Tutorial: Usar o fluxo estruturado do Apache Spark com o Apache Kafka no HDInsight
Este tutorial demonstra como usar o fluxo estruturado do Apache Spark para ler e gravar dados com o Apache Kafka no Azure HDInsight.
O Streaming Estruturado do Spark é um mecanismo de processamento de fluxo baseado no Spark SQL. Ele permite expressar cálculos de streaming do mesmo modo que cálculos de lote em dados estáticos.
Neste tutorial, você aprenderá como:
- Usar um modelo do Azure Resource Manager para criar clusters
- Usar o Streaming Estruturado do Spark com o Kafka
Quando você concluir as etapas neste documento, lembre-se de excluir os clusters para evitar cobranças em excesso.
Pré-requisitos
jq, um processador JSON de linha de comando. Consulte https://stedolan.github.io/jq/.
Familiaridade com o uso de Jupyter Notebook com Spark no HDInsight. Para saber mais, confira o documento Carregar dados e executar consultas com o Apache Spark no HDInsight.
Familiaridade com a linguagem de programação Scala. O código usado neste tutorial é gravado em Scala.
Familiaridade com a criação de tópicos Kafka. Para saber mais, confira o documento Início rápido do Apache Kafka no HDInsight.
Importante
As etapas neste documento requerem um grupo de recursos do Azure que contém um Spark no HDInsight e um Kafka no cluster de HDInsight. Esses clusters são ambos localizados em uma Rede Virtual do Azure, que permite que o cluster Spark se comunique diretamente com o cluster Kafka.
Para sua conveniência, este documento direciona para um modelo que pode criar todos os recursos necessários do Azure.
Para obter mais informações sobre como usar o HDInsight em uma rede virtual, confira o documento Planejar uma rede virtual para o HDInsight.
Fluxo estruturado com Apache Kafka
O fluxo estruturado do Spark é um mecanismo de processamento de fluxo baseado no mecanismo SQL do Spark. Ao usar fluxo estruturado, você pode gravar consultas de fluxo da mesma maneira que você grava consultas de lote.
Os snippets de código a seguir demonstram a leitura do Kafka e o armazenamento de arquivo. A primeira é uma operação em lote, enquanto a segunda é uma operação de fluxo:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
Em ambos os snippets de código, os dados são lidos do Kafka e gravados no arquivo. As diferenças entre os exemplos são:
| Lote | Streaming |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
A operação de streaming também usa awaitTermination(30000), que interrompe o fluxo após 30.000 ms.
Para usar o fluxo estruturado com Kafka, seu projeto deve ter uma dependência no pacote org.apache.spark : spark-sql-kafka-0-10_2.11. A versão deste pacote deve corresponder à versão do Spark no HDInsight. Para o Spark 2.4 (disponível no HDInsight 4.0), você pode encontrar as informações de dependência para diferentes tipos de projeto em https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar.
Para o Jupyter Notebook usado com este tutorial, a seguinte célula carrega essa dependência de pacote:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
Criar os clusters
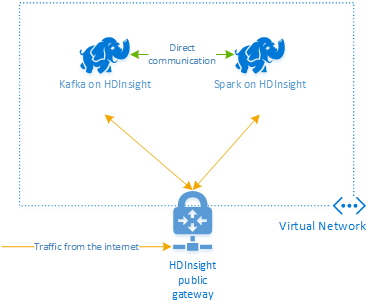
O Apache Kafka no HDInsight não fornece acesso para agentes de Kafka pela Internet pública. Qualquer coisa que usa Kafka deve estar na mesma rede virtual do Azure. Neste tutorial, os clusters de Spark e Kafka estão localizados na mesma rede virtual do Azure.
O diagrama a seguir mostra como a comunicação flui entre o Spark e o Kafka:
Observação
O serviço Kafka é limitado a comunicação dentro da rede virtual. Outros serviços no cluster, como SSH e Ambari, podem ser acessados pela Internet. Para obter mais informações sobre as portas públicas disponíveis com o HDInsight, consulte portas e URIs usados pelo HDInsight.
Para criar uma Rede Virtual do Azure e, em seguida, criar os clusters Kafka e Spark dentro dela, use as seguintes etapas:
Use o botão a seguir para entrar no Azure e abra o modelo do Gerenciador de Recursos no portal do Azure.

O modelo do Azure Resource Manager está localizado em https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json .
Este modelo cria os seguintes recursos:
Um cluster do Kafka no HDInsight 4.0 ou 5.0.
Um cluster do Spark 2.4 ou 3.1 no HDInsight 4.0 ou 5.0.
Uma Rede Virtual do Azure, que contém os clusters HDInsight.
Importante
O notebook de fluxo estruturado usado neste tutorial requer o Spark 2.4 ou 3.1 no HDInsight 4.0 ou 5.0. Se você usar uma versão anterior do Spark no HDInsight, você receberá erros ao usar o bloco de anotações.
