Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Saiba o que é o Lakeflow Spark Declarative Pipelines (SDP), os principais conceitos (como pipelines, tabelas de streaming e exibições materializadas) que o definem, as relações entre esses conceitos e os benefícios de usá-lo em seus fluxos de trabalho de processamento de dados.
Observação
O Lakeflow Spark Declarative Pipelines requer o plano Premium. Entre em contato com sua equipe de conta do Databricks para obter mais informações.
O que é SDP?
Lakeflow Spark Declarative Pipelines é uma estrutura declarativa para desenvolver e executar pipelines de dados em lote e streaming no SQL e Python. O Lakeflow SDP expande e é interoperável com Pipelines Declarativos do Apache Spark, executando no Databricks Runtime otimizado para desempenho, e a API de Pipelines Declarativos flows do Lakeflow Spark utiliza a mesma API de DataFrame que o Apache Spark e o Structured Streaming. Os casos de uso comuns para SDP incluem ingestão incremental de dados de fontes como armazenamento em nuvem (incluindo Amazon S3, Azure ADLS Gen2 e Google Cloud Storage) e barramentos de mensagens (como Apache Kafka, Amazon Kinesis, Google Pub/Sub, Azure EventHub e Apache Pulsar), transformações incrementais em lote e streaming com operações sem estado e com estado, e processamento de fluxo em tempo real entre repositórios transacionais, como barramentos de mensagens e bancos de dados.
Para obter mais detalhes sobre o processamento de dados declarativos, consulte Processual versus processamento de dados declarativos no Databricks.
Quais são os benefícios do SDP?
A natureza declarativa do SDP fornece os seguintes benefícios em comparação com o desenvolvimento de processos de dados com as APIs do Apache Spark e Spark Structured Streaming e executá-los com o Databricks Runtime através de orquestração manual com Jobs do Lakeflow.
- Orquestração automática: o SDP orquestra etapas de processamento (chamadas de "fluxos") automaticamente para garantir a ordem correta de execução e o nível máximo de paralelismo para um desempenho ideal. Além disso, os pipelines repetem falhas transitórias automaticamente e eficientemente. O processo de repetição começa com a unidade mais granular e econômica: a tarefa Spark. Se a repetição no nível da tarefa falhar, o SDP continuará a tentar novamente o fluxo e, em seguida, todo o pipeline, se necessário.
- Processamento declarativo: o SDP fornece funções declarativas que podem reduzir centenas ou até milhares de linhas de código spark manual e de streaming estruturado para apenas algumas linhas. A API SDP AUTO CDC simplifica o processamento de eventos de captura de dados de mudança (CDC) com suporte para SCD Tipo 1 e SCD Tipo 2. Elimina a necessidade de código manual para lidar com eventos fora de ordem e não requer uma compreensão da semântica de streaming ou conceitos como marcas d'água.
- Processamento incremental: o SDP fornece um mecanismo de processamento incremental para exibições materializadas. Para usá-la, você escreve sua lógica de transformação com semântica em lote e o mecanismo processará apenas novos dados e alterações nas fontes de dados sempre que possível. O processamento incremental reduz o reprocessamento ineficiente quando novos dados ou alterações ocorrem nas fontes e elimina a necessidade de código manual para lidar com o processamento incremental.
Conceitos Principais
O diagrama a seguir ilustra os conceitos mais importantes dos Pipelines Declarativos do Lakeflow Spark.
