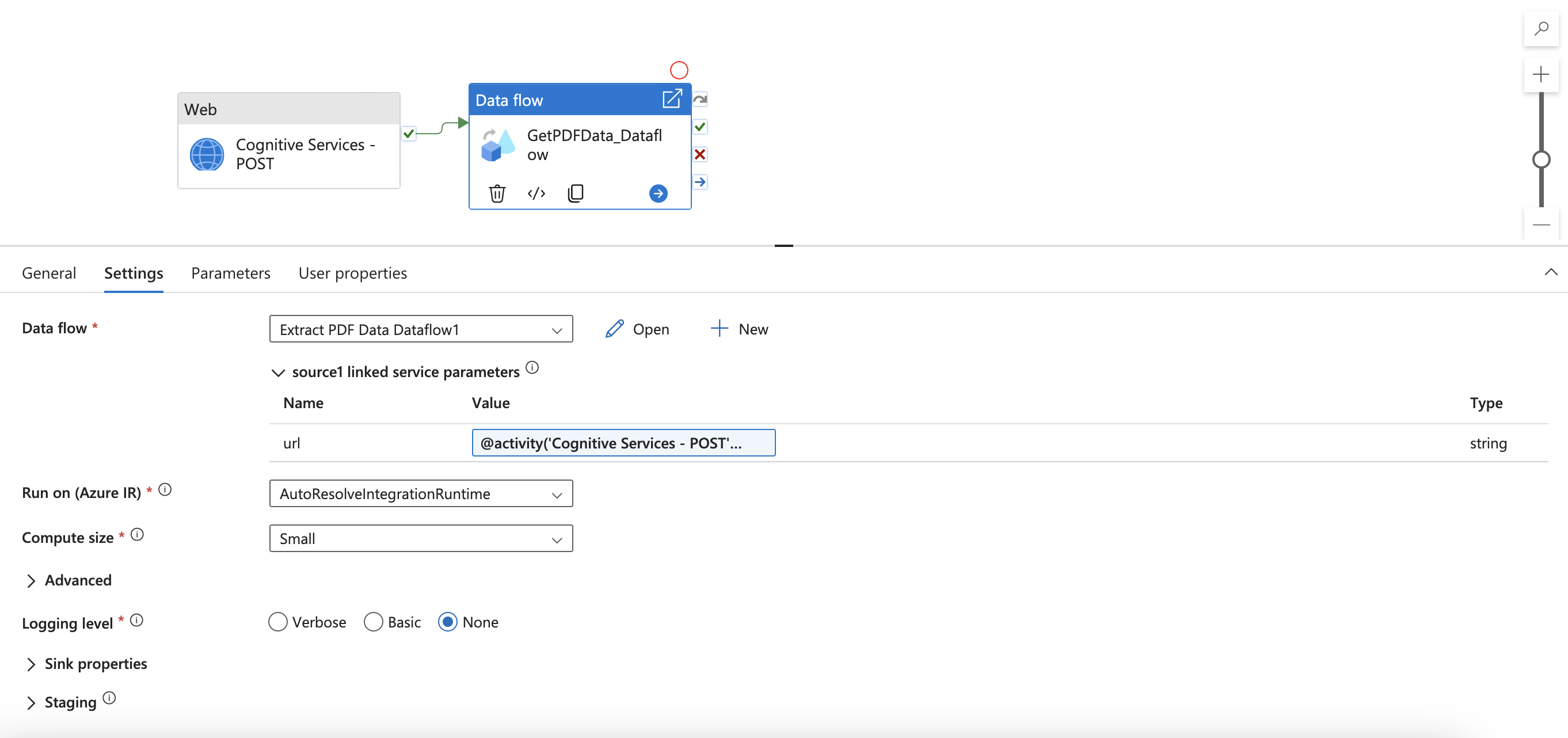
Clique em OK para voltar ao pipeline.
Em seguida, selecione Depurar.
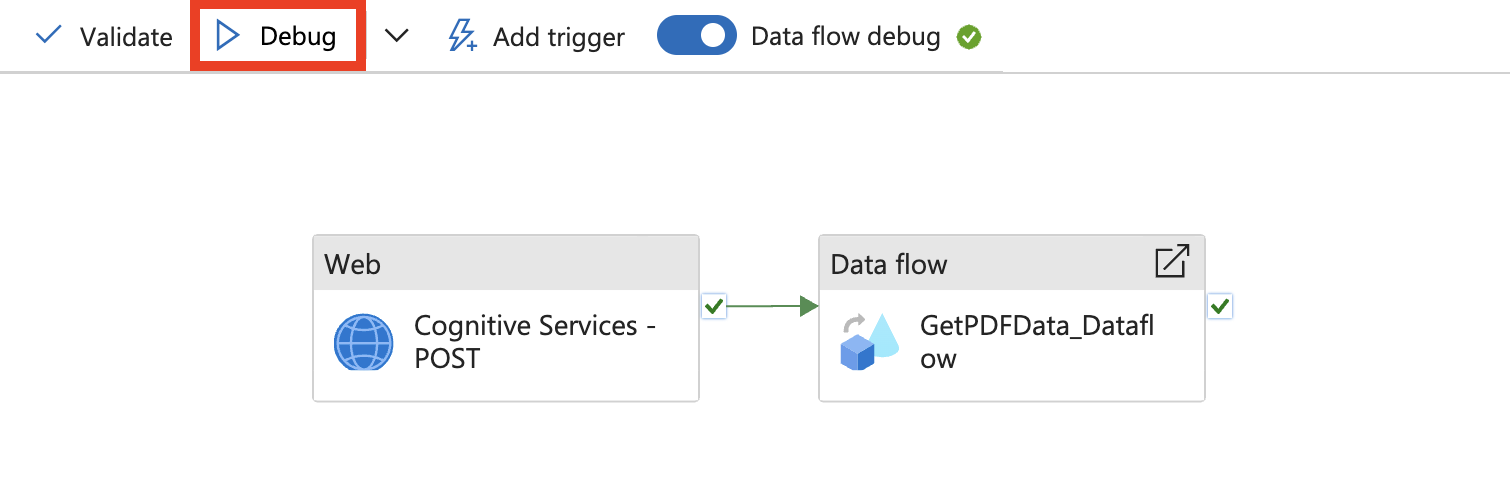
Insira os valores dos parâmetros, revise os resultados e publique.