Execuções de pipeline
Azure DevOps Services | Azure DevOps Server 2022 - Azure DevOps Server 2019
Este artigo explica a sequência de atividades nas execuções de pipeline do Azure Pipelines. Um build representa uma execução de um pipeline. Os pipelines de CI (integração contínua) e CD (entrega contínua) consistem em execuções. Durante uma execução, o Azure Pipelines processa o pipeline e os agentes processam um ou mais trabalhos, etapas e tarefas.
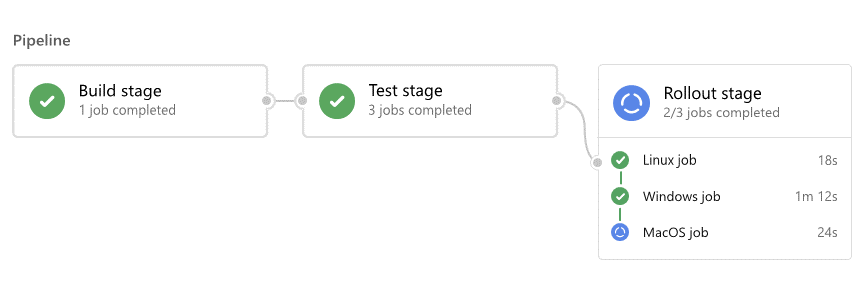
Para cada execução, o Azure Pipelines:
- Processa o pipeline.
- Solicita que um ou mais agentes executem trabalhos.
- Entrega trabalhos aos agentes e coleta os resultados.
Para cada trabalho, um agente:
- Prepara para o trabalho.
- Executa cada etapa do trabalho.
- Relata resultados.
Os trabalhos podem ser bem-sucedidos, falhar, ser cancelados ou não concluídos. Entender esses resultados pode ajudá-lo a solucionar problemas.
As seções a seguir descrevem o processo de execução do pipeline em detalhes.
Processamento de pipeline
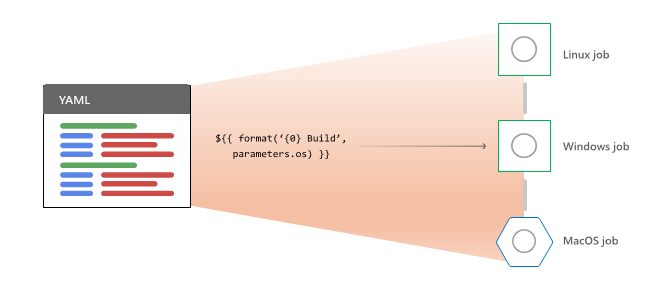
Para processar um pipeline para uma execução, o Azure Pipelines primeiro:
- Expande modelos e avalia expressões de modelo.
- Avalia as dependências no nível do estágio para escolher o primeiro estágio a ser executado.
Para cada estágio selecionado para execução, o Azure Pipelines:
- Reúne e valida todos os recursos de trabalho para autorização de execução.
- Avalia as dependências no nível do trabalho para escolher o primeiro trabalho a ser executado.
O Azure Pipelines executa as seguintes atividades para cada trabalho selecionado para execução:
- Expande YAML
strategy: matrixoustrategy: parallelvárias configurações em vários trabalhos de tempo de execução. - Avalia as condições para decidir se o trabalho está qualificado para execução.
- Solicita um agente para cada trabalho qualificado.
À medida que os trabalhos de runtime são concluídos, o Azure Pipelines verifica se há novos trabalhos qualificados para execução. Da mesma forma, à medida que os estágios são concluídos, o Azure Pipelines verifica se há mais estágios.
Variáveis
Entender a ordem de processamento esclarece por que você não pode usar determinadas variáveis nos parâmetros do modelo. A primeira etapa de expansão do modelo opera apenas no texto do arquivo YAML. As variáveis de tempo de execução ainda não existem durante essa etapa. Após essa etapa, os parâmetros do modelo já foram resolvidos.
