Copiar dados e enviar notificações por email sobre sucesso e falha
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Neste tutorial, você deve criar um pipeline de Data Factory que apresente alguns dos recursos de fluxo de controle. Esse pipeline faz uma cópia simples de um contêiner no Armazenamento de Blobs do Azure para outro contêiner na mesma conta de armazenamento. Se a atividade de cópia for bem-sucedida, o pipeline enviará detalhes da operação de cópia bem-sucedida (tais como a quantidade de dados gravados) em um email de êxito. Se a atividade de cópia falhar, o pipeline enviará detalhes da falha de cópia (por exemplo, a mensagem de erro) em um email de falha. Ao longo do tutorial, você verá como passar parâmetros.
Uma visão geral de alto nível do cenário: 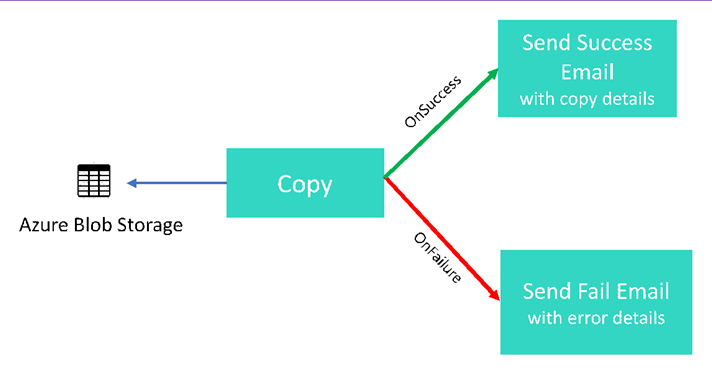
Neste tutorial, você realizará os seguintes procedimentos:
- Criar um data factory.
- Criar um serviço vinculado do Armazenamento do Azure.
- Criar um conjunto de dados do Blob do Azure
- Criar um pipeline que contém uma atividade de Cópia e uma atividade da Web
- Enviar saídas de atividades para as atividades subsequentes
- Utilizar passagem de parâmetros e variáveis do sistema
- Iniciar uma execução de pipeline
- Monitorar as execuções de pipeline e de atividade
Este tutorial usa o portal do Azure. Você pode usar outros mecanismos para interagir com o Azure Data Factory, consulte "Guias de início rápido" no sumário.
Pré-requisitos
- Assinatura do Azure. Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
- Conta de Armazenamento do Azure. Você usa o Armazenamento de Blobs como um armazenamento de dados de origem. Se você não tiver uma conta de Armazenamento do Azure, veja o artigo Criar uma conta de armazenamento para conhecer as etapas para criar uma.
- Banco de dados SQL do Azure. Você usa o banco de dados como um armazenamento de dados de coletor. Se você não tiver um banco de dados no Banco de Dados SQL do Azure, confira o artigo Criar um banco de dados no Banco de Dados SQL do Azure para ver as etapas para a criação de um.
Criar tabela de blob
Inicie o Bloco de notas. Copie o texto a seguir e salve-o como um arquivo input.txt no disco.
John,Doe Jane,DoeUse ferramentas como o Gerenciador de Armazenamento do Azure para executar estas etapas:
- Crie o contêiner adfv2branch.
- Crie a pasta input no contêiner adfv2branch.
- Carregue o arquivo input.txt no contêiner.
Criar pontos de extremidade do fluxo de trabalho de email
Para disparar o envio de um email desde o pipeline, use os Aplicativos Lógicos do Azure para definir o fluxo de trabalho. Para obter mais informações sobre como criar um fluxo de trabalho de aplicativo lógico, consulte Criar um exemplo de fluxo de trabalho de aplicativo lógico de Consumo.
Fluxo de trabalho de email de êxito
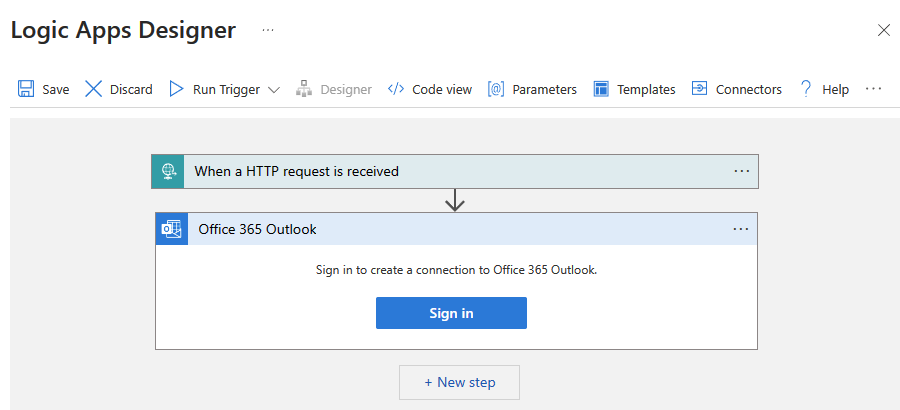
Criar um fluxo de trabalho do aplicativo lógico de Consumo chamado CopySuccessEmail. Adicione o gatilho de solicitação chamado Quando uma solicitação HTTP for recebida e adicione a ação Office 365 Outlook chamada Enviar um email. Se solicitado, em sua conta do Outlook do Office 365.
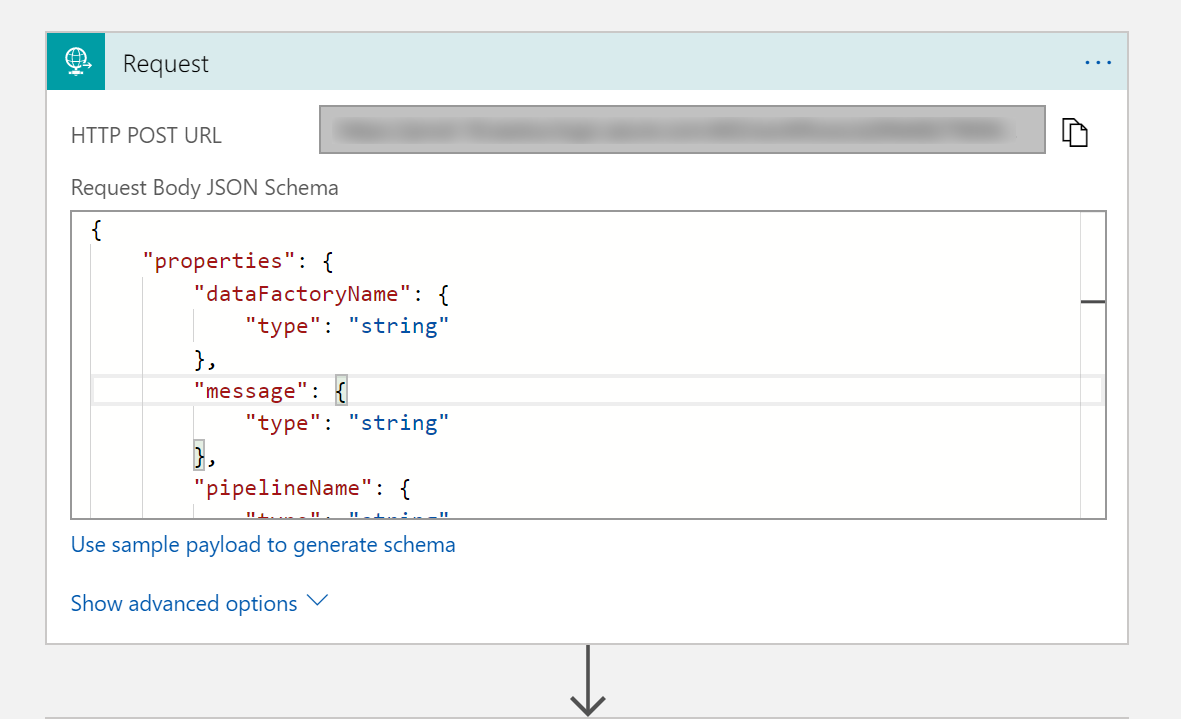
No gatilho Solicitação, preencha a caixa esquema JSON do Corpo da Solicitação com o seguinte JSON:
{
"properties": {
"dataFactoryName": {
"type": "string"
},
"message": {
"type": "string"
},
"pipelineName": {
"type": "string"
},
"receiver": {
"type": "string"
}
},
"type": "object"
}
O gatilho Solicitação no designer de fluxo de trabalho deve ter a seguinte imagem:
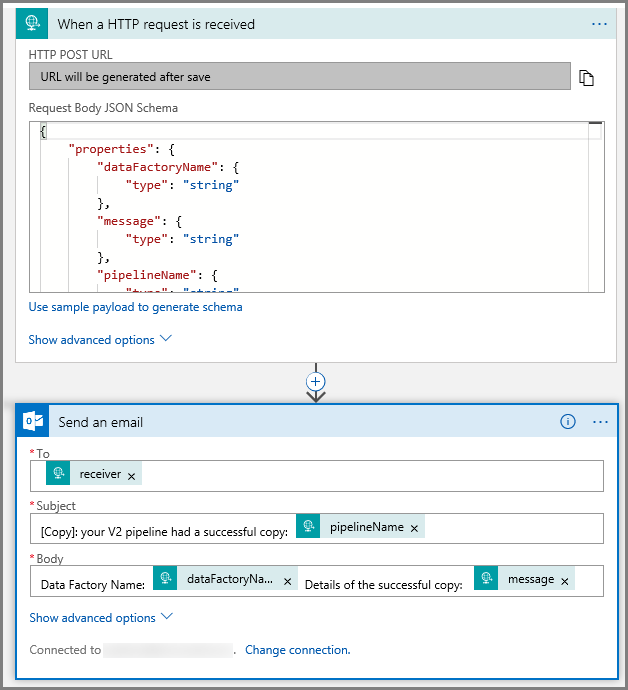
Para a ação Enviar um email, personalize o modo como você deseja formatar o email, utilizando as propriedades passadas no esquema JSON do corpo da solicitação. Veja um exemplo:
Salve o fluxo de trabalho. Anote a URL da solicitação HTTP Post para o fluxo de trabalho de email de êxito:
//Success Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Fluxo de trabalho de email de falha
Siga as mesmas etapas para criar outro fluxo de trabalho de aplicativos lógicos chamado CopyFailEmail. No gatilho Solicitação, o valor esquema JSON do Corpo da Solicitação é o mesmo. Altere o formato do seu email como o Subject para ajustá-lo, tornando-o um email de falha. Veja um exemplo:
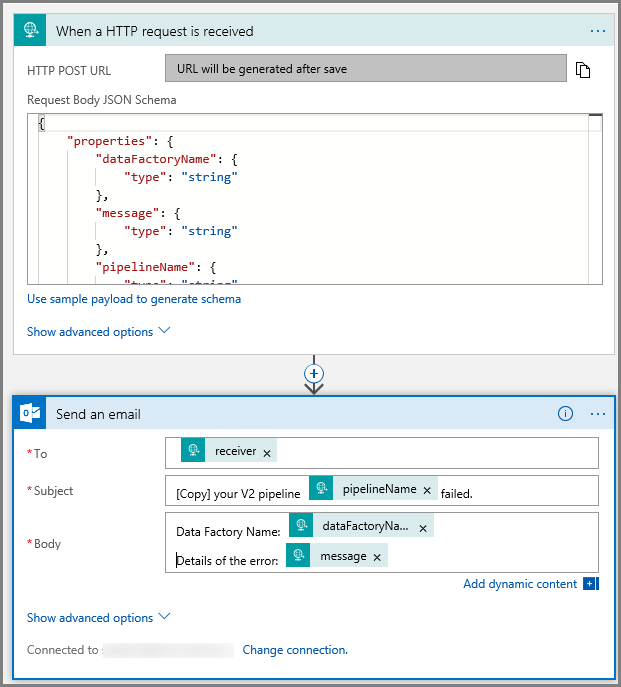
Salve o fluxo de trabalho. Anote a URL da solicitação HTTP Post para o fluxo de trabalho de email de falha:
//Fail Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Agora você deve ter duas URL de fluxo de trabalho:
//Success Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
//Fail Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Criar uma data factory
Iniciar o navegador da Web Microsoft Edge ou Google Chrome. Atualmente, a interface do usuário do Data Factory tem suporte apenas nos navegadores da Web Microsoft Edge e Google Chrome.
Expanda o menu no canto superior esquerdo e selecione Criar um recurso. Em seguida, selecione >Integração>Data Factory:

Na página Novo data factory, insira ADFTutorialDataFactory no campo nome.
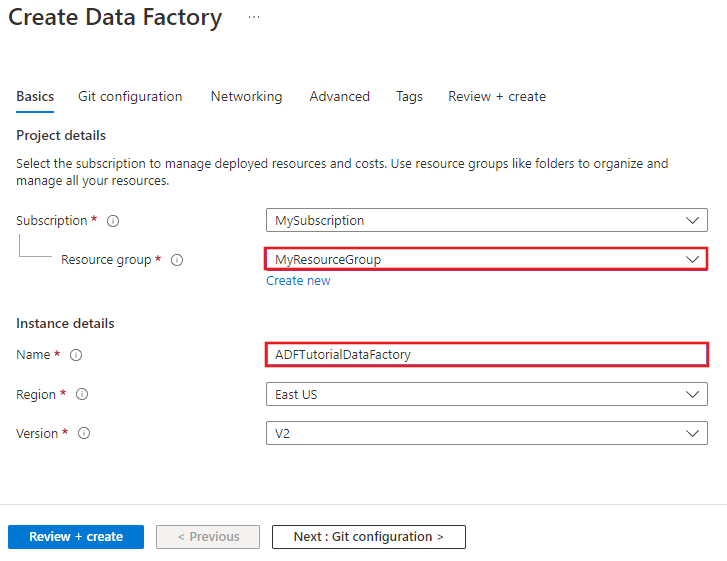
O nome do Azure Data Factory deve ser globalmente exclusivo. Se você receber o seguinte erro, altere o nome de data factory (por exemplo, yournameADFTutorialDataFactory) e tente criar novamente. Confira o artigo Data Factory - regras de nomenclatura para ver as regras de nomenclatura para artefatos do Data Factory.
O nome do data factory “ADFTutorialDataFactory” não está disponível.
Selecione a assinatura do Azure na qual você deseja criar o data factory.
Para o Grupo de Recursos, execute uma das seguintes etapas:
Selecione Usar existentee selecione um grupo de recursos existente na lista suspensa.
Selecione Criar novoe insira o nome de um grupo de recursos.
Para saber mais sobre grupos de recursos, consulte Usando grupos de recursos para gerenciar recursos do Azure.
Selecione V2 para a versão.
Selecione o local do data factory. Apenas os locais com suporte são exibidos na lista suspensa. Os armazenamentos de dados (Armazenamento do Azure, Banco de Dados SQL do Azure, etc.) e serviços de computação (HDInsight, etc.) usados pelo data factory podem estar em outras regiões.
Selecione Fixar no painel.
Clique em Criar.
Após a criação, a página do Data Factory será exibida conforme mostrado na imagem.
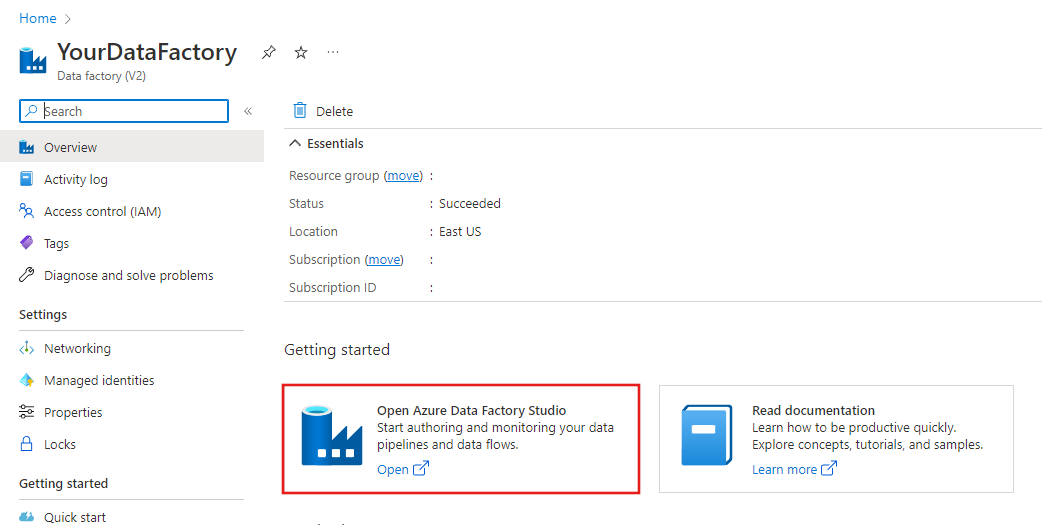
Clique no bloco Abrir Azure Data Factory Studio para iniciar a interface do usuário do Azure Data Factory em uma guia separada.
Criar um pipeline
Nesta etapa, você pode criar um pipeline com uma atividade de Cópia e duas atividades da Web. Você pode usar os recursos a seguir para criar o pipeline:
- Parâmetros para o pipeline acessado por conjuntos de dados.
- Atividade de Web para invocar os fluxos de trabalho de aplicativos lógicos para enviar emails de êxito/falha.
- Conexão a uma atividade com outra atividade (no caso de sucesso e falha)
- Usando a saída de uma atividade como uma entrada para a atividade subsequente
Na página inicial da interface do usuário do Data Factory, clique no bloco Orquestrar.
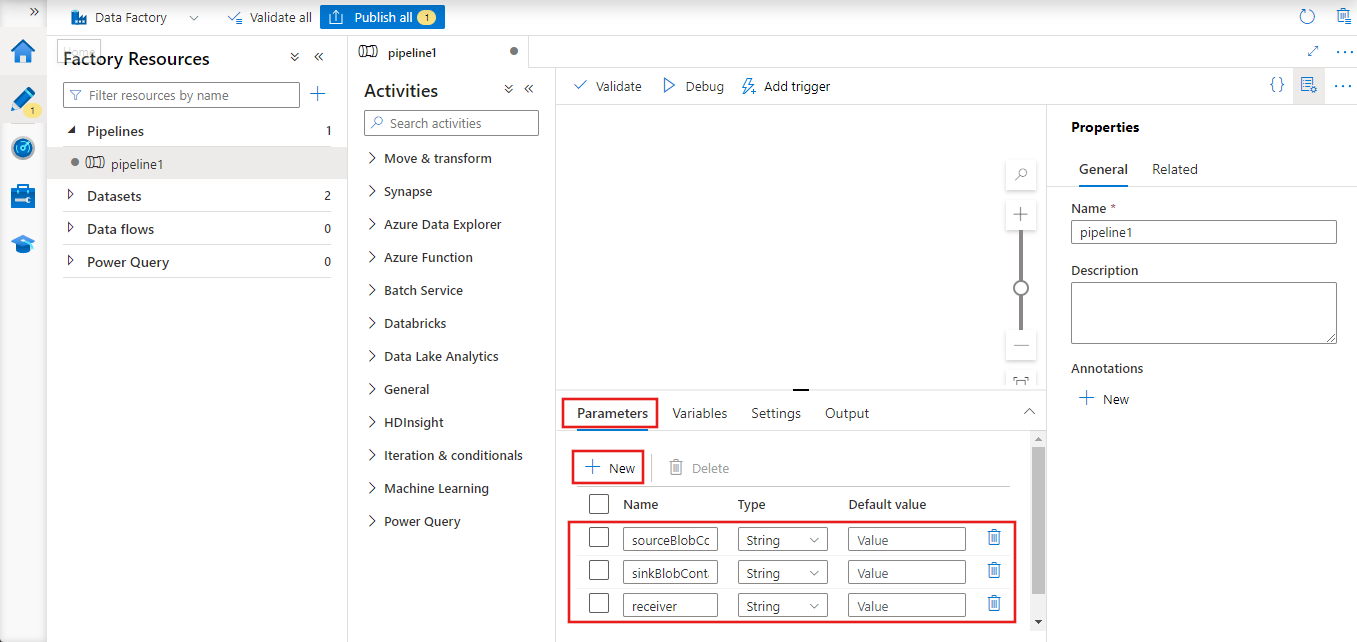
Na janela de propriedades do pipeline, alterne para a guia Parâmetros e use o botão Novo para adicionar o três parâmetros a seguir do tipo String: sourceBlobContainer, sinkBlobContainer e receptor.
- sourceBlobContainer – parâmetro no pipeline consumido pelo conjunto de dados de blob de origem.
- sinkBlobContainer – parâmetro no pipeline consumido pelo conjunto de dados de blob do coletor
- receiver – este parâmetro é usado pelas duas atividades Web no pipeline que enviam emails de êxito ou falha para o receptor cujos endereços de email são especificados por esse parâmetro.
