Use o Apache Spark MLlib para criar um aplicativo de aprendizado de máquina e analisar um conjunto de dados
Saiba como usar o Apache Spark MLlib para criar um aplicativo de aprendizado de máquina. O aplicativo faz análise preditiva em um conjunto de dados aberto. Das bibliotecas aprendizado de máquina internas do Spark, este exemplo usa classificação por meio de regressão logística.
MLlib é uma biblioteca Spark principal que fornece vários utilitários úteis para tarefas de aprendizado de máquina, incluindo:
- classificação
- Regressão
- Clustering
- Modelagem
- Decomposição de valor singular (SVD) e análise de componente principal (PCA)
- Teste de hipótese e cálculo de estatísticas de exemplo
Compreender a classificação e regressão logística
Classificação, uma tarefa popular de aprendizado de máquina, é o processo de classificação de dados de entrada em categorias. Um algoritmo de classificação é responsável por descobrir como atribuir “rótulos” a dados de entrada que você fornece. Por exemplo, imagine um algoritmo de aprendizado de máquina que aceite informações sobre estoque como entrada. Depois, ele divide o estoque em duas categorias: o estoque que você deve vender e o estoque que deve ser mantido.
Regressão logística é o algoritmo usado para classificação. A API de regressão logística do Spark é útil para classificação bináriaou para classificação de dados de entrada em um dos dois grupos. Para obter mais informações sobre a regressão logística, consulte Wikipédia.
Resumindo, o processo de regressão logística produz uma função logística. Use a função para prever a probabilidade de um vetor de entrada pertencer a um grupo ou outro.
Exemplo de análise preditiva dos dados de inspeção de alimentos
Neste exemplo, você usa o Spark para executar uma análise preditiva sobre os dados de inspeção de alimentos (Food_Inspections1.csv). Dados adquiridos por meio do portal de dados da cidade de Chicago. Esse conjunto de dados contém informações sobre inspeções de estabelecimentos de alimentos realizadas em Chicago. Incluindo informações sobre cada estabelecimento de alimentos inspecionado, as violações encontradas (se houver) e os resultados da inspeção. O arquivo de dados CSV já está disponível na conta de armazenamento associada ao cluster em /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv.
Nas etapas a seguir, você desenvolve um modelo para ver o que é preciso para passar ou falhar em uma inspeção de alimentos.
Crie um aplicativo de aprendizado de máquina Apache Spark MLlib
Crie um Jupyter Notebook usando o kernel do PySpark. Para obter as instruções, confira Criar um arquivo do Jupyter Notebook.
Importe os tipos obrigatórios necessários para este aplicativo. Copie e cole o código a seguir em uma célula vazia e pressione SHIFT + ENTER.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *Por causa do kernel do PySpark, não será necessário criar nenhum contexto explicitamente. Os contextos do Spark e do Hive são criados automaticamente quando você executa a primeira célula do código.
Construir o dataframe de entrada
Use o contexto do Spark para efetuar pull dos dados brutos CSV na memória como texto não estruturado. Em seguida, use a biblioteca CSV do Python para analisar cada linha dos dados.
Execute as seguintes linhas para criar um RDD (Conjunto de Dados distribuídos resiliente), importando e analisando os dados de entrada.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Execute o seguinte código para recuperar uma linha de RDD, portanto você pode dar uma olhada do esquema de dados:
inspections.take(1)A saída é:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]A saída anterior lhe dá uma ideia do esquema do arquivo de entrada. Ele inclui o nome de cada estabelecimento e o tipo de estabelecimento. Ele inclui também o endereço, os dados da inspeção e a localização, entre outras informações.
Execute o seguinte código para criar um dataframe (df) e uma tabela temporária (CountResults) com algumas colunas que são úteis para a análise de previsão.
sqlContexté usado para executar transformações em dados estruturados.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')As quatro colunas de interesse no dataframe são ID, nome, resultados e violações.
Execute o código a seguir para obter uma pequena amostra dos dados:
df.show(5)A saída é:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
Entender os dados
Vamos começar a ter uma ideia do que o nosso conjunto de dados contém.
Execute o seguinte código para mostrar os valores distintos na coluna resultados:
df.select('results').distinct().show()A saída é:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Execute o seguinte código para visualizar a distribuição desses resultados:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsA mágica do
%%sqlseguido pelo-o countResultsdfassegura que a saída da consulta seja mantida localmente no servidor Jupyter (normalmente o nó principal do cluster). A saída é mantida como uma estrutura de dados Pandas com o nome especificado countResultsdf. Para obter mais informações sobre a mágica%%sqle outras mágicas disponíveis com o kernel do PySpark, veja Kernels disponíveis em Jupyter Notebooks com clusters do Apache Spark HDInsight.A saída é:
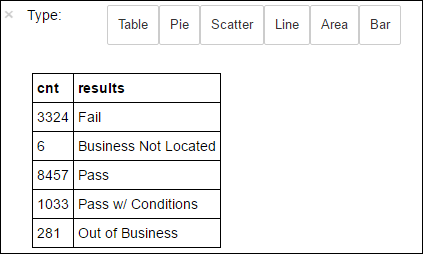
Você também pode usar Matplotlib, uma biblioteca usada para construir a visualização de dados para criar um gráfico. Como o gráfico deve ser criado a partir do dataframe countResultsdf mantido localmente, o snippet de código deve começar com a mágica
%%local. Essa ação garante que o código seja executado localmente no servidor do Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Para prever um resultado de inspeção de alimentos, você precisa desenvolver um modelo com base nas violações. Como a regressão logística é um método de classificação binária, faz sentido agrupar os dados de resultado em duas categorias: Reprovado e Aprovado:
Aprovado
- Aprovado
- Aprovado c/ condições
Falha
- Falha
Descartar
- Negócios não localizados
- Fora de negócio
Dados com os outros resultados (“Negócios não localizados” ou “Fora de negócio”) não são úteis, e formam uma porcentagem bem pequena dos resultados de qualquer maneira.
Execute o código a seguir para converter nosso dataframe existente (
df) em um novo dataframe em que cada inspeção é representada como um par de violações de rótulo. Nesse caso, um rótulo de0.0representa uma falha, um rótulo de1.0representa um sucesso e um rótulo de-1.0representa alguns resultados diferentes desses dois.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Execute o seguinte código para mostrar uma linha de dados rotulados:
labeledData.take(1)A saída é:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Criar um modelo de regressão logística do dataframe de entrada
A tarefa final é converter os dados rotulados. Converta os dados em um formato analisado por regressão logística. A entrada em um algoritmo de regressão logística precisa ser um conjunto de pares de vetor de recurso de rótulo. Em que o “vetor de recurso” é um vetor de números que representa o ponto de entrada. Portanto, você precisa converter a coluna “violações”, que é semiestruturada e contém vários comentários em texto livre. Converta a coluna para uma matriz de números reais que um computador entenderia facilmente.
Uma abordagem de aprendizado de máquina padrão para processar linguagem natural é atribuir um índice a cada palavra distinta. Depois, passe um vetor para o algoritmo de aprendizado de máquina. Faça isso de modo que o valor de cada índice contenha a frequência relativa dessa palavra na cadeia de texto.
A MLlib proporciona uma forma fácil de executar essa operação. Primeiro, crie tokens de cada cadeia de caracteres de violações para obter as palavras individuais em cada cadeia de caracteres. Em seguida, use um HashingTF para converter cada conjunto de tokens em um vetor de recurso que pode ser passado para o algoritmo de regressão logística para construir um modelo. Você realiza todas essas etapas em sequência usando um pipeline.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Avaliar o modelo usando outro conjunto de dados
Você pode usar o modelo criado anteriormente para prever os resultados de novas inspeções. As previsões são baseadas nas violações que foram observadas. Você treinou esse modelo no conjunto de dados Food_Inspections1.csv. Você pode usar um segundo conjunto de dados, Food_Inspections2.csv, para avaliar a força deste modelo nos dados novos. Esse segundo conjunto de dados (Food_Inspections2.csv) está no contêiner de armazenamento padrão associado ao cluster.
Execute o código a seguir para criar um novo dataframe, predictionsDf que contém a previsão gerada pelo modelo. O snippet de código também cria uma tabela temporária Previsões com base no dataframe.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsVocê deverá ver uma saída como o seguinte texto:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Examine uma das previsões. Execute este snippet de código:
predictionsDf.take(1)Há uma previsão para a primeira entrada no conjunto de dados de teste.
O método
model.transform()aplica a mesma transformação para novos dados com o mesmo esquema e chega a uma previsão de como classificar os dados. Você pode realizar algumas estatísticas simples para ter uma ideia de quão precisas foram as previsões:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")A saída se parece com o seguinte texto:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateO uso da regressão logística com o Spark fornece um modelo preciso da relação entre as descrições de violações em inglês. E se um determinado negócio seria aprovado ou reprovado uma inspeção de alimentos.
Criar uma representação visual da previsão
Agora você pode construir uma visualização final para ajudar a justificar os resultados deste teste.
Você começa extraindo as diferentes previsões e os resultados da tabela temporária Predictions criada anteriormente. As consultas a seguir separam a saída como true_positive, false_positive, true_negative e false_negative. Nas consultas a seguir, você vai desligar as visualização usando
-qe também salvar a saída (usando-o) como quadros de dados que podem ser usados com a mágica%%local.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Por fim, use o snippet de código a seguir para gerar o gráfico usando o Matplotlib.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')A seguinte saída deve ser exibida:
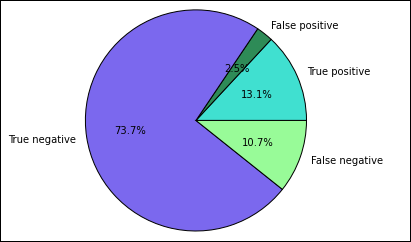
Neste gráfico, um resultado "positivo" refere-se a uma reprovação na inspeção de alimentos, enquanto um resultado negativo refere-se a uma aprovação na inspeção.
Fechar o notebook
Depois de executar o aplicativo, você deve desligar o notebook para liberar os recursos. Para fazer isso, no menu Arquivo do notebook, selecione Fechar e Interromper. Essa ação desliga e fecha o bloco de anotações.