Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Se você não estiver familiarizado com Azure Data Factory, consulte Introduction para Azure Data Factory.
Neste tutorial, você usará a interface do usuário (interface do usuário) do Data Factory para criar um pipeline que copia e transforma dados de uma fonte de Azure Data Lake Storage Gen2 para um coletor de Data Lake Storage Gen2 (ambos permitindo o acesso somente a redes selecionadas) usando o fluxo de dados de mapeamento no Data Factory Managed Rede Virtual. É possível expandir o padrão de configuração neste tutorial ao transformar dados usando o fluxo de dados de mapeamento.
Neste tutorial, você executa as seguintes etapas:
- Criar uma fábrica de dados.
- Crie um pipeline com uma atividade de fluxo de dados.
- Crie um fluxo de dados de mapeamento com quatro transformações.
- Executar teste do pipeline.
- Monitorar uma atividade de fluxo de dados.
Pré-requisitos
- Assinatura do Azure. Se você não tiver uma assinatura Azure, crie uma conta de Azure free antes de começar.
- Azure conta de armazenamento. Use o Data Lake Store como armazenamentos de dados de origem e de coletor. Se você não tiver uma conta de armazenamento, consulte Criar uma conta de armazenamento Azure para ver as etapas para criar uma. Verifique se a conta de armazenamento permite acesso somente de redes selecionadas.
O arquivo que transformaremos neste tutorial é moviesDB.csv, que pode ser encontrado neste site de conteúdo GitHub. Para recuperar o arquivo de GitHub, copie o conteúdo para um editor de texto de sua escolha para salvá-lo localmente como um arquivo .csv. Para carregar o arquivo em sua conta de armazenamento, consulte Upload blobs com o portal Azure. Os exemplos farão referência a um contêiner chamado sample-data.
Criar uma fábrica de dados
Nesta etapa, crie uma Fábrica de Dados e inicie a interface do usuário da Fábrica de Dados para criar um pipeline na Fábrica de Dados.
Abra Microsoft Edge ou Google Chrome. Atualmente, apenas navegadores da Web Microsoft Edge e do Google Chrome dão suporte à interface do usuário do Data Factory.
No menu à esquerda, selecione Criar um recurso>Analytics>Data Factory.
Na página Novo fábrica de dados, em Nome, insira ADFTutorialDataFactory.
O nome da fábrica de dados deve ser globalmente exclusivo. Se você receber uma mensagem de erro sobre o valor do nome, insira um nome diferente para a fábrica de dados (por exemplo, yournameADFTutorialDataFactory). Para ver as regras de nomenclatura para artefatos do Data Factory, confira Data Factory – Regras de nomenclatura.
Selecione a assinatura do Azure na qual você deseja criar a fábrica de dados.
Em Grupo de Recursos, use uma das seguintes etapas:
- Selecione Usar existente e selecione um grupo de recursos existente na lista suspensa.
- Selecione Criar novoe insira o nome de um grupo de recursos.
Para saber mais sobre grupos de recursos, consulte Use grupos de recursos para gerenciar seus recursos Azure.
Em Versão, selecione V2.
Em Local, selecione uma localização para o Data Factory. Apenas os locais com suporte aparecem na lista suspensa. Armazenamentos de dados (por exemplo, Armazenamento do Azure e Banco de Dados SQL do Azure) e cálculos (por exemplo, Azure HDInsight) usados pelo data factory podem estar em outras regiões.
Selecione Criar.
Depois que a criação for concluída, você verá o aviso no Centro de notificações. Selecione Ir para o recurso para ir até a página do Data Factory.
Selecione Open Azure Data Factory Studio para iniciar a interface do usuário do Data Factory em uma guia separada.
Criar um IR do Azure na Rede Virtual Gerenciada do Data Factory
Nesta etapa, você criará uma Azure IR e habilitará a Rede Virtual Gerenciada do Data Factory.
No portal do Data Factory, acesse Manage e selecione New para criar uma nova Azure IR.
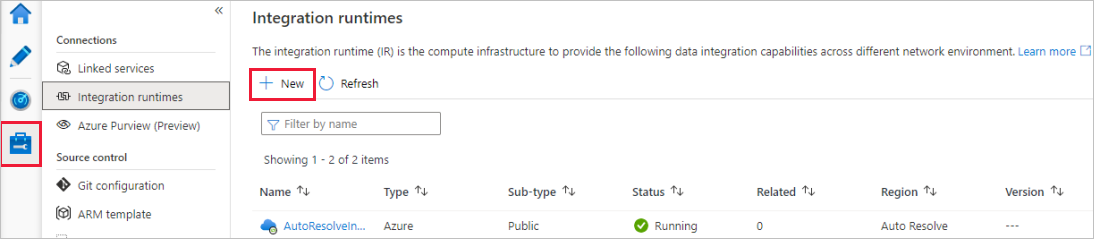
Na página Instalação do runtime de integração, escolha o runtime de integração a ser criado com base nas funcionalidades necessárias. Neste tutorial, selecione Azure, Auto-Hospedado e clique em Continue.
Selecione Azure e clique em Continue para criar um runtime do Azure Integration.
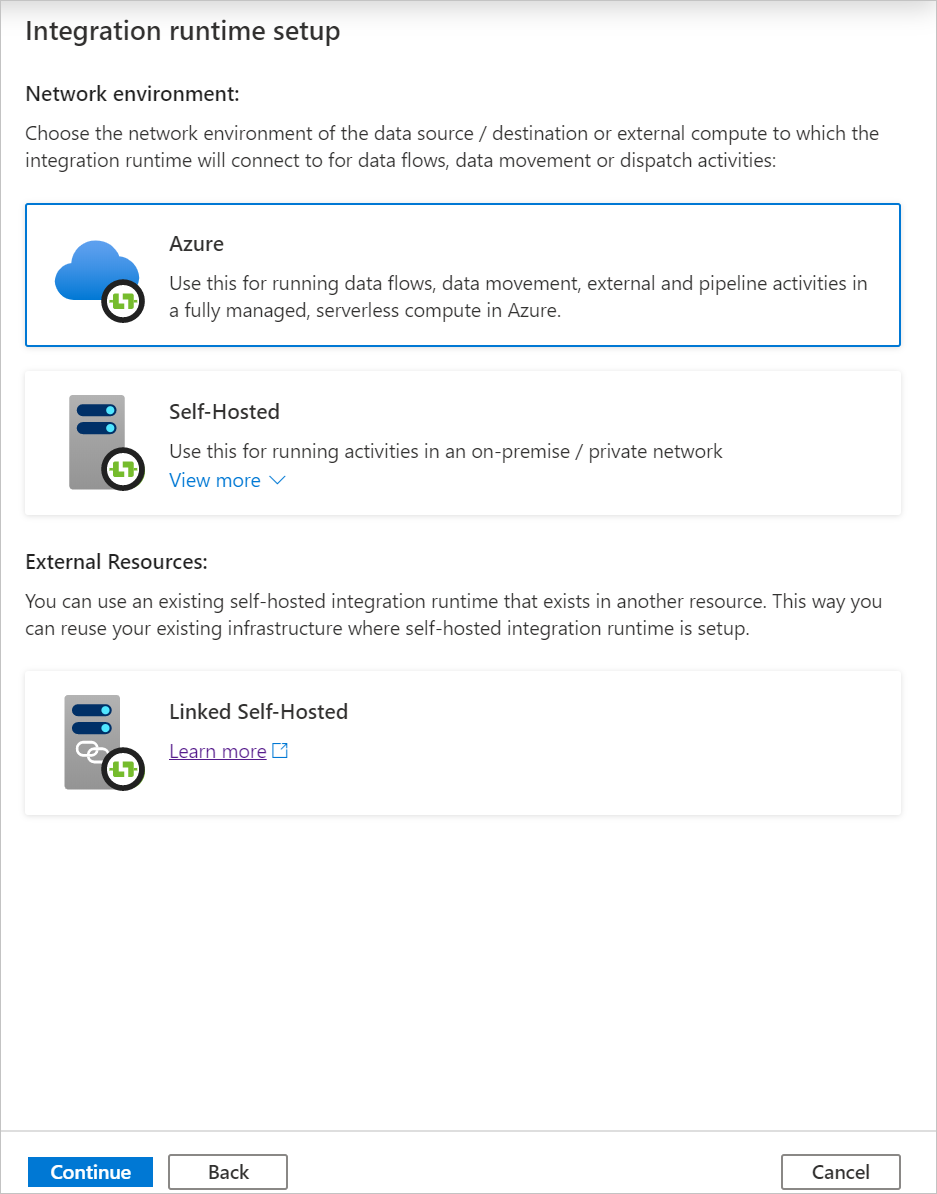
Em Configuração de rede virtual (versão prévia) , selecione Habilitar.
