Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Um cluster HDInsight Spark inclui uma instalação da biblioteca Apache Spark. Cada cluster HDInsight inclui parâmetros de configuração padrão para todos os seus serviços instalados, incluindo Spark. Um aspecto importante do gerenciamento de um cluster Apache Hadoop do HDInsight é o monitoramento da carga de trabalho, incluindo trabalhos do Spark. Para executar melhor trabalhos do Spark, considere a configuração de cluster físico ao determinar a configuração lógica do cluster.
O cluster padrão do HDInsight Apache Spark inclui os seguintes nós: três nós do Apache ZooKeeper, dois nós principais e um ou mais nós do trabalhador:
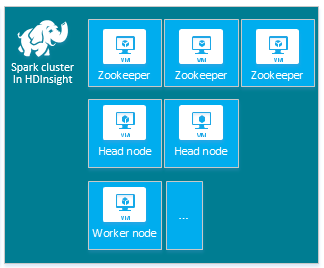
O número de VMs e os tamanhos de VM para os nós no cluster HDInsight também podem afetar sua configuração do Spark. Valores de configuração do HDInsight não padrão geralmente requerem valores de configuração do Spark não padrão. Quando você cria um cluster Spark do HDInsight, serão mostrados tamanhos de VM sugeridos para cada um dos componentes. Atualmente os tamanhos de VM do Linux com otimização de memória do Azure são D12 v2 ou posterior.
Versões Apache Spark
Use a versão recomendada do Spark para seu cluster. O serviço HDInsight inclui várias versões do Spark e HDInsight em si. Cada versão do Spark inclui um conjunto de configurações de cluster padrão.
Quando você cria um novo cluster, aqui estão as versões atuais do Spark para escolher. Pode ver a lista completa em Versões e componentes do HDInsight.
Observação
A versão padrão de Apache Spark para o serviço HDInsight pode ser alterada sem aviso prévio. Se você tem uma dependência de versão, a Microsoft recomenda que você especifique essa versão específica ao criar clusters usando o SDK do .NET, o Azure PowerShell e a CLI Clássica do Azure.
Apache Spark tem três locais de configuração do sistema:
- Propriedades do Spark controla a maioria dos parâmetros do aplicativo e pode ser definida usando um
SparkConfobjeto, ou por meio de propriedades do sistema Java. - Variáveis de ambiente podem ser usadas para definