Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aprenda como acessar as interfaces como a interface do usuário do Apache Ambari, do Apache Hadoop YARN e o Servidor do histórico do Spark associado ao cluster do Apache Spark e como ajustar a configuração de cluster para desempenho ideal.
Abrir o servidor de histórico do Spark
O Servidor de Histórico do Spark é a interface do usuário da Web para aplicativos Spark concluídos e em execução. Trata-se de uma extensão da interface do usuário da Web do Spark. Para obter informações completas, consulte servidor de histórico do Spark.
Abrir a interface do usuário do Yarn
É possível usar a interface do usuário do YARN para monitorar aplicativos que estão em execução no momento no cluster Spark.
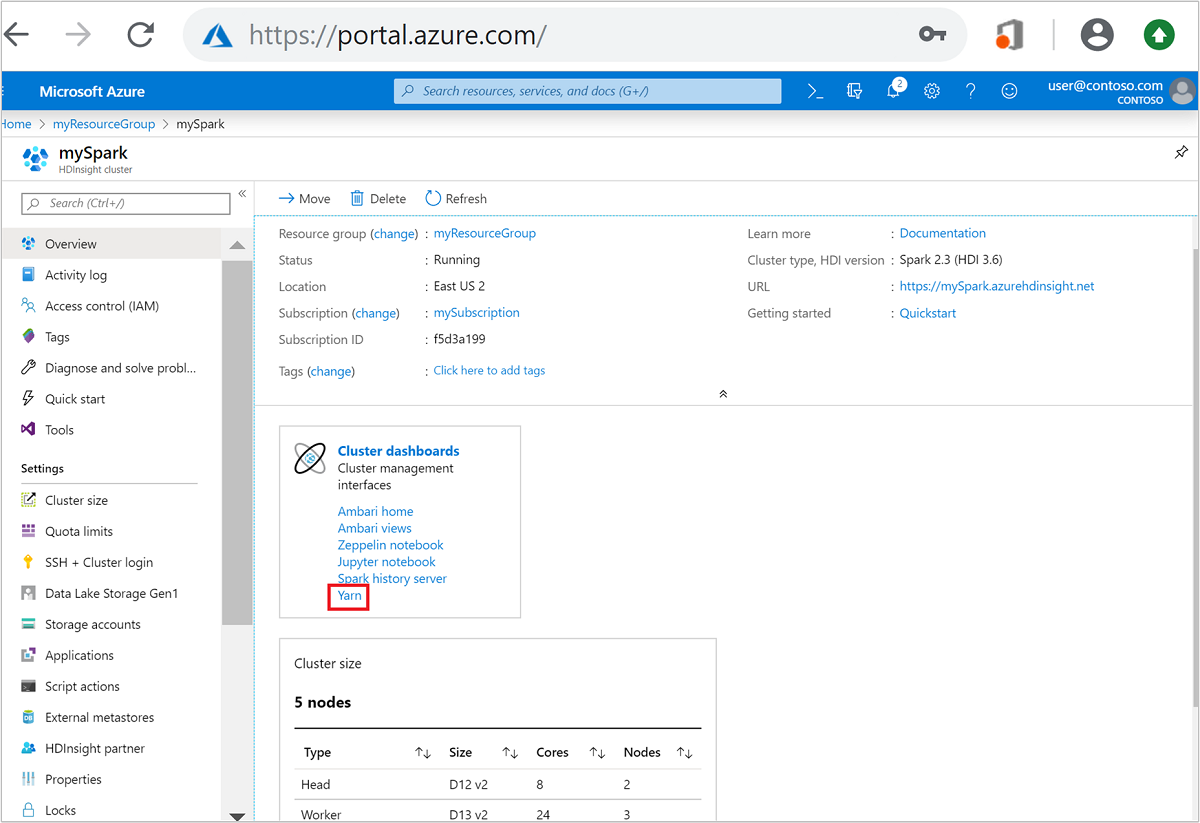
No portal do Azure, abra o cluster Spark. Para obter mais informações, consulte Listar e mostrar clusters.
Em Painéis de cluster, selecione Yarn. Quando solicitado, insira as credenciais de administrador para o cluster Spark.
Dica
Alternativamente, também é possível iniciar a interface do usuário do YARN na interface do usuário do Ambari. Na interface do usuário do Ambari, navegue até YARN>links rápidos>Ativar>Interface do usuário do Resource Manager.
Otimizar clusters para aplicativos do Spark
Os três principais parâmetros que podem ser usados para a configuração do Spark dependendo dos requisitos de aplicativo são spark.executor.instances, spark.executor.cores e spark.executor.memory. Um Executor é um processo iniciado por um aplicativo Spark. Ele é executado no nó de trabalho e é responsável por realizar as tarefas do aplicativo. O número padrão de executores e os tamanhos do executor para cada cluster são calculados com base no número de nós de trabalho e no tamanho do nó de trabalho. Essas informações são armazenadas em spark-defaults.conf nos nós do cabeçalho do cluster.
Os três parâmetros de configuração podem ser definidos no nível de cluster (para todos os aplicativos que são executados no cluster) ou também podem ser especificados para cada aplicativo individualmente.
Alterar os parâmetros usando a interface de usuário do Ambari
Na interface do usuário do Ambari, navegue até o Spark 2>Configurações>spark2-defaults personalizados.
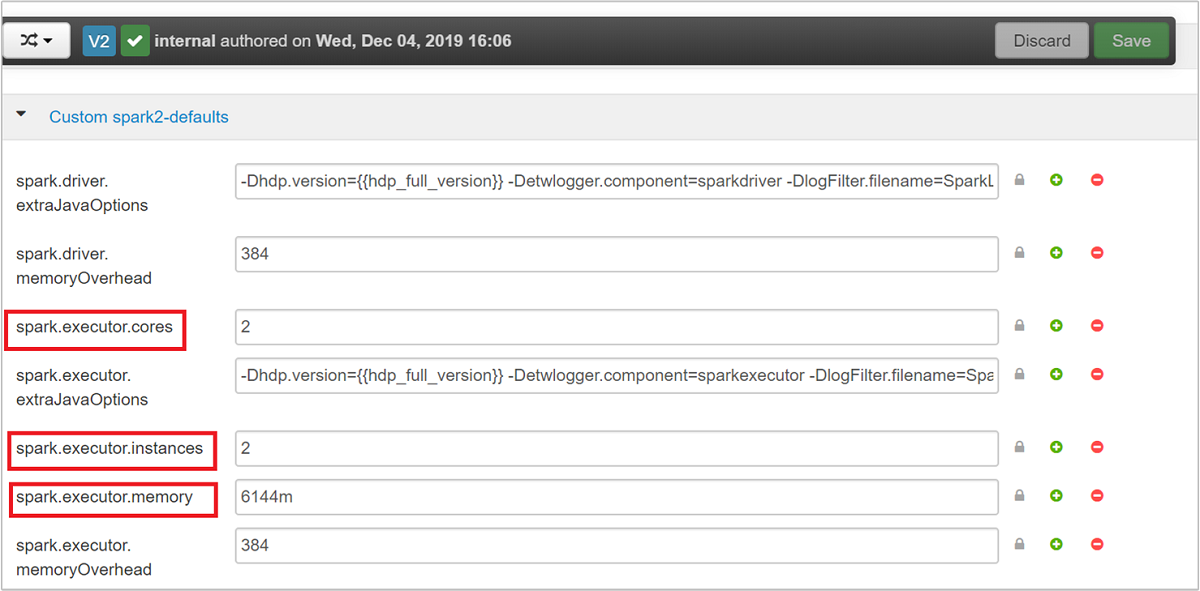
Ter quatro aplicativos Spark em execução simultaneamente no cluster é o número de valores padrão ideal. Você pode alterar esses valores na interface do usuário, conforme mostrado na seguinte captura de tela:
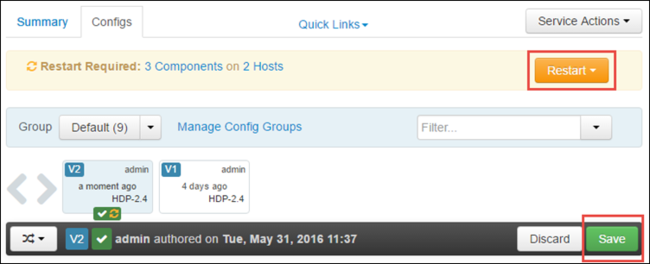
Selecionar Salvar para salvar as alterações na configuração. Na parte superior da página, será solicitado que sejam reiniciados todos os serviços afetados. Selecione Reiniciar.
Alterar os parâmetros para um aplicativo em execução no Jupyter Notebook
Para aplicativos em execução no Jupyter Notebook, é possível usar a mágica %%configure para fazer as alterações na configuração. De modo ideal, você deve fazer tais alterações no início do aplicativo, antes de executar a primeira célula de código. Isso garante que a configuração seja aplicada à sessão Livy quando for criada. Se quiser alterar a configuração em uma fase posterior no aplicativo, você deverá usar o parâmetro -f . No entanto, ao fazer isso, todo o progresso do aplicativo é perdido.
O snippet a seguir mostra como alterar a configuração para um aplicativo em execução no Jupyter.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Os parâmetros devem ser passados como uma cadeia de caracteres JSON e devem estar na linha seguinte, logo após a mágica, conforme mostrado na coluna de exemplo.
Alterar os parâmetros de um aplicativo enviado usando spark-submit
O comando a seguir é um exemplo de como alterar os parâmetros de configuração para um aplicativo em lote que é enviado usando spark-submit.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
Alterar os parâmetros de um aplicativo enviado usando cURL
O comando a seguir é um exemplo de como alterar os parâmetros de configuração para um aplicativo em lote que é enviado usando o cURL.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Observação
Copie o arquivo JAR para sua conta de armazenamento de cluster. Não copie o arquivo JAR diretamente para o nó principal.
Alterar esses parâmetros em um Servidor Spark Thrift
O Servidor Thrift Spark fornece acesso JDBC/ODBC a um cluster Spark e é usado para atender às consultas SQL do Spark. Ferramentas como Power BI, Tableau, dentre outroas, usam o protocolo ODBC para se comunicar com o Servidor Thrift Spark e executar consultas SQL do Spark como um Aplicativo Spark. Quando um cluster Spark é criado, as duas instâncias do Servidor Thrift Spark são iniciadas, uma em cada nó de cabeçalho. Cada Servidor Thrift Spark é visto como um aplicativo Spark na interface de usuário do YARN.
O Servidor Thrift Spark usa a alocação dinâmica de executor e, portanto, spark.executor.instances não é usado. Em vez disso, o Servidor Thrift Spark usa spark.dynamicAllocation.maxExecutors e spark.dynamicAllocation.minExecutors para especificar a contagem do executor. Os parâmetros de configuração spark.executor.cores e spark.executor.memory são usados para modificar o tamanho do executor. Altere esses parâmetros, conforme mostrado nas seguintes etapas:
Expanda a categoria spark2-thrift-sparkconf avançada para atualizar os parâmetros
spark.dynamicAllocation.maxExecutorsespark.dynamicAllocation.minExecutors.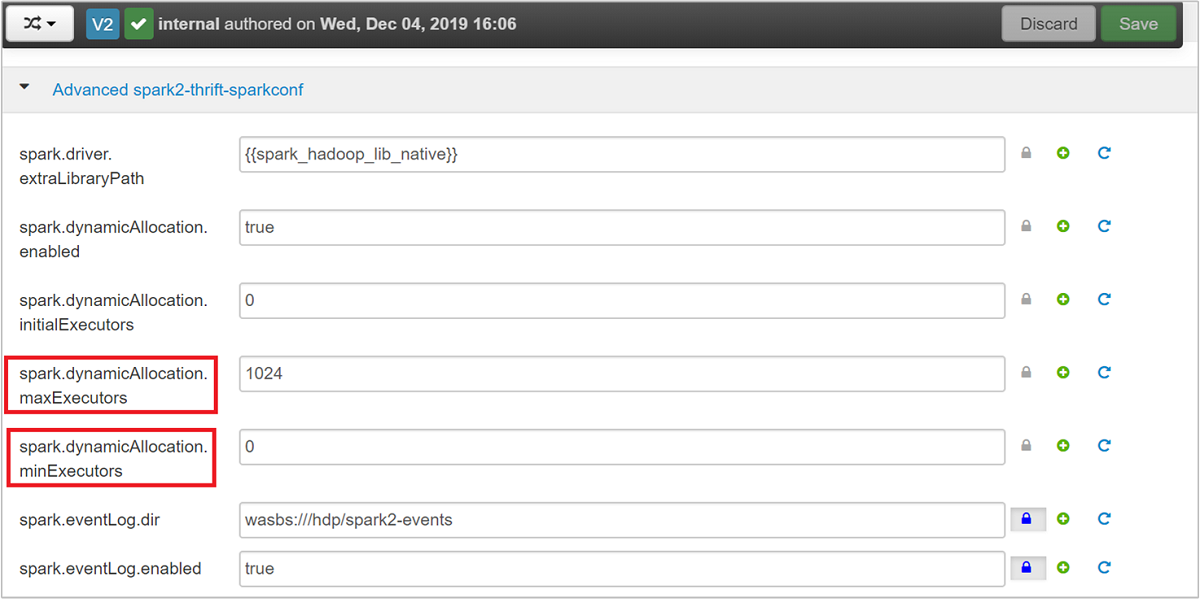
Expanda a categoria spark2-thrift-sparkconf personalizada para atualizar os parâmetros
spark.executor.coresespark.executor.memory.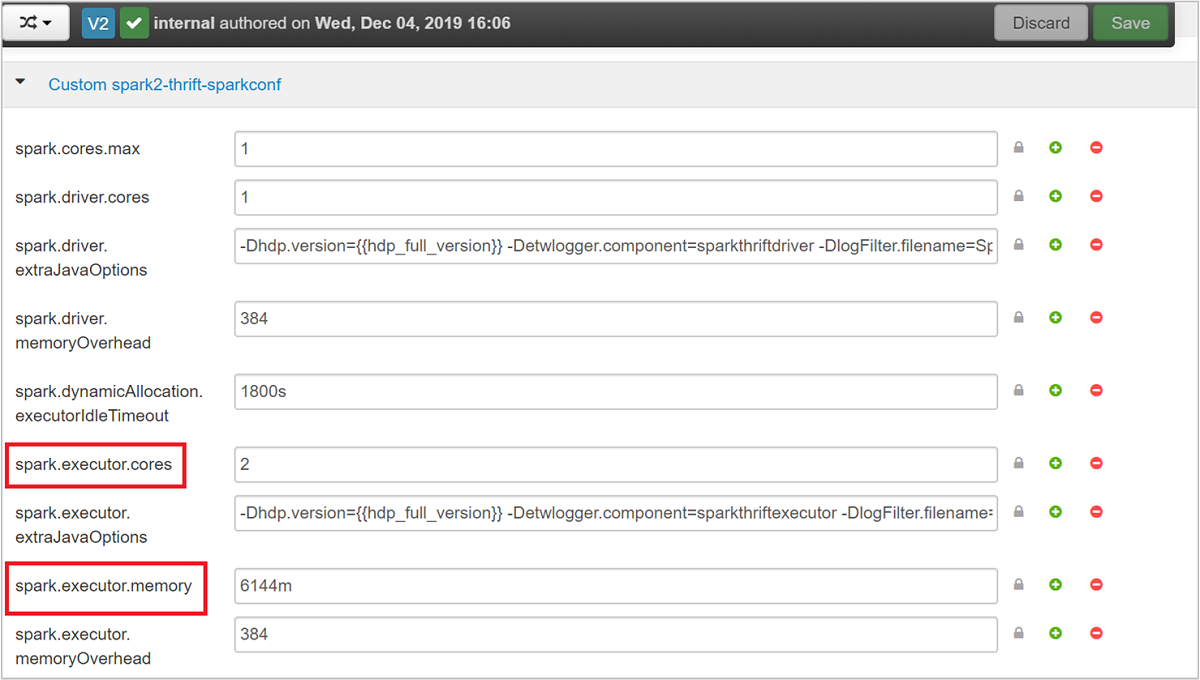
Alterar a memória do driver do servidor Spark Thrift
A memória do driver do Servidor Spark Thrift é configurada para 25% do tamanho da RAM do nó de cabeçalho, desde que o tamanho total da RAM do nó de cabeçalho seja superior a 14 GB. Use a interface do usuário do Ambari para alterar a configuração da memória do driver, conforme mostrado na seguinte captura de tela:
Na interface do usuário do Ambari, navegue até Spark2>Configurações>Spark2-env avançadas. Em seguida, forneça o valor para spark_thrift_cmd_opts.
Recuperar recursos do cluster Spark
Devido à alocação dinâmica do Spark, os únicos recursos que são consumidos pelo servidor Thrift são os recursos para os dois mestres de aplicativo. Para recuperar esses recursos, é necessário interromper os serviços do Servidor Thrift em execução no cluster.
Na interface de usuário do Ambari, no painel esquerdo, selecione Spark2.
Na página seguinte, selecione Servidores Thrift Spark 2.
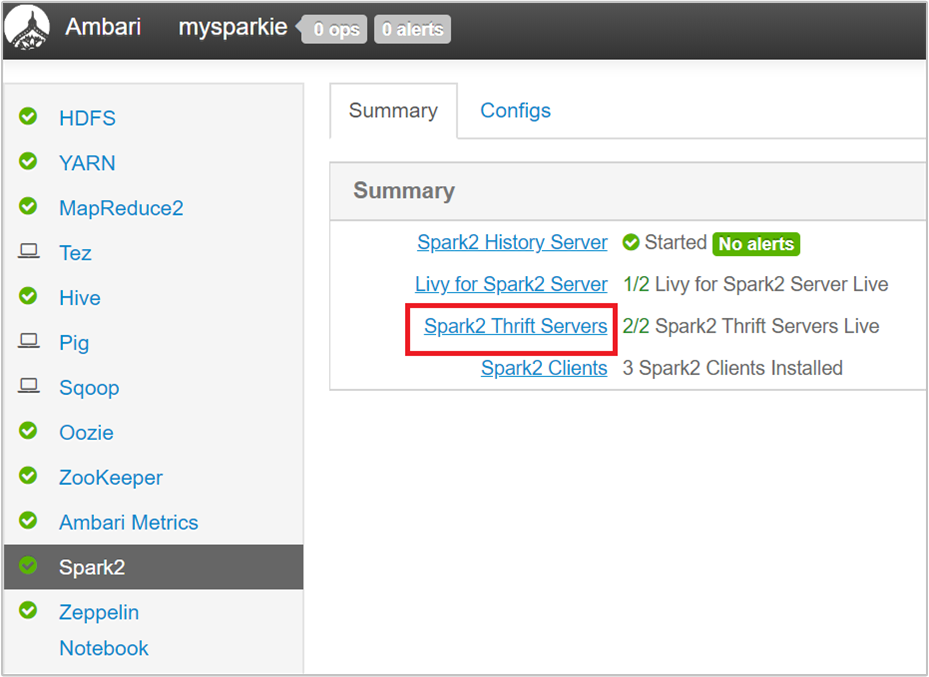
Você deve ver os dois nós de cabeçalho nos quais o servidor Thrift Spark 2 está em execução. Selecione um dos nós de cabeçalho.
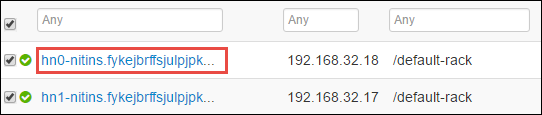
A próxima página lista todos os serviços em execução nesse nó de cabeçalho. Na lista, selecione o botão de menu ao lado de servidor Thrift Spark 2 e, em seguida, selecione Parar.
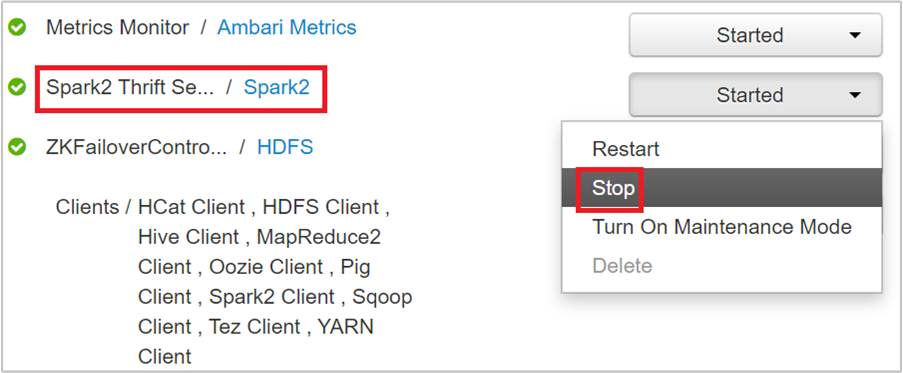
Repita essas etapas no outro nó de cabeçalho.
Reiniciar o serviço Jupyter
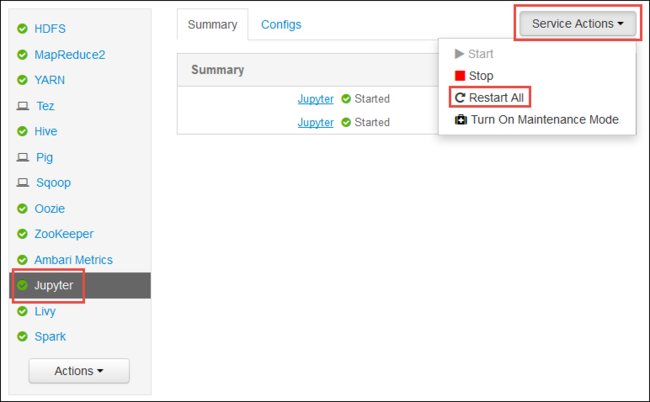
Inicie a interface do usuário da Web do Ambari, conforme mostrado no início do artigo. No painel de navegação esquerdo, selecione Jupyter, selecione Ações de Serviço e selecione Reiniciar Tudo. Isso iniciará o serviço Jupyter em todos os nós de cabeçalho.
