Use o SQL do Databricks em um trabalho Azure Databricks
Você pode usar o tipo de tarefa SQL em um trabalho do Azure Databricks, permitindo a criação, agendamento, operação e monitoramento de fluxos de trabalho que incluem objetos do Databricks SQL, como consultas, painéis herdados e alertas. Por exemplo, seu fluxo de trabalho pode ingerir dados, preparar os dados, executar análises usando consultas do Databricks SQL e exibir os resultados em um painel herdado.
Este artigo fornece um exemplo de fluxo de trabalho que cria um painel herdado exibindo métricas para contribuições do GitHub. Neste exemplo, você vai:
- Ingerir dados do GitHub usando um script Python e a API REST do GitHub.
- Transformar os dados do GitHub usando um pipeline do Delta Live Tables.
- Disparar consultas SQL do Databricks executando análises nos dados preparados.
- Exiba a análise em um painel herdado.
Antes de começar
Você precisa dos seguintes itens para concluir este passo a passo:
- Um token de acesso pessoal do GitHub. Esse token precisa ter a permissão do repositório.
- Um SQL warehouse sem servidor ou um SQL warehouse profissional. Consulte Tipos de SQL warehouses.
- Um escopo de segredo do Databricks. O escopo do segredo é usado para armazenar com segurança o token do GitHub. Consulte Etapa 1: armazenar o token do GitHub em um segredo.
Etapa 1: armazenar o token do GitHub em um segredo.
Em vez de codificar credenciais como o token de acesso pessoal do GitHub em um trabalho, o Databricks recomenda usar um escopo secreto para armazenar e gerenciar segredos com segurança. Os seguintes comandos da CLI do Databricks são um exemplo de criação de um escopo secreto e armazenamento do token GitHub em um segredo nesse escopo:
databricks secrets create-scope <scope-name>
databricks secrets put-secret <scope-name> <token-key> --string-value <token>
- Substitua
<scope-namepelo nome de um escopo de segredo do Azure Databricks para armazenar o token. - Substitua
<token-key>pelo nome de uma chave a ser atribuída ao token. - Substitua
<token>pelo valor do seu token de acesso pessoal do GitHub.
Etapa 2: Criar um script para buscar dados do GitHub
O script Python a seguir usa a API REST do GitHub para buscar dados sobre commits e contribuições de um repositório do GitHub. Os argumentos de entrada especificam o repositório GitHub. Os registros são salvos em um local no DBFS especificado por outro argumento de entrada.
Este exemplo usa o DBFS para armazenar o script do Python, mas você também pode usar pastas Git do Databricks ou arquivos de workspace para armazenar e gerenciar o script.
Salve esse script em um local no disco local:
import json import requests import sys api_url = "https://api.github.com" def get_commits(owner, repo, token, path): page = 1 request_url = f"{api_url}/repos/{owner}/{repo}/commits" more = True get_response(request_url, f"{path}/commits", token) def get_contributors(owner, repo, token, path): page = 1 request_url = f"{api_url}/repos/{owner}/{repo}/contributors" more = True get_response(request_url, f"{path}/contributors", token) def get_response(request_url, path, token): page = 1 more = True while more: response = requests.get(request_url, params={'page': page}, headers={'Authorization': "token " + token}) if response.text != "[]": write(path + "/records-" + str(page) + ".json", response.text) page += 1 else: more = False def write(filename, contents): dbutils.fs.put(filename, contents) def main(): args = sys.argv[1:] if len(args) < 6: print("Usage: github-api.py owner repo request output-dir secret-scope secret-key") sys.exit(1) owner = sys.argv[1] repo = sys.argv[2] request = sys.argv[3] output_path = sys.argv[4] secret_scope = sys.argv[5] secret_key = sys.argv[6] token = dbutils.secrets.get(scope=secret_scope, key=secret_key) if (request == "commits"): get_commits(owner, repo, token, output_path) elif (request == "contributors"): get_contributors(owner, repo, token, output_path) if __name__ == "__main__": main()Carregue o script no DBFS:
- Acesse a página de aterrissagem do Azure Databricks e clique no
 Catálogo na barra lateral.
Catálogo na barra lateral. - Clique em Procurar DBFS.
- No navegador de arquivos DBFS, clique em Carregar. A caixa de diálogo Carregar Dados no DBFS é exibida.
- Insira um caminho no DBFS para armazenar o script, clique em Remover arquivos para carregar ou clique para navegar e selecione o script Python.
- Clique em Concluído.
