Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Neste tutorial, você usará o portal Azure para criar um pipeline de Azure Data Factory. Este pipeline transforma os dados usando uma atividade Spark e um serviço vinculado do Azure HDInsight sob demanda.
Neste tutorial, você realizará os seguintes procedimentos:
- Criar uma fábrica de dados.
- Crie um pipeline que utilize uma atividade do Spark.
- Dispare uma execução de pipeline.
- Monitorar a execução de pipeline.
Se você não tiver uma assinatura Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
Observação
Recomendamos que você use o módulo Azure Az PowerShell para interagir com Azure. Para começar, consulte Instalar Azure PowerShell. Para saber como migrar para o módulo do Az PowerShell, consulte Migrate Azure PowerShell do AzureRM para o Az.
- Azure conta de armazenamento. Você cria um script Python e um arquivo de entrada e os carrega para Azure Storage. A saída do programa Spark é armazenada nessa conta de armazenamento. O cluster do Spark sob demanda usa a mesma conta de armazenamento que o respectivo armazenamento primário.
Observação
O HDInsight dá suporte somente a contas de armazenamento para uso geral com a camada Standard. Garanta que a conta não seja uma conta de armazenamento Premium ou somente de Blob.
- Azure PowerShell. Siga as instruções em Como instalar e configurar Azure PowerShell.
Carregar o script de Python para sua conta de armazenamento de Blobs
Crie um arquivo de Python chamado WordCount_Spark.py com o seguinte conteúdo:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Substitua <storageAccountName> pelo nome da sua conta de armazenamento Azure. Em seguida, salve o arquivo.
No armazenamento de Blobs Azure, crie um contêiner chamado adftutorial se ele não existir.
Crie uma pasta chamada spark.
Crie uma subpasta chamada script na pasta spark.
Carregue o arquivo WordCount_Spark.py na subpasta script.
Carregue o arquivo de entrada
- Crie um arquivo chamado minecraftstory.txt com um pouco de texto. O programa Spark conta o número de palavras no texto.
- Criar uma subpasta chamada inputfiles na pasta spark.
- Carregue o arquivo minecraftstory.txt na subpasta inputfiles.
Criar uma fábrica de dados
Siga as etapas no artigo Quickstart: Criar uma fábrica de dados usando o portal do Azure para criar uma fábrica de dados se você ainda não tiver uma com a qual trabalhar.
Criar serviços vinculados
Você cria dois serviços vinculados nesta seção:
- Um serviço vinculado Azure Storage que conecta uma conta de armazenamento do Azure ao Data Factory. Esse armazenamento é usado pelo cluster HDInsight sob demanda. Ele também contém o script Spark a ser executado.
- Um serviço vinculado do HDInsight sob demanda. Azure Data Factory cria automaticamente um cluster HDInsight e executa o programa Spark. Em seguida, ele exclui o cluster HDInsight após o cluster ficar ocioso por um tempo pré-configurado.
Criar um serviço vinculado do Azure Storage
Na página inicial, alterne para a guia Gerenciar no painel esquerdo.
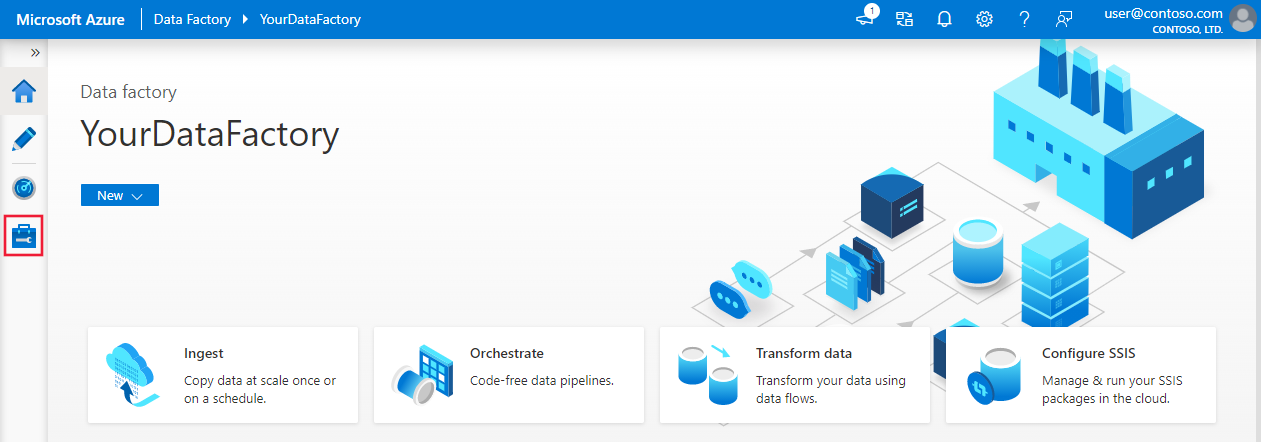
Selecione Conexões na parte inferior da janela e, depois, selecione + Novo.
