Databricks Autologging
Essa página cobre como personalizar Databricks Autologging, que captura automaticamente parâmetros de modelos, métricas, arquivos e informações de linhagem quando você treina modelos de várias bibliotecas de aprendizado de máquina populares. As sessões de treinamento são registradas como execuções de acompanhamento do MLflow. Os arquivos de modelo também são acompanhados para que você possa registrá-los facilmente no Registro de Modelos do MLflow.
Observação
Para habilitar o registro em log de rastreamento para cargas de trabalho de IA generativa, o MLflow oferece suporte ao log automático do OpenAI.
O vídeo a seguir mostra o Databricks Autologging com uma sessão de treinamento de modelo scikit-learn em um notebook Python interativo. As informações de acompanhamento são capturadas e exibidas automaticamente na barra lateral Execuções de experimento e na interface do usuário do MLflow.
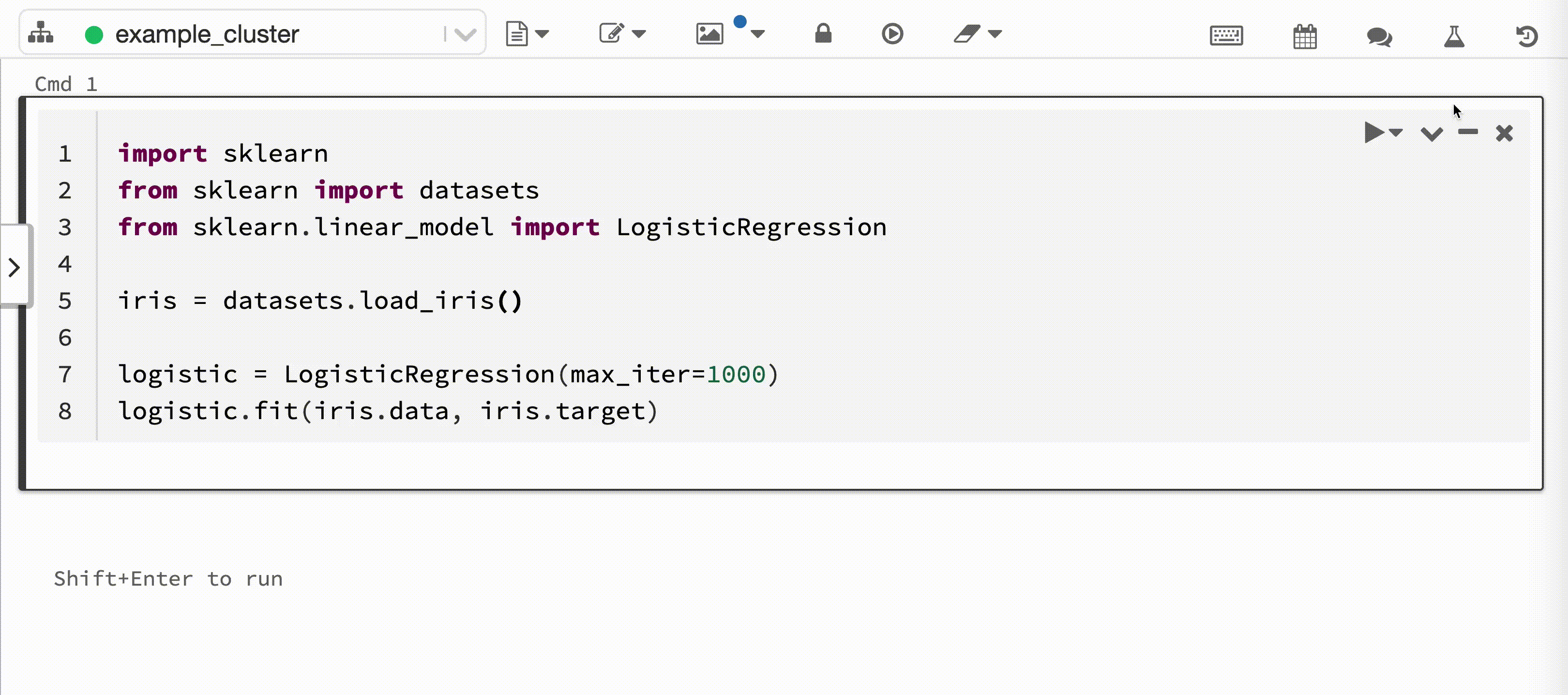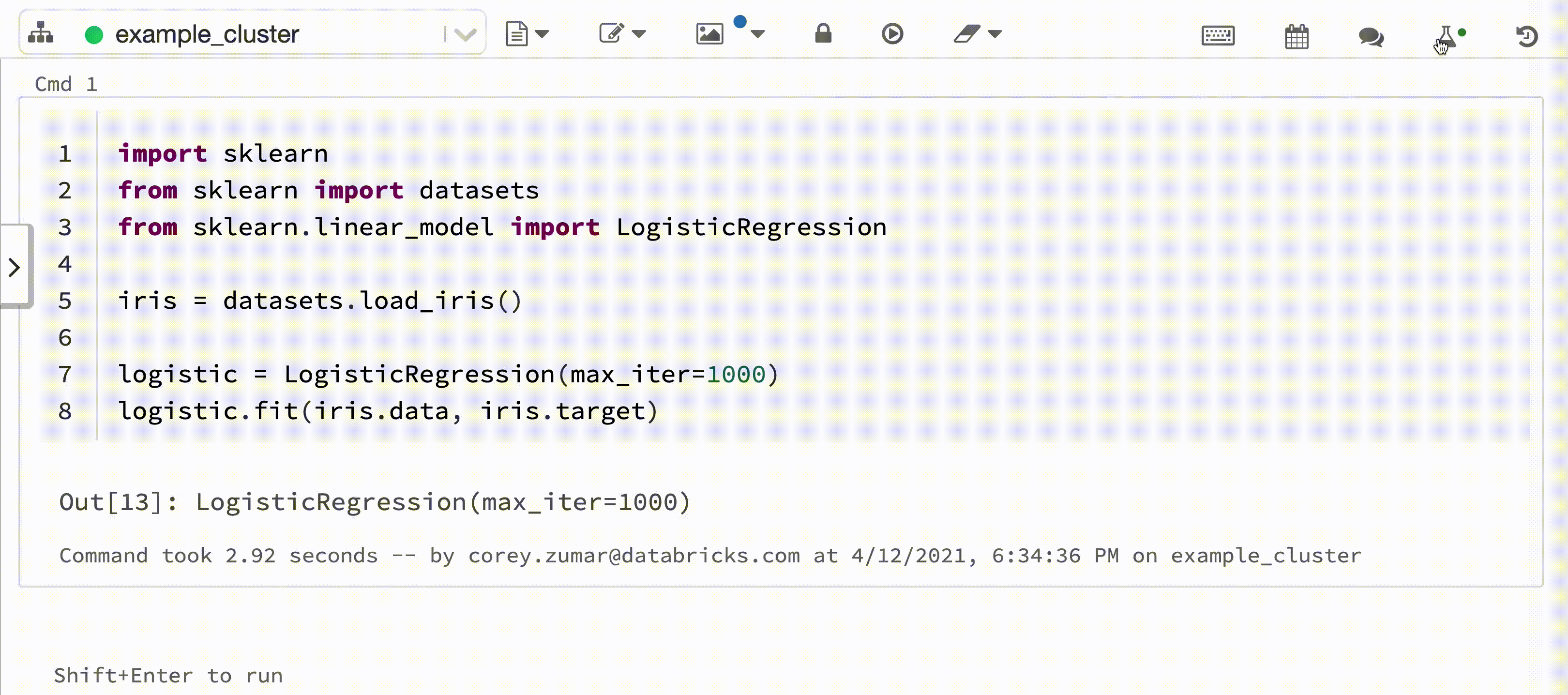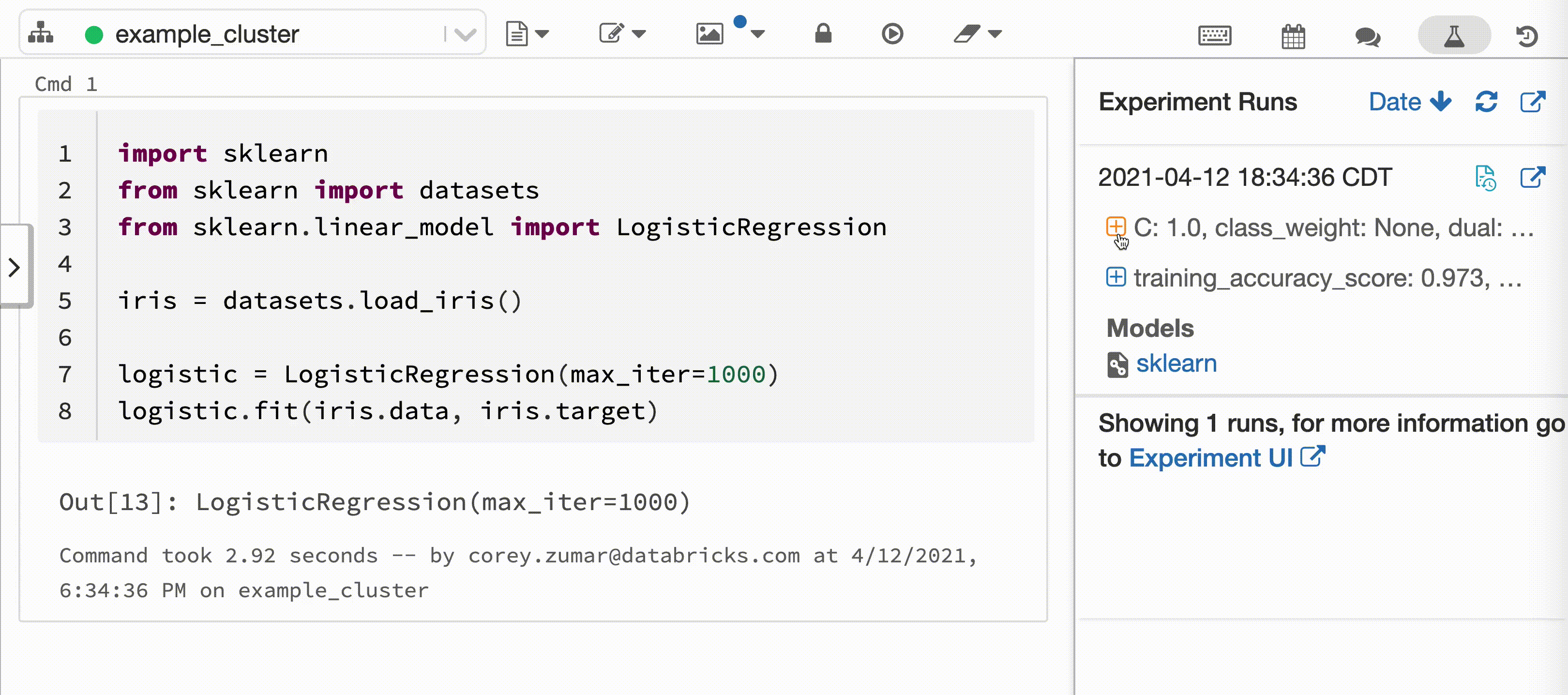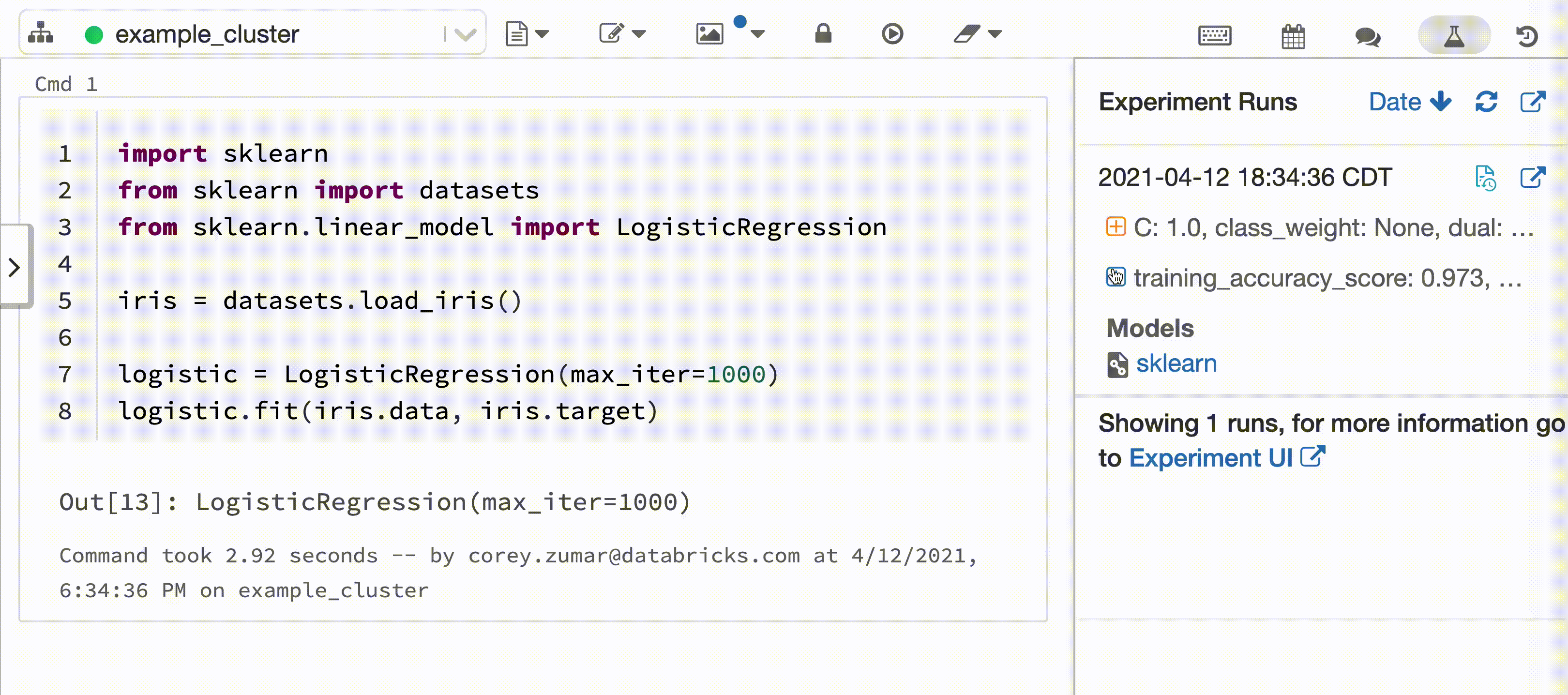
Requisitos
- O Registro em Log Automático do Databricks está em disponibilidade geral em todas as regiões com o Databricks Runtime 10.4 LTS ML ou superior.
- O Databricks Autologging está disponível em regiões de versão prévia selecionadas com o Databricks Runtime 9.1 LTS ML ou superior.
Como ele funciona
Quando você anexa um notebook Python interativo a um cluster do Azure Databricks, o Databricks Autologging chama mlflow.autolog() para configurar o acompanhamento para suas sessões de treinamento de modelo. Quando você treina modelos no notebook, as informações de treinamento do modelo são rastreadas automaticamente com o Acompanhamento do MLflow. Para obter informações sobre como essas informações de treinamento de modelo são protegidas e gerenciadas, consulte Segurança e gerenciamento de dados.
A configuração padrão para a chamada mlflow.autolog() é:
mlflow.autolog(
log_input_examples=False,
log_model_signatures=True,
log_models=True,
disable=False,
exclusive=False,
disable_for_unsupported_versions=True,
silent=False
)
Você pode personalizar a configuração de registro em log automático.
Uso
Para usar o Databricks Autologging, treine um modelo de machine learning em uma estrutura com suporte usando um notebook Python interativo do Azure Databricks. O Databricks Autologging registra automaticamente informações de linhagem de modelo, parâmetros e métricas para o Acompanhamento do MLflow. Você também pode personalizar o comportamento do Databricks Autologging.
Observação
O Databricks Autologging não é aplicado a execuções criadas usando a API fluente do MLflow com mlflow.start_run(). Nesses casos, você deve chamar mlflow.autolog() para salvar o conteúdo registrado automaticamente na execução MLflow. Confira Acompanhar conteúdo adicional.
Personalizar o comportamento de registro em log
Para personalizar o registro em log, use mlflow.autolog().
Essa função fornece parâmetros de configuração para habilitar o registro em log do modelo (log_models), registrar conjuntos de dados (log_datasets), coletar exemplos de entrada (log_input_examples), registrar assinaturas de modelo (log_model_signatures), configurar avisos (silent) e muito mais.
Acompanhar conteúdo adicional
Para acompanhar métricas, parâmetros, arquivos e metadados adicionais com execuções do MLflow criadas pelo Databricks Autologging, siga estas etapas em um notebook Python interativo do Azure Databricks:
- Chame mlflow.autolog() com
exclusive=False. - Inicie uma execução do MLflow usando mlflow.start_run().
Você pode envolver essa chamada em
with mlflow.start_run(). Quando fizer isso, a operação será encerrada automaticamente após a conclusão. - Use métodos de Acompanhamento do MLflow, como mlflow.log_param(), para acompanhar o conteúdo de pré-treinamento.
- Treine um ou mais modelos de machine learning em uma estrutura com suporte pelo Databricks Autologging.
- Use métodos de Acompanhamento do MLflow, como mlflow.log_metric(), para acompanhar o conteúdo de pós-treinamento.
- Se você não usou
with mlflow.start_run()na Etapa 2, termine a execução do MLflow usando mlflow.end_run().
Por exemplo:
import mlflow
mlflow.autolog(exclusive=False)
with mlflow.start_run():
mlflow.log_param("example_param", "example_value")
# <your model training code here>
mlflow.log_metric("example_metric", 5)
Desabilitar Databricks Autologging
Para desabilitar o Databricks Autologging em um notebook Python interativo do Azure Databricks, chame mlflow.autolog() com disable=True:
import mlflow
mlflow.autolog(disable=True)
Os administradores também podem desabilitar o Databricks Autologging para todos os clusters em um workspace na guia Avançado da página de configurações de administração. Os clusters devem ser reiniciados para que essa alteração entre em vigor.
Ambientes e estruturas com suporte
O Databricks Autologging tem suporte em notebooks Python interativos e está disponível para as seguintes estruturas ML:
- scikit-learn
- MLlib do Apache Spark
- TensorFlow
- Keras
- PyTorch Lightning
- XGBoost
- LightGBM
- Gluon
- Fast.ai
- statsmodels
- PaddlePaddle
- OpenAI
- LangChain
Para obter mais informações sobre cada uma das estruturas com suporte, consulte Registro em log automático do MLflow.
Habilitação de rastreamento do MLflow
O Rastreamento do MLflow utiliza o recurso autolog nas respectivas integrações da estrutura do modelo para controlar a habilitação ou desabilitação do suporte ao rastreamento para integrações que dão suporte ao rastreamento.
Por exemplo, para habilitar o rastreamento ao usar um modelo LlamaIndex, utilize mlflow.llama_index.autolog() com log_traces=True:
import mlflow
mlflow.llama_index.autolog(log_traces=True)
As integrações com suporte que têm ativação de rastreamento em suas implementações de log automático são:
Segurança e gerenciamento de dados
Todas as informações de treinamento de modelo rastreadas com o Databricks Autologging são armazenadas no Acompanhamento de MLflow e são protegidas por permissões do Experimento MLflow. Você pode compartilhar, modificar ou excluir informações de treinamento de modelo usando a API de Acompanhamento do MLflow ou a interface do usuário.
Administração
Os administradores podem habilitar ou desabilitar o Databricks Autologging para todas as sessões interativas do notebook em seu espaço de trabalho na guia Avançado da página de configurações de administração. As alterações não fazem efeito até que o cluster seja reiniciado.
Limitações
- Não há suporte para o Databricks Autologging em trabalhos do Azure Databricks. Para usar o registro em log automático a partir de trabalhos, você pode chamar mlflow.autolog() explicitamente.
- O Databricks Autologging está habilitado somente no nó do driver do seu cluster do Azure Databricks. Para usar o registro em log automático a partir de nós de trabalho, você deve chamar mlflow.autolog() explicitamente de dentro do código em execução em cada trabalho.
- Não há suporte para a integração scikit-learn do XGBoost.
Apache Spark MLlib, Hyperopt e acompanhamento de MLflow automatizado
O Databricks Autologging não altera o comportamento das integrações de acompanhamento de MLflow automatizadas existentes para Apache Spark MLlib e Hyperopt.
Observação
No Databricks Runtime 10.1 ML, desabilitar a integração automatizada de acompanhamento do MLflow para os modelos CrossValidator e TrainValidationSplit MLlib do Apache Spark também desabilita o recurso do Databricks Autologging para todos os modelos MLlib do Apache Spark.