Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O HDInsight tem duas instalações internas do Python no cluster do Spark, Anaconda Python 2.7 e Python 3.5. Os clientes talvez precisem personalizar o ambiente do Python, como instalar pacotes externos do Python. Aqui, mostramos a melhor prática de gerenciamento seguro de ambientes do Python para clusters Apache Spark no HDInsight.
Pré-requisitos
Um cluster do Apache Spark no HDInsight. Para obter instruções, consulte o artigo sobre como Criar clusters do Apache Spark no Azure HDInsight. Se você ainda não tiver um cluster Spark no HDInsight, poderá executar ações de script durante a criação do cluster. Acesse a documentação em como usar ações de script personalizadas.
Suporte para software livre utilizado em clusters do HDInsight
O serviço Microsoft Azure HDInsight usa um ambiente de tecnologias de software livre construído em torno do Apache Hadoop. O Microsoft Azure fornece um nível geral de suporte para tecnologias de software livre. Para obter mais informações, confira o site de perguntas frequentes do Suporte do Azure. O serviço HDInsight fornece um nível adicional de suporte a componentes internos.
Há dois tipos de componentes de software livre disponíveis no serviço HDInsight:
| Componente | Descrição |
|---|---|
| Interno | Esses componentes estão pré-instalados em clusters do HDInsight e fornecem os recursos básicos do cluster. Por exemplo, o Apache Hadoop YARN Resource Manager, a linguagem de consulta do Apache Hive (HiveQL) e a biblioteca do Mahout pertencem a essa categoria. Uma lista completa de componentes de cluster está disponível em O que há de novo nas versões de cluster do Apache Hadoop fornecidas pelo HDInsight. |
| Personalizado | Você, como usuário do cluster, pode instalar ou usar em sua carga de trabalho qualquer componente disponível na comunidade ou criado por você. |
Importante
Componentes fornecidos com o cluster HDInsight contam com suporte total. O Suporte da Microsoft ajuda a isolar e resolver problemas relacionados a esses componentes.
Componentes personalizados recebem suporte comercialmente razoável para ajudá-lo a solucionar o problema. O suporte da Microsoft pode estar apto a resolver o problema OU pode solicitar que você contate canais disponíveis para as tecnologias de software livre em que é encontrado conhecimento profundo sobre essa tecnologia. Por exemplo, existem muitos sites da comunidade que podem ser usados, como a Página de perguntas do Microsoft Q&A para o HDInsight, https://stackoverflow.com. Além disso, os projetos Apache têm sites de projeto em https://apache.org.
Entender a instalação padrão do Python
Os clusters do Spark do HDInsight têm o Anaconda instalado. Há duas instalações do Python no cluster: Anaconda Python 2.7 e Python 3.5. A tabela a seguir mostra as configurações padrão do Python para Spark, Livy e Jupyter.
| Configuração | Python 2,7 | Python 3.5 |
|---|---|---|
| Caminho | /usr/bin/anaconda/bin | /usr/bin/anaconda/envs/py35/bin |
| Versão do Spark | Padrão definido como 2.7 | Pode alterar a configuração para 3.5 |
| Versão do Livy | Padrão definido como 2.7 | Pode alterar a configuração para 3.5 |
| Jupyter | Kernel do PySpark | Kernel do PySpark3 |
Para a versão 3.1.2 do Spark, o kernel do Apache PySpark é removido e um novo ambiente do Python 3.8 é instalado em /usr/bin/miniforge/envs/py38/bin, que é usado pelo kernel do PySpark3. As variáveis de ambiente PYSPARK_PYTHON e PYSPARK3_PYTHON são atualizadas com o seguinte:
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
export PYSPARK3_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
Instalar com segurança pacotes externos do Python
O cluster do HDInsight depende do ambiente interno do Python, tanto Python 2.7 quanto Python 3.5. A instalação direta de pacotes personalizados nesses ambientes internos padrão pode causar alterações inesperadas na versão da biblioteca. Além disso, pode dividir ainda mais o cluster. Para instalar pacotes externos do Python personalizados para os seus aplicativos Spark com segurança, siga as etapas.