- Acesse a página de aterrissagem do Azure Databricks e clique no
Etapa 3: Criar um pipeline do Delta Live Tables para processar os dados do GitHub
Nesta seção, você criará um pipeline do Delta Live Tables para converter os dados brutos do GitHub em tabelas que podem ser analisadas por consultas SQL do Databricks. Para criar o pipeline, execute as seguintes etapas:
Na barra lateral, clique no
 Novo e selecione Notebook no menu. A caixa de diálogo Criar Notebook será exibida.
Novo e selecione Notebook no menu. A caixa de diálogo Criar Notebook será exibida.Em Idioma Padrão, insira um nome e selecione Python. Mantenha Cluster definido com o valor padrão. O runtime do Delta Live Tables cria um cluster antes de executar o pipeline.
Clique em Criar.
Copie o código de exemplo em Python e cole-o em seu novo notebook. Você pode adicionar o código de exemplo a uma única célula do notebook ou a várias células.
import dlt from pyspark.sql.functions import * def parse(df): return (df .withColumn("author_date", to_timestamp(col("commit.author.date"))) .withColumn("author_email", col("commit.author.email")) .withColumn("author_name", col("commit.author.name")) .withColumn("comment_count", col("commit.comment_count")) .withColumn("committer_date", to_timestamp(col("commit.committer.date"))) .withColumn("committer_email", col("commit.committer.email")) .withColumn("committer_name", col("commit.committer.name")) .withColumn("message", col("commit.message")) .withColumn("sha", col("commit.tree.sha")) .withColumn("tree_url", col("commit.tree.url")) .withColumn("url", col("commit.url")) .withColumn("verification_payload", col("commit.verification.payload")) .withColumn("verification_reason", col("commit.verification.reason")) .withColumn("verification_signature", col("commit.verification.signature")) .withColumn("verification_verified", col("commit.verification.signature").cast("string")) .drop("commit") ) @dlt.table( comment="Raw GitHub commits" ) def github_commits_raw(): df = spark.read.json(spark.conf.get("commits-path")) return parse(df.select("commit")) @dlt.table( comment="Info on the author of a commit" ) def commits_by_author(): return ( dlt.read("github_commits_raw") .withColumnRenamed("author_date", "date") .withColumnRenamed("author_email", "email") .withColumnRenamed("author_name", "name") .select("sha", "date", "email", "name") ) @dlt.table( comment="GitHub repository contributors" ) def github_contributors_raw(): return( spark.readStream.format("cloudFiles") .option("cloudFiles.format", "json") .load(spark.conf.get("contribs-path")) )Na barra lateral, clique em
 Fluxos de Trabalho, clique na guia Delta Live Tables e em Criar pipeline.
Fluxos de Trabalho, clique na guia Delta Live Tables e em Criar pipeline.Dê um nome ao pipeline, por exemplo,
Transform GitHub data.No campo Bibliotecas de notebooks, insira o caminho para o notebook ou clique em
 para selecionar o notebook.
para selecionar o notebook.Clique em Adicionar configuração. Na caixa de texto
Key, insiracommits-path. Na caixa de textoValue, insira o caminho DBFS em que os registros do GitHub serão gravados. Esse pode ser qualquer caminho escolhido e é o mesmo caminho que você usará ao configurar a primeira tarefa do Python ao criar o fluxo de trabalho.Clique novamente em Adicionar Configuração. Na caixa de texto
Key, insiracontribs-path. Na caixa de textoValue, insira o caminho DBFS em que os registros do GitHub serão gravados. Esse pode ser qualquer caminho escolhido e é o mesmo caminho que você usará ao configurar a segunda tarefa do Python ao criar o fluxo de trabalho.No campo Destino, insira um banco de dados de destino, por exemplo,
github_tables. Definir um banco de dados de destino publica os dados de saída no metastore e é necessário para as consultas downstream que analisam os dados produzidos pelo pipeline.Clique em Save (Salvar).
Etapa 4: Criar um fluxo de trabalho para ingerir e transformar dados do GitHub
Antes de analisar e visualizar os dados do GitHub com o SQL do Databricks, você precisa ingerir e preparar os dados. Para criar um fluxo de trabalho para concluir essas tarefas, execute as seguintes etapas:
Criar um trabalho do Azure Databricks e adicionar a primeira tarefa
Vá para a página inicial do Azure Databricks e siga um destes procedimentos:
- Na barra lateral, clique no Fluxos de Trabalhos e clique no
 .
. - Na barra lateral, clique no Novo e selecione Trabalho no menu.
- Na barra lateral, clique no
Na caixa de diálogo da tarefa exibida na guia Tarefas, substitua Adicionar um nome para seu trabalho... com seu nome de trabalho, por exemplo
GitHub analysis workflow.Em Nome da tarefa, insira um nome para a tarefa, por exemplo,
get_commits.Em Tipo, selecione Script do Python.
Em Fonte, selecione DBFS/S3.
Em Caminho, insira o caminho para o script no DBFS.
Em Parâmetros, insira os seguintes argumentos para o script Python:
["<owner>","<repo>","commits","<DBFS-output-dir>","<scope-name>","<github-token-key>"]- Substitua
<owner>pelo nome do proprietário do repositório. Por exemplo, para buscar registros dogithub.com/databrickslabs/overwatchrepositório, insiradatabrickslabs. - Substitua
<repo>pelo nome do repositório, por exemplo,overwatch. - Substitua
<DBFS-output-dir>por um caminho no DBFS para armazenar os registros buscados do GitHub. - Substitua
<scope-name>pelo nome do escopo do segredo que você criou para armazenar o token do GitHub. - Substitua
<github-token-key>pelo nome da chave que você atribuiu ao token do GitHub.
- Substitua
Clique em Salvar tarefa.
Adicionar outra tarefa
Clique no
 sob a tarefa recém-criada.
sob a tarefa recém-criada.Em Nome da tarefa, insira um nome para a tarefa, por exemplo,
get_contributors.Em Tipo, selecione o tipo de tarefa Script do Python.
Em Fonte, selecione DBFS/S3.
Em Caminho, insira o caminho para o script no DBFS.
Em Parâmetros, insira os seguintes argumentos para o script Python:
["<owner>","<repo>","contributors","<DBFS-output-dir>","<scope-name>","<github-token-key>"]- Substitua
<owner>pelo nome do proprietário do repositório. Por exemplo, para buscar registros dogithub.com/databrickslabs/overwatchrepositório, insiradatabrickslabs. - Substitua
<repo>pelo nome do repositório, por exemplo,overwatch. - Substitua
<DBFS-output-dir>por um caminho no DBFS para armazenar os registros buscados do GitHub. - Substitua
<scope-name>pelo nome do escopo do segredo que você criou para armazenar o token do GitHub. - Substitua
<github-token-key>pelo nome da chave que você atribuiu ao token do GitHub.
- Substitua
Clique em Salvar tarefa.
Adicionar uma tarefa para transformar os dados
- Clique no sob a tarefa recém-criada.
- Em Nome da tarefa, insira um nome para a tarefa, por exemplo,
transform_github_data. - Em Tipo, selecione Pipeline do Delta Live Tables e insira um nome para a tarefa.
- Em Pipeline, selecione o pipeline criado na Etapa 3: criar um pipeline do Delta Live Tables para processar os dados do GitHub.
- Clique em Criar.
Etapa 5: Executar o fluxo de trabalho de transformação de dados
Clique no  agora para executar o fluxo de trabalho. Para exibir detalhes da execução, clique no link na coluna Hora de início da execução no modo de exibição execuções do trabalho. Clique em cada tarefa para exibir detalhes da execução da tarefa.
agora para executar o fluxo de trabalho. Para exibir detalhes da execução, clique no link na coluna Hora de início da execução no modo de exibição execuções do trabalho. Clique em cada tarefa para exibir detalhes da execução da tarefa.
Etapa 6: (Opcional) Para exibir os dados de saída após a conclusão da execução do fluxo de trabalho, execute as seguintes etapas:
- Na exibição de detalhes da execução, clique na tarefa Delta Live Tables.
- No painel Detalhes da execução da tarefa, clique no nome do pipeline em Pipeline. A página Detalhes do Pipeline é exibida.
- Selecione a tabela
commits_by_authorno DAG do pipeline. - Clique no nome da tabela ao lado de Metastore no painel commits_by_author. A página do Explorador de Catálogos é aberta.
No Explorador de Catálogos, você pode exibir o esquema da tabela, os dados de amostra e outros detalhes dos dados. Siga as mesmas etapas para exibir os dados da tabela github_contributors_raw.
Etapa 7: Remover os dados do GitHub
Em um aplicativo do mundo real, você pode estar ingerindo e processando dados continuamente. Como este exemplo baixa e processa todo o conjunto de dados, você deve remover os dados do GitHub já baixados para evitar um erro ao executar novamente o fluxo de trabalho. Para remover os dados baixados, execute as seguintes etapas:
Crie um novo notebook e insira os seguintes comandos na primeira célula:
dbutils.fs.rm("<commits-path", True) dbutils.fs.rm("<contributors-path", True)Substitua
<commits-path>e<contributors-path>pelos caminhos DBFS que você configurou ao criar as tarefas do Python.Clique em
 e selecione Executar célula.
e selecione Executar célula.
Você também pode adicionar esse notebook como uma tarefa no fluxo de trabalho.
Etapa 8: Criar as consultas SQL do Databricks
Depois de executar o fluxo de trabalho e criar as tabelas necessárias, crie consultas para analisar os dados preparados. Para criar as consultas e visualizações de exemplo, execute as seguintes etapas:
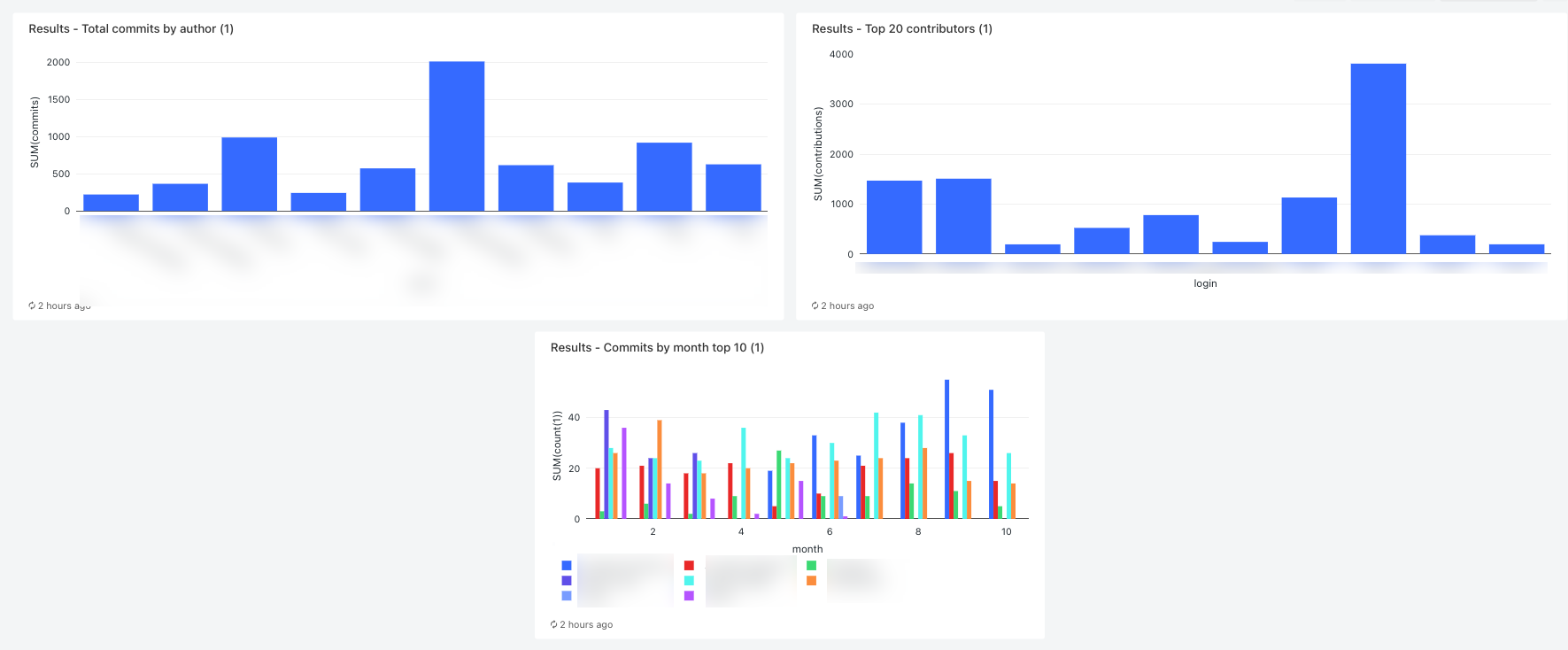
Exibir os 10 principais colaboradores por mês
Clique no ícone abaixo do logotipo do Databricks
 na barra lateral e selecione SQL.
na barra lateral e selecione SQL.Clique em Criar uma consulta para abrir o editor de consultas SQL do Databricks.
Verifique se o catálogo está definido como hive_metastore. Clique em padrão ao lado de hive_metastore e defina o banco de dados como o valor de Destino definido no pipeline do Delta Live Tables.
Na página Nova Consulta, execute a seguinte consulta:
SELECT date_part('YEAR', date) AS year, date_part('MONTH', date) AS month, name, count(1) FROM commits_by_author WHERE name IN ( SELECT name FROM commits_by_author GROUP BY name ORDER BY count(name) DESC LIMIT 10 ) AND date_part('YEAR', date) >= 2022 GROUP BY name, year, month ORDER BY year, month, nameClique na guia Nova consulta e renomeie a consulta, por exemplo,
Commits by month top 10 contributors.Por padrão, os resultados são exibidos como uma tabela. Para alterar como os dados são visualizados, por exemplo, usando um gráfico de barras, no painel Resultados, clique nas
 e clique em Editar.
e clique em Editar.Em Tipo de visualização, selecione Barra.
Na coluna X, selecione mês.
Nas colunas Y, selecione contagem(1).
Em Agrupar por, selecione nome.
Clique em Save (Salvar).
Exibir os 20 principais colaboradores
Clique em +> Criar nova consulta e verifique se o catálogo está definido como hive_metastore. Clique em padrão ao lado de hive_metastore e defina o banco de dados como o valor de Destino definido no pipeline do Delta Live Tables.
Insira a consulta a seguir:
SELECT login, cast(contributions AS INTEGER) FROM github_contributors_raw ORDER BY contributions DESC LIMIT 20Clique na guia Nova consulta e renomeie a consulta, por exemplo,
Top 20 contributors.Para alterar a visualização da tabela padrão, no painel Resultados, clique em
e clique em Editar.Em Tipo de visualização, selecione Barra.
Na coluna X, selecione login.
Em colunas Y, selecione contribuições.
Clique em Save (Salvar).
Exibir o total de commits por autor
Clique em +> Criar nova consulta e verifique se o catálogo está definido como hive_metastore. Clique em padrão ao lado de hive_metastore e defina o banco de dados como o valor de Destino definido no pipeline do Delta Live Tables.
Insira a consulta a seguir:
SELECT name, count(1) commits FROM commits_by_author GROUP BY name ORDER BY commits DESC LIMIT 10Clique na guia Nova consulta e renomeie a consulta, por exemplo,
Total commits by author.Para alterar a visualização da tabela padrão, no painel Resultados, clique em
e clique em Editar.Em Tipo de visualização, selecione Barra.
Na coluna X, selecione nome.
Na coluna Y, selecione commits.
Clique em Save (Salvar).
Step 9: criar um painel
- Na barra lateral, clique no
 Painéis
Painéis - Clique em Criar painel.
- Insira um nome para o painel, por exemplo,
GitHub analysis. - Para cada consulta e visualização criada na Etapa 8: criar as consultas SQL do Databricks, clique em Adicionar > Visualização e selecione cada visualização.
Etapa 10: Adicionar as tarefas do SQL ao fluxo de trabalho
Para adicionar as novas tarefas de consulta ao fluxo de trabalho criado em Criar um trabalho do Azure Databricks e adicionar a primeira tarefa, para cada consulta que você criou na Etapa 8: Criar as consultas SQL do Databricks:
- Clique no Fluxos de Trabalho na barra lateral.
- Na coluna Nome, clique no nome do trabalho.
- Clique na guia Tarefas.
- Clique em abaixo da última tarefa.
- Insira um nome para a tarefa, em Tipo, selecione SQL e, na tarefa SQL, selecione Consulta.
- Selecione a consulta na Consulta SQL.
- No SQL Warehouse, selecione um SQL Warehouse sem servidor ou um SQL Warehouse profissional para executar a tarefa.
- Clique em Criar.
Etapa 11: Adicionar uma tarefa de painel
- Clique em abaixo da última tarefa.
- Insira um nome para a tarefa, em Tipo, selecione SQL e, na tarefa SQL, selecione Painel herdado.
- Selecione o painel criado na Etapa 9: Criar um painel.
- No SQL Warehouse, selecione um SQL Warehouse sem servidor ou um SQL Warehouse profissional para executar a tarefa.
- Clique em Criar.
Etapa 12: Executar o fluxo de trabalho completo
Para executar o fluxo de trabalho, clique no . Para exibir detalhes da execução, clique no link na coluna Hora de início da execução no modo de exibição execuções do trabalho.
Etapa 13: Ver os resultados
Para exibir os resultados quando a execução for concluída, clique na tarefa final do painel e clique no nome do painel no painel SQL no painel direito.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de