Você também não pode usar variáveis para resolver nomes de conexão de serviço ou ambiente, pois o pipeline autoriza recursos antes que um estágio possa começar a ser executado. As variáveis de estágio e nível de trabalho ainda não estão disponíveis. Os grupos de variáveis são um recurso sujeito à autorização, portanto, seus dados não estão disponíveis ao verificar a autorização do recurso.
Você pode usar variáveis no nível do pipeline que são explicitamente incluídas na definição de recurso do pipeline. Para obter mais informações, confira Metadados de recursos do pipeline como variáveis predefinidas.
Agentes
Quando o Azure Pipelines precisa executar um trabalho, ele solicita um agente do pool. O processo funciona de forma diferente para pools de agentes hospedados e auto-hospedados pela Microsoft.
Observação
Os trabalhos de servidor não usam um pool porque são executados no próprio servidor do Azure Pipelines.
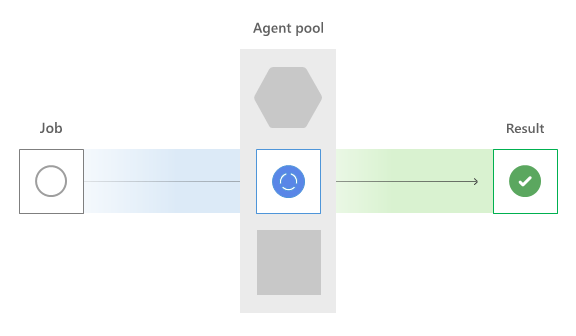
Trabalhos paralelos
Primeiro, o Azure Pipelines verifica os trabalhos paralelos da sua organização. O serviço soma todos os trabalhos em execução em todos os agentes e os compara com o número de trabalhos paralelos concedidos ou comprados.
Se não houver slots paralelos disponíveis, o trabalho precisará aguardar a liberação de um slot. Quando um slot paralelo estiver disponível, o trabalho será roteado para o tipo de agente apropriado.
Agentes hospedados pela Microsoft
Conceitualmente, o pool hospedado pela Microsoft é um pool global de computadores, embora seja fisicamente muitos pools diferentes divididos por geografia e tipo de sistema operacional. Com base no nome do pool do editor YAML vmImage ou Clássico solicitado, o Azure Pipelines seleciona um agente.
Todos os agentes no pool da Microsoft são VMs (máquinas virtuais) novas e novas que nunca executaram nenhum pipeline. Quando o trabalho é concluído, a VM do agente é descartada.
Agentes auto-hospedados
Depois que um slot paralelo estiver disponível, o Azure Pipelines examinará o pool auto-hospedado em busca de um agente compatível. Os agentes auto-hospedados oferecem recursos, que indicam que um software específico está instalado ou as configurações definidas. O pipeline tem demandas, que são os recursos necessários para executar o trabalho.
Se o Azure Pipelines não conseguir encontrar um agente livre cujos recursos correspondam às demandas do pipeline, o trabalho continuará aguardando. Se não houver agentes no pool cujos recursos correspondam às demandas, o trabalho falhará.
Os agentes auto-hospedados normalmente são reutilizados de execução para execução. Para agentes auto-hospedados, um trabalho de pipeline pode ter efeitos colaterais, como aquecer caches ou ter a maioria das confirmações já disponíveis no repositório local.
Preparação do trabalho
Depois que um agente aceita um trabalho, ele faz o seguinte trabalho de preparação:
- Baixa todas as tarefas necessárias para executar o trabalho e as armazena em cache para uso futuro.
- Cria espaço de trabalho no disco para armazenar o código-fonte, artefatos e saídas usados na execução.
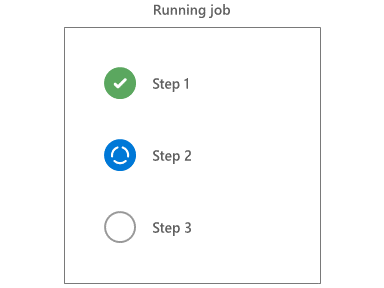
Execução da etapa
O agente executa etapas sequencialmente em ordem. Antes que uma etapa possa ser iniciada, todas as etapas anteriores devem ser concluídas ou ignoradas.