Crie um ambiente virtual do Python usando o Conda. Um ambiente virtual fornece um espaço isolado para seus projetos sem dividir outros. Ao criar o ambiente virtual do Python, você pode especificar a versão do Python que deseja usar. Você ainda precisa criar um ambiente virtual, mesmo que queira usar Python 2.7 e 3.5. Esse requisito é para garantir que o ambiente padrão do cluster não está sendo dividido. Execute ações de script no seu cluster para todos os nós com o script a seguir para criar um ambiente virtual do Python.
--prefixespecifica um caminho em que um ambiente virtual Conda reside. Há várias configurações que precisam ser alteradas com base no caminho especificado aqui. Neste exemplo, usamos o py35new, pois o cluster já tem um ambiente virtual existente chamado py35.python=especifica a versão do Python para o ambiente virtual. Neste exemplo, usamos a versão 3.5, a mesma versão do cluster interno. Você também pode usar outras versões do Python para criar o ambiente virtual.anacondaespecifica o package_spec como Anaconda para instalar os pacotes do Anaconda no ambiente virtual.
sudo /usr/bin/anaconda/bin/conda create --prefix /usr/bin/anaconda/envs/py35new python=3.5 anaconda=4.3 --yesInstale pacotes externos do Python no ambiente virtual criado, se necessário. Execute ações de script no seu cluster para todos os nós com o script a seguir para instalar pacotes externos do Python. Aqui, você precisa ter privilégio de acesso no sudo para gravar arquivos na pasta do ambiente virtual.
Pesquise o índice do pacote para obter uma lista completa de pacotes disponíveis. Você também pode obter uma lista de pacotes disponíveis de outras fontes. Por exemplo, você pode instalar pacotes disponibilizados por meio conda-forge.
Use o comando a seguir se quiser instalar uma biblioteca com sua versão mais recente:
Use o canal do conda:
seaborné o nome do pacote que você deseja instalar.-n py35newespecifica o nome do ambiente virtual que foi criado. Não se esqueça de alterar o nome de forma correspondente, com base na criação do ambiente virtual.
sudo /usr/bin/anaconda/bin/conda install seaborn -n py35new --yesOu use o repositório PyPi e altere
seabornepy35newde forma correspondente:sudo /usr/bin/anaconda/envs/py35new/bin/pip install seaborn
Use o seguinte comando caso queira instalar uma biblioteca com uma versão específica:
Use o canal do conda:
numpy=1.16.1é o nome do pacote e a versão que você deseja instalar.-n py35newespecifica o nome do ambiente virtual que foi criado. Não se esqueça de alterar o nome de forma correspondente, com base na criação do ambiente virtual.
sudo /usr/bin/anaconda/bin/conda install numpy=1.16.1 -n py35new --yesOu use o repositório PyPi e altere
numpy==1.16.1epy35newde forma correspondente:sudo /usr/bin/anaconda/envs/py35new/bin/pip install numpy==1.16.1
Se você não souber o nome do ambiente virtual, use SSH no nó principal do cluster e execute
/usr/bin/anaconda/bin/conda info -epara mostrar todos os ambientes virtuais.Altere as configurações do Spark e do Livy e aponte para o ambiente virtual criado.
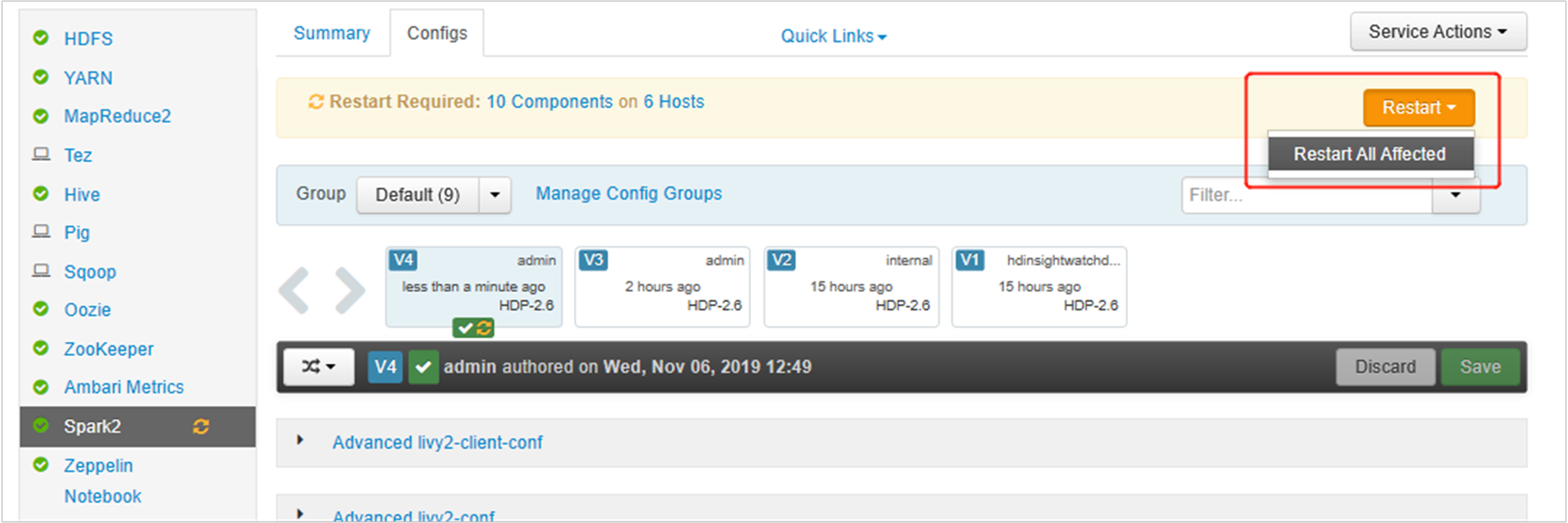
Abra a Interface do Usuário do Ambari e vá para a página do Spark 2, guia de Configurações.
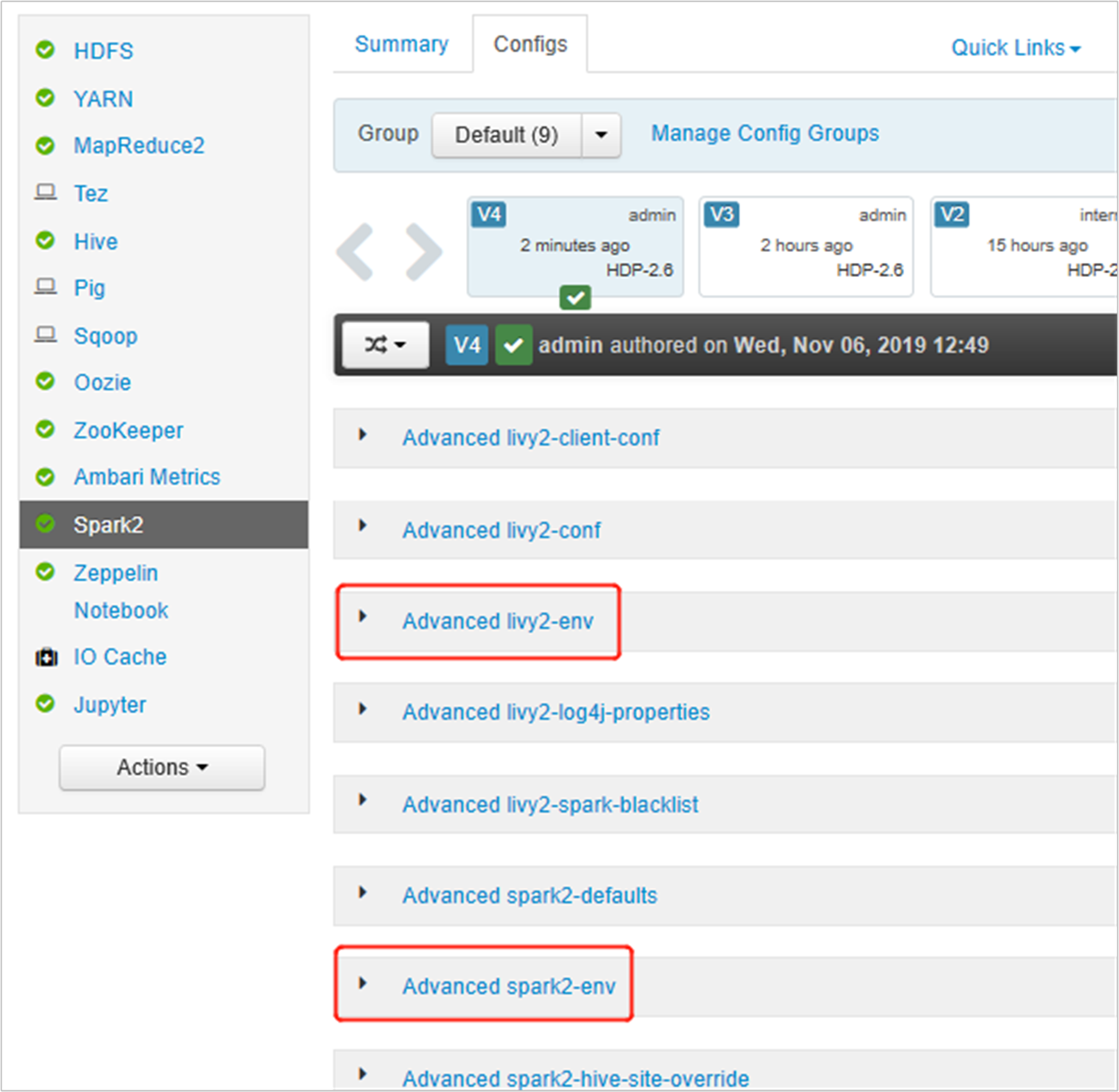
Expanda "Advanced livy2-env" e adicione as instruções a seguir na parte de baixo. Se você instalou o ambiente virtual com um prefixo diferente, altere o caminho analogamente.
export PYSPARK_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python export PYSPARK_DRIVER_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python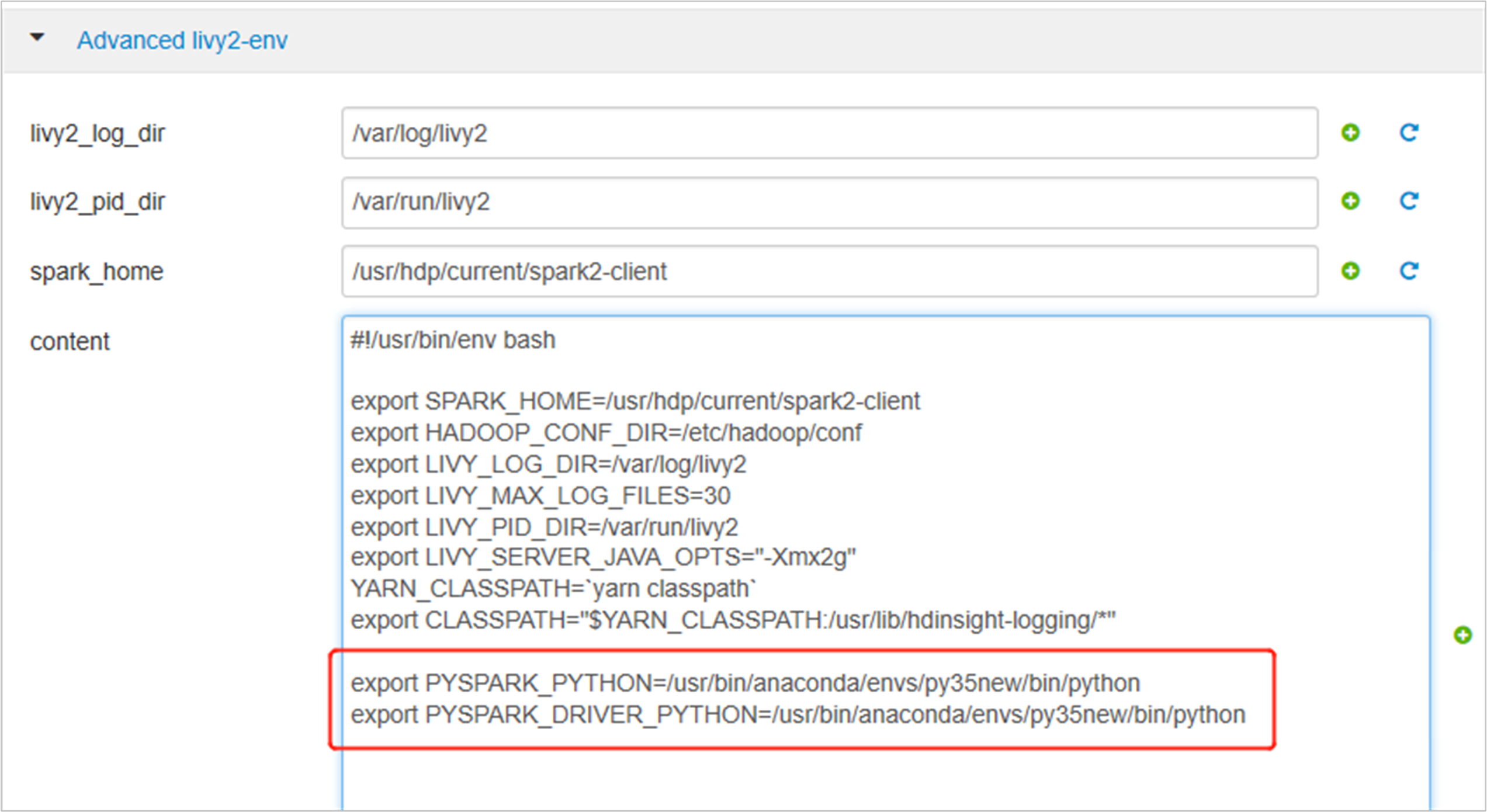
Expanda Spark2-env avançado, substitua a instrução exportação PYSPARK_PYTHON existente, na parte inferior. Se você instalou o ambiente virtual com um prefixo diferente, altere o caminho analogamente.
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/anaconda/envs/py35new/bin/python}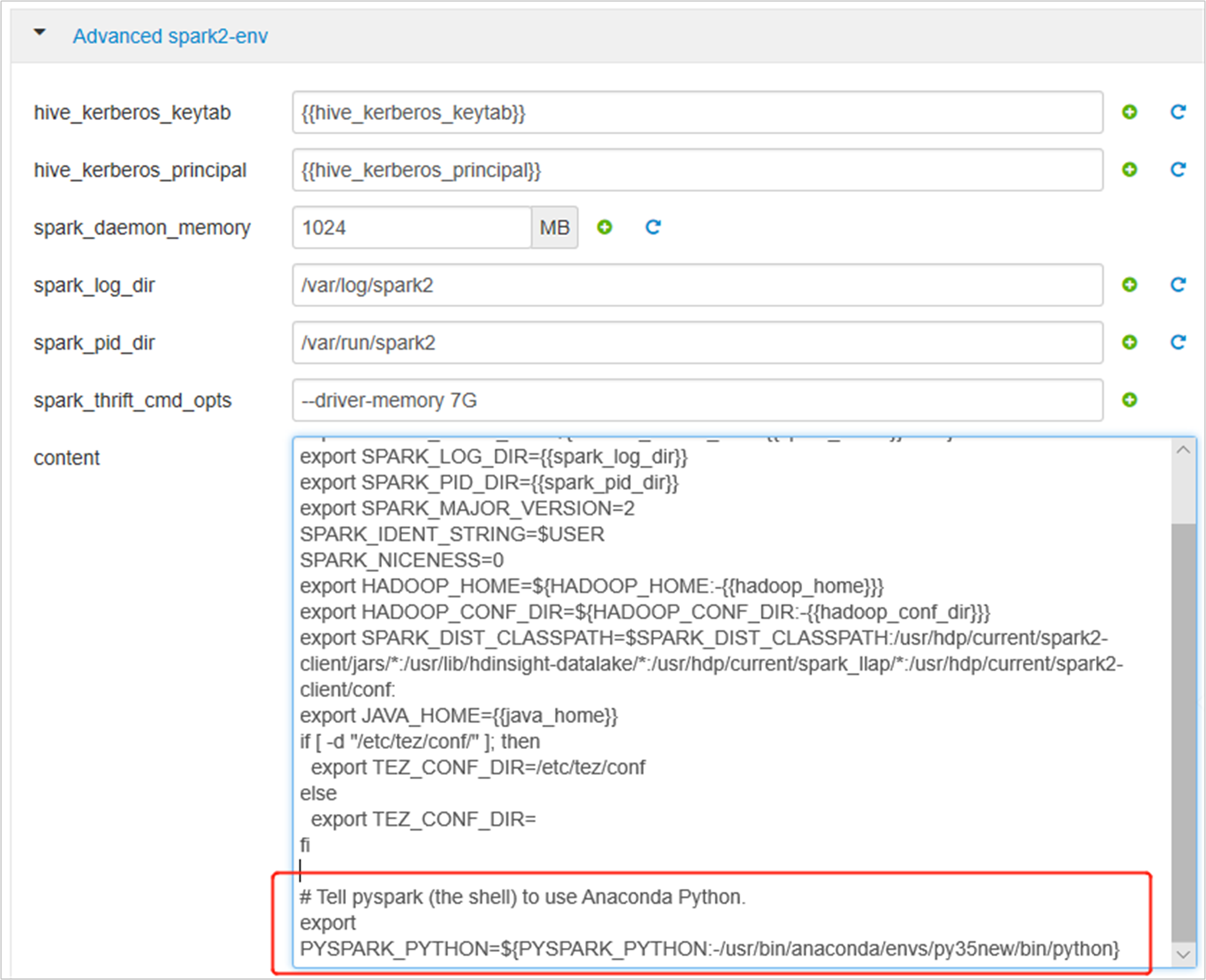
Salve as alterações e reinicie os serviços afetados. Essas alterações requerem uma reinicialização do serviço do Spark 2. A interface do usuário do Ambari exibirá um lembrete de reinicialização necessária. Clique em Reiniciar para reiniciar todos os serviços afetados.
Defina duas propriedades para sua sessão do Spark para garantir que o trabalho aponte para a configuração atualizada do Spark:
spark.yarn.appMasterEnv.PYSPARK_PYTHONespark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON.Usando o terminal ou um notebook, use a função
spark.conf.set.spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python") spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python")Se estiver usando o
livy, adicione as seguintes propriedades ao corpo da solicitação:"conf" : { "spark.yarn.appMasterEnv.PYSPARK_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python", "spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python" }
Se você quiser usar o novo ambiente virtual criado no Jupyter. Altere as configurações do Jupyter e reinicie-o. Execute ações de script em todos os nós de cabeçalho com a instrução a seguir para apontar o Jupyter para o novo ambiente virtual criado. Não se esqueça de modificar o caminho para o prefixo que você especificou para o seu ambiente virtual. Depois de executar essa ação de script, reinicie o serviço Jupyter por meio da interface do usuário do Ambari para disponibilizar essa alteração.
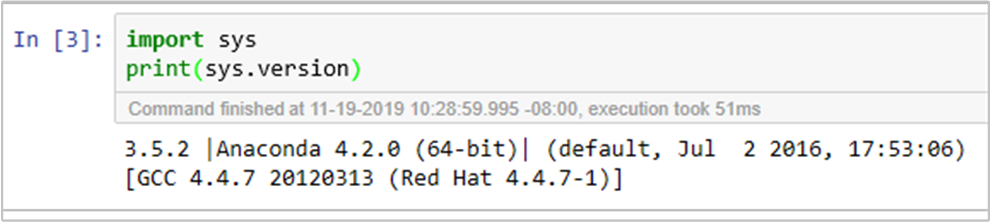
sudo sed -i '/python3_executable_path/c\ \"python3_executable_path\" : \"/usr/bin/anaconda/envs/py35new/bin/python3\"' /home/spark/.sparkmagic/config.jsonVocê pode confirmar duas vezes o ambiente do Python no Jupyter Notebook executando o seguinte código: