Serviço e engenharia de recursos
Esta página aborda a engenharia de recursos e os recursos de disponibilização destinados a workspaces habilitados para o Catálogo do Unity. Se o workspace não estiver habilitado para o Catálogo do Unity, consulte Repositório de recursos do workspace (herdado).
Por que usar o Databricks como um repositório de recursos?
Realize todo o fluxo de trabalho de treinamento de modelos com a plataforma Data Intelligence do Databricks:
- Pipelines de dados que ingerem dados brutos, criam tabelas de recursos, treinam modelos e executam inferência em lote. Ao treinar e registrar um modelo usando a engenharia de recursos no Catálogo do Unity, o modelo é empacotado com metadados de recursos. Quando você usa o modelo para pontuação em lote ou inferência online, ele recupera automaticamente os valores de recursos. O chamador não precisa saber sobre eles ou incluir lógica para pesquisar ou unir recursos a fim de pontuar novos dados.
- Pontos de extremidade de disponibilização de modelos e recursos que estão disponíveis com um único clique e fornecem milissegundos de latência.
- Monitoramento de modelos e dados.
Além disso, a plataforma fornece o seguinte:
- Descoberta de recursos. É possível procurar e pesquisar recursos na interface do usuário do Databricks.
- Governança. As tabelas de recursos, as funções e os modelos são controlados pelo Catálogo do Unity. Quando você treina um modelo, ele herda permissões dos dados em que foi treinado.
- Linhagem. Quando você cria uma tabela de recursos no Azure Databricks, as fontes de dados usadas para criar a tabela de recursos são salvas e acessíveis. Para cada recurso em uma tabela de recursos, também é possível acessar os modelos, notebooks, trabalhos e pontos de extremidade que o utilizam.
- Acesso entre workspaces. As tabelas de recursos, as funções e os modelos são disponibilizados automaticamente em qualquer workspace que tenha acesso ao catálogo.
Requisitos
- Seu workspace deve estar habilitado para o Catálogo do Unity.
- A engenharia de recursos no Catálogo do Unity requer o Databricks Runtime 13.3 LTS ou versões mais recentes.
Se o workspace não atender a esses requisitos, consulte Repositório de recursos do workspace (herdado) sobre como usar o repositório de recursos do workspace.
Como funciona a engenharia de recursos no Databricks?
O fluxo de trabalho típico de machine learning que usa a engenharia de recursos segue este caminho:
- Escrever o código para converter dados brutos em recursos e criar um DataFrame do Spark contendo os recursos desejados.
- Crie uma tabela Delta no Catálogo do Unity. Qualquer tabela Delta com uma chave primária é automaticamente uma tabela de recursos.
- Treine e registre um modelo usando a tabela de recursos. Ao fazer isso, o modelo armazena as especificações dos recursos usados para treinamento. Quando o modelo é usado para inferência, ele une automaticamente os recursos das tabelas de recursos apropriadas.
- Registre o modelo no Registro de modelos.
Agora é possível usar o modelo para fazer previsões sobre novos dados. Para casos de uso em lote, o modelo recupera automaticamente os recursos necessários no Repositório de Recursos.
