Por que pipelines de dados?
Azure DevOps Services
Você pode usar pipelines de dados para:
- Ingerir dados de várias fontes de dados
- Processar e transformar os dados
- Salvar os dados processados em um local de preparo para outras pessoas consumirem
Os pipelines de dados na empresa podem evoluir para cenários mais complicados com vários sistemas de origem e dar suporte a vários aplicativos downstream.
Os pipelines de dados fornecem:
- Consistência: pipelines de dados transformam dados em um formato consistente para os usuários consumirem
- Redução de erros: pipelines de dados automatizados eliminam erros humanos ao manipular dados
- Eficiência: os profissionais de dados economizam tempo gasto na transformação de processamento de dados. Poupar tempo permite então se concentrar em sua função de trabalho principal: obter insight dos dados e ajudar as empresas a tomar decisões melhores
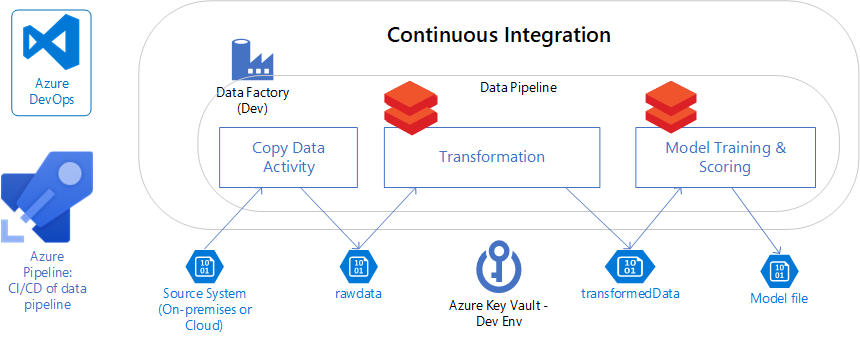
O que é CI/CD?
A CI/CD (integração contínua e entrega contínua) é uma abordagem de desenvolvimento de software em que todos os desenvolvedores trabalham juntos em um repositório compartilhado de código – e conforme as alterações são feitas, há um processo de build automatizado para detectar problemas de código. O resultado é um ciclo de vida de desenvolvimento mais rápido e uma taxa de erro menor.
O que é um pipeline de dados de CI/CD e por que ele importa para a ciência de dados?
A criação de modelos de machine learning é semelhante ao desenvolvimento de software tradicional no sentido de que o cientista de dados precisa escrever código para treinar e pontuar modelos de machine learning.
Ao contrário do desenvolvimento de software tradicional em que o produto se baseia no código, os modelos de machine learning de ciência de dados são baseados no código (algoritmo, hiperparâmetros) e nos dados usados para treinar o modelo. É por isso que a maioria dos cientistas de dados informará que eles gastam 80% do tempo fazendo preparação de dados, limpeza e engenharia de recursos.
Para complicar ainda mais a questão – para garantir a qualidade dos modelos de machine learning, técnicas como testes A/B são usadas. Com os testes A/B, pode haver vários modelos de machine learning em uso ao mesmo tempo. Geralmente, há um modelo de controle e um ou mais modelos de tratamento para comparação para que o desempenho do modelo possa ser comparado e mantido. Ter vários modelos adiciona outra camada de complexidade para a CI/CD dos modelos de machine learning.
Ter um pipeline de dados de CI/CD é crucial para a equipe de ciência de dados fornecer os modelos de machine learning para os negócios em tempo hábil e de qualidade.
Próximas etapas
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de