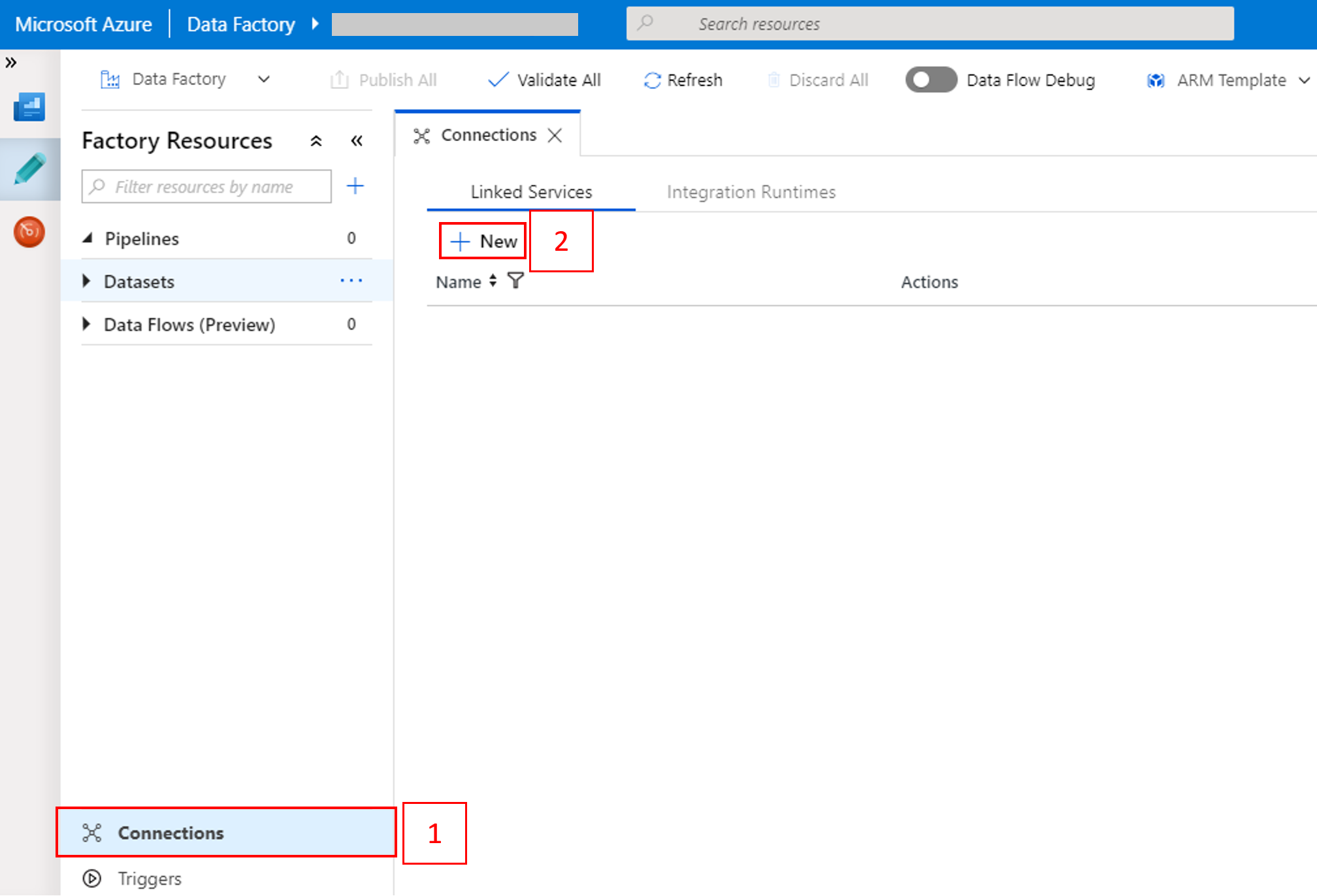
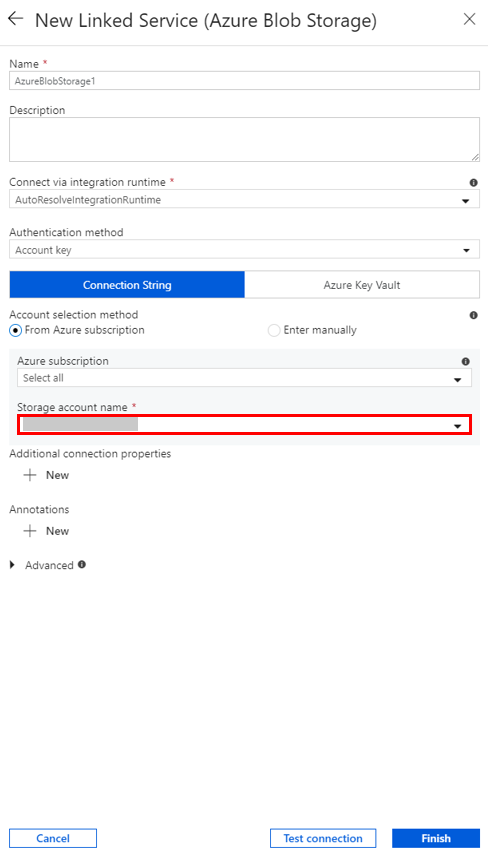
Na janela New Linked Service, selecione Data Store>Azure Blob Storage e selecione Continue.

Em Nome da conta de Armazenamento, selecione o nome na lista e selecione Salvar.
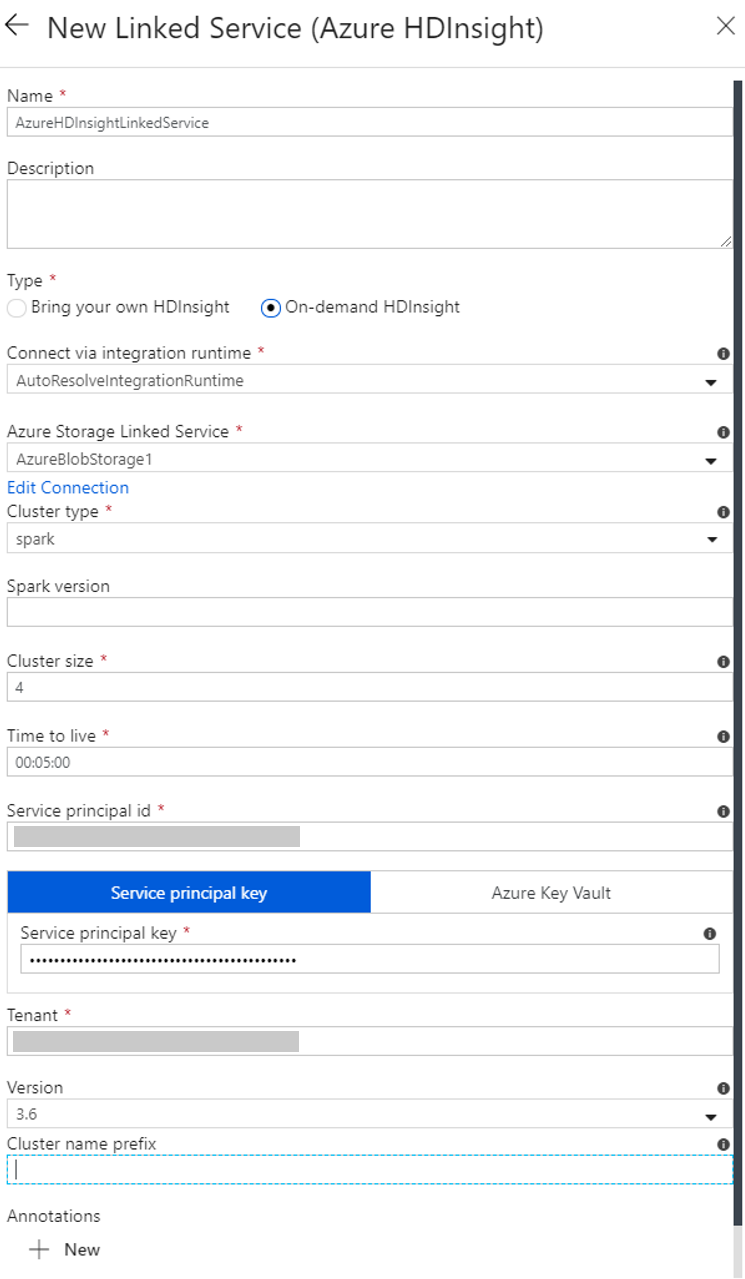
Criar um serviço vinculado do HDInsight sob demanda
Selecione o botão + Novo novamente para criar outro serviço vinculado.
Na janela New Linked Service, selecione Compute>Azure HDInsight e selecione Continue.

Na janela Novo Serviço Vinculado, execute as seguintes etapas:
a. Para Name, insira AzureHDInsightLinkedService.
b. Para Tipo, confirme se HDInsight sob demanda está selecionado.
c. Para Azure Storage Linked Service, selecione AzureBlobStorage1. Você criou esse serviço vinculado anteriormente. Se você usou um nome diferente, especifique o nome correto aqui.
d. Para o campo Tipo de cluster, selecione spark.
e. Para ID do principal de serviço, insira a ID do principal de serviço que possui permissão para criar um cluster do HDInsight.
Essa entidade de serviço precisa ser um membro da função de Colaborador de assinatura ou o grupo de recursos em que o cluster é criado. Para obter mais informações, consulte Criar uma entidade de serviço e um aplicativo do Microsoft Entra. A ID da entidade de serviço é equivalente à ID do aplicativo e uma Chave de entidade de serviço é equivalente ao valor de um Segredo do cliente.
f. Para Chave da entidade de serviço, insira a chave.
g. Para Grupo de recursos, selecione o mesmo grupo de recursos que você usou ao criar o data factory. O cluster Spark é criado nesse grupo de recursos.
h. Expandir o Tipo de sistema operacional.
i. Insira um nome para o Nome de usuário do cluster.
j. Insira a Senha do cluster para o usuário.
k. Selecione Concluir.
Observação
Azure HDInsight limita o número total de núcleos que você pode usar em cada região Azure à qual ele dá suporte. Para o serviço vinculado do HDInsight sob demanda, o cluster HDInsight é criado na mesma localização do Armazenamento do Azure usada como o armazenamento primário. Verifique se você tem cotas de núcleo suficientes para que o cluster seja criado com êxito. Para obter mais informações, consulte Configurar clusters no HDInsight com Hadoop, Spark, Kafka e mais.
Criar um pipeline
Selecione o botão + (adição) e escolha Pipeline no menu.
Na caixa de ferramentas Atividades, expanda HDInsight. Arraste a atividade Spark da caixa de ferramentas Atividades para a superfície do designer do pipeline.
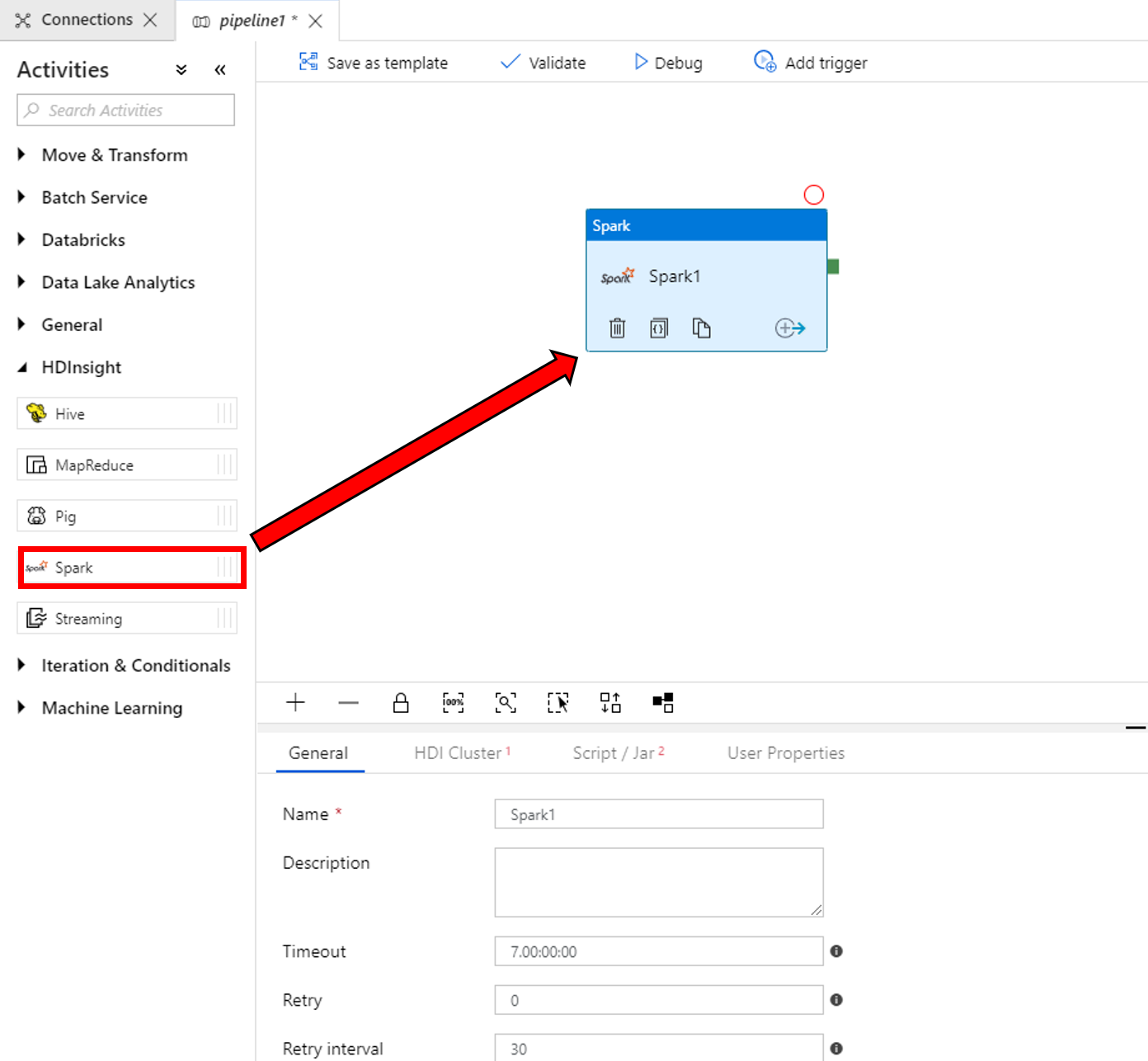
Na parte inferior da janela de propriedades da atividade Spark, execute as seguintes etapas:
a. Troque para a guia HDI Cluster.
b. Selecione AzureHDInsightLinkedService (criado no procedimento anterior).