Use as informações a seguir para preencher as entradas na seção Modelo personalizado:
Configuração Valor Subscription Sua assinatura do Azure Resource group O grupo de recursos que contém os recursos. Location A região do Azure em que os recursos são criados. Nome do cluster do Spark O nome do cluster do Spark. Os primeiro de seis caracteres devem ser diferentes do nome de cluster Kafka. Nome do cluster do Kafka O nome do cluster do Kafka. Os primeiro de seis caracteres devem ser diferentes do nome de cluster Spark. Nome de usuário de logon do cluster O nome de usuário administrador para os clusters. Senha de logon do cluster A senha de usuário administrador para os clusters. Nome de usuário do SSH O usuário do SSH para criar os clusters. Senha SSH A senha para o usuário do SSH. 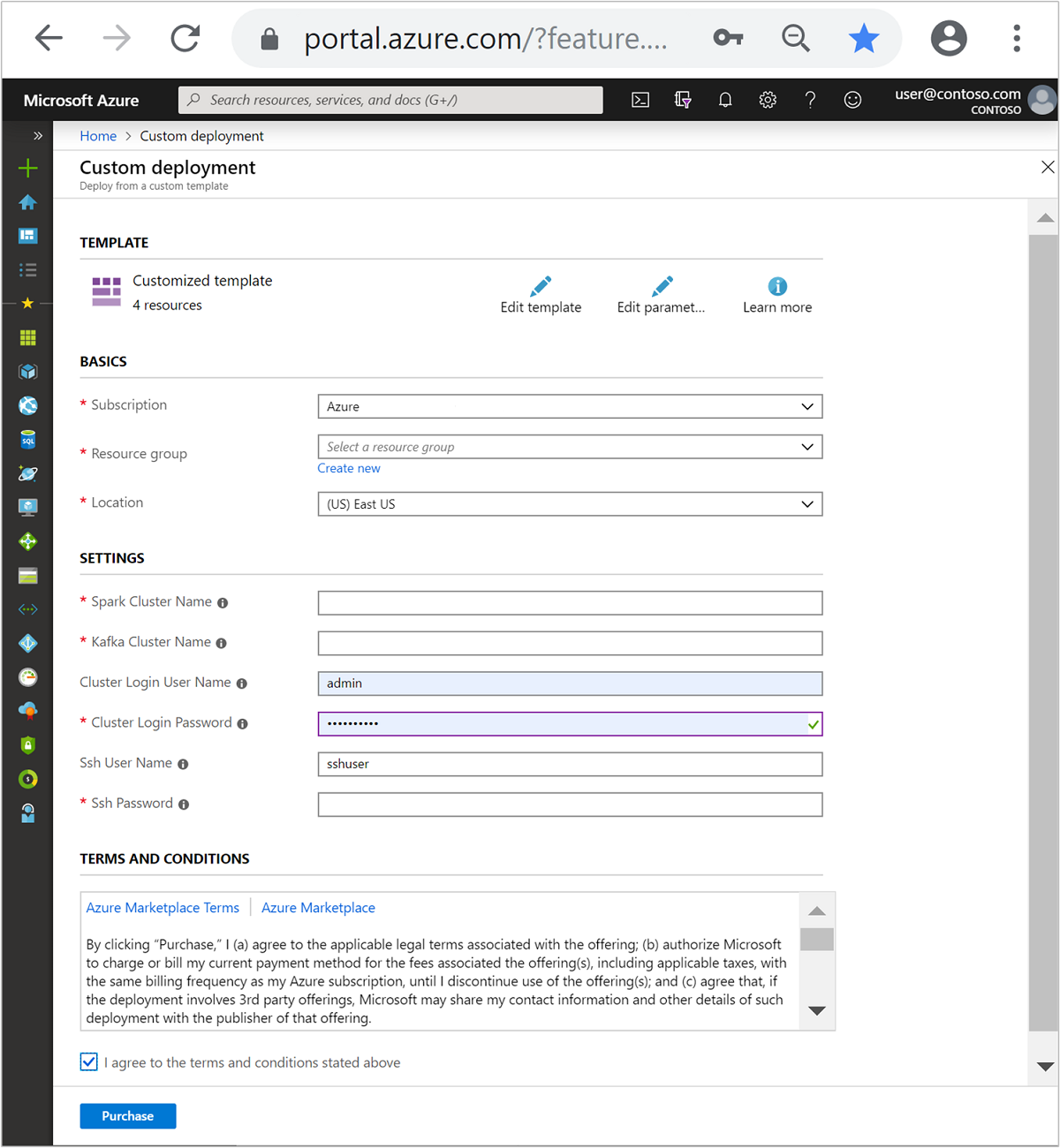
Leia os Termos e Condições e, em seguida, selecione Concordo com os termos e condições declarados acima.
Selecione Comprar.
Observação
A criação de clusters pode levar até 20 minutos.
Usar o Streaming Estruturado do Spark
Este exemplo demonstra como usar o Streaming Estruturado do Spark com o Kafka no HDInsight. Ele usa dados de corridas de táxi, que são fornecidos pela cidade de Nova York. O conjunto de dados usado por este notebook foi obtido dos Dados de Táxis Verdes de 2016.
Colete informações do host. Use os comandos do curl e do jq abaixo para obter as informações do Kafka ZooKeeper e de hosts do agente. Os comandos foram projetados para um prompt de comando do Windows; pequenas variações serão necessárias para outros ambientes. Substitua
KafkaClusterpelo nome do cluster Kafka eKafkaPasswordpela senha de logon do cluster. Além disso, substituaC:\HDI\jq-win64.exepelo caminho real da instalação do jq. Insira os comandos em um prompt de comando do Windows e salve a saída para uso em etapas posteriores.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"Em um navegador da Web, navegue até
https://CLUSTERNAME.azurehdinsight.net/jupyter, em queCLUSTERNAMEé o nome do cluster. Quando solicitado, insira o nome de usuário e senha que você inseriu ao criar o cluster.Selecione Novo > Spark para criar um notebook.
O streaming do Spark tem microenvio em lote, o que significa que os dados são recebidos como lotes e os executores são executados nos lotes de dados. Se o executor tiver um tempo limite de ociosidade menor que o tempo necessário para processar o lote, os executores serão constantemente adicionados e removidos. Se o tempo limite de ociosidade dos executores for maior que a duração do lote, o executor nunca será removido. Assim, recomendamos que você desabilite a alocação dinâmica definindo spark.dynamicAllocation.enabled como falso ao executar aplicativos de streaming.
Carregue os pacotes usados pelo Notebook inserindo as informações a seguir em uma célula do Notebook. Execute o comando usando CTRL + ENTER.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Crie o tópico do Kafka. Edite o comando abaixo substituindo
YOUR_ZOOKEEPER_HOSTSpelas informações de host do ZooKeeper extraídas na primeira etapa. Insira o comando editado no Jupyter Notebook para criar o tópicotripdata.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersRecupere os dados de corridas de táxi. Insira o comando na próxima célula para carregar os dados de corridas de táxi em Nova York. Os dados são carregados em um dataframe e, em seguida, o dataframe é exibido como a saída da célula.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Defina as informações de hosts do agente do Kafka. Substitua
YOUR_KAFKA_BROKER_HOSTSpelas informações de hosts do agente extraídas na etapa 1. Insira o comando editado na próxima célula do Jupyter Notebook.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Envie os dados para o Kafka. No comando a seguir, o campo
vendoridé usado como o valor da chave para a mensagem do Kafka. A chave é usada pelo Kafka durante o particionamento de dados. Todos os campos são armazenados na mensagem do Kafka como um valor de cadeia de caracteres JSON. Insira o comando a seguir no Jupyter para salvar os dados no Kafka usando uma consulta em lotes.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")Declare um esquema. O comando a seguir demonstra como usar um esquema durante a leitura de dados JSON do Kafka. Insira o comando na próxima célula do Jupyter.
// Import bits useed for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")Selecione dados e inicie o fluxo. O comando a seguir demonstra como recuperar dados do Kafka usando uma consulta em lote. E, em seguida, grave os resultados no HDFS no cluster do Spark. Neste exemplo, o comando
selectrecupera a mensagem (campo de valor) do Kafka e aplica o esquema a ela. Os dados são então gravados no HDFS (WASB ou ADL) no formato parquet. Insira o comando na próxima célula do Jupyter.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")Verifique se os arquivos foram criados inserindo o comando na próxima célula do Jupyter. Ele lista os arquivos no diretório
/example/batchtripdata.%%bash hdfs dfs -ls /example/batchtripdataEmbora o exemplo anterior tenha usado uma consulta em lotes, o comando a seguir demonstra como fazer a mesma coisa usando uma consulta de streaming. Insira o comando na próxima célula do Jupyter.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")Execute a célula a seguir para verificar se os arquivos foram gravados pela consulta de streaming.
%%bash hdfs dfs -ls /example/streamingtripdata
Limpar os recursos
Para limpar os recursos criados por este tutorial, você pode excluir o grupo de recursos. Excluir o grupo de recursos também exclui o cluster HDInsight associado. E quaisquer outros recursos associados ao grupo de recursos.
Para remover o grupo de recursos usando o portal do Azure:
- No portal do Azure, expanda o menu à esquerda para abrir o menu de serviços e escolha Grupo de Recursos para exibir a lista dos seus grupos de recursos.
- Localize o grupo de recursos a ser excluído e clique com o botão direito do mouse no botão Mais (...) do lado direito da lista.
- Selecione Excluir grupo de recursos e confirme.
Aviso
A cobrança do cluster HDInsight começa quando um cluster é criado e para quando o cluster é excluído. A cobrança ocorre por minuto, portanto, sempre exclua o cluster quando ele não estiver mais sendo usado.
Excluir um Kafka no cluster HDInsight exclui todos os dados armazenados no Kafka.