Selecione Criar.
Criar um pipeline com uma atividade de fluxo de dados
Nesta etapa, você criará um pipeline contendo uma atividade de fluxo de dados.
Na home page do Azure Data Factory, selecione Orchestrate.
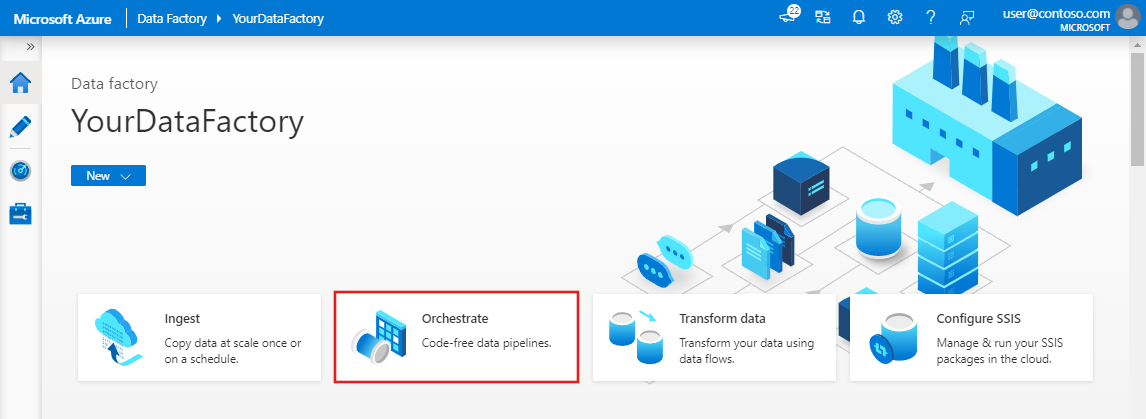
No painel de propriedades do pipeline, insira TransformMovies como o nome do pipeline.
No painel Atividades, expanda Mover e Transformar. Arraste a atividade de Fluxo de Dados do painel para a tela do pipeline.
Na janela pop-up Adicionar fluxo de dados, selecione Criar novo fluxo de dados e, em seguida, selecione Fluxo de Dados de Mapeamento. Quando tiver terminado, selecione OK.
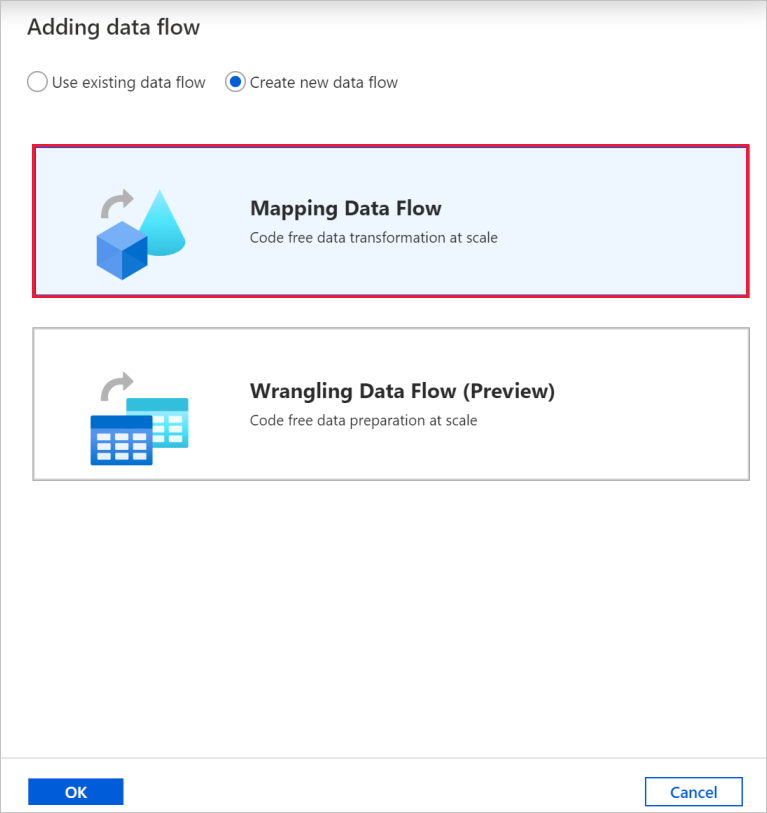
Dê ao fluxo de dados o nome de TransformMovies no painel Propriedades.
Na barra superior da tela do pipeline, deslize o controle deslizante Depurar fluxo de dados. O modo de depuração permite o teste interativo da lógica de transformação em um cluster do Spark em execução. Fluxo de Dados clusters levam de 5 a 7 minutos para aquecer, e é recomendado que os usuários ativem a depuração antes, se planejam desenvolver no Fluxo de Dados. Para saber mais, consulte Modo de depuração.

Criar lógica de transformação na tela de fluxo de dados
Depois de criar o fluxo de dados, você será automaticamente direcionado para a interface do fluxo de dados. Nesta etapa, você criará um fluxo de dados que usa o arquivo de moviesDB.csv em Data Lake Storage e agregará a classificação média de comedies de 1910 a 2000. Em seguida, você gravará esse arquivo novamente no Data Lake Storage.
Adicionar a transformação de origem
Nesta etapa, você configura Data Lake Storage Gen2 como uma origem.
Na tela fluxo de dados, adicione uma origem clicando na caixa Adicionar origem.
Nomeie sua fonte MoviesDB. Selecione Novo para criar um conjunto de dados de origem.
Selecione Azure Data Lake Storage Gen2 e selecione Continue.
Selecione DelimitedText e clique em Continuar.
Dê um nome ao conjunto de dados MovieDB. Na lista suspensa de serviço vinculado, selecione Novo.
