Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Saiba como acessar os logs de aplicativos YARN (Yet Another Resource Negotiator) do Apache Hadoop em um cluster do Apache Hadoop no Azure HDInsight.
O que é o Apache YARN?
O YARN dá suporte para vários modelos de programação (sendo o MapReduce do Apache Hadoop um deles) pela separação do gerenciamento de recursos do agendamento/do monitoramento de aplicativos. O YARN usa um ResourceManager (RM) global, NodeManagers (NMs) por nó de trabalho e ApplicationMasters (AMs) por aplicativo. O AM por aplicativo negocia os recursos (CPU, memória, disco e rede) para executar o aplicativo com o RM. O RM atua junto com os NMs para conceder esses recursos na forma de contêineres. O AM é responsável por controlar o andamento dos contêineres atribuídos pelo RM. Um aplicativo pode exigir um número de contêineres dependendo da natureza do aplicativo.
Cada aplicativo pode consistir em várias tentativas do aplicativo. Se um aplicativo falhar, ele poderá ser repetido como uma nova tentativa. Cada tentativa é executada em um contêiner. De certa forma, um contêiner dá o contexto para a unidade básica de trabalho executado por um aplicativo YARN. Todo trabalho feito no contexto de um contêiner é executado no nó de trabalho único no qual o contêiner foi alocado. Confira Hadoop: escrevendo aplicativos YARN ou Apache Hadoop YARN para referência.
Para escalar o cluster para aumentar a taxa de transferência de processamento, você pode usar o dimensionamento automático ou dimensionar os clusters manualmente usando algumas linguagens diferentes.
Servidor de Linha do Tempo do YARN
O Servidor de Linha de Tempo do YARN do Apache Hadoop fornece informações genéricas sobre os aplicativos concluídos
O Servidor de Linha de Tempo do YARN inclui o seguinte tipo de dados:
- A ID do aplicativo, um identificador exclusivo de um aplicativo
- O usuário que iniciou o aplicativo
- Informações sobre as tentativas feitas para concluir o aplicativo
- Os contêineres usados por uma tentativa de aplicativo específica
Aplicativos e logs do YARN
Os logs de aplicativos (e os logs de contêiner associados) são essenciais na depuração de aplicativos problemáticos do Hadoop. O YARN fornece uma ótima estrutura para coletar, agregar e armazenar logs de aplicativos com a agregação de logs.
O recurso de agregação de logs permite acessar os logs de aplicativos de maneira mais determinística. Ele agrega os logs em todos os contêineres em um só de trabalho e as armazena como um arquivo de log agregado por nó de trabalho. O log é armazenado no sistema de arquivos padrão após a conclusão de um aplicativo. O aplicativo pode usar centenas ou milhares de contêineres, mas os logs para todos os contêineres executados em um só nó de trabalho sempre são agregados a um arquivo individual. Portanto, há apenas um log por nó de trabalho usado pelo aplicativo. A agregação de log é habilitada por padrão em clusters do HDInsight versão 3.0 e superior. Os logs agregados estão localizados no armazenamento padrão do cluster. O seguinte caminho é o caminho do HDFS para os logs:
/app-logs/<user>/logs/<applicationId>
No caminho, user é o nome do usuário que iniciou o aplicativo. O applicationId é o identificador exclusivo atribuído a um aplicativo pelo RM do YARN.
Os logs agregados não podem ser lidos diretamente, pois são escritos em um TFile, formato binário indexado por contêiner. Use as ferramentas dos logs ResourceManager do YARN ou da CLI para exibir os logs dos aplicativos ou contêineres de interesse como texto sem formatação.
Logs do Yarn em um cluster ESP
Duas configurações devem ser adicionadas ao mapred-site personalizado no Ambari.
Em um navegador da Web, navegue até
https://CLUSTERNAME.azurehdinsight.net, em queCLUSTERNAMEé o nome do cluster.Na IU do Ambari, acesse MapReduce2>Configurações> Avançadas>Site mapred personalizado.
Adicione um dos seguintes conjuntos de propriedades:
Conjunto 1
mapred.acls.enabled=true mapreduce.job.acl-view-job=*Conjunto 2
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>Salve as alterações e reinicie todos os serviços afetados.
Ferramentas da CLI do YARN
Use o comando ssh para se conectar ao cluster. Edite o seguinte comando substituindo CLUSTERNAME pelo nome do cluster e insira o comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netListe todas as IDs de aplicativo dos aplicativos YARN em execução no momento com o seguinte comando:
yarn topObserve a ID do aplicativo na coluna
APPLICATIONID, cujos logs devem ser baixados.YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerÉ possível exibir esses logs como texto sem formatação executando um dos seguintes comandos:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>Especifique as informações <applicationId>, <user-who-started-the-application>,<containerId> e <worker-node-address> ao executar esses comandos.
Outros exemplos de comandos
Baixe os logs dos contêineres do YARN para todos os mestres de aplicativos com o comando a seguir. Essa etapa cria o arquivo de log chamado
amlogs.txtem formato de texto.yarn logs -applicationId <application_id> -am ALL > amlogs.txtBaixe os logs do contêiner do YARN apenas para o mestre aplicativo mais recente com o seguinte comando:
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txtBaixe os logs do contêiner do YARN para os dois primeiros mestres de aplicativo com o seguinte comando:
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtBaixe todos os logs do contêiner do YARN com o seguinte comando:
yarn logs -applicationId <application_id> > logs.txtBaixe o log do contêiner do YARN para um contêiner específico com o seguinte comando:
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
IU ResourceManager do YARN
A IU ResourceManager do YARN é executada no nó de cabeçalho do cluster. Ele é acessado por meio da interface do usuário da Web do Ambari. Realize as seguintes etapas para exibir os logs do YARN:
No navegador da Web, navegue até
https://CLUSTERNAME.azurehdinsight.net. Substitua CLUSTERNAME pelo nome do cluster HDInsight.Na lista de serviços à esquerda, selecione YARN.
Na lista suspensa Links Rápidos, selecione um dos nós principais do cluster e selecione
ResourceManager Log.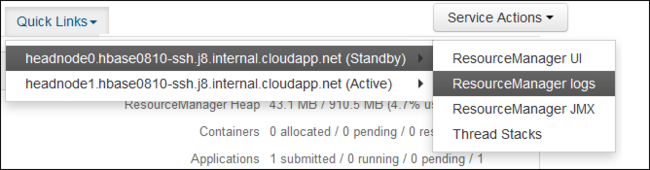
Você verá uma lista de links para os logs do YARN.