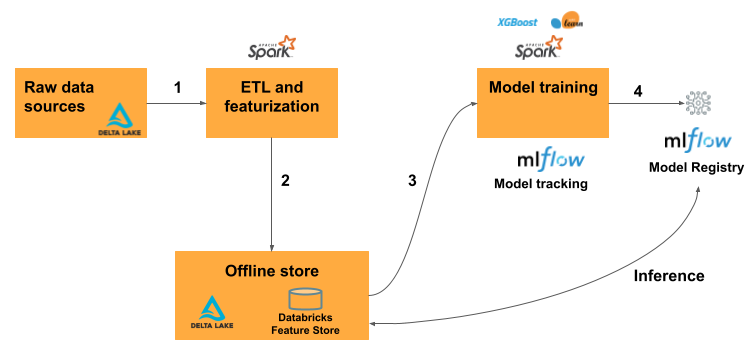
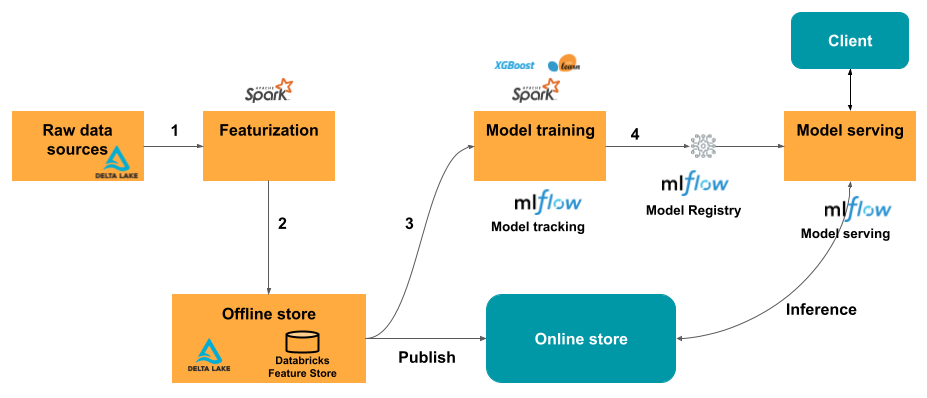
Para casos de uso de distribuição em tempo real, publique os recursos em uma tabela online. Também há suporte para lojas online de terceiros. Confira Lojas online de terceiros.
No momento da inferência, o modelo faz a leitura dos recursos pré-computados do Repositório de Recursos online e os une aos dados fornecidos na solicitação do cliente para o ponto de extremidade de serviço do modelo.
Começar a usar a engenharia de recursos – Notebooks de exemplo
Para começar, experimente estes notebooks de exemplo. O notebook de exemplo básico explica como criar uma tabela de recursos, usá-la para treinar um modelo e, em seguida, executar a pontuação em lote usando a pesquisa automática de recursos. Ele também apresenta a interface do usuário da Engenharia de Recursos e mostra como você pode usá-la para pesquisar recursos e entender como os recursos são criados e usados.
Notebook de exemplo de engenharia de recursos básico no Catálogo do Unity
O notebook de exemplo de táxi ilustra o processo de criar recursos, atualizá-los e usá-los para treinamento de modelo e inferência em lotes.
Notebook de exemplo de táxi de Engenharia de Recursos no Catálogo do Unity
Tipos de dados com suporte
A engenharia de recursos no Catálogo do Unity e o repositório de recursos do workspace dão suporte aos seguintes tipos de dados PySpark:
IntegerTypeFloatTypeBooleanTypeStringTypeDoubleTypeLongTypeTimestampTypeDateTypeShortTypeArrayTypeBinaryType[1]DecimalType[1]MapType[1]StructType[2]
[1] há suporte para BinaryType, DecimalTypee MapType em todas as versões da Engenharia de Recursos no Catálogo do Unity e no Repositório de Recursos do Workspace v0.3.5 ou superior.
[2] StructType é aceito na engenharia de recursos v0.6.0 ou em versões mais recentes.
Os tipos de dados listados acima dão suporte a tipos de recursos comuns em aplicativos de machine learning. Por exemplo:
- Você pode armazenar vetores, tensores e inserções densos como
ArrayType. - Você pode armazenar vetores, tensores e inserções esparsos como
MapType. - Você pode armazenar texto como
StringType.
Quando publicados em repositórios online, os recursos ArrayType e MapType são armazenados no formato JSON.
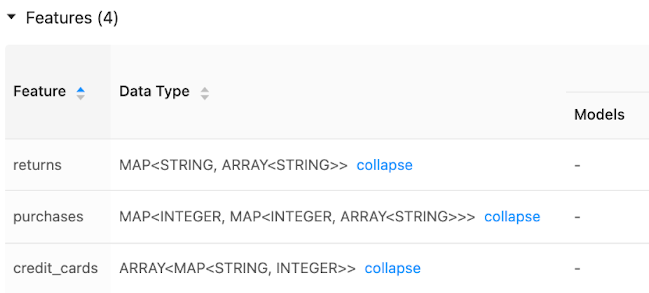
A interface do usuário do Repositório de Recursos exibe metadados em tipos de dados de recurso:
Mais informações
Para saber mais sobre as melhores práticas, baixe o Guia abrangente dos repositórios de recursos.