O que é o Apache Spark™ no HDInsight no AKS? (Visualização)
Importante
Esse recurso está atualmente na visualização. Os Termos de uso complementares para versões prévias do Microsoft Azure incluem mais termos legais que se aplicam aos recursos do Azure que estão em versão beta, em versão prévia ou ainda não lançados em disponibilidade geral. Para obter informações sobre essa versão prévia específica, confira Informações sobre a versão prévia do Azure HDInsight no AKS. Caso tenha perguntas ou sugestões de recursos, envie uma solicitação no AskHDInsight com os detalhes e siga-nos para ver mais atualizações sobre a Comunidade do Azure HDInsight.
O Apache Spark™ é uma estrutura de processamento paralelo que dá suporte ao processamento na memória para melhorar o desempenho de aplicativos de análise de Big Data.
O Apache Spark™ oferece primitivos para computação de cluster na memória. Um trabalho do Spark pode carregar e armazenar dados em cache na memória e consultá-los várias vezes. A computação na memória é muito mais rápida do que aplicativos baseados em disco, como o Hadoop, que compartilha dados por meio do Sistema de Arquivos Distribuído do Hadoop (HDFS). O Apache Spark permite a integração com as linguagens de programação Scala e Python para permitir que você manipule conjuntos de dados distribuídos, como coleções locais. Não é necessário para estruturar tudo como operações de mapeamento e redução.
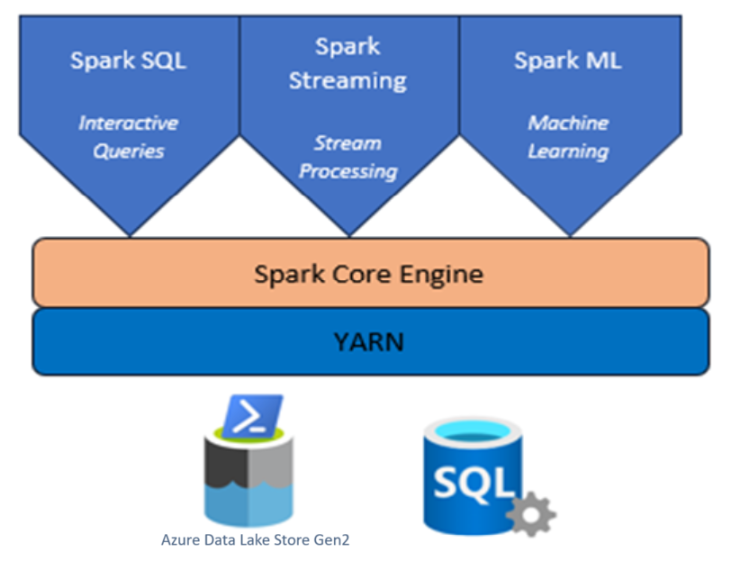
Cluster Apache Spark com HDInsight no AKS
O Azure HDInsight é um serviço de análise de software livre gerenciado e de amplo espectro para empresas.
O Apache Spark™ no Azure HDInsight no AKS é o serviço gerenciado do Spark no Microsoft Azure. Com o Apache Spark no Azure HDInsight no AKS, você pode armazenar e processar todos os seus dados no Azure. Os clusters Spark no HDInsight são compatíveis com o Azure Data Lake Storage Gen2 e permite que você aplique o processamento do Spark em seus armazenamentos de dados existentes.
A estrutura Apache Spark para HDInsight permite análises rápidas de dados e computação de cluster usando o processamento na memória. O Jupyter Notebook permite que você interaja com os seus dados, combine o código com texto Markdown e realizar visualizações simples.
Apache Spark no AKS no HDInsight composto por vários componentes, como pods.
Controladores de vários clusters
Os controladores de cluster são responsáveis por instalar e gerenciar o respectivo serviço. Vários controladores são instalados e gerenciados em um cluster Spark.
Componentes de serviço do Apache Spark
Serviço zookeeper: um cluster zookeeper de três nós, serve como coordenador distribuído ou armazenamento de alta disponibilidade para outros serviços.
Serviço Yarn: cluster do Yarn do Hadoop, os trabalhos do Spark seriam agendados no cluster como aplicativos Yarn.
Interfaces do Cliente: clusters do Apache Spark no HDInsight no AKS, fornecem várias interfaces de cliente. Livy Server, Jupyter Notebook, Spark History Server, fornece serviços Spark para o HDInsight em usuários do AKS.
Referência
- Apache, Apache Spark, Spark e nomes de projeto de software livre associados são marcas comerciais da Apache Software Foundation (ASF).
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de