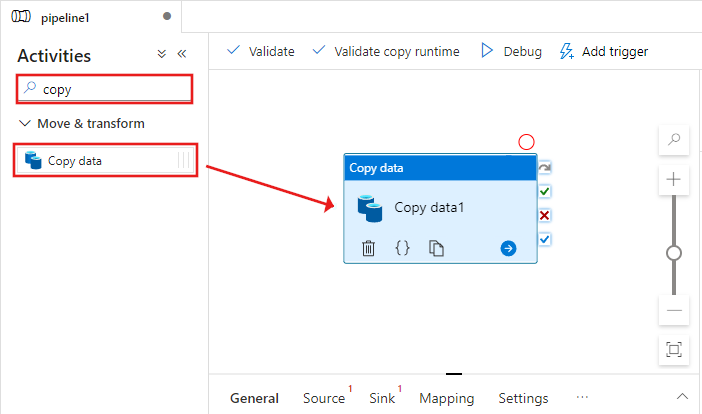
Na caixa de ferramentas Atividades, pesquise Copiar e arraste e solte a atividade Copiar na superfície do designer de pipeline.
Selecione a atividade Copiar que você arrastou para a superfície do designer de pipeline. Na janela Propriedades da atividade de Cópia, na parte inferior, alterne para a guia Origemguia e, em seguida, clique em + Novo. Você cria um conjunto de dados de origem para a atividade de cópia nesta etapa.
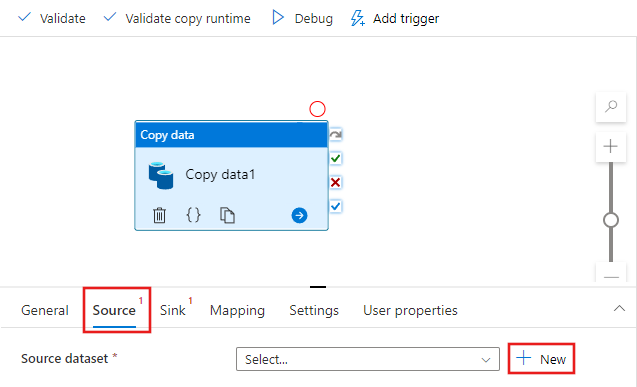
Na janela Novo Conjunto de Dados, selecione a guia Azure na parte superior, em seguida, escolha Armazenamento de Blobs do Azure e selecione Continuar.
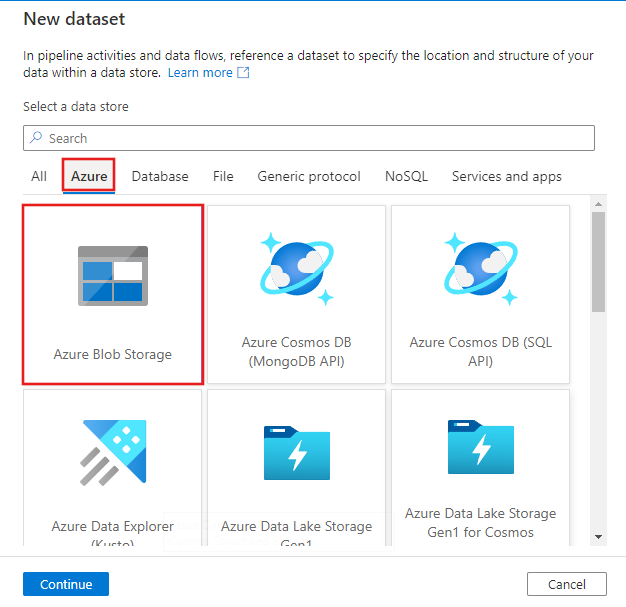
Na janela Selecionar formato, escolhaDelimitedText e selecione Continuar.

Você verá uma nova guia com o título Definir propriedades. Altere o nome do conjunto de dados para SourceBlobDataset. Selecione a lista suspensa Serviço Vinculado e escolha +Novo para criar um novo serviço vinculado ao conjunto de dados de origem.
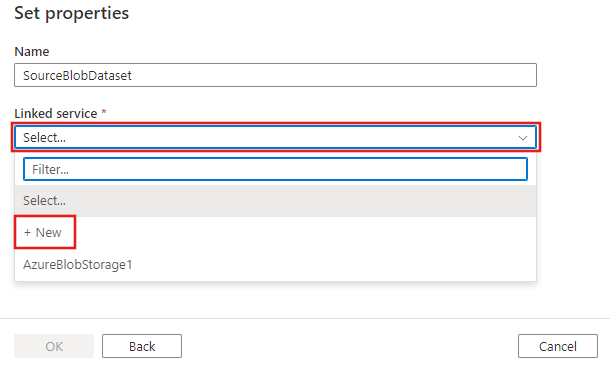 Serviço vinculado e aspas; dropdown.**" data-linktype="relative-path">
Serviço vinculado e aspas; dropdown.**" data-linktype="relative-path">
Você verá a janela Novo serviço vinculado, em que poderá preencher as propriedades necessárias para o serviço vinculado.
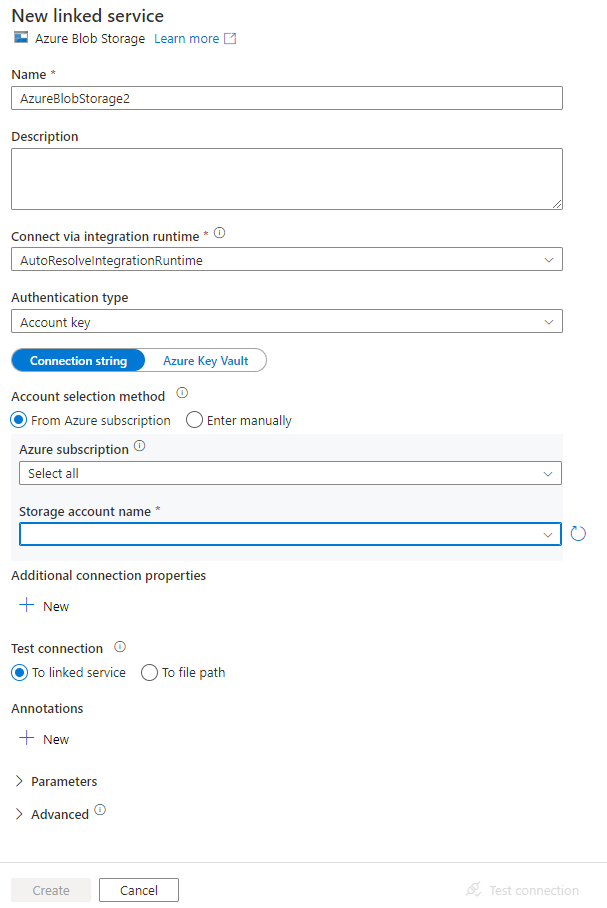
Na janela Novo Serviço Vinculado, execute as seguintes etapas:
- Insira AzureStorageLinkedService como o Nome.
- Selecione sua conta de armazenamento do Azure cmoo o Nome da conta de armazenamento.
- Clique em Criar.
Na janela Definir propriedades que aparece a seguir, selecione Abrir esse conjunto de dados para inserir um valor parametrizado ao nome do arquivo.
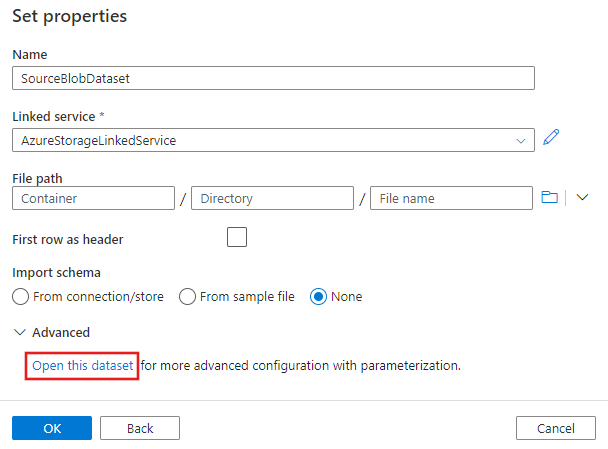
Insira
@pipeline().parameters.sourceBlobContainercomo a pasta eemp.txtcomo o nome do arquivo.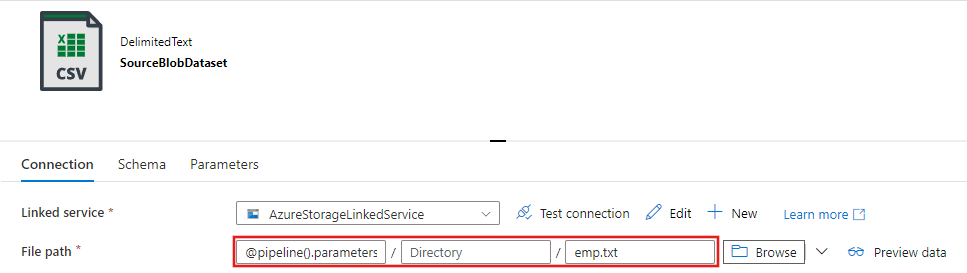
Volte para a guia pipeline (ou clique no pipeline no modo de exibição de árvore esquerdo) e selecione a atividade Copiar no designer. Confirme se o novo conjunto de dados está selecionado para Conjunto de Dados de Origem.
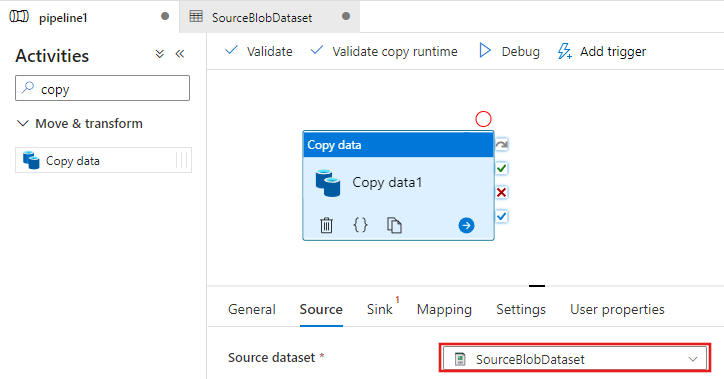
Na janela de propriedades, alterne para a guia Coletor e, em seguida, clique em + Novo para Conjunto de Dados do Coletor. Você cria um conjunto de dados do coletor para a atividade de cópia nesta etapa de forma semelhante a como você criou o conjunto de dados de origem.
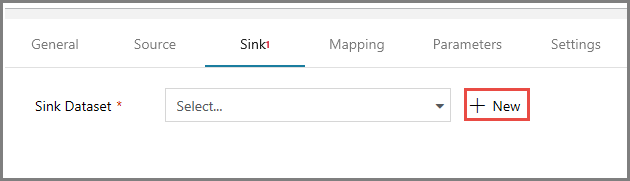
Na janela Novo Conjunto de Dados, selecione Armazenamento de Blobs do Azure e clique em Continuar e, em seguida, selecione DelimitedText novamente na janela Selecionar formato e clique novamente em Continuar.
Na página Definir propriedades para o conjunto de dados, insira SinkBlobDataset para Nome e selecione AzureStorageLinkedService para LinkedService.
Expanda a seção Avançado da página de propriedades e selecione Abrir esse conjunto de dados.
Na guia Conexão do conjunto de dados, edite o Caminho do arquivo. Insira
@pipeline().parameters.sinkBlobContainerpara a pasta e@concat(pipeline().RunId, '.txt')para o nome do arquivo. A expressão usa a ID da execução do pipeline atual como o nome do arquivo. Para obter a lista de expressões e variáveis do sistema com suporte, consulte Variáveis de sistema e Linguagem de expressão.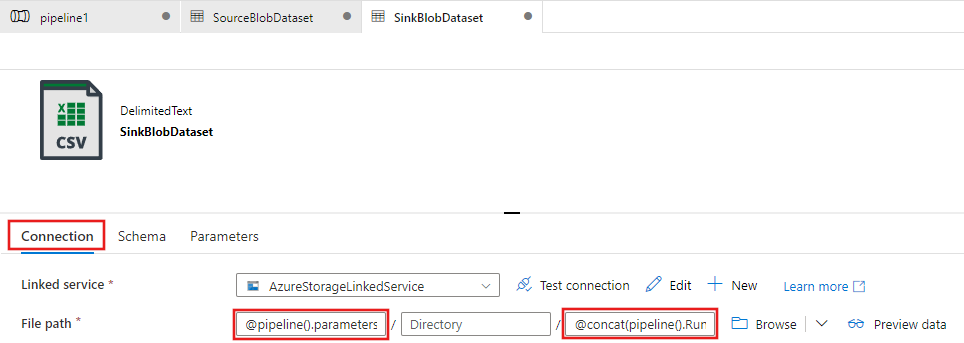
Volte para a guia do pipeline na parte superior. Pesquise Web na caixa de pesquisa e arraste e solte uma atividade da Web na superfície do designer de pipeline. Defina o nome da atividade como SendSuccessEmailActivity. A atividade da Web permite uma chamada para qualquer ponto de extremidade REST. Para obter mais informações sobre a atividade, consulte o artigo Atividade da Web. Esse pipeline usa uma atividade de Web para chamar o fluxo de trabalho de email de Aplicativos Lógicos.
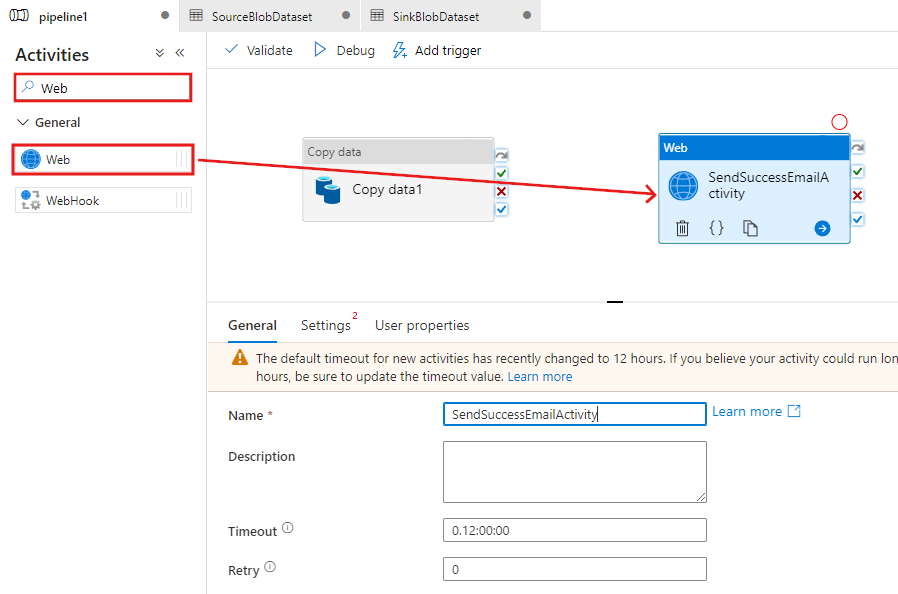
Alterne para a guia Configurações da guia Geral e siga as etapas a seguir:
Como a URL, especifique a URL para o fluxo de trabalho de aplicativos lógicos que envia o email de êxito.