As etapas são implementadas por tarefas, que podem ser Node.js, PowerShell ou outros scripts. O sistema de tarefas roteia entradas e saídas para os scripts de suporte. As tarefas também fornecem serviços comuns, como alterar o caminho do sistema e criar novas variáveis de pipeline.
Cada etapa é executada em seu próprio processo, isolando seu ambiente das etapas anteriores. Devido a esse modelo de processo por etapa, as variáveis de ambiente não são preservadas entre as etapas. No entanto, tarefas e scripts podem usar um mecanismo chamado comandos de log para se comunicar com o agente. Quando uma tarefa ou script grava um comando de log na saída padrão, o agente executa qualquer ação solicitada pelo comando.
Você pode usar um comando de log para criar novas variáveis de pipeline. As variáveis de pipeline são convertidas automaticamente em variáveis de ambiente na próxima etapa. Um script pode definir uma nova variável myVar com um valor da myValue seguinte maneira:
echo '##vso[task.setVariable variable=myVar]myValue'
Write-Host "##vso[task.setVariable variable=myVar]myValue"
Relatório e coleta de resultados
Cada etapa pode relatar avisos, erros e falhas. A etapa relata erros e avisos na página de resumo do pipeline marcando as tarefas como bem-sucedidas com problemas ou relata falhas marcando a tarefa como falha. Uma etapa falhará se relatar explicitamente a falha usando um ##vso comando ou encerrar o script com um código de saída diferente de zero.
À medida que as etapas são executadas, o agente envia constantemente linhas de saída para o Azure Pipelines, para que você possa ver um feed dinâmico do console. No final de cada etapa, toda a saída da etapa é carregada como um arquivo de log. Você pode baixar o log assim que o pipeline for concluído.
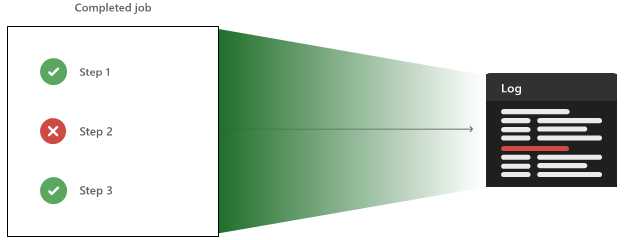
O agente também pode carregar artefatos e resultados de teste, que também estão disponíveis após a conclusão do pipeline.
Estado e condições
O agente controla o sucesso ou a falha de cada etapa. À medida que as etapas são bem-sucedidas com problemas ou falham, o status do trabalho é atualizado. O trabalho sempre reflete o pior resultado de cada uma de suas etapas. Se uma etapa falhar, o trabalho também falhará.
Antes de o agente executar uma etapa, ele verifica a condição dessa etapa para determinar se a etapa deve ser executada. Por padrão, uma etapa só é executada quando o status do trabalho é bem-sucedido ou bem-sucedido com problemas, mas você pode definir outras condições.
Muitos trabalhos têm etapas de limpeza que precisam ser executadas independentemente do que mais aconteça, para que possam especificar uma condição de always(). A limpeza ou outras etapas também podem ser definidas para serem executadas somente no cancelamento.
Uma etapa de limpeza bem-sucedida não pode evitar que o trabalho falhe. Os empregos nunca podem voltar ao sucesso depois de entrar no fracasso.
Tempos limite e desconexões
Cada trabalho tem um tempo limite. Se o trabalho não for concluído no tempo especificado, o servidor cancelará o trabalho. O servidor tenta sinalizar ao agente para parar e marca o trabalho como cancelado. Do lado do agente, cancelamento significa cancelar todas as etapas restantes e carregar os resultados restantes.