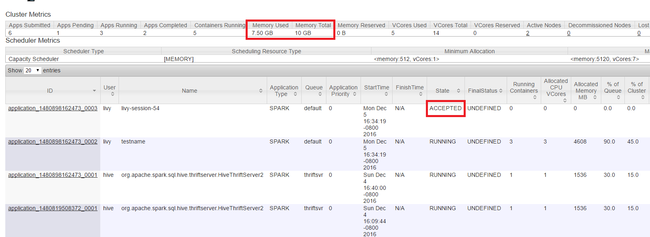
Monitorar recursos
Inicie a interface do usuário do Yarn, conforme mostrado no início do artigo. Na tabela de métricas de Cluster na parte superior da tela, verifique os valores de memória usada e memória Total colunas. Se os dois valores estiverem próximos, talvez não haja recursos suficientes para iniciar o próximo aplicativo. O mesmo se aplica para o VCores usado e VCores Total colunas. Além disso, no modo de exibição principal, se um aplicativo continuar em estado ACEITO e não em transição para o estado EXECUTANDO nem FALHA, também pode ser uma indicação de que ele não está obtendo recursos suficientes para iniciar.
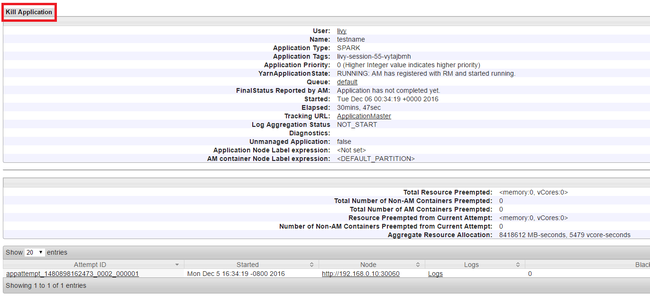
Encerrar aplicativos em execução
Na interface do usuário Yarn, no painel esquerdo, selecione executando. Na lista de aplicativos em execução, determine o aplicativo a ser encerrado e selecione a ID.
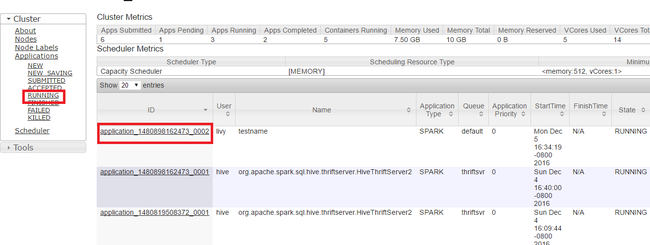
Selecione Encerrar Aplicativo no canto superior direito e selecione OK.
Confira também
Para analistas de dados
- Apache Spark com Machine Learning: use o Spark no HDInsight para analisar a temperatura do edifício usando dados de HVAC
- Apache Spark com Machine Learning: use o Spark no HDInsight para prever os resultados da inspeção de alimentos
- Análise de log do site usando o Apache Spark no HDInsight
- Análise de dados do Application Insight telemetria usando o Apache Spark no HDInsight
Para desenvolvedores do Apache Spark
- Criar um aplicativo autônomo usando Scala
- Execute trabalhos remotamente em um cluster do Apache Spark usando o Apache Livy
- Use o Plug-in de Ferramentas do HDInsight para IntelliJ IDEA para criar e enviar aplicativos Spark Scala
- Use o Plugin do HDInsight Tools para o IntelliJ IDEA para depurar os aplicativos do Apache Spark remotamente
- Use os blocos de anotações do Apache Zeppelin com um cluster do Apache Spark no HDInsight
- Kernels disponíveis para o Jupyter Notebook no cluster do Apache Spark para HDInsight
- Usar pacotes externos com Jupyter Notebooks
- Instalar o Jupyter em seu computador e conectar-se a um cluster Spark do HDInsight