Selecione POST para Método.
Clique no link + Adicionar cabeçalho na seção Cabeçalhos.
Adicione um cabeçalho Content-Type e defina-a como application/json.
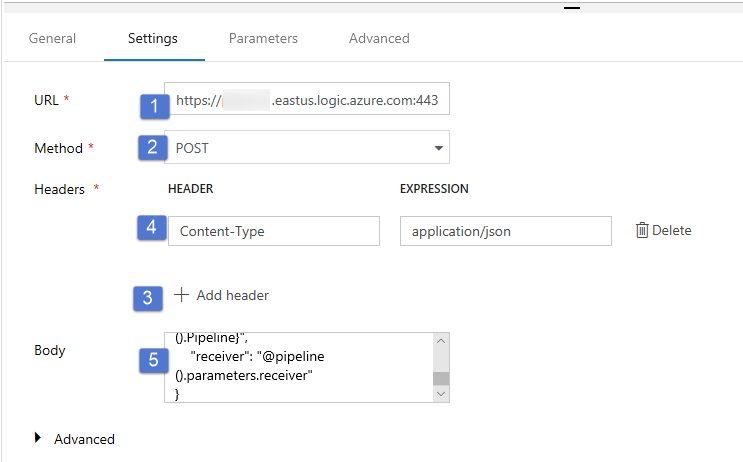
Especifique o JSON a seguir para Corpo.
{ "message": "@{activity('Copy1').output.dataWritten}", "dataFactoryName": "@{pipeline().DataFactory}", "pipelineName": "@{pipeline().Pipeline}", "receiver": "@pipeline().parameters.receiver" }O corpo da mensagem contém as seguintes propriedades:
Mensagem – passagem do valor de
@{activity('Copy1').output.dataWritten. Acessa uma propriedade da atividade de cópia anterior e passa o valor de dataWritten. Em caso de falha, passe a saída de erro em vez de@{activity('CopyBlobtoBlob').error.message.Nome do Data Factory – Passagem do valor de
@{pipeline().DataFactory}Essa é uma variável de sistema, permitindo que você acesse o nome do data factory correspondente. Para obter uma lista das variáveis de sistema, consulte o artigo Variáveis de Sistema.Nome do Pipeline – Passagem do valor de
@{pipeline().Pipeline}. Essa também é uma variável de sistema, permitindo que você acesse o nome do pipeline correspondente.Destinatário – passagem do valor de "pipeline().parameters.receiver"). Acessando os parâmetros de pipeline.
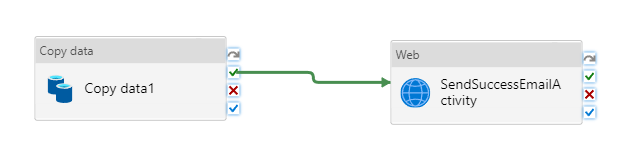
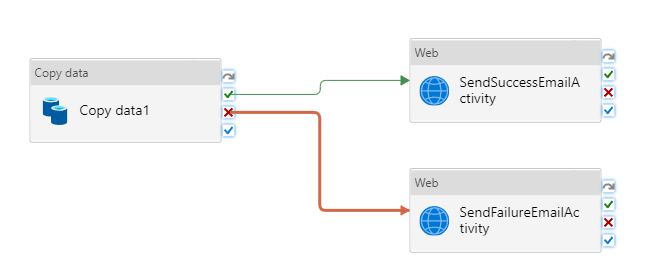
Conecte a atividade Copiar à atividade da Web arrastando o botão verde da caixa de seleção ao lado da atividade Copiar e soltando na atividade da Web.
Arraste e solte outra atividade da Web da caixa de ferramentas Atividades para a superfície do designer do pipeline e defina o nome como SendFailureEmailActivity.
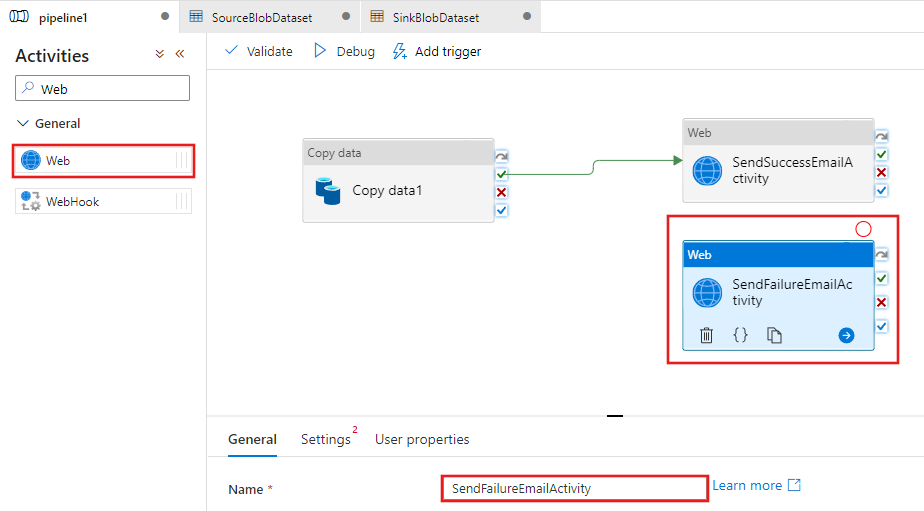
Alterne para a guia Configurações e siga estas etapas:
Como a URL, especifique a URL para o fluxo de trabalho de aplicativos lógicos que envia o email de falha.
Selecione POST para Método.
Clique no link + Adicionar cabeçalho na seção Cabeçalhos.
Adicione um cabeçalho Content-Type e defina-a como application/json.
Especifique o JSON a seguir para Corpo.