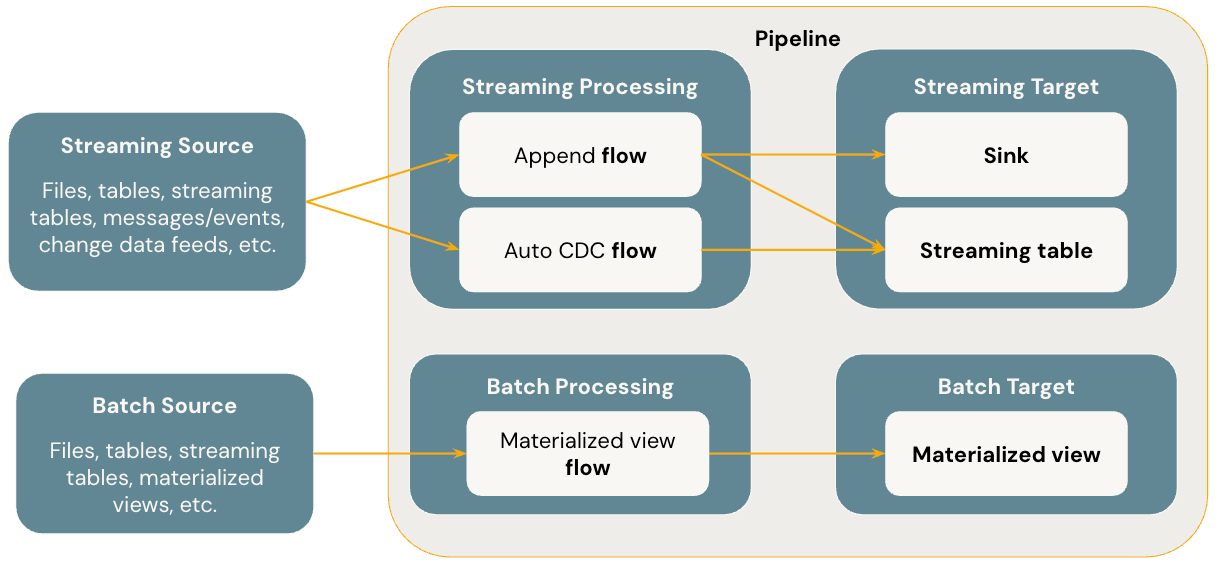
Flows
Um fluxo é o conceito fundamental de processamento de dados no SDP que dá suporte tanto à semântica de streaming quanto à de processamento em lote. Um fluxo lê dados de uma fonte, aplica a lógica de processamento definida pelo usuário e grava o resultado em um destino. O SDP compartilha o mesmo tipo de fluxo de streaming (Acrescentar, Atualizar, Concluir) que o Streaming Estruturado do Spark. (Atualmente, somente o fluxo de Anexação é exposto.) Para obter mais detalhes, consulte os modos de saída no Streaming Estruturado.
O Lakeflow Spark Declarative Pipelines também fornece tipos de fluxo adicionais:
- O AUTO CDC é um fluxo de streaming exclusivo no Lakeflow SDP que lida com eventos CDC fora de ordem e dá suporte ao SCD Tipo 1 e SCD Tipo 2. O Auto CDC não está disponível nos pipelines declarativos do Apache Spark.
- A exibição materializada é um fluxo em lote no SDP que processa apenas novos dados e alterações nas tabelas de origem sempre que possível.
Para obter mais detalhes, consulte:
Tabelas de streaming
Uma tabela de streaming é um tipo de tabela gerenciada do Catálogo do Unity que também é um destino de streaming para o Lakeflow SDP. Uma tabela de streaming pode ter um ou mais fluxos de streaming (Acréscimo, CDC AUTOMÁTICO) gravados nela. AUTO CDC é um fluxo de streaming exclusivo que só está disponível para tabelas de streaming no Databricks. Você pode definir fluxos de streaming de forma explícita e separada da tabela de streaming de destino. Você também pode definir fluxos de streaming implicitamente como parte de uma definição de tabela de streaming.
Para obter mais detalhes, consulte:
Visões materializadas
Uma exibição materializada também é uma forma de tabela gerenciada pelo Unity Catalog e serve como um alvo em processamento por lote. Uma exibição materializada pode ter um ou mais fluxos de exibição materializados gravados nele. As exibições materializadas diferem das tabelas de streaming, pois você sempre define os fluxos implicitamente como parte da definição de exibição materializada.
Para obter mais detalhes, consulte:
Sinks
Um coletor é um destino de streaming para um pipeline e dá suporte a tabelas Delta, tópicos do Apache Kafka, tópicos do Azure EventHubs e fontes de dados personalizadas do Python. Um coletor pode ter um ou mais fluxos de streaming (Acréscimo) gravados nele.
Para obter mais detalhes, consulte:
Pipelines
Um pipeline é a unidade de desenvolvimento e execução no sistema Lakeflow Spark Declarative Pipelines. Um pipeline pode conter um ou mais fluxos, tabelas de streaming, exibições materializadas e coletores. Você usa o SDP ao definir fluxos, tabelas de streaming, visões materializadas e destinos no código-fonte do pipeline, e então executa o pipeline. Enquanto o pipeline é executado, ele analisa as dependências de seus fluxos definidos, tabelas de streaming, exibições materializadas e coletores e orquestra automaticamente sua ordem de execução e paralelização.
Para obter mais detalhes, consulte:
Pipelines de SQL do Databricks
Tabelas de streaming e exibições materializadas são duas funcionalidades fundamentais no DATAbricks SQL. Você pode usar o SQL padrão para criar e atualizar tabelas de streaming e exibições materializadas no DATAbricks SQL. As tabelas de streaming e as exibições materializadas no DATAbricks SQL são executadas na mesma infraestrutura do Azure Databricks e têm a mesma semântica de processamento que no Lakeflow Spark Declarative Pipelines. Quando você usa tabelas de streaming e exibições materializadas no Databricks SQL, os fluxos são definidos implicitamente como parte das tabelas de streaming e da definição de exibições materializadas.
Para obter mais detalhes, consulte: