Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Azure Databricks é uma plataforma unificada de open analytics para criar, implantar, compartilhar e manter soluções de dados de nível empresarial, analytics e IA em escala. A Plataforma de Inteligência de Dados do Databricks integra-se ao armazenamento em nuvem e à segurança em sua conta de nuvem e gerencia e implanta a infraestrutura de nuvem para você.
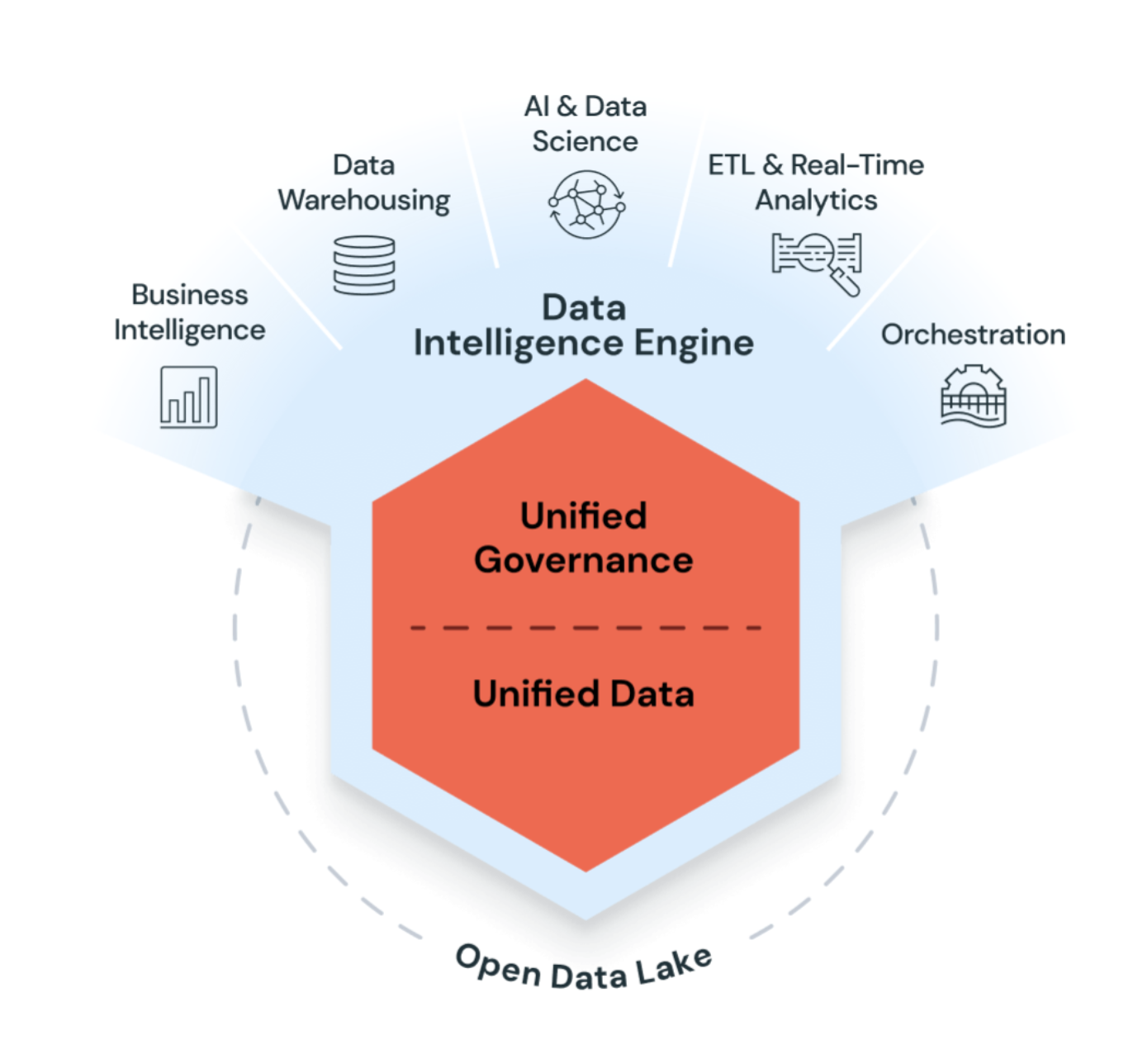
O Azure Databricks usa a IA generativa com o data lakehouse para entender a semântica única dos seus dados. Em seguida, otimiza automaticamente o desempenho e gerencia a infraestrutura para atender às necessidades dos seus negócios.
O processamento de idioma natural aprende a linguagem da sua empresa, para que você possa pesquisar e descobrir dados fazendo uma pergunta em suas próprias palavras. A assistência à linguagem natural ajuda você a programar, solucionar erros e encontrar respostas na documentação.
Integração de software livre gerenciada
O Databricks está comprometido com a comunidade de software livre e gerencia atualizações de integrações de software livre com as versões do Databricks Runtime. As seguintes tecnologias são projetos de software livre originalmente criados por funcionários do Databricks:
Casos de uso comuns
Os casos de uso a seguir destacam algumas das maneiras pelas quais os clientes usam o Azure Databricks para realizar tarefas essenciais para processar, armazenar e analisar os dados que impulsionam funções e decisões comerciais críticas.
Criar um data lakehouse corporativo
O data lakehouse combina data warehouses corporativos e data lakes para acelerar, simplificar e unificar soluções de dados corporativos. Engenheiros de dados, cientistas de dados, analistas e sistemas de produção podem usar o data lakehouse como sua única fonte de verdade, fornecendo acesso a dados consistentes e reduzindo as complexidades da criação, manutenção e sincronização de muitos sistemas de dados distribuídos. Confira O que é um data lakehouse?.
ETL e engenharia de dados
Se você estiver gerando painéis ou alimentando aplicativos de inteligência artificial, a engenharia de dados fornece o backbone para empresas centradas em dados, garantindo que os dados estejam disponíveis, limpos e armazenados em modelos de dados para descoberta e uso eficientes. O Azure Databricks combina o poder do Apache Spark com o Delta e ferramentas personalizadas para fornecer uma experiência ETL inigualálida. Use SQL, Python e Scala para compor a lógica ETL e orquestrar a implantação de trabalho agendada com alguns cliques.
O Lakeflow Spark Declarative Pipelines simplifica ainda mais o ETL gerenciando de forma inteligente as dependências entre conjuntos de dados e implantando e dimensionando automaticamente a infraestrutura de produção para garantir a entrega de dados oportuna e precisa para suas especificações.
O Azure Databricks fornece ferramentas para ingestão de dados, incluindo o Auto Loader, uma ferramenta eficiente e escalonável para carregar dados de forma incremental e idempotente do armazenamento de objetos de nuvem e lagos de dados no data lakehouse.
Aprendizado de máquina, IA e ciência de dados
O aprendizado de máquina do Azure Databricks expande a funcionalidade principal da plataforma com um conjunto de ferramentas adaptadas às necessidades de cientistas de dados e engenheiros de ML, incluindo o MLflow e o Databricks Runtime for Machine Learning.
Modelos de linguagem grandes e IA generativa
O Databricks Runtime para Machine Learning inclui bibliotecas como Hugging Face Transformers que permitem integrar modelos pré-treinados existentes ou outras bibliotecas de código aberto em seu fluxo de trabalho. A integração do Databricks MLflow facilita o uso do serviço de acompanhamento do MLflow com pipelines, modelos e componentes de processamento do transformador. Integre modelos ou soluções openai de parceiros como o John Snow Labs em seus fluxos de trabalho do Databricks.
Com o Azure Databricks, personalize um LLM usando seus dados para sua tarefa específica. Com suporte de ferramentas de código aberto, como Hugging Face e DeepSpeed, você pode pegar um LLM básico e começar a treinar com seus próprios dados para obter mais precisão para seu domínio e carga de trabalho.
Além disso, o Azure Databricks fornece funções de IA que os analistas de dados do SQL podem usar para acessar LLMs, inclusive do OpenAI, diretamente em seus pipelines de dados e fluxos de trabalho. Consulte Enriquecer dados usando o AI Functions.
Armazenamento de dados, análise e BI
O Azure Databricks combina UIs amigáveis ao usuário com recursos de computação econômicos e armazenamento infinitamente escalonável e acessível para fornecer uma plataforma avançada para executar consultas analíticas. Os administradores configuram clusters de computação escalonáveis como SQL Warehouses, permitindo que os usuários finais executem consultas sem se preocupar com as complexidades do trabalho na nuvem. Os usuários do SQL podem consultar os dados no lakehouse usando o editor de consultas SQL ou em notebooks. Os notebooks dão suporte a Python, R e Scala, além do SQL, e permitem que os usuários insiram as mesmas visualizações disponíveis em dashboards junto com links, imagens e comentários escritos no markdown.
Governança de dados e compartilhamento seguro de dados
O Catálogo do Unity fornece um modelo de governança de dados unificado para o data lakehouse. Os administradores de nuvem configuram e integram permissões de controle de acesso grosseiras para o Catálogo do Unity e, em seguida, os administradores do Azure Databricks podem gerenciar permissões para equipes e indivíduos. Os privilégios são gerenciados com ACLs (listas de controle de acesso) por meio de UIs amigáveis para o usuário ou sintaxe SQL, facilitando para os administradores de banco de dados o acesso aos dados sem a necessidade de dimensionar o IAM (gerenciamento de acesso de identidade) nativo de nuvem e a rede.
O Catálogo do Unity simplifica a execução da análise segura na nuvem e fornece uma divisão de responsabilidade que ajuda a limitar a requalificação ou o treinamento necessário para administradores e usuários finais da plataforma. Veja O que é o Catálogo do Unity?.
O lakehouse torna o compartilhamento de dados em sua organização tão simples quanto a concessão de acesso de consulta a uma tabela ou visualização. Para compartilhar fora do seu ambiente seguro, o Catálogo do Unity apresenta uma versão gerenciada do Compartilhamento Delta.
DevOps, CI/CD e orquestração de tarefas
Os ciclos de vida de desenvolvimento para pipelines de ETL, modelos de ML e painéis de análise apresentam seus próprios desafios exclusivos. O Azure Databricks permite que todos os usuários aproveitem uma única fonte de dados, o que reduz esforços duplicados e relatórios fora de sincronia. Além de fornecer um conjunto de ferramentas comuns para controle de versão, automatização, agendamento, implantação de recursos de código e produção, você pode simplificar sua sobrecarga de monitoramento, orquestração e operações.
Os jobs agendam notebooks do Azure Databricks, consultas SQL e outros códigos arbitrários. Os Pacotes de Automação Declarativa permitem definir, implantar e executar recursos do Databricks, como trabalhos e pipelines programaticamente. As pastas Git permitem sincronizar projetos do Azure Databricks com vários provedores Git populares.
Para obter as melhores práticas e recomendações de CI/CD, consulte as práticas recomendadas e os fluxos de trabalho de CI/CD recomendados no Databricks. Para obter uma visão geral completa das ferramentas para desenvolvedores, consulte Desenvolver no Databricks.
Análise em tempo real e de streaming
O Azure Databricks aproveita o Streaming estruturado do Apache Spark para trabalhar com dados de streaming e alterações de dados incrementais. O Streaming Estruturado integra-se firmemente ao Delta Lake, e essas tecnologias fornecem as bases para o Lakeflow Spark Declarative Pipelines e o Carregador Automático. Consulte Conceitos de Streaming Estruturado.
Processamento transacional online
O Lakebase é um banco de dados OLTP (processamento transacional online) totalmente integrado à Plataforma de Inteligência de Dados do Databricks. Esse banco de dados Postgres totalmente gerenciado permite que você crie e gerencie bancos de dados OLTP armazenados no armazenamento gerenciado pelo Azure Databricks. Veja O que é o Lakebase Provisioned?