Use C# com fluxo de MapReduce no Apache Hadoop no HDInsight
Saiba como usar C# para criar uma solução de MapReduce no HDInsight.
O streaming do Apache Hadoop permite executar tarefas MapReduce usando um script ou executável. Aqui, o .NET é usado para implementar o mapeador e redutor de uma solução de contagem de palavras.
.NET no HDInsight
Clusters HDInsight usam Mono (https://mono-project.com) para executar aplicativos .NET. A versão 4.2.1 do Mono está incluída no HDInsight versão 3.6. Para saber mais sobre a versão de Mono incluída com o HDInsight, confira Versão de componentes do Apache Hadoop disponíveis com o HDInsight.
Para obter mais informações sobre compatibilidade de Mono com versões do .NET Framework, consulte Compatibilidade de Mono.
Como funciona o Hadoop Streaming
O processo básico usado para streaming neste documento é o seguinte:
- O Hadoop passa dados para o mapeador (mapper.exe neste exemplo) no STDIN.
- O mapeador processa os dados e emite pares de chave/valor delimitados por tabulação para STDOUT.
- A saída é lida pelo Hadoop e, em seguida, passada para o redutor (reducer.exe neste exemplo) no STDIN.
- O redutor lê os pares de chave/valor delimitados por tabulação, processa os dados e, em seguida, emite o resultado como pares de chave/valor delimitados por tabulação no STDOUT.
- A saída é lido pelo Hadoop e gravada no diretório de saída.
Para mais informações sobre streaming, consulte Hadoop Streaming.
Pré-requisitos
Visual Studio.
Familiaridade com gravação e compilação de código em C# que se destina ao .NET Framework 4.5.
Uma forma de carregar arquivos .exe no cluster. As etapas neste documento usam o Data Lake Tools para Visual Studio para carregar os arquivos no armazenamento primário do cluster.
Se estiver usando o PowerShell, você precisará do Az Module.
Um cluster do Apache Hadoop no HDInsight. Consulte Introdução ao HDInsight no Linux.
O esquema de URI do seu armazenamento primário de clusters. Esse esquema seria
wasb://para o Armazenamento do Azure,abfs://para o Azure Data Lake Storage Gen2 ouadl://para o Azure Data Lake Storage Gen1. Se a transferência segura estiver habilitada para o Armazenamento do Azure ou para o Data Lake Storage Gen2, o URI seráwasbs://ouabfss://, respectivamente.
Criar o mapeador
No Visual Studio, crie um novo aplicativo de console .NET Framework chamado mapeador. Use o seguinte código para o aplicativo:
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
Depois de criar o aplicativo, compile-o para produzir o arquivo /bin/Debug/mapper.exe no diretório do projeto.
Criar o redutor
No Visual Studio, crie um novo aplicativo de console .NET Framework chamado redutor. Use o seguinte código para o aplicativo:
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
Depois de criar o aplicativo, compile-o para produzir o arquivo /bin/Debug/reducer.exe no diretório do projeto.
Carregar para o armazenamento
Em seguida, você precisa carregar os aplicativos de mapeador e de redutor no armazenamento do HDInsight.
No Visual Studio, selecione Exibir>Gerenciador de Servidores.
Clique com o botão direito do mouse em Azure, selecione Conectar-se à assinatura do Microsoft Azure… e conclua o processo de credenciamento.
Expanda o cluster HDInsight no qual você deseja implantar esse aplicativo. Uma entrada com o texto (Conta de armazenamento padrão) é listada.
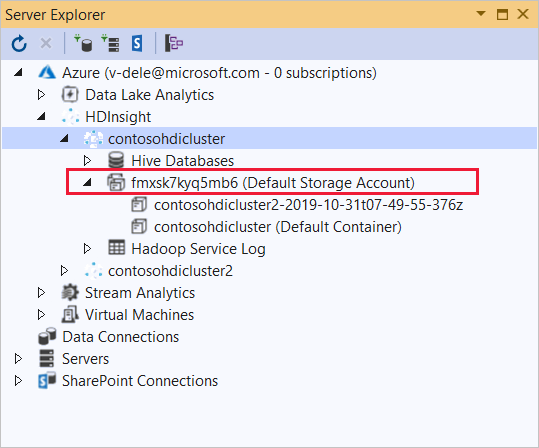
Se essa entrada (Conta de Armazenamento Padrão) puder ser expandida, você estará usando uma Conta de Armazenamento do Azure como armazenamento padrão do cluster. Para exibir os arquivos no armazenamento padrão para o cluster, expanda a entrada e clique duas vezes no (Contêiner Padrão) .
Se essa entrada (Conta de Armazenamento Padrão) puder ser expandida, você estará usando um Azure Data Lake Storage, como armazenamento padrão do cluster. Para exibir os arquivos no armazenamento padrão do cluster, clique duas vezes na entrada (Conta de Armazenamento Padrão).
Para carregar os arquivos .exe, use um dos seguintes métodos:
Se você estiver usando uma Conta de Armazenamento do Azure, selecione o ícone Carregar Blob.

Na caixa de diálogo Carregar Novo Arquivo, em Nome do arquivo, selecione Procurar. Na caixa de diálogo Carregar Blob, vá para a pasta bin\debug do projeto mapeador e escolha o arquivo mapper.exe. Por fim, selecione Abrir e, em seguida, OK para concluir o carregamento.
No Azure Data Lake Storage, clique com o botão direito do mouse em uma área vazia na listagem de arquivos e selecione Carregar. Por fim, selecione o arquivo mapper.exe e selecione Abrir.
Após o mapper.exe cser carregado, repita o processo de upload para o arquivo reducer.exe.
Executar um trabalho: usando uma sessão SSH
O procedimento a seguir descreve como executar um trabalho MapReduce usando uma sessão SSH:
Use o comando ssh para se conectar ao cluster. Edite o comando abaixo substituindo CLUSTERNAME pelo nome do cluster e, em seguida, insira o comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netUse um dos seguintes comandos para iniciar o trabalho MapReduce:
Se o armazenamento padrão for o Armazenamento do Azure:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutSe o armazenamento padrão for Data Lake Storage Gen1:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutSe o armazenamento padrão for Data Lake Storage Gen2:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
A lista a seguir descreve o que cada parâmetro e opção representa:
Parâmetro Descrição hadoop-streaming.jar Especifica o arquivo jar que contém a funcionalidade de streaming do MapReduce. -files Especifica os arquivos mapper.exe e reducer.exe para esse trabalho. A declaração de protocolo wasbs:///,adl:///ouabfs:///antes de cada arquivo é o caminho para a raiz do armazenamento padrão do cluster.-mapper Especifica o arquivo que implementa o mapeador. -reducer Especifica o arquivo que implementa o redutor. -input Especifica os dados de entrada. -output Especifica o diretório de saída. Após a conclusão do trabalho MapReduce, use o seguinte comando para exibir os resultados:
hdfs dfs -text /example/wordcountout/part-00000A seguinte lista é um exemplo dos dados retornados pelos comandos anteriores:
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
Executar um trabalho: usando o PowerShell
Use o seguinte script de PowerShell para executar um trabalho MapReduce e baixar os resultados.
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
Esse script solicita nome e senha da conta de logon do cluster, juntamente com o nome do cluster HDInsight. Depois que o trabalho é concluído, a saída é baixada em um arquivo chamado output.txt. O seguinte texto é um exemplo dos dados no arquivo output.txt:
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17