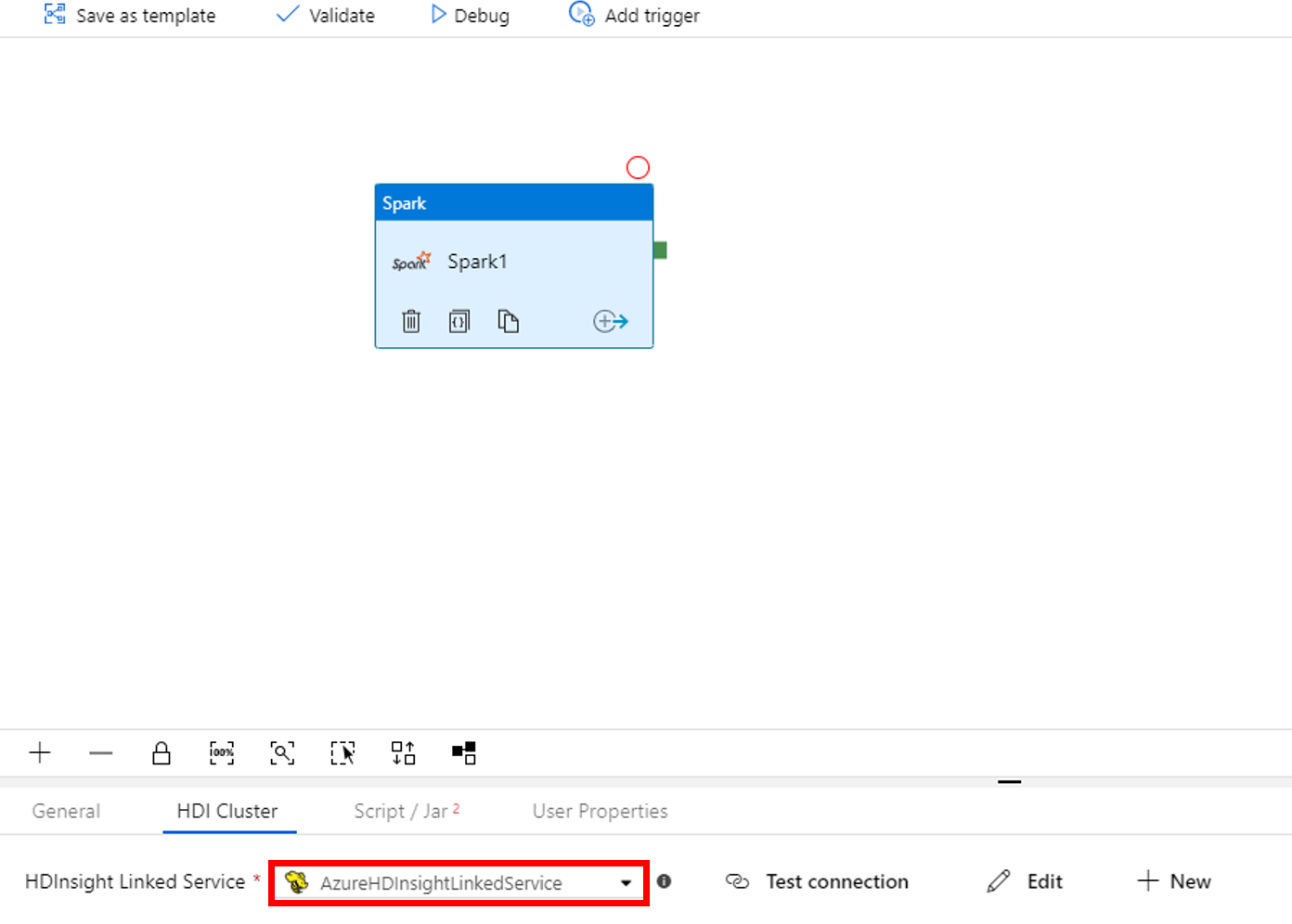
Alterne para a guia Script/Jar e execute estas etapas:
a. Para Serviço Vinculado de Tarefa, selecione AzureBlobStorage1.
b. Selecione Explorar Armazenamento.

c. Procure na pasta adftutorial/spark/script, selecione WordCount_Spark.py e selecione Concluir.
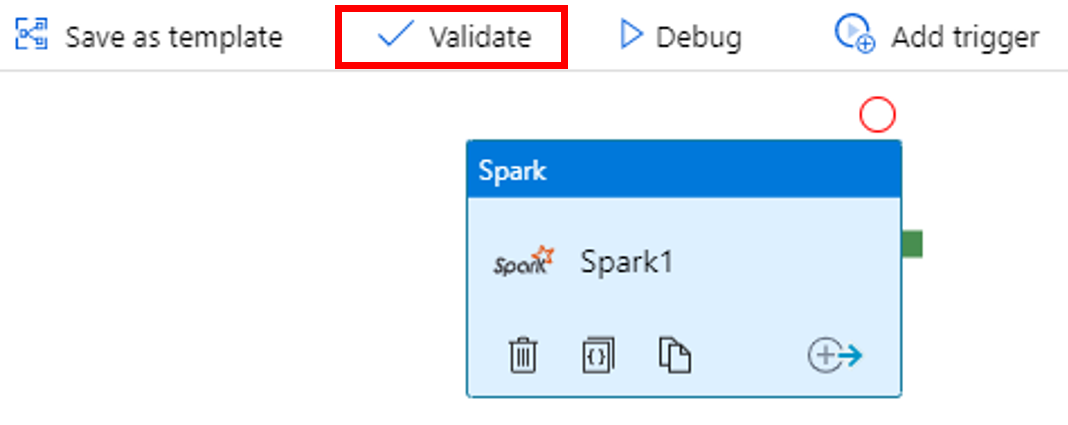
Para validar o pipeline, selecione o botão Validar na barra de ferramentas. Selecione o botão >> (seta para a direita) para fechar a janela de validação.
Selecione Publicar Tudo. A interface do usuário do Data Factory publica entidades (serviços vinculados e pipeline) no serviço Azure Data Factory.
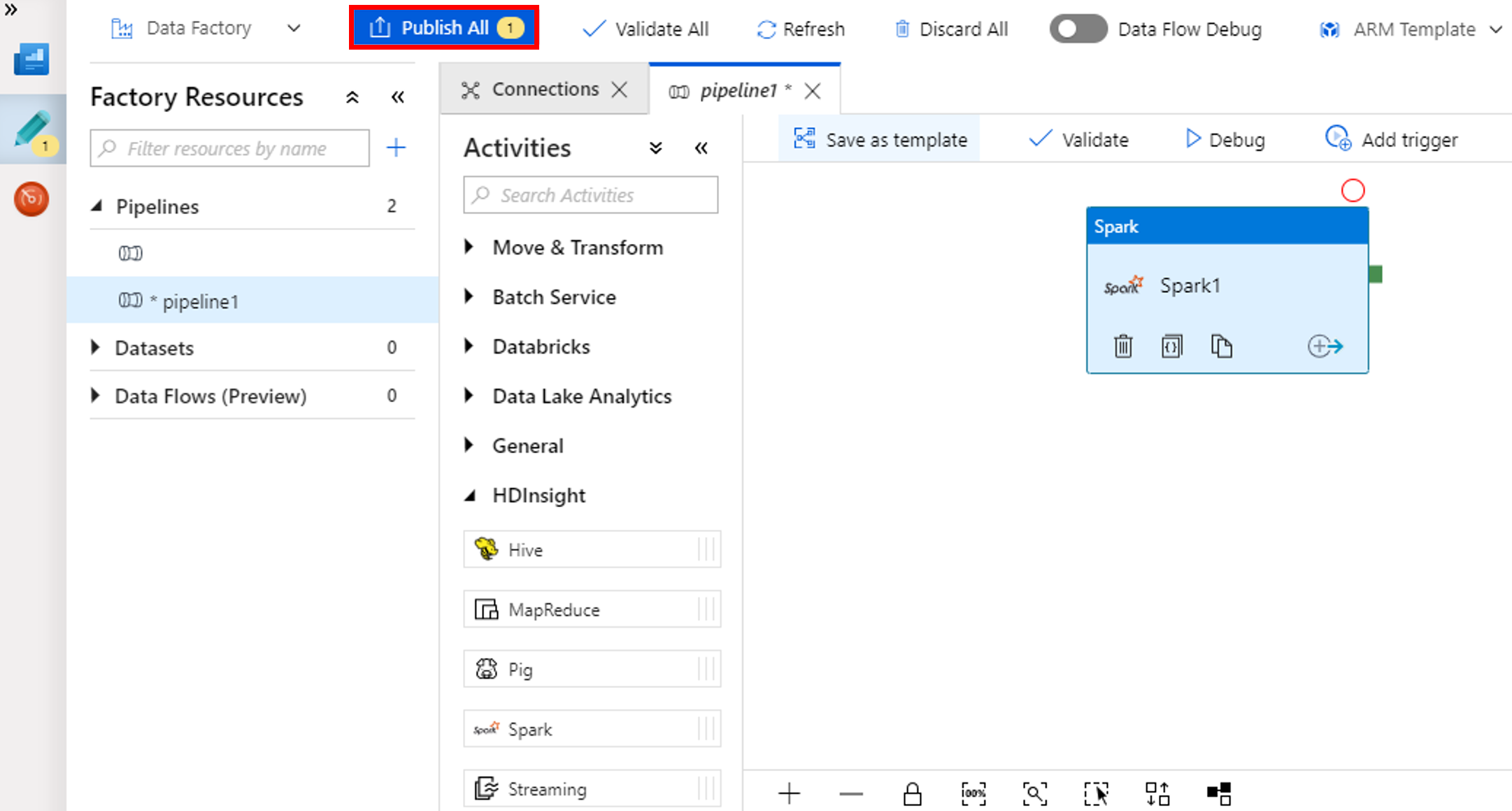
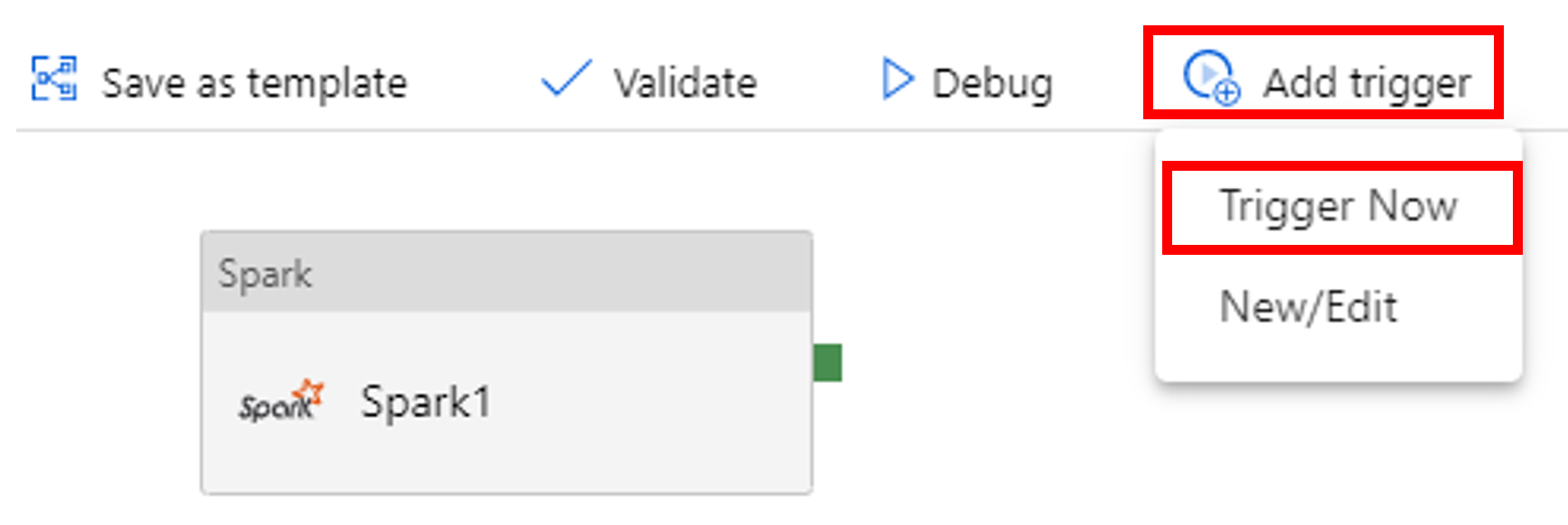
Disparar uma execução de pipeline
Selecione Adicionar gatilho na barra de ferramentas e selecione Acionar Agora.
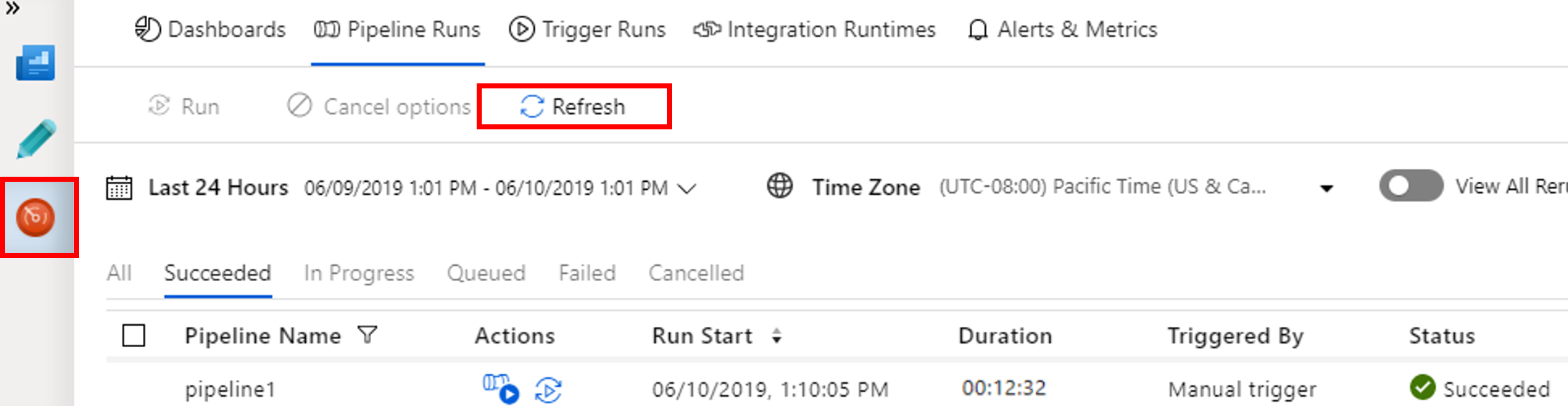
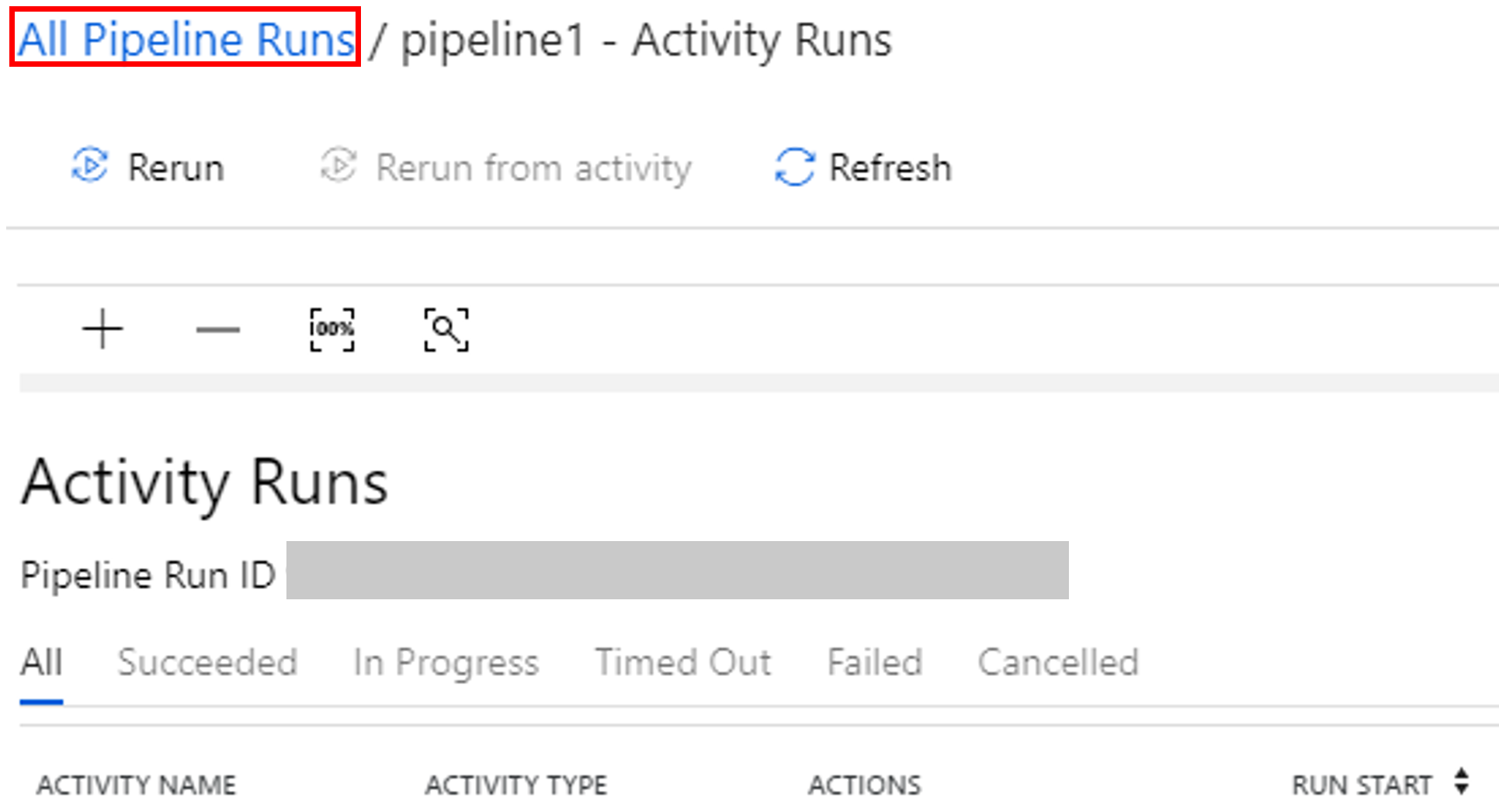
Monitorar a execução de pipeline
Alterne para a guia Monitorar. Verifique se o pipeline está sendo executado. Leva aproximadamente 20 minutos para criar um cluster Spark.
