Solucione problemas de YARN do Apache Hadoop usando o Azure HDInsight
Saiba mais sobre os principais problemas e suas soluções ao trabalhar com cargas de Apache Hadoop YARN no Apache Ambari.
Como fazer para criar uma nova fila do YARN em um cluster?
Etapas de resolução
Use as etapas a seguir por meio do Ambari para criar uma nova fila do YARN e equilibrar a alocação de capacidade entre todas as filas.
Neste exemplo, duas filas existentes (padrão e thriftsvr) são alteradas de 50% da capacidade para 25% da capacidade, o que oferece a nova capacidade de fila de 50% (spark).
| Fila | Capacity | Capacidade máxima |
|---|---|---|
| padrão | 25% | 50% |
| thrftsvr | 25% | 50% |
| spark | 50% | 50% |
Selecione o ícone Exibições do Ambari e então selecione o padrão de grade. Em seguida, selecione Gerenciador de Filas do YARN.
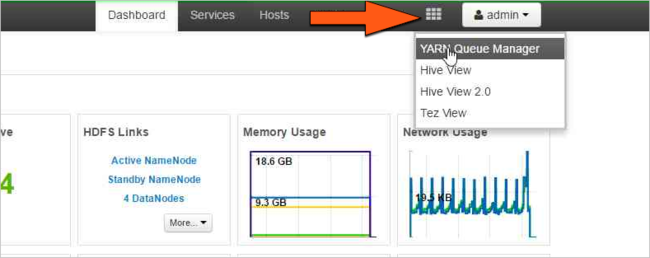
Selecione a fila padrão.
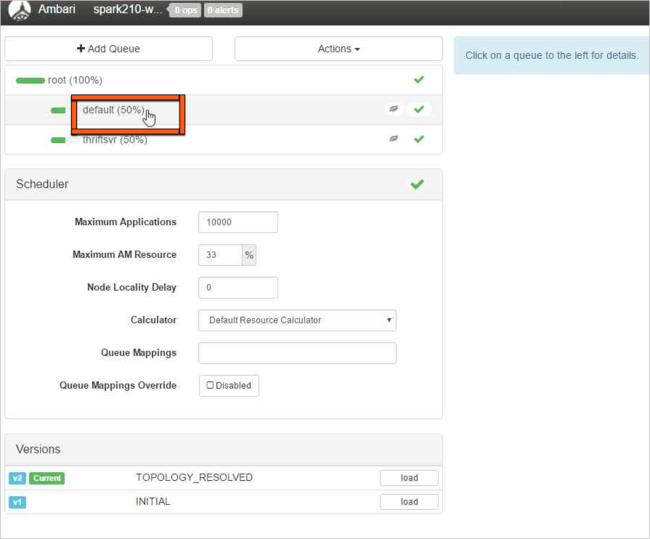
Para a fila padrão , altere a capacidade de 50% para 25%. Para a fila thriftsvr, altere a capacidade para 25%.
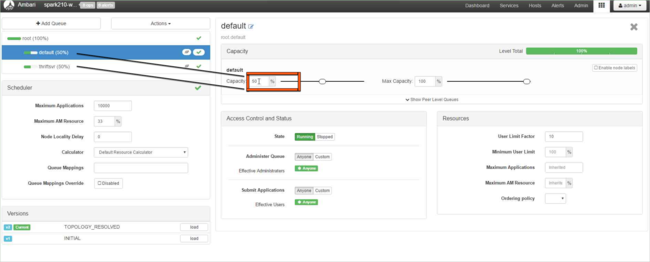
Para criar uma nova fila, selecione Adicionar Fila.
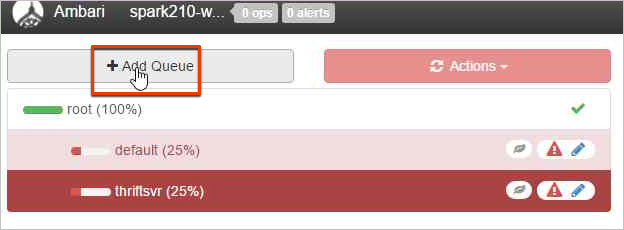
Dê um nome à nova fila.
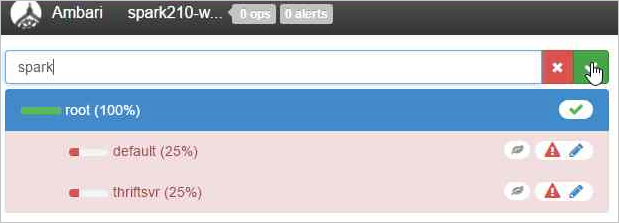
Deixe os valores de capacidade em 50% e então selecione o botão Ações.
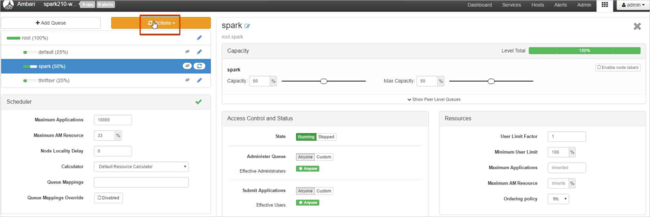
Escolha Salvar e Atualizar Filas.
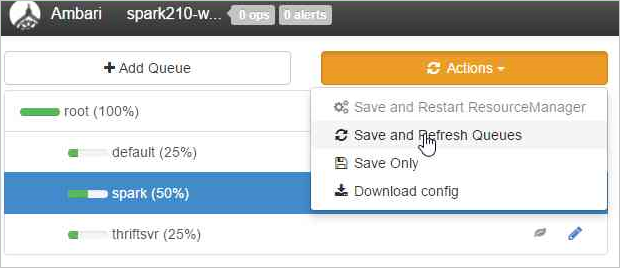
Essas alterações estarão visíveis imediatamente na interface do usuário do Agendador do YARN.
Leitura adicional
Como fazer para baixar logs do YARN de um cluster?
Etapas de resolução
Conecte-se ao cluster HDInsight com um cliente SSH (Secure Shell). Para saber mais, confira Leitura adicional.
Para listar todas as IDs de aplicativo dos aplicativos YARN em execução no momento, execute este comando:
yarn topAs IDs são listadas na coluna APPLICATIONID. Você pode baixar os logs da coluna APPLICATIONID.
YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerPara baixar os logs de contêineres do YARN para todos os mestres de aplicativo, use este comando:
yarn logs -applicationIdn logs -applicationId <application_id> -am ALL > amlogs.txtEste comando cria um arquivo de log chamado amlogs.txt.
Para baixar os logs do contêiner do YARN somente para o aplicativo mestre mais recente, use este comando:
yarn logs -applicationIdn logs -applicationId <application_id> -am -1 > latestamlogs.txtEste comando cria um arquivo de log chamado latestamlogs.txt.
Para baixar os logs do contêiner do YARN para os dois primeiros mestres de aplicativo, use este comando:
yarn logs -applicationIdn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtEste comando cria um arquivo de log chamado first2amlogs.txt.
Para baixar todos os logs do contêiner do YARN, use este comando:
yarn logs -applicationIdn logs -applicationId <application_id> > logs.txtEste comando cria um arquivo de log chamado logs.txt.
Para baixar o log do contêiner YARN para um contêiner específico, use o seguinte comando:
yarn logs -applicationIdn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txtEste comando cria um arquivo de log chamado containerlogs.txt.
Leituras adicionais
Como faço para verificar as Informações de Diagnóstico de Aplicativos do Yarn?
O diagnóstico na interface do usuário do Yarn é um recurso que permite exibir os status e logs de seus aplicativos em execução no Yarn. O diagnóstico pode ajudá-lo a solucionar problemas e depurar seus aplicativos, bem como monitorar o desempenho e o uso de recursos.
Para exibir o diagnóstico de um aplicativo específico, clique na ID do aplicativo na lista de aplicativos. Na página de detalhes do aplicativo, você também pode ver uma lista de todas as tentativas que foram feitas para executar o aplicativo. Você pode clicar em qualquer tentativa para ver mais detalhes, como a ID da tentativa, a ID do contêiner, a ID do nó, a hora de início, a hora de término e diagnóstico
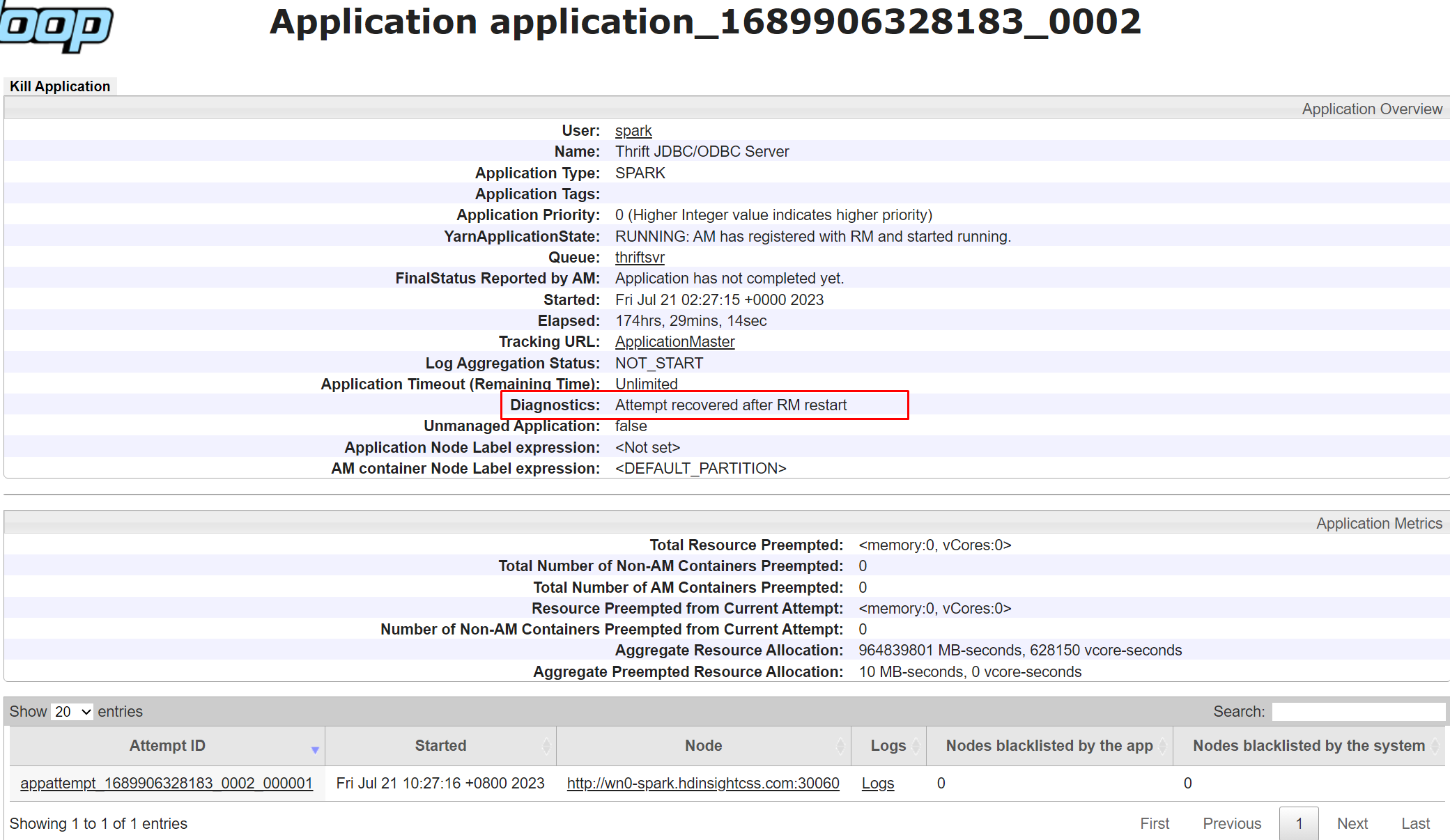
Como fazer para solucionar problemas comuns do YARN?
A IU do Yarn não está carregando
Se a interface do usuário do YARN não estiver sendo carregada ou se não estiver acessível e retornar o "Erro HTTP 502.3 – Gateway Incorreto", isso indica que o serviço do Resource Manager não está íntegro. Para atenuar o problema, siga estas etapas:
- Acesse Interface do Usuário do Ambari>YARN>RESUMO e verifique se apenas o Resource Manager ativo está no estado Iniciado. Caso contrário, tente atenuar o problema reiniciando o Resource Manager não íntegro ou interrompido.
- Se a etapa 1 não resolver o problema, execute o SSH no nó de cabeçalho do Resource Manager ativo e verifique o status da coleta de lixo usando
jstat -gcutil <Resource Manager pid> 1000 100. Se você observar que o FGCT aumentou consideravelmente em apenas alguns segundos, isso indicará que o Resource Manager está ocupado na Coleta de Lixo Completa e não pode processar as outras solicitações. - Acesse Interface do Usuário do Ambari>YARN>CONFIGS>Avançado e aumente
Resource Manager java heap size. - Reinicie os serviços necessários na interface do usuário do Ambari.
Os dois gerenciadores de recursos ficam em espera
- Verifique o log do Resource Manager para ver se há um erro semelhante.
Service RMActiveServices failed in state STARTED; cause: org.apache.hadoop.service.ServiceStateException: com.google.protobuf.InvalidProtocolBufferException: Could not obtain block: BP-452067264-10.0.0.16-1608006815288:blk_1074235266_494491 file=/yarn/node-labels/nodelabel.mirror
Se o erro existir, verifique se alguns arquivos estão em replicação ou se há blocos ausentes no HDFS. Você pode executar
hdfs fsck hdfs://mycluster/Execute
hdfs fsck hdfs://mycluster/ -deletepara forçar a limpeza do HDFS e eliminar o problema do RM em espera. Como alternativa, execute PatchYarnNodeLabel em um dos nós de cabeçalho para corrigir o cluster.
Próximas etapas
Se você não encontrou seu problema ou não conseguiu resolver seu problema, visite um dos seguintes canais para obter mais suporte:
Obtenha respostas de especialistas do Azure por meio do Suporte da Comunidade do Azure.
Conecte-se com @AzureSupport – a conta oficial do Microsoft Azure para aprimorar a experiência do cliente. Como se conectar à comunidade do Azure para os recursos certos: respostas, suporte e especialistas.
Se precisar de mais ajuda, poderá enviar uma solicitação de suporte do portal do Azure. Selecione Suporte na barra de menus ou abra o hub Ajuda + suporte. Para obter informações mais detalhadas, consulte Como criar uma solicitação de Suporte do Azure. O acesso ao Gerenciamento de assinaturas e ao suporte de cobrança está incluído na sua assinatura do Microsoft Azure, e o suporte técnico é fornecido por meio de um dos Planos de suporte do Azure.