Na tela de criação de serviço vinculado, nomeie seu serviço vinculado Data Lake Storage Gen2 ADLSGen2 e especifique seu método de autenticação. Em seguida, insira suas credenciais de conexão. Neste tutorial, estamos usando a Chave de conta para nos conectar à nossa conta de armazenamento.
Certifique-se de que você ative a Criação interativa. Pode levar um minuto para habilitar essa opção.

Selecione Testar conexão. Ela deve falhar porque a conta de armazenamento não habilita o acesso a ela sem a criação e a aprovação de um ponto de extremidade privado. Na mensagem de erro, você verá um link para criar um ponto de extremidade privado que poderá seguir para criar um ponto de extremidade privado gerenciado. Uma alternativa é acessar diretamente a guia Gerenciar e seguir as instruções desta seção para criar um ponto de extremidade privado gerenciado.
Mantenha a caixa de diálogo aberta e acesse sua conta de armazenamento.
Siga as instruções desta seção para aprovar o link privado.
Volte à caixa de diálogo. Selecione novamente Testar conectividade e selecione Criar para implantar o serviço vinculado.
Na tela de criação do conjunto de dados, insira onde o arquivo está localizado no campo Caminho do arquivo. Neste tutorial, o arquivo moviesDB.csv está localizado no contêiner sample-data. Como o arquivo tem cabeçalhos, marque a caixa de seleção Primeira linha como cabeçalho. Selecione Do repositório/conexão para importar o esquema de cabeçalho diretamente do arquivo no armazenamento. Quando tiver terminado, selecione OK.
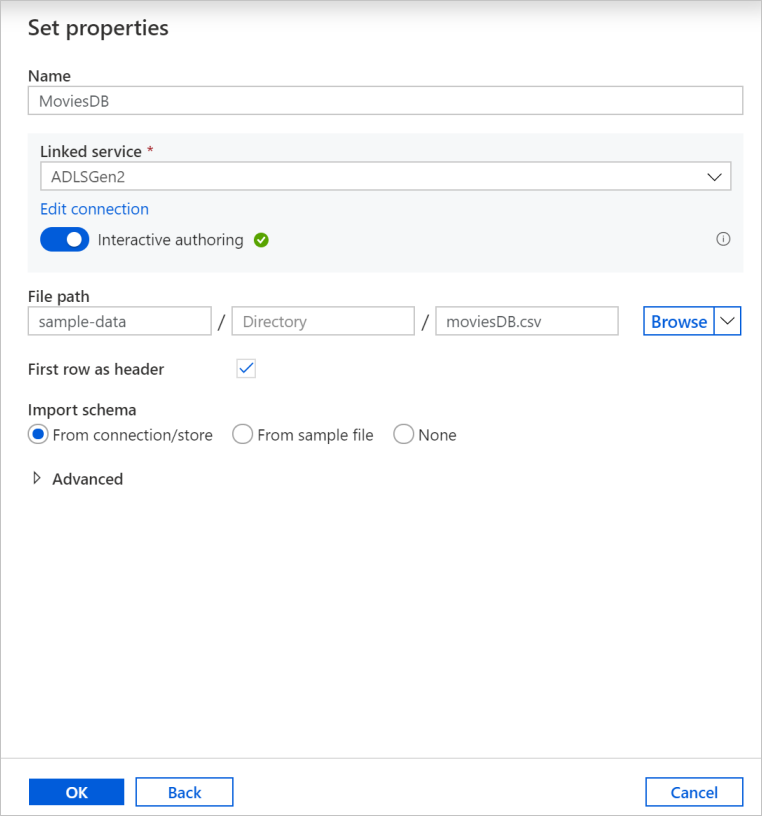
Se o cluster de depuração for iniciado, vá para a guia Visualização de Dados da transformação de origem e selecione Atualizar para obter um instantâneo dos dados. É possível usar a visualização de dados para verificar se a transformação está configurada corretamente.
Criar um ponto de extremidade privado gerenciado
Se não usou o hiperlink quando testou a conexão anterior, siga o caminho. Agora você precisará criar um ponto de extremidade privado gerenciado que será conectado ao serviço vinculado que você criou.
Acesse a guia Gerenciar.
Observação
É possível que a guia Gerenciar não fique disponível para todas as instâncias do Data Factory. Se você não o vir, poderá acessar os pontos de extremidade privados selecionando Autor>Conexões>Ponto de Extremidade Privado.
Acesse a seção Pontos de extremidade privados gerenciados.
Selecione + Novo em Pontos de extremidade privados gerenciados.
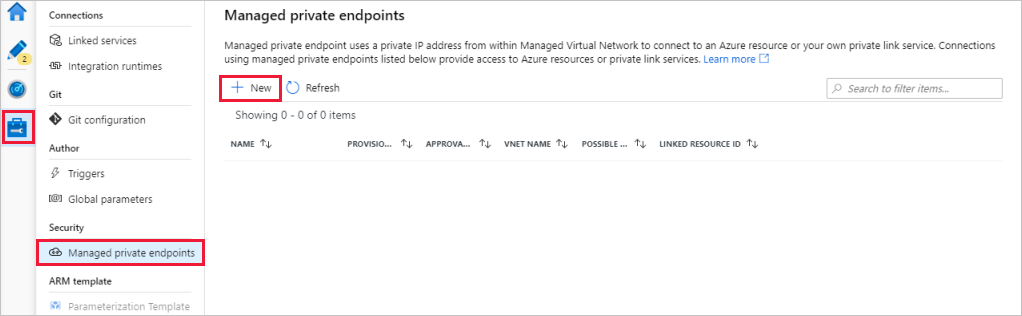
Selecione o bloco Azure Data Lake Storage Gen2 na lista e selecione Continue.
Insira o nome da conta de armazenamento criada.
Selecione Criar.
Depois de alguns segundos, você verá que o link privado criado precisa de uma aprovação.
Selecione o ponto de extremidade privado que você criou. Você verá um hiperlink que vai levar você à aprovação do ponto de extremidade privado no nível da conta de armazenamento.
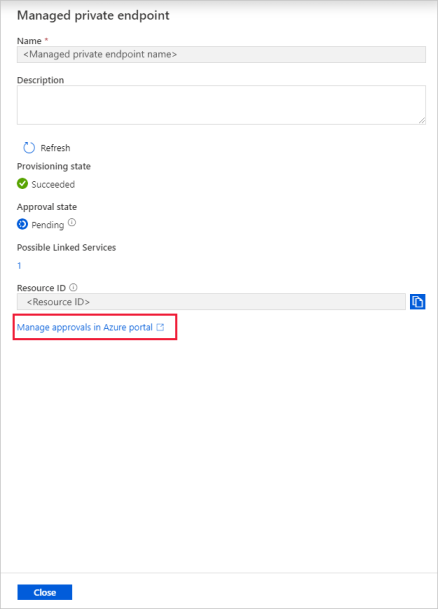
Aprovação de um link privado em uma conta de armazenamento
Na conta de armazenamento, acesse Conexões do ponto de extremidade privado na seção Configurações.
Marque a caixa de seleção ao lado do ponto de extremidade privado que você criou e selecione Aprovar.
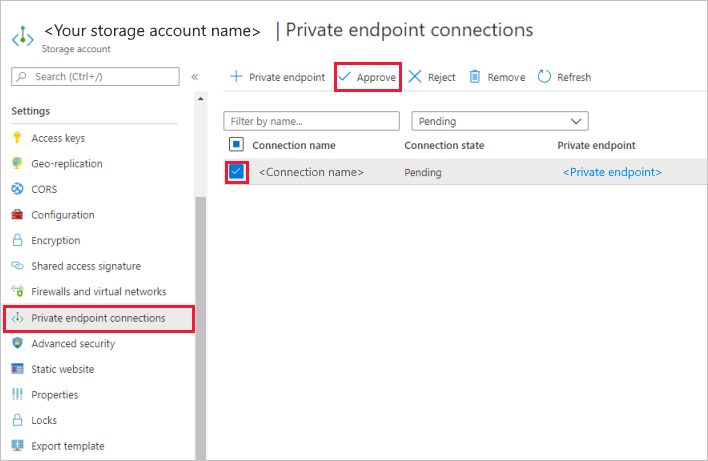
Adicione uma descrição e selecione sim.
Volte à seção Pontos de extremidade privados gerenciados da guia Gerenciar no Data Factory.
Após cerca de um minuto, a aprovação deverá ser exibida para o ponto de extremidade privado.
Adicionar a transformação de filtro
Ao lado do nó de origem na tela fluxo de dados, selecione o ícone de adição para adicionar uma nova transformação. A primeira transformação que será adicionada é um Filtro.
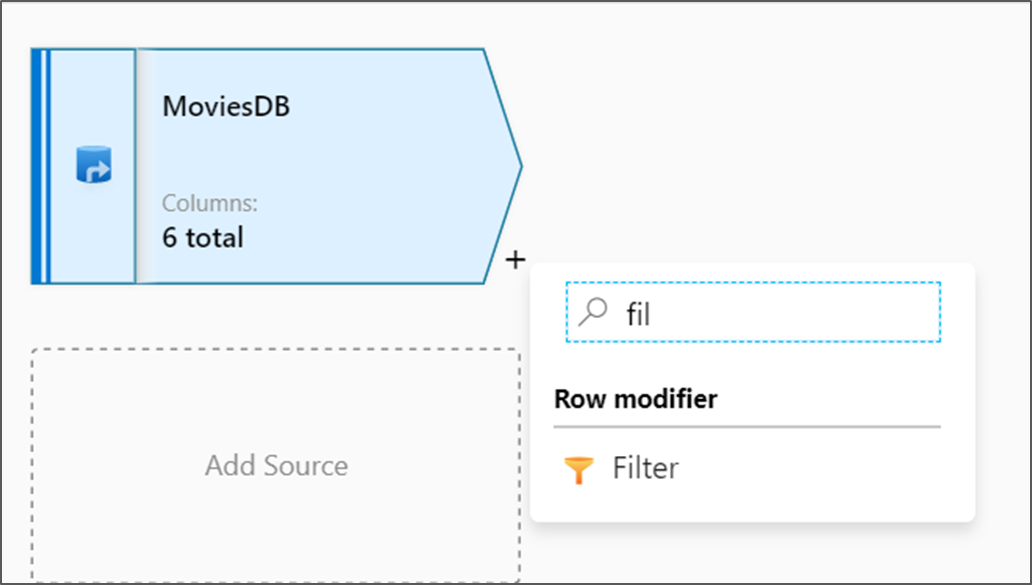
Nomeie sua transformação de filtro FilterYears. Selecione a caixa de expressão ao lado de Filtrar por para abrir o construtor de expressões. Aqui você especificará sua condição de filtragem.
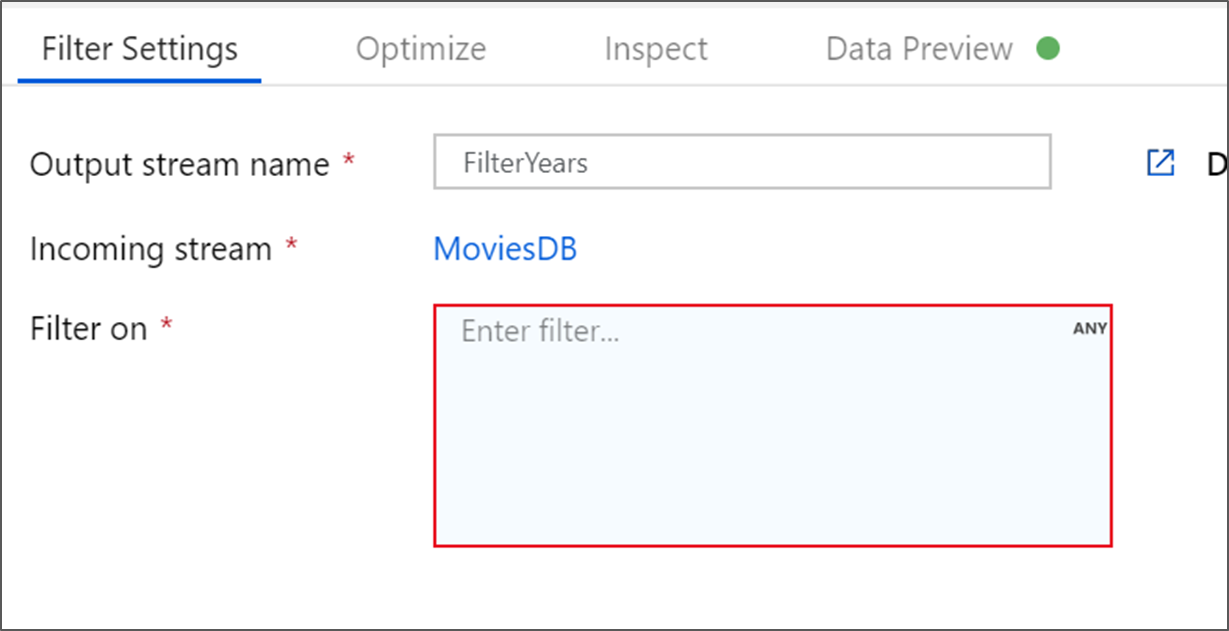
O construtor de expressões de fluxo de dados permite criar expressões de forma interativa para uso em várias transformações. As expressões podem incluir funções internas, colunas do esquema de entrada e parâmetros definidos pelo usuário. Para obter mais informações sobre como criar expressões, consulte Construtor de expressões de fluxo de dados.
Neste tutorial, se deseja filtrar filmes do gênero comédia lançados entre os anos 1910 e 2000. Como o ano é atualmente uma cadeia de caracteres, você precisará convertê-lo em um inteiro usando a função
toInteger(). Utilize os operadores maior que ou igual a (>=) e menor que ou igual a (<=) para comparar os valores de anos literais entre 1910 e 2000. Reúna essas expressões com o operador and (&&). A expressão é apresentada como:toInteger(year) >= 1910 && toInteger(year) <= 2000Para descobrir quais filmes são comedies, é possível usar a função
rlike()para localizar o padrão 'Comédia' na coluna de gêneros. Una a expressãorlikeà comparação do ano para obter:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')Caso tenha um cluster de depuração ativo, é possível verificar a lógica selecionando Atualizar para ver a saída da expressão em comparação com as entradas usadas. Há mais de uma resposta certa sobre como realizar essa lógica usando a linguagem de expressão de fluxo de dados.
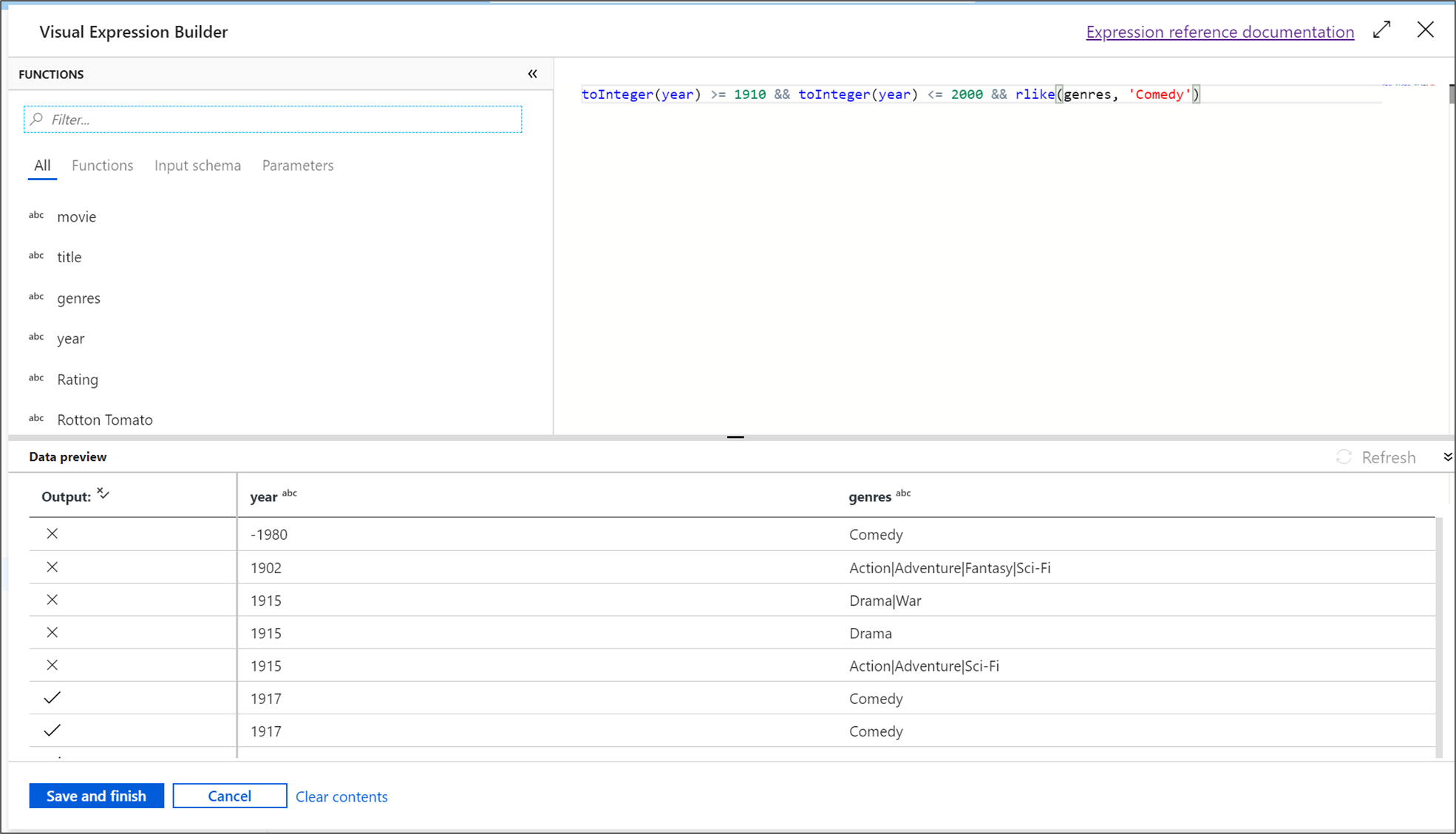
Selecione Salvar e concluir depois de concluir a expressão.
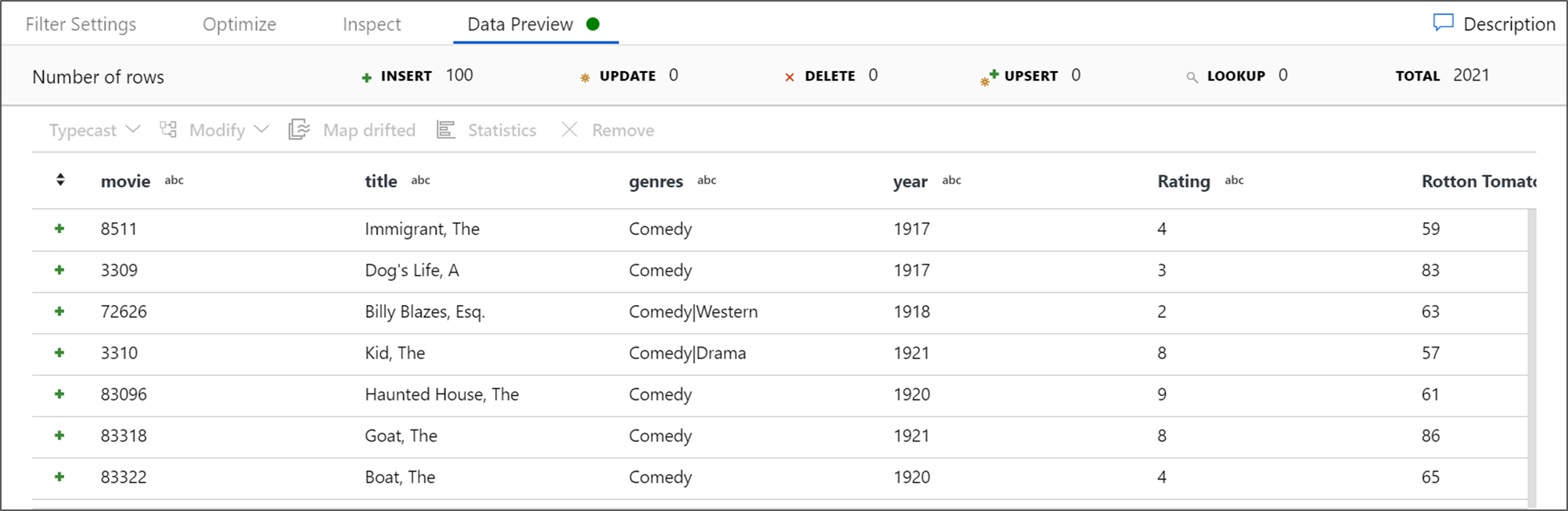
Obtenha uma Visualização de Dados para verificar se o filtro está funcionando corretamente.
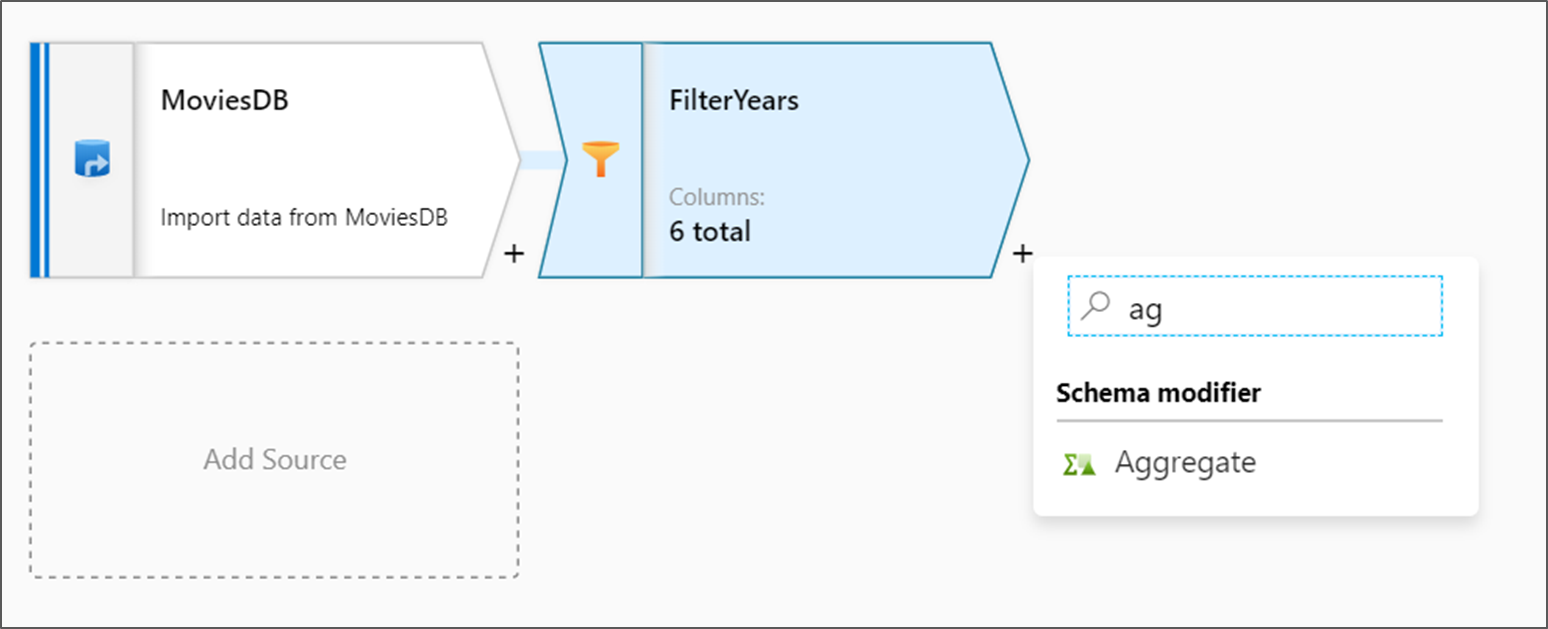
Adicionar a transformação de agregação
A próxima transformação que você adicionará é uma transformação de Agregação em Modificador de Esquema.
Dê à transformação de agregação o nome de AggregateComedyRating. Na guia Agrupar por, selecione ano na lista suspensa para agrupar as agregações pelo ano em que o filme foi lançado.
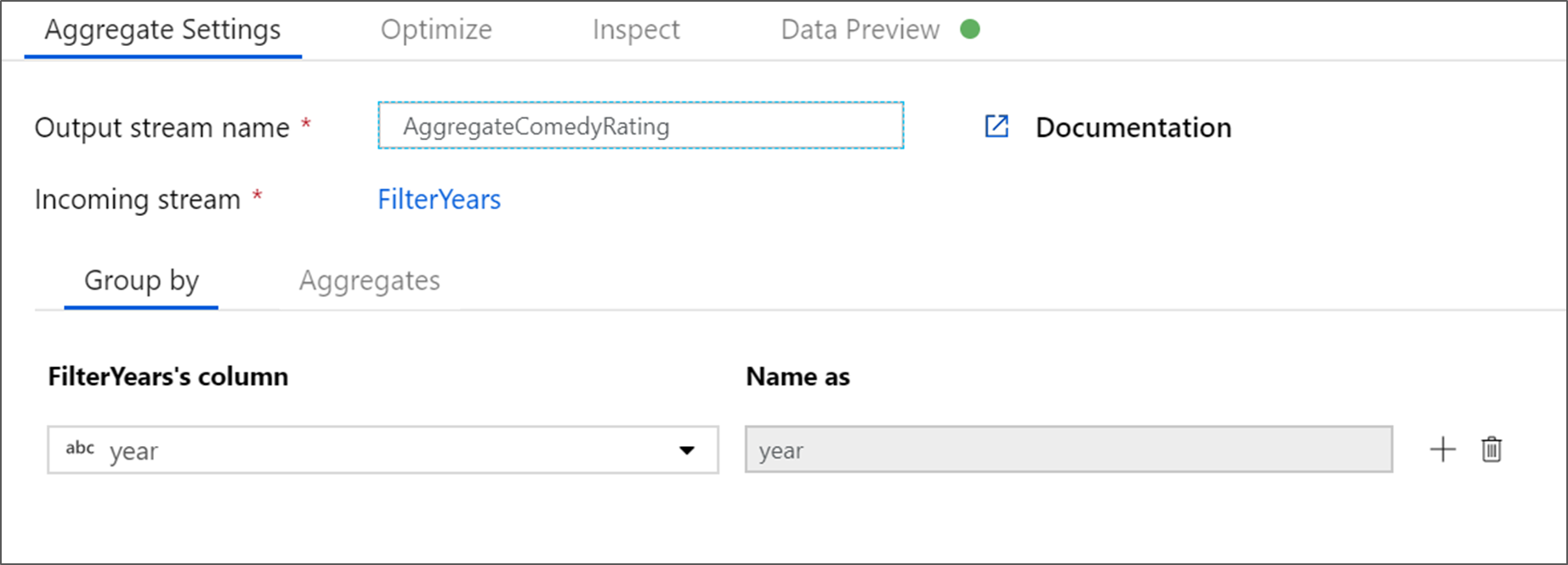
Vá para a guia Agregações. Na caixa de texto à esquerda, nomeie a coluna de agregação AverageComedyRating. Selecione a caixa de expressão à direita para inserir a expressão de agregação por meio do construtor de expressões.
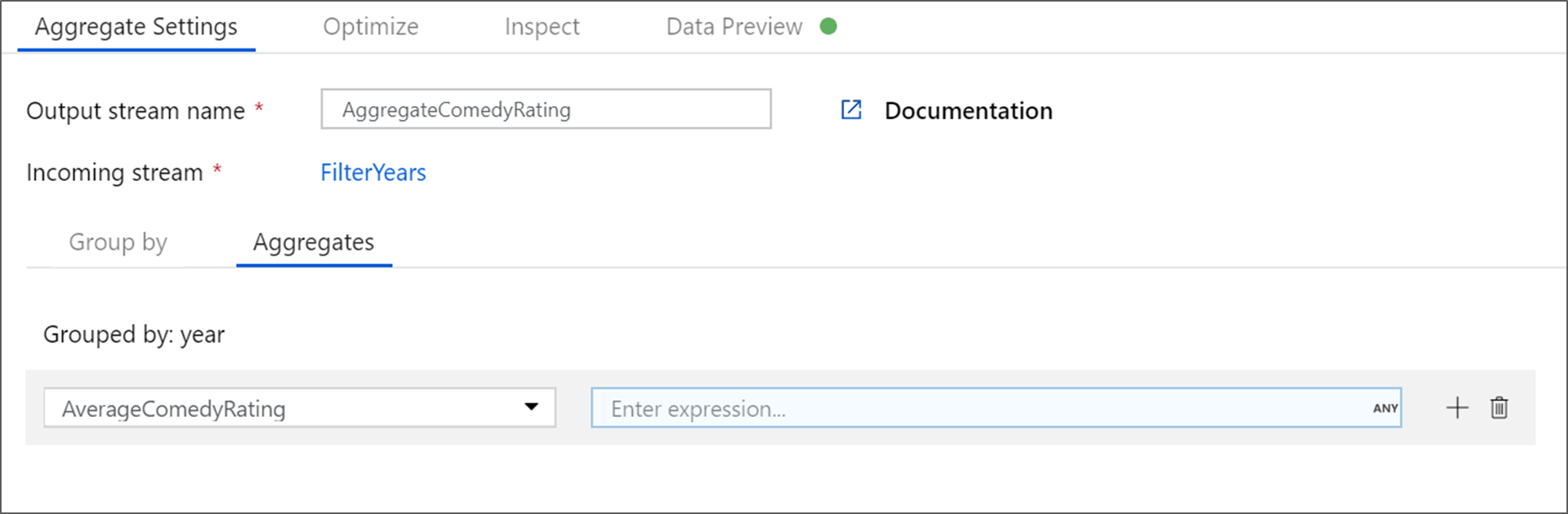
Para obter a média da coluna Rating, use a função de agregação
avg(). Como a Classificação é uma cadeia de caracteres eavg()usa uma entrada numérica, devemos converter o valor em um número por meio da funçãotoInteger(). Essa expressão é semelhante a:avg(toInteger(Rating))Selecione Salvar e concluir depois que terminar.

Vá para a guia Visualização de dados para exibir a saída da transformação. Observe que apenas duas colunas estão lá, ano e AverageComedyRating.
Adicionar a transformação de coletor
Em seguida, adicione uma transformação de Sink em Destino.
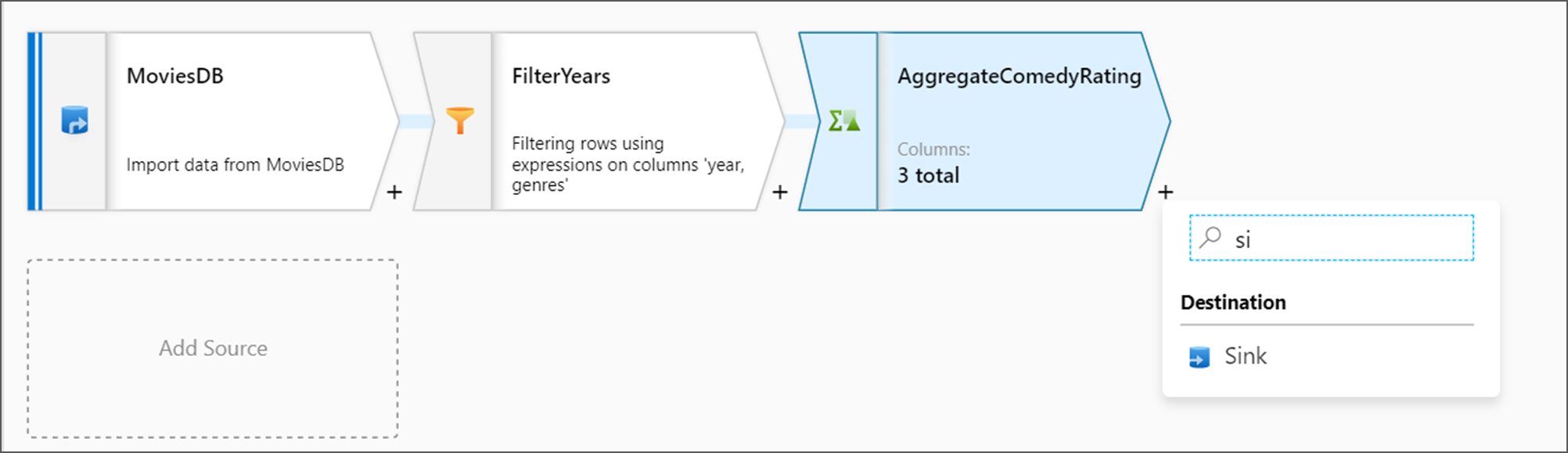
Dê ao seu sink o nome Sink. Selecione Novo para criar o conjunto de dados do coletor.
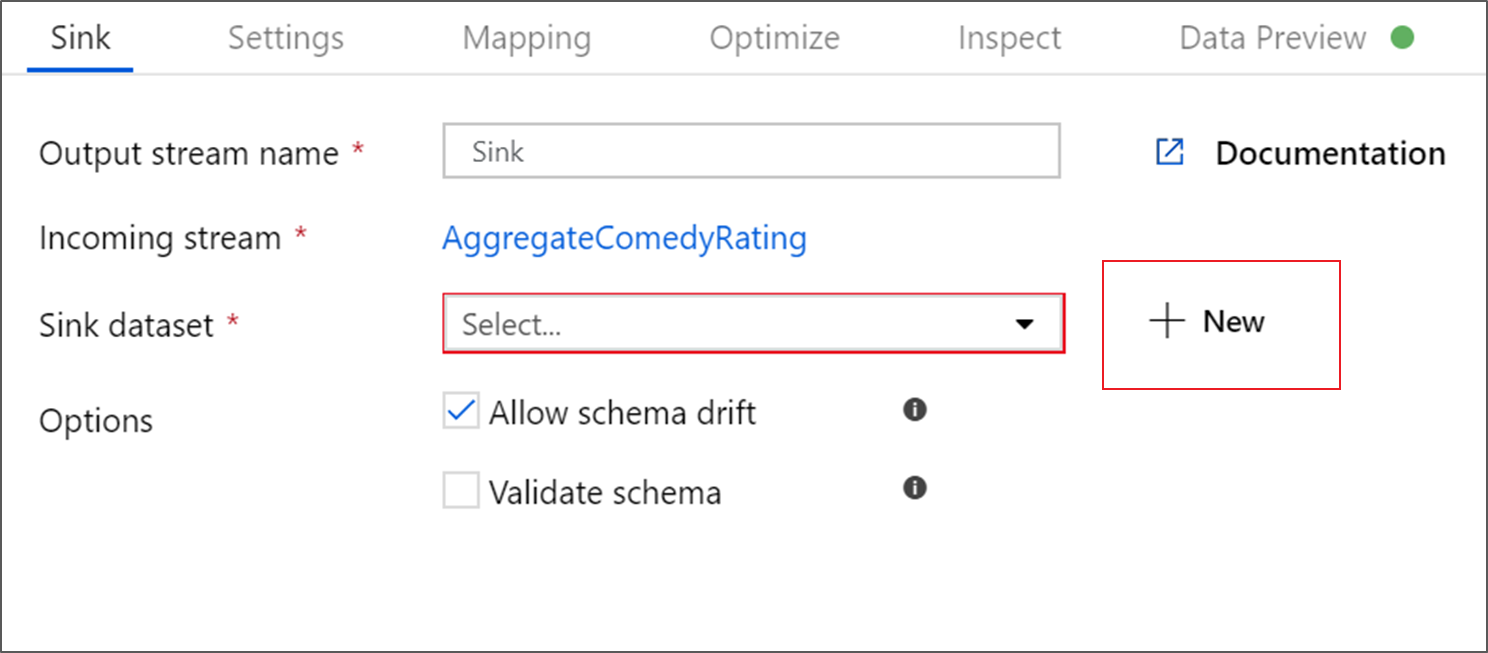
Na página New dataset, selecione Azure Data Lake Storage Gen2 e selecione Continue.
Na página Selecionar formato, selecione DelimitedText e, em seguida, selecione Continuar.
Dê ao seu conjunto de dados de destino o nome MoviesSink. Para o serviço vinculado, escolha o mesmo serviço vinculado do ADLSGen2 criado para a transformação de origem. Insira uma pasta de saída na qual os dados são gravados. Neste tutorial, gravamos na pasta saída no contêiner sample-data. A pasta não precisa existir com antecedência e pode ser criada dinamicamente. Selecione a caixa de seleção Primeira linha como cabeçalho e selecione Nenhum para Importar o esquema. Selecione OK.
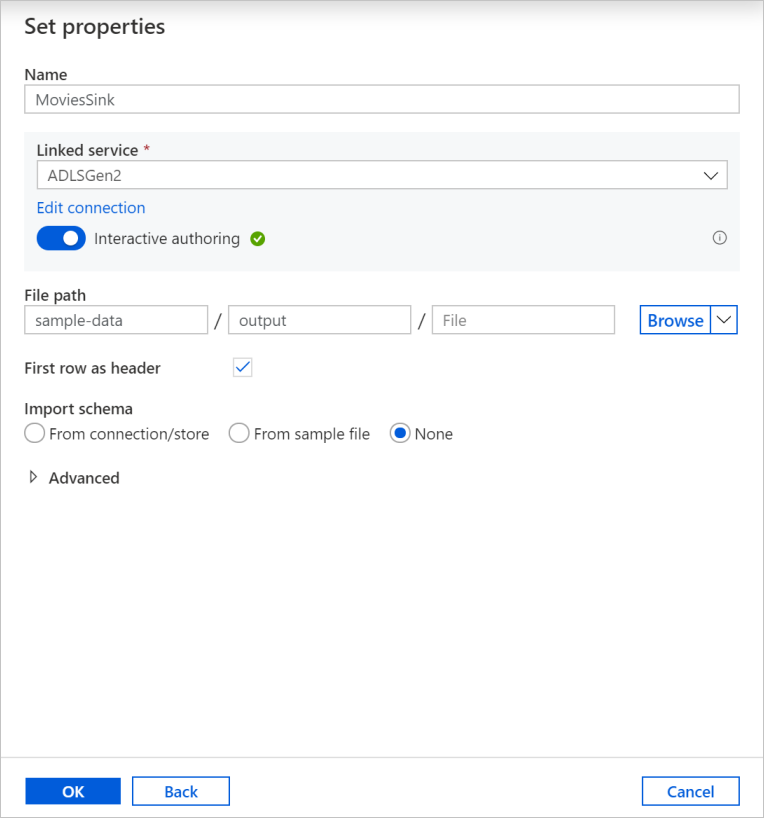
Agora você concluiu a criação do fluxo de dados. Você está pronto para executá-lo em seu pipeline.
Executar e monitorar o fluxo de dados
Você pode depurar um pipeline antes de publicá-lo. Nesta etapa, será disparada uma execução de depuração do pipeline de fluxo de dados. Embora a visualização de dados não grave dados, uma execução de depuração gravará dados no destino do coletor.
Acesse a tela do pipeline. Clique em Depurar para disparar uma execução de depuração.
A depuração de pipeline de atividades de fluxo de dados usa o cluster de depuração ativo, mas ainda leva pelo menos um minuto para ser inicializado. É possível acompanhar o progresso por meio da guia Saída. Depois que a execução for bem-sucedida, selecione o ícone de óculos para obter detalhes de execução.
Na página de detalhes, é possível ver o número de linhas e o tempo gasto em cada etapa da transformação.
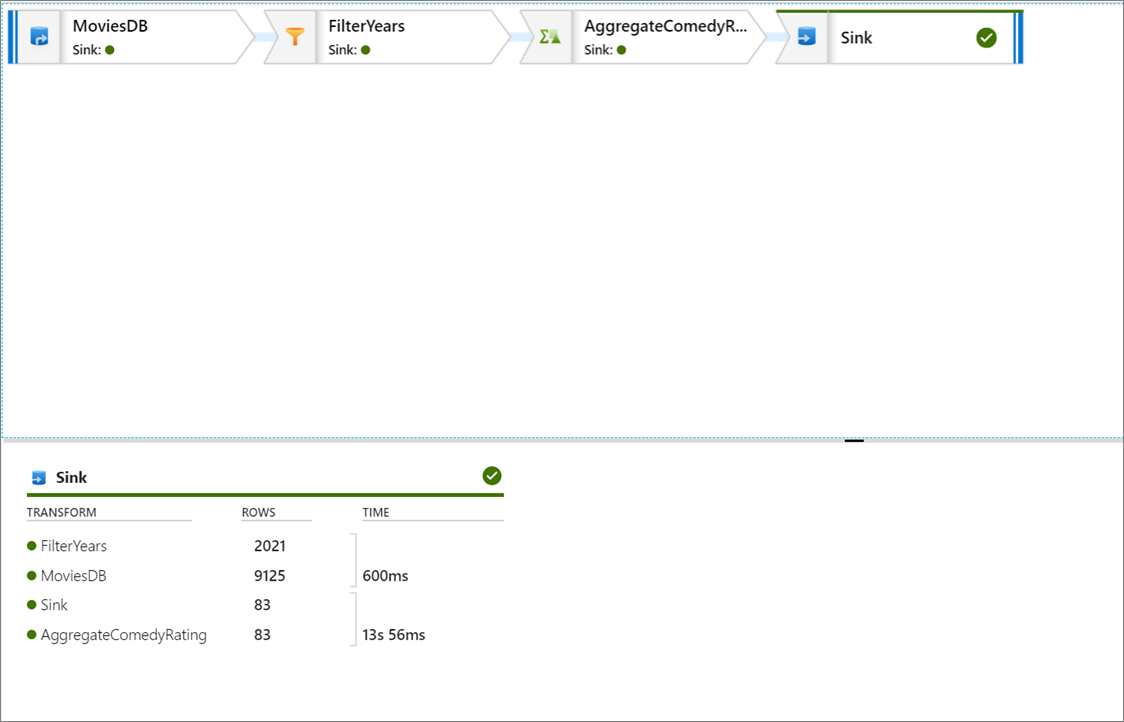
Selecione uma transformação para obter informações detalhadas sobre as colunas e o particionamento dos dados.
Se este tutorial foi seguido corretamente, devem ter sido gravadas 83 linhas e 2 colunas na pasta do coletor. Você pode verificar se os dados estão corretos verificando seu armazenamento de blob.
Resumo
Neste tutorial, você usou a interface do usuário do Data Factory para criar um pipeline que copia e transforma dados de uma fonte de Data Lake Storage Gen2 em um coletor de Data Lake Storage Gen2 (ambos permitindo acesso somente a redes selecionadas) usando o fluxo de dados de mapeamento em Data Factory Managed Rede Virtual.