API de tabela e SQL em clusters do Apache Flink® no Azure HDInsight no AKS
Importante
Esse recurso está atualmente na visualização. Os Termos de uso complementares para versões prévias do Microsoft Azure incluem mais termos legais que se aplicam aos recursos do Azure que estão em versão beta, em versão prévia ou ainda não lançados em disponibilidade geral. Para obter informações sobre essa versão prévia específica, confira Informações sobre a versão prévia do Azure HDInsight no AKS. Caso tenha perguntas ou sugestões de recursos, envie uma solicitação no AskHDInsight com os detalhes e siga-nos para ver mais atualizações sobre a Comunidade do Azure HDInsight.
O Apache Flink apresenta duas APIs relacionais, a API de Tabela e o SQL, para processamento em lotes e fluxo unificado. A API de Tabela é uma API de consulta integrada à linguagem que permite a composição de consultas de operadores relacionais, como seleção, filtro e junção, de maneira intuitiva. O suporte ao SQL do Flink é baseado no Apache Calcite, que implementa o padrão SQL.
As interfaces de API de tabela e SQL se integram perfeitamente entre si e à API DataStream do Flink. Você pode alternar facilmente entre todas as APIs e bibliotecas, que se baseiam nelas.
SQL do Apache Flink
Assim como outros mecanismos SQL, as consultas Flink operam na parte superior das tabelas. Isso difere de um banco de dados tradicional porque o Flink não gerencia dados inativos localmente; em vez disso, suas consultas operam continuamente em tabelas externas.
Os pipelines de processamento de dados do Flink começam com tabelas de origem e terminam com tabelas de coletor. As tabelas de origem produzem linhas operadas durante a execução da consulta; elas são tabelas referenciadas na cláusula FROM de uma consulta. Os conectores podem ser do tipo HDInsight Kafka, HDInsight HBase, Hubs de Eventos do Azure, bancos de dados, sistemas de arquivos ou qualquer outro sistema cujo conector esteja no classpath.
Usando o Cliente SQL do Flink no Azure HDInsight em clusters do AKS
Você pode consultar este artigo sobre como usar a CLI por meio do Secure Shell no portal do Azure. Aqui estão alguns exemplos rápidos de como começar.
Para iniciar o cliente SQL
./bin/sql-client.shPara passar um arquivo SQL de inicialização para execução junto com o sql-client
./sql-client.sh -i /path/to/init_file.sqlPara definir uma configuração no sql-client
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
DDL do SQL
O SQL do Flink dá suporte às seguintes instruções CREATE:
- CREATE TABLE
- CREATE DATABASE
- CRIAR CATÁLOGO
Veja a seguir uma sintaxe de exemplo para definir uma tabela de origem usando o conector jdbc para se conectar ao MSSQL, com id, nome como colunas em uma instrução CREATE TABLE
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
CREATE DATABASE :
CREATE DATABASE students;
CREATE CATALOG:
CREATE CATALOG myhive WITH ('type'='hive');
Você pode executar consultas contínuas sobrepostas a essas tabelas
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Grave para a Tabela do Coletor da Tabela de Origem:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Adicionando Dependências
Instruções JAR são usadas para adicionar jars de usuário ao classpath ou remover jars de usuário do classpath ou mostrar jars adicionados no classpath no runtime.
O SQL do Flink dá suporte às seguintes instruções JAR:
- ADD JAR
- SHOW JARS
- REMOVE JAR
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
Metastore do Hive em clusters do Apache Flink® no Azure HDInsight no AKS
Os catálogos fornecem metadados, como bancos de dados, tabelas, partições, exibições e funções e informações necessárias para acessar dados armazenados em um banco de dados ou em outros sistemas externos.
No HDInsight no AKS, o Flink dá suporte a duas opções de catálogo:
GenericInMemoryCatalog
O GenericInMemoryCatalog é uma implementação na memória de um catálogo. Todos os objetos estão disponíveis apenas para o tempo de vida da sessão SQL.
HiveCatalog
O HiveCatalog atende a duas finalidades; como armazenamento persistente para metadados Flink puros e como uma interface para ler e gravar metadados do Hive existentes.
Observação
Os Azure HDInsight em clusters do AKS vêm com uma opção integrada do Metastore do Hive para o Apache Flink. Você pode optar pelo Metastore do Hive durante a criação do cluster
Como criar e registrar bancos de dados Flink em catálogos
Você pode consultar este artigo sobre como usar a CLI e começar a usar o cliente SQL do Flink por meio do Secure Shell no portal do Azure.
Iniciar sessão do
sql-client.sh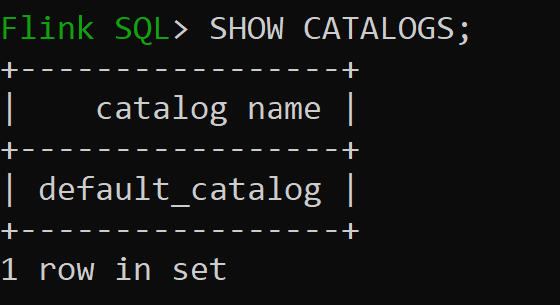
Default_catalog é o catálogo na memória padrão
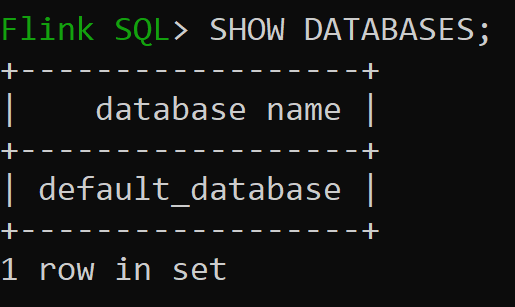
Agora, vamos verificar o banco de dados padrão do catálogo na memória
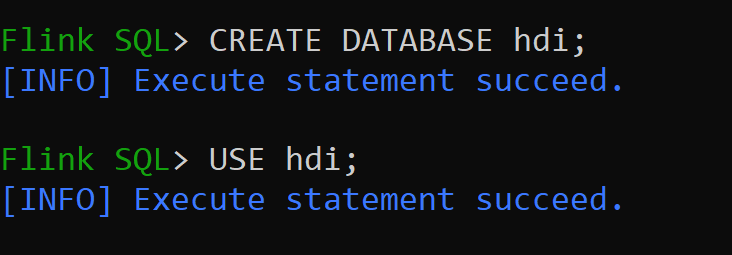
Vamos criar o Catálogo do Hive da versão 3.1.2 e usá-lo
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Observação
O Azure HDInsight no AKS dá suporte para o Hive 3.1.2 e o Hadoop 3.3.2. O
hive-conf-direstá definido como a localização/opt/hive-confVamos criar o Banco de Dados no catálogo do hive e torná-lo padrão para a sessão (a menos que alterado).
Como criar e registrar tabelas do Hive no catálogo do Hive
Siga as instruções em Como criar e registrar bancos de dados Flink em catálogos
Vamos criar a Tabela Flink do tipo de conector Hive sem partição
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');Inserir dados em uma hive_table
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';Ler dados de uma hive_table
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsObservação
O diretório do Hive Warehouse está localizado no contêiner designado da conta de armazenamento escolhida durante a criação do cluster Apache Flink, pode ser encontrado no diretório hive/warehouse/
Vamos criar a Tabela Flink do tipo de conector Hive com partição
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
Importante
Existe uma limitação conhecida no Apache Flink. As últimas ‘n’ colunas são escolhidas para partições, independentemente da coluna de partição definida pelo usuário. FLINK-32596 A chave de partição estará errada ao usar o dialeto Flink para criar a tabela Hive.
Referência
- API de Tabela do Apache Flink e SQL
- Apache, Apache Flink, Flink e nomes de projetos de código aberto associados são marcas registradas da Apache Software Foundation (ASF).
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de