Os trabalhos têm um período de carência chamado tempo limite de cancelamento para concluir qualquer trabalho de cancelamento. Você também pode marcar as etapas a serem executadas mesmo no cancelamento. Após um tempo limite de trabalho mais um tempo limite de cancelamento, se o agente não relatar que o trabalho foi interrompido, o servidor marcará o trabalho como uma falha.
Os computadores do agente podem parar de responder ao servidor se o computador host do agente ficar sem energia ou estiver desligado, ou se houver uma falha de rede. Para ajudar a detectar essas condições, o agente envia uma mensagem de pulsação uma vez por minuto para informar ao servidor que ele ainda está operando.
Se o servidor não receber uma pulsação por cinco minutos consecutivos, ele presumirá que o agente não está voltando. O trabalho é marcado como uma falha, informando ao usuário que ele deve repetir o pipeline.
Gerenciar execuções por meio da CLI do Azure DevOps
Você pode gerenciar execuções de pipeline usando execuções az pipelines na CLI do Azure DevOps. Para começar, confira Introdução à CLI do Azure DevOps. Para obter uma referência de comando completa, consulte Referência de comando da CLI do Azure DevOps.
Os exemplos a seguir mostram como usar a CLI do Azure DevOps para listar as execuções de pipeline em seu projeto, exibir detalhes sobre uma execução específica e gerenciar marcas para execuções de pipeline.
Pré-requisitos
- CLI do Azure com a extensão da CLI do Azure DevOps instalada, conforme descrito em Introdução à CLI do Azure DevOps. Entre no Azure usando
az logino . - A organização padrão definida usando
az devops configure --defaults organization=<YourOrganizationURL>.
Listar execuções de pipeline
Liste as execuções de pipeline em seu projeto com o comando az pipelines runs list.
O comando a seguir lista as três primeiras execuções de pipeline que têm um status de concluído e um resultado de êxito e retorna o resultado no formato de tabela.
az pipelines runs list --status completed --result succeeded --top 3 --output table
Run ID Number Status Result Pipeline ID Pipeline Name Source Branch Queued Time Reason
-------- ---------- --------- --------- ------------- -------------------------- --------------- -------------------------- ------
125 20200124.1 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 18:56:10.067588 manual
123 20200123.2 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 11:55:56.633450 manual
122 20200123.1 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 11:48:05.574742 manual
Mostrar detalhes da execução de pipeline
Mostre os detalhes de uma execução de pipeline em seu projeto com o comando az pipelines runs show.
O comando a seguir mostra detalhes da execução do pipeline com a ID 123, retorna os resultados no formato de tabela e abre o navegador da Web na página de resultados de build do Azure Pipelines.
az pipelines runs show --id 122 --open --output table
Run ID Number Status Result Pipeline ID Pipeline Name Source Branch Queued Time Reason
-------- ---------- --------- --------- ------------- -------------------------- --------------- -------------------------- --------
123 20200123.2 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 11:55:56.633450 manual
Adicionar marca à execução de pipeline
Adicione uma marca a uma execução de pipeline em seu projeto com o comando az pipelines runs tag add.
O comando a seguir adiciona a marca YAML à execução de pipeline com a ID 123 e retorna o resultado no formato JSON.
az pipelines runs tag add --run-id 123 --tags YAML --output json
[
"YAML"
]
Listar marcas de execução de pipeline
Liste as marcas de uma execução de pipeline em seu projeto com o comando az pipelines runs tag list. O comando a seguir lista as marcas para a execução de pipeline com a ID 123 e retorna o resultado no formato de tabela.
az pipelines runs tag list --run-id 123 --output table
Tags
------
YAML
Excluir marca da execução de pipeline
Exclua uma marca de uma execução de pipeline em seu projeto com o comando az pipelines runs tag delete. O comando a seguir exclui a marca YAML da execução de pipeline com a ID 123.
az pipelines runs tag delete --run-id 123 --tag YAML
Conteúdo relacionado
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de