{ "message": "@{activity('Copy1').error.message}", "dataFactoryName": "@{pipeline().DataFactory}", "pipelineName": "@{pipeline().Pipeline}", "receiver": "@pipeline().parameters.receiver" }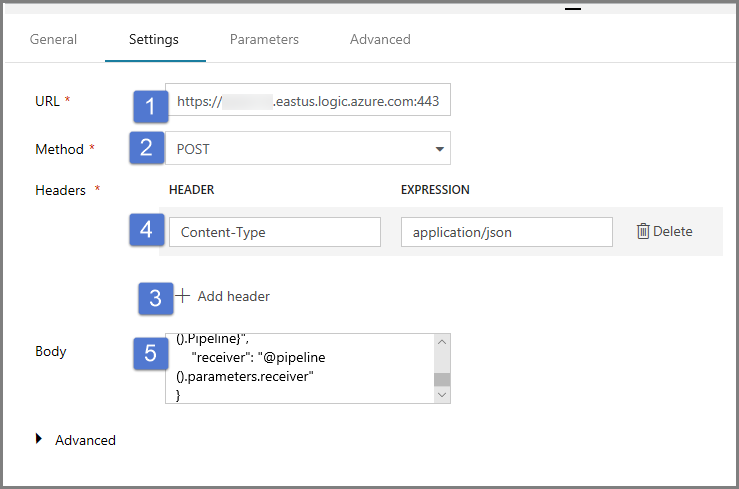
Selecione o botão X vermelho no lado direito da atividade Copiar no designer de pipeline e arraste e solte-o no SendFailureEmailActivity que você acabou de criar.
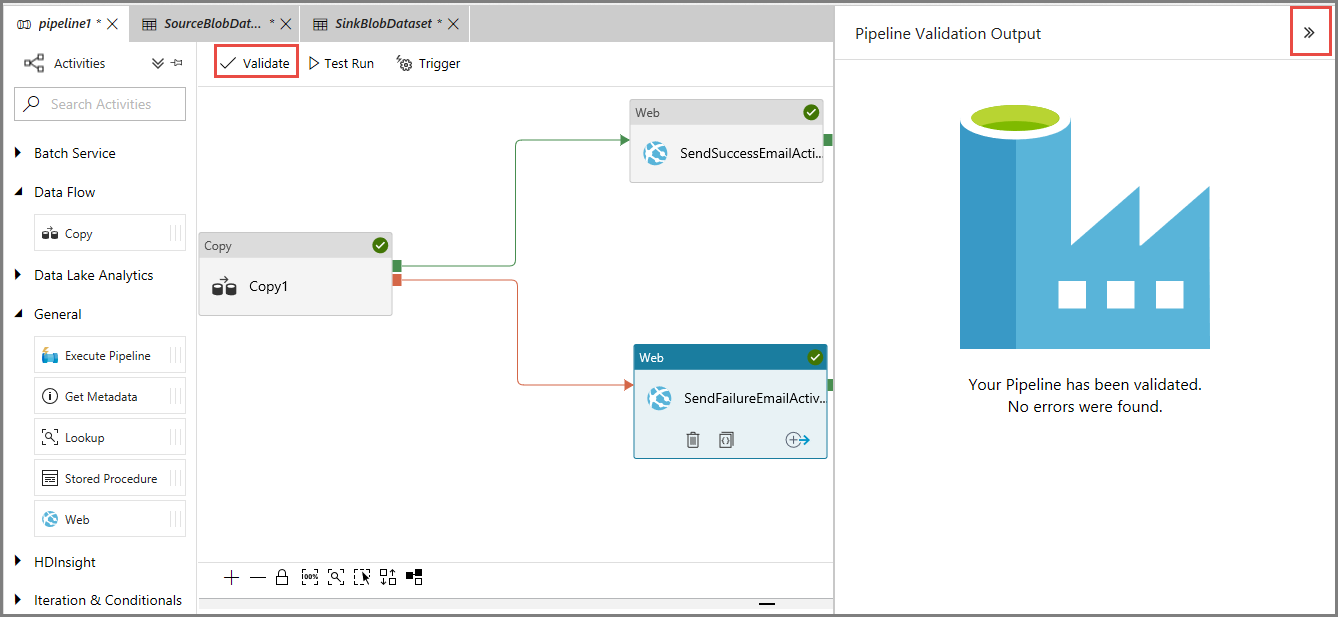
Para validar o pipeline, clique em Validar na barra de ferramentas. Feche a janela Saída da Validação do Pipeline clicando no botão >>.
Para publicar as entidades (conjuntos de dados, pipelines etc.) no serviço Data Factory, selecione Publicar tudo. Aguarde até que você veja a mensagem Publicado com êxito.

Disparar uma execução do pipeline com êxito
Para disparar uma execução de pipeline, clique em Disparar na barra de ferramentas e em Disparar Agora.
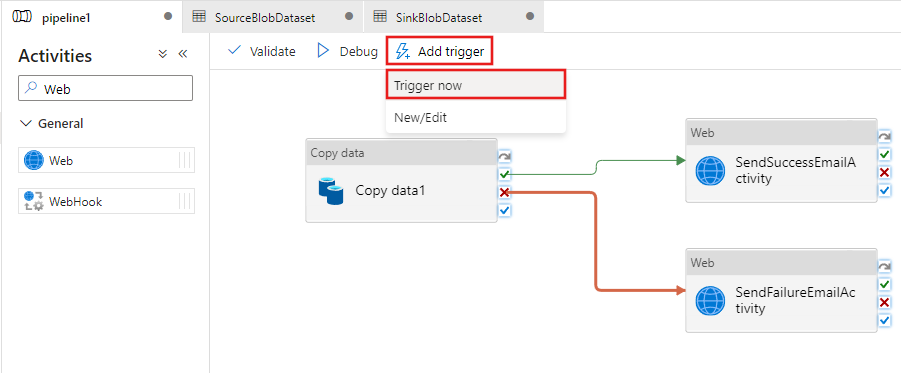
Na janela Execução de Pipeline, siga estas etapas:
Insira adftutorial/adfv2branch/input no parâmetro sourceBlobContainer.
Insira adfv2branch/adftutorial/saída como o parâmetro sinkBlobContainer.
Insira um endereço de email do receptor.
Clique em Concluir
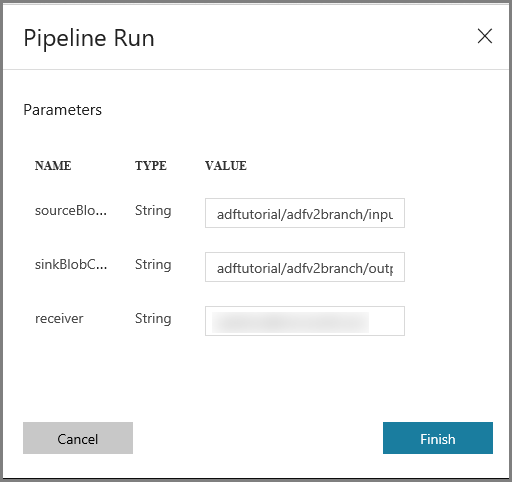
Monitorar a execução do pipeline com êxito
Para monitorar a execução do pipeline, alterne para a guia Monitorar à esquerda. Você verá a execução do pipeline disparada manualmente por você. Use o botão Atualizar para atualizar a lista.
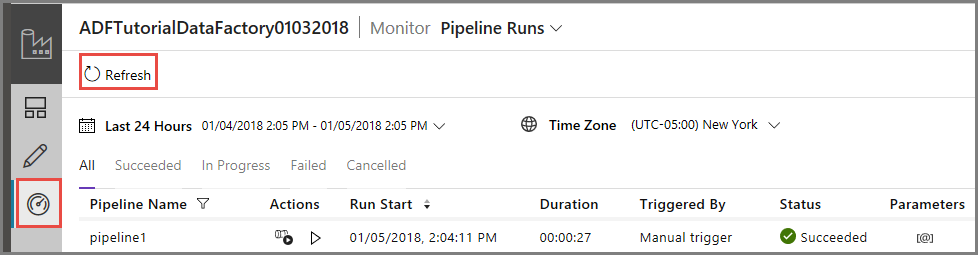
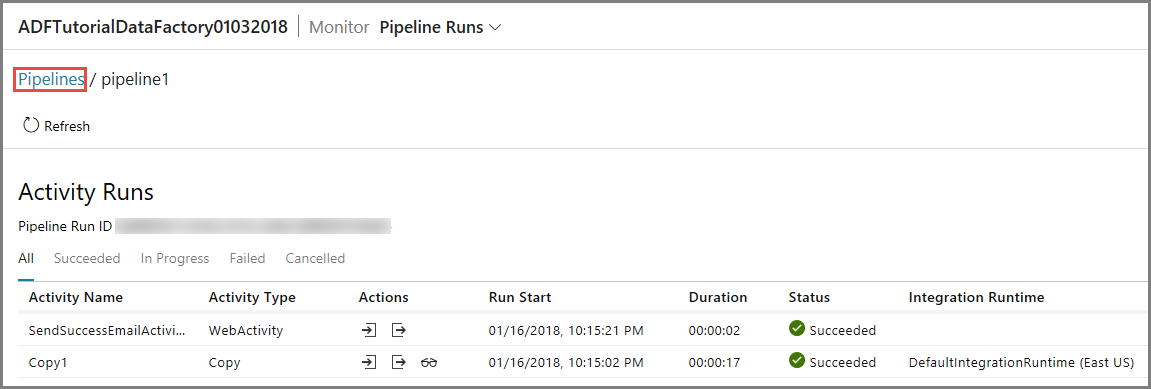
Para exibir execuções de atividade associadas a esta execução de pipeline, clique no primeiro link na coluna Ações. Você pode alternar para o modo de exibição anterior clicando em Pipelines na parte superior. Use o botão Atualizar para atualizar a lista.
Gatilho de uma execução do pipeline com falha
Alterne para a guia Editar à esquerda.
Para disparar uma execução de pipeline, clique em Disparar na barra de ferramentas e em Disparar Agora.
Na janela Execução de Pipeline, siga estas etapas:
- Insira adftutorial/dummy/inputt no parâmetro sourceBlobContainer. Certifique-se de que a pasta fictícia não existe no contêiner adftutorial.
- Insira adftutorial/dummy/output no parâmetro sinkBlobContainer.
- Insira um endereço de email do receptor.
- Clique em Concluir.
Monitorar a execução do pipeline com falha
Para monitorar a execução do pipeline, alterne para a guia Monitorar à esquerda. Você verá a execução do pipeline disparada manualmente por você. Use o botão Atualizar para atualizar a lista.
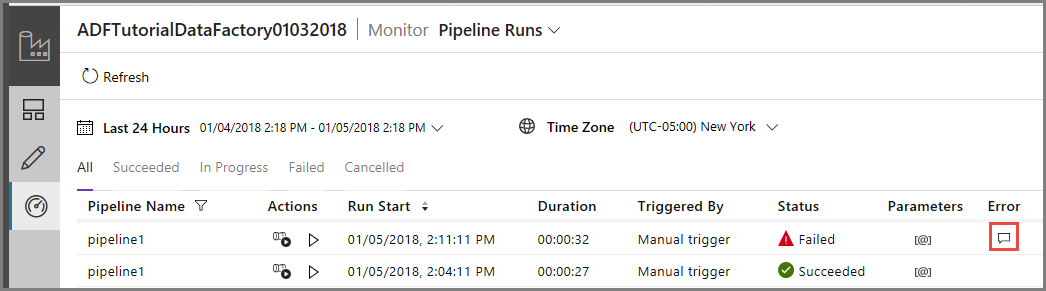
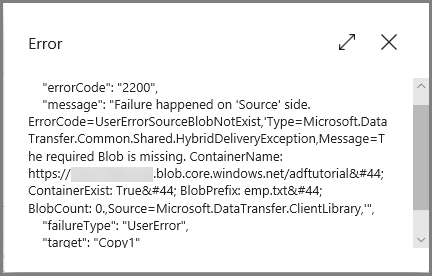
Clique no link Erro para a execução do pipeline para ver detalhes sobre o erro.

Para exibir execuções de atividade associadas a esta execução de pipeline, clique no primeiro link na coluna Ações. Use o botão Atualizar para atualizar a lista. Observe que a atividade Cópia no pipeline falhou. A atividade da Web foi bem-sucedida ao enviar o email de falha para o destinatário especificado.
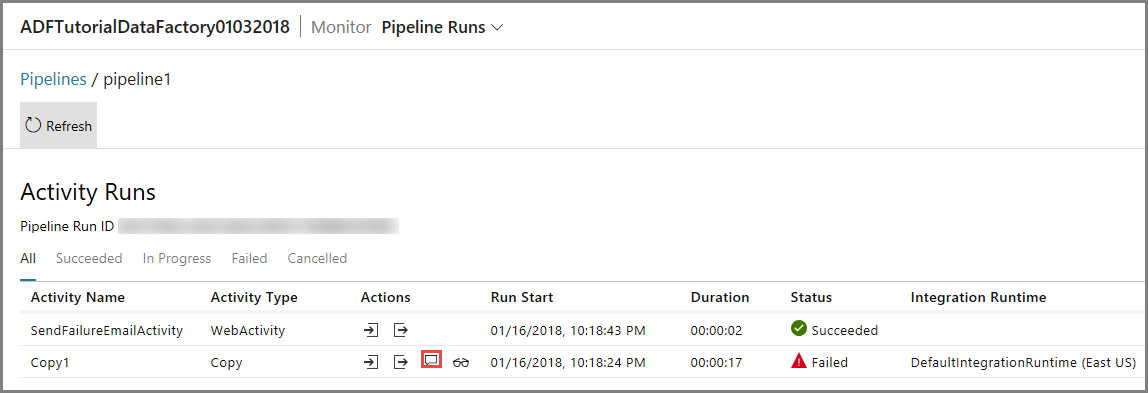
Clique no link Erro na coluna Ações para ver os detalhes sobre o erro.
Conteúdo relacionado
Neste tutorial, você realizará os seguintes procedimentos:
- Criar um data factory.
- Criar um serviço vinculado do Armazenamento do Azure.
- Criar um conjunto de dados do Blob do Azure
- Criar um pipeline que contém uma atividade de cópia e uma atividade da Web
- Enviar saídas de atividades para as atividades subsequentes
- Utilizar passagem de parâmetros e variáveis do sistema
- Iniciar uma execução de pipeline
- Monitorar as execuções de pipeline e de atividade
Agora você pode seguir para a seção Conceitos para obter mais informações sobre o Azure Data Factory.