Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Esta página descreve como visualizar a linhagem de dados usando o Gerenciador de Catálogos e as tabelas do sistema de linhagem de dados.
Visão geral da linhagem de dados
O Unity Catalog captura a linhagem de dados em tempo de execução em consultas executadas no Azure Databricks. A linhagem tem suporte para todos os idiomas e é capturada até o nível da coluna. Os dados da linhagem incluem notebooks, trabalhos e painéis de controle relacionados à consulta. A linhagem pode ser visualizada no Catalog Explorer quase em tempo real e recuperada programaticamente usando as tabelas do sistema de linhagem.
A linhagem também pode incluir ativos externos e fluxos de trabalho executados fora de Azure Databricks. Esse recurso de metadados de linhagem externa está na Visualização Pública. Consulte Traga sua própria linhagem de dados.
A linhagem é agregada em todos os workspaces anexados a um metastore do Catálogo do Unity. Isso significa que a linhagem capturada em um workspace é visível em qualquer outro workspace que compartilhe esse metastore. Especificamente, tabelas e outros objetos de dados registrados no metastore são visíveis para usuários que têm pelo menos BROWSE permissões nesses objetos, em todos os workspaces anexados ao metastore. No entanto, informações detalhadas sobre objetos no nível do workspace, como notebooks e dashboards em outros workspaces, são mascaradas (consulte limitações de linhagem e permissões de linhagem).
Os dados de linhagem são mantidos indefinidamente. Todos os dados de linhagem capturados após 1º de setembro de 2024 estão disponíveis. Para metastores criados após essa data, o Gerenciador de Catálogos inclui Todos os tempos na lista suspensa de intervalo de tempo de linhagem. Para metastores mais antigos, a lista suspensa inclui uma opção Todos disponíveis que começa em 1º de setembro de 2024. A seleção padrão é de 1 ano.
A imagem a seguir é um grafo de linhagem de exemplo.
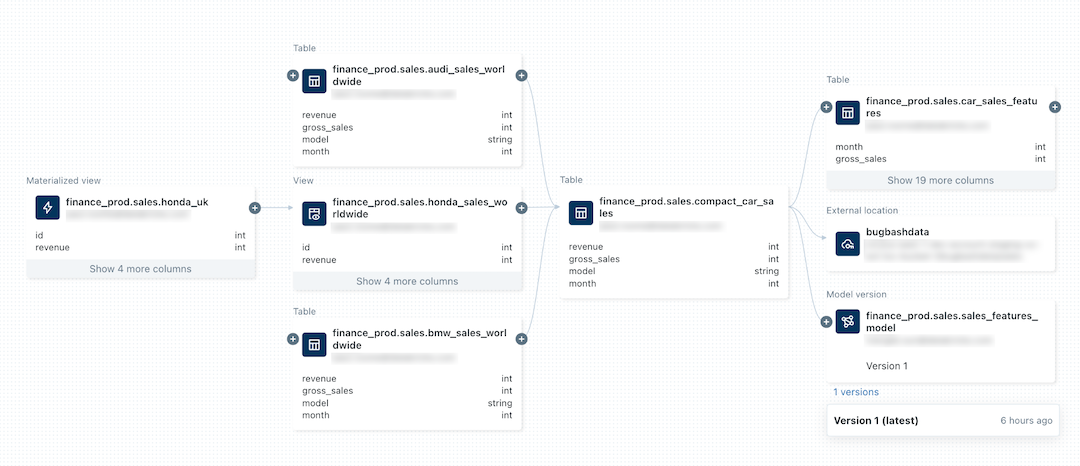
Para obter uma demonstração de exibição da linhagem de dados, consulte o Catálogo do Unity – Linhagem de Dados.
Para obter informações sobre como acompanhar a linhagem de um modelo de machine learning, consulte Acompanhar a linhagem de dados de um modelo no Catálogo do Unity.
Requisitos
Para capturar a linhagem de dados usando o Catálogo do Unity:
- As tabelas precisam ser registradas em um metastore do Unity Catalog.
- Os ativos externos (aqueles não registrados no metastore do Catálogo do Unity) devem ser adicionados como objetos de metadados externos no Catálogo do Unity, configurados para ter relações com outros objetos protegíveis registrados no metastore do Catálogo do Unity. Consulte Traga sua própria linhagem de dados.
- As consultas devem usar o DataFrame do Spark (por exemplo, funções SQL do Spark que retornam um DataFrame) ou interfaces SQL do Databricks, como notebooks ou o editor de consultas SQL.
Para exibir a linhagem de dados:
- Você deve ter pelo menos o privilégio
BROWSEno catálogo pai da tabela ou exibição. O catálogo pai também deve estar acessível no workspace. Consulte Workspace-catalog binding. - Para notebooks, trabalhos ou painéis, você deve ter permissões nesses objetos, conforme definido pelas configurações de controle de acesso no workspace. Para obter detalhes, consulte permissões de linhagem.
- Para um pipeline habilitado para o Catálogo do Unity, você deve ter a permissão CAN VIEW no pipeline.
Requisitos de computação:
- O acompanhamento de linhagem do streaming entre tabelas Delta requer Databricks Runtime 11.3 LTS ou superior.
- O rastreamento de linhagem de coluna para cargas de trabalho do Lakeflow Spark Declarative Pipelines requer o Databricks Runtime 13.3 LTS ou superior.
Requisitos de rede:
- Talvez seja necessário atualizar suas regras de firewall de saída para permitir a conectividade com o ponto de extremidade do Event Hubs no plano de controle do Azure Databricks. Normalmente, isso se aplica caso o seu workspace do Azure Databricks seja implantado em sua própria VNet (também chamada de injeção de VNet). Para obter o ponto de extremidade dos Hub de Eventos para a sua região de workspace, confira Metastore, armazenamento de blobs de artefatos, armazenamento de tabelas do sistema, armazenamento de blobs de log e endereços IP de ponto de extremidade dos Hubs de Eventos. Para obter informações sobre como configurar UDR (rotas definidas pelo usuário) para Azure Databricks, consulte as configurações de rota definidas por User para Azure Databricks.
Exibir linhagem de dados usando o Gerenciador de Catálogos
Para usar o Gerenciador de Catálogos para exibir a linhagem da tabela:
No workspace Azure Databricks, clique em
 Catalog.
Catalog.Pesquise ou procure sua tabela.
Selecione a guia Linhagem . O painel de linhagem é exibido e exibe tabelas relacionadas.
Para exibir um grafo interativo da linhagem de dados, clique em Ver grafo de linhagem.
Por padrão, um nível é exibido no grafo. Clique no ícone
 em um nó para revelar mais conexões se elas estiverem disponíveis.
em um nó para revelar mais conexões se elas estiverem disponíveis.Clique em uma seta que conecta nós no grafo de linhagem para abrir o painel Conexão de linhagem.
O painel Conexão de linhagem mostra detalhes sobre a conexão, incluindo tabelas de origem e de destino, notebooks e tarefas.
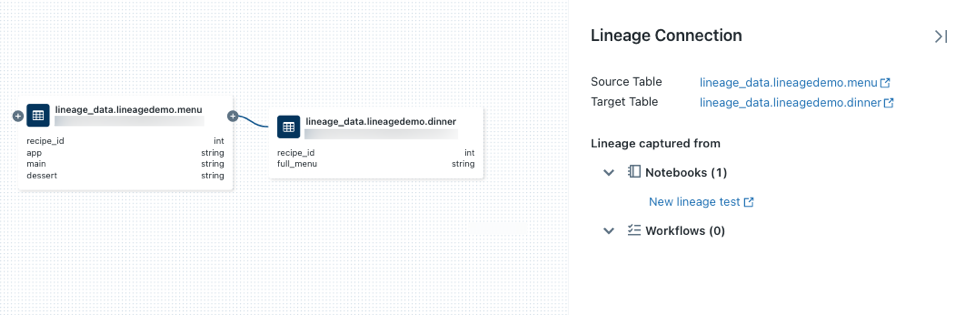
Para exibir um notebook associado a uma tabela, selecione o notebook no painel de conexão de linhagem ou feche o gráfico de linhagem e clique em Notebooks.
Para abrir o bloco de anotações em uma nova guia, clique no nome do bloco de anotações.
Para exibir a linhagem no nível da coluna, clique em uma coluna no grafo para mostrar links para colunas relacionadas. Por exemplo, clicar na
full_menucoluna neste grafo de exemplo mostra as colunas upstream das quais a coluna foi derivada: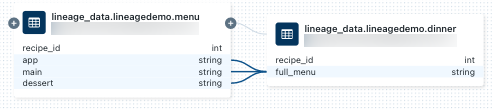
Exibir linhagem de trabalho
Para exibir a linhagem do trabalho, acesse a guia Linhagem de uma tabela, selecione Trabalhos e selecione Downstream. O nome do trabalho aparece em Nome do Trabalho como um consumidor da tabela.
Exibir a linhagem do painel de controle
Para exibir a linhagem do painel, acesse a guia Linhagem de uma tabela e clique em Painéis. O painel aparece em Nome do Painel como um consumidor da tabela.
Obter linhagem de tabela usando o Genie Code
Genie Code fornece informações detalhadas sobre linhagens de tabela e análises.
Para obter informações de linhagem usando o Genie Code:
- Na barra lateral do workspace, clique no Catálogo.
- Procure ou pesquise o catálogo, clique no nome do catálogo e clique no
 Ícone do Genie Code no canto superior direito.
Ícone do Genie Code no canto superior direito. - No prompt do Genie Code, digite:
- /getTableLineages para exibir dependências anteriores e posteriores.
- /getTableInsights para acessar insights controlados por metadados, como padrões de consulta e atividade do usuário.
Essas consultas permitem que o Genie Code responda perguntas como "mostrar-me linhagens downstream" ou "quem consulta essa tabela com mais frequência".

Consultar os dados de linhagem usando as tabelas de sistema
Você pode usar as tabelas do sistema de linhagem para consultar dados de linhagem programaticamente. Para obter instruções detalhadas, consulte referência de tabelas do sistema e referência de tabelas de sistema de linhagem.
Permissões de linhagem
Os grafos de linhagem compartilham o mesmo modelo de permissão que o Unity Catalog. Tabelas e outros objetos de dados registrados no metastore do Catálogo do Unity são visíveis apenas para usuários que têm pelo menos BROWSE permissões nesses objetos. Se um usuário não tiver o BROWSE ou SELECT privilégio em uma tabela, ele não poderá explorar sua linhagem. Os gráficos de linhagem exibem objetos do Unity Catalog em todos os workspaces conectados ao metastore, desde que o usuário tenha permissões adequadas para os objetos.
Por exemplo, execute os seguintes comandos para userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
Quando userA exibir o grafo de linhagem da tabela lineage_data.lineagedemo.menu, eles verão a tabela menu. Eles não poderão ver informações sobre tabelas associadas, como a tabela downstream lineage_data.lineagedemo.dinner. A tabela dinner é exibida como um nó masked na exibição para userA e userA não pode expandir o grafo para revelar tabelas de downstream de tabelas que não têm permissão para acessar.
Se você executar o seguinte comando para conceder a permissão BROWSE a userB, esse usuário poderá exibir o grafo de linhagem para uma tabela no esquema lineage_data:
GRANT BROWSE on lineage_data to `userB@company.com`;
Da mesma forma, os usuários de linhagem devem ter permissões específicas para exibir objetos de workspace, como notebooks, trabalhos e dashboards. Além disso, eles só podem ver informações detalhadas sobre objetos de workspace quando são conectados ao workspace no qual esses objetos foram criados. Informações detalhadas sobre os objetos no nível do workspace em outros workspaces são mascaradas no grafo de linhagem.
Para mais informações sobre como gerenciar o acesso a objetos protegíveis no Unity Catalog, veja como Gerenciar privilégios no Unity Catalog. Para obter mais informações sobre como gerenciar o acesso a objetos de workspace, como notebooks, trabalhos e painéis, confira Lista de controle de acesso.
Limitações de linhagem
A linhagem de dados tem as seguintes limitações. Essas limitações também se aplicam a tabelas do sistema de linhagem:
- Embora a linhagem seja agregada para todos os workspaces anexados ao mesmo metastore do Catálogo do Unity, os detalhes de objetos de workspace, como notebooks e painéis, ficam visíveis apenas no workspace no qual foram criados.
- Os dados de linhagem capturados antes de 1º de setembro de 2024 não estão disponíveis.
- Os trabalhos que usam a solicitação da API
runs submitde trabalhos ou o tipo de tarefaspark submitnão estão disponíveis nas visões de linhagem. A linhagem no nível de tabela e coluna ainda é capturada para esses fluxos de trabalho, mas o link para a execução de tarefas não é capturado. - A linhagem não é preservada para objetos renomeados– isso se aplica a catálogos, esquemas, tabelas, exibições e colunas.
- Se você usar o ponto de verificação do conjunto de dados do Spark SQL, a linhagem não será capturada.
- Unity Catalog captura a linhagem dos Pipelines Declarativos do Lakeflow Spark na maioria dos casos. No entanto, em alguns casos, não é possível garantir a cobertura completa de linhagem, como quando os pipelines usam tabelas _PRIVATE_.
- Os RDDs (conjuntos de dados distribuídos resilientes) não são capturados na linhagem de dados.
- Exibições temporárias globais não são capturadas na linhagem.
- As transações emitem linhagem conforme cada leitura e gravação ocorre. Os eventos de linhagem persistem mesmo se a transação for revertida.
- As tabelas em
system.information_schemanão são capturadas na linhagem. - O Catálogo do Unity captura a linhagem para o nível de coluna ao máximo. No entanto, há alguns casos em que a linhagem no nível da coluna não pode ser capturada. Estes incluem:
A linhagem de coluna não poderá ser capturada se a origem ou o destino for referenciado como caminho (exemplo:
select * from delta."s3://<bucket>/<path>"). Há suporte para a linhagem da coluna somente quando a origem e o destino são referenciados pelo nome da tabela (Exemplo:select * from <catalog>.<schema>.<table>).Uso de UDFs (funções definidas pelo usuário), que podem obscurecer o mapeamento entre colunas de origem e de destino.