Selecione Atualizar periodicamente para verificar o status da execução do pipeline.
Para ver as execuções de atividade associadas com a execução de pipeline, selecione Exibir as Execuções de Atividade na coluna Ações.
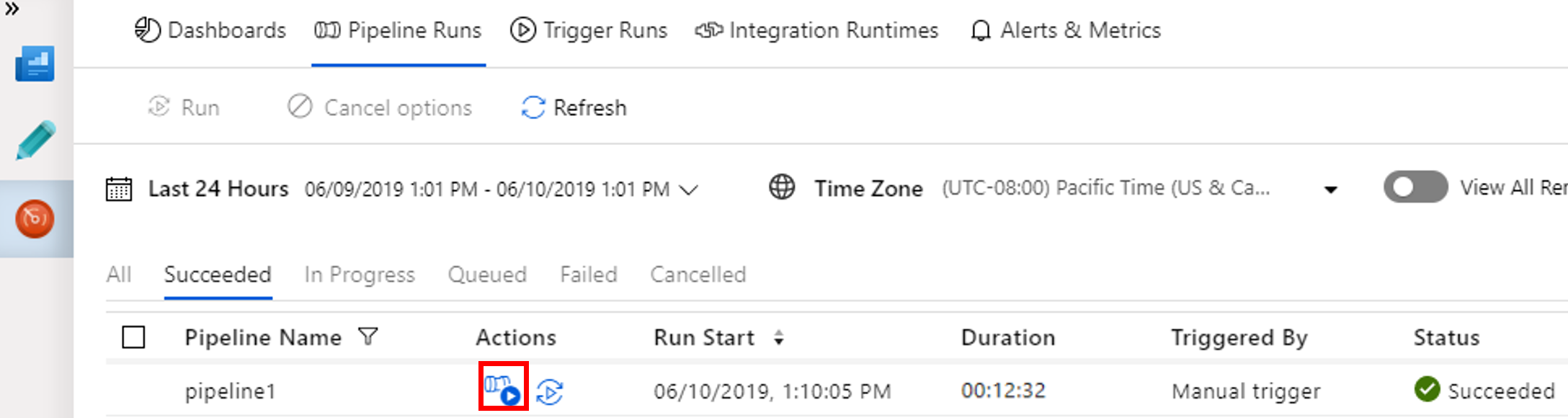
Você pode alternar novamente para o modo de execução do pipeline selecionando o link Todas as execuções de pipelines na parte superior.
Verificar a saída
Verifique se o arquivo de saída é criado na pasta spark/outputfiles/wordcount no contêiner do adftutorial.
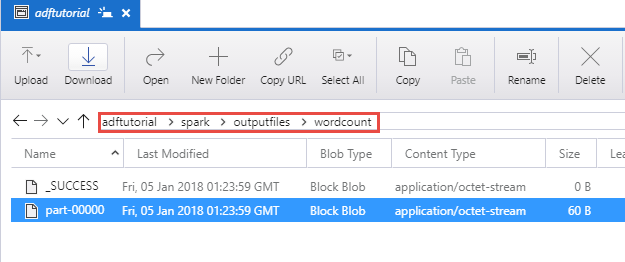
O arquivo deve ter cada palavra do texto do arquivo de entrada e o número de vezes que a palavra apareceu no arquivo. Por exemplo:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Conteúdo relacionado
Neste exemplo, o pipeline transforma dados usando a atividade Spark e um serviço vinculado do HDInsight sob demanda. Você aprendeu a:
- Criar uma fábrica de dados.
- Crie um pipeline que utilize uma atividade do Spark.
- Dispare uma execução de pipeline.
- Monitorar a execução de pipeline.
Para saber como transformar dados executando um script do Hive em um cluster Azure HDInsight que está em uma rede virtual, avance para o próximo tutorial: