Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo descreve as configurações de acesso a dados executadas pelos administradores do Azure Databricks para todos os SQL warehouses que usam a interface do usuário.
Observação
Se o workspace estiver habilitado para o Catálogo do Unity, você não precisará executar as etapas neste artigo. O Catálogo do Unity dá suporte a SQL warehouses por padrão.
Para configurar todos os SQL warehouses usando a API REST, confira API SQL Warehouses.
Importante
A alteração dessas configurações reinicia todos os SQL warehouses em execução.
Para obter uma visão geral de como habilitar o acesso aos dados, confira Visão geral do Controle de acesso.
Observação
O Databricks recomenda usar volumes do Catálogo do Unity ou locais externos para se conectar ao armazenamento de objetos de nuvem em vez de perfis de instância. O Unity Catalog simplifica a segurança e a governança de seus dados fornecendo um local central para administrar e auditar o acesso a dados em vários workspaces em sua conta. Confira O que é o Catálogo do Unity? e Recomendações para usar locais externos.
Antes de começar
- Você precisa ser um administrador do Azure Databricks para definir configurações para todos os SQL warehouses.
Configurar uma entidade de serviço
Para configurar o acesso aos seus SQL warehouses em uma conta de armazenamento do Azure Data Lake Storage Gen2 usando entidades de serviço, siga estas etapas:
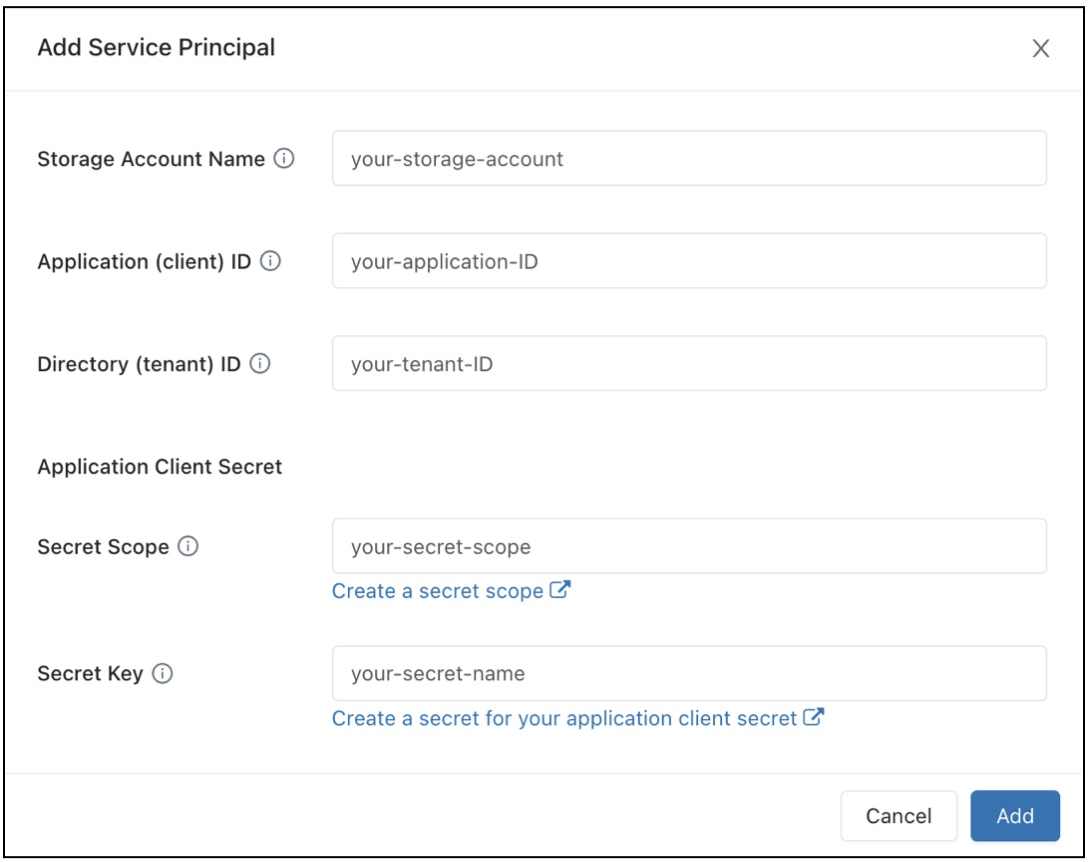
Registre um aplicativo do Microsoft Entra ID e registre as seguintes propriedades:
- ID do aplicativo (cliente): uma ID que identifica exclusivamente o aplicativo do Microsoft Entra ID.
- ID de diretório (locatário): uma ID que identifica exclusivamente a instância do Microsoft Entra ID (chamada de ID de diretório (locatário) no Azure Databricks).
- Segredo do cliente: o valor de um segredo do cliente criado para este registro de aplicativo. O aplicativo usará essa cadeia de caracteres secreta para provar sua identidade.
Na sua conta de armazenamento, adicione uma atribuição de função para o aplicativo registrado na etapa anterior para ele ter acesso à conta de armazenamento.
Crie um escopo de secreto com suporte do Azure Key Vault ou um escopo de secreto com escopo do Databricks e registre o valor da propriedade de nome do escopo:
- Nome do escopo: o nome do escopo de segredo criado.
Se estiver usando o Azure Key Vault, acesse a seção Segredos e crie um novo segredo com o nome que desejar. Use o "segredo do cliente" obtido na Etapa 1 para preencher o campo "valor" desse segredo. Mantenha um registro do nome secreto que você acabou de escolher.
- Nome do segredo: o nome do segredo do Azure Key Vault criado.
Se estiver usando um escopo com suporte do Databricks, crie um novo segredo usando a CLI do Databricks e use-o para armazenar o segredo do cliente obtido na Etapa 1. Mantenha um registro da chave secreta que você inseriu nesta etapa.
- Chave secreta: a chave do segredo criado com o backup do Databricks.
Observação
Opcionalmente, você pode criar um segredo adicional para armazenar a ID do cliente obtida na Etapa 1.
Clique no nome de usuário na barra superior do workspace e selecione Configurações do Administrador no menu suspenso.
Clique na guia Configurações do SQL Warehouse.
No campo Configuração de Acesso a Dados, clique no botão Adicionar Entidade de Serviço.
Configure as propriedades da sua conta de armazenamento do Azure Data Lake Storage Gen2.
Clique em Adicionar.
Você notará que novas entradas foram adicionadas à caixa de texto Configuração de Acesso aos Dados.
Clique em Save (Salvar).
Observação
Você também pode editar diretamente as entradas da caixa de texto Configuração de Acesso aos Dados.
Importante
Para definir uma propriedade de configuração para o valor de um segredo sem expor esse valor ao Spark, defina o valor como {{secrets/<secret-scope>/<secret-name>}}. Substitua <secret-scope> pelo escopo do segredo e <secret-name> pelo nome do segredo. O valor deve começar com {{secrets/ and end with }}. Para obter mais informações sobre essa sintaxe, confira Sintaxe para referenciar segredos em uma variável de ambiente ou uma propriedade de configuração do Spark.
Configurar propriedades de acesso a dados para SQL warehouses
Para configurar todos os warehouses com propriedades de acesso a dados:
Clique no nome de usuário na barra superior do workspace e selecione Configurações do Administrador no menu suspenso.
Clique na guia Configurações do SQL Warehouse.
Na caixa de texto Configuração de Acesso a Dados, especifique pares de chave-valor que contenham propriedades do metastore.
Importante
Para definir uma propriedade de configuração do Spark com o valor de um segredo sem expor esse valor ao Spark, defina o valor como
{{secrets/<secret-scope>/<secret-name>}}. Substitua<secret-scope>pelo escopo do segredo e<secret-name>pelo nome do segredo. O valor deve começar com{{secrets/e terminar com}}. Para obter mais informações sobre essa sintaxe, confira Sintaxe para referenciar segredos em uma variável de ambiente ou uma propriedade de configuração do Spark.Clique em Save (Salvar).
Você também pode configurar propriedades de acesso a dados usando o provedor Terraform do Databricks e databricks_sql_global_config.
Propriedades com suporte
As propriedades a seguir têm suporte para SQL warehouses. Para uma entrada que termine com *, todas as propriedades nesse prefixo têm suporte. Por exemplo, spark.sql.hive.metastore.* indica que há suporte para spark.sql.hive.metastore.jars e spark.sql.hive.metastore.version, e também para quaisquer outras propriedades iniciadas com spark.sql.hive.metastore.
No caso de propriedades cujos valores contenham informações confidenciais, você pode armazená-las em um segredo e definir o valor da propriedade como o nome do segredo, usando a seguinte sintaxe: secrets/<secret-scope>/<secret-name>.
spark.sql.hive.metastore.*spark.sql.warehouse.dirspark.hadoop.datanucleus.*spark.hadoop.fs.*spark.hadoop.hive.*spark.hadoop.javax.jdo.option.*spark.hive.*
Para obter mais informações sobre como definir essas propriedades, confira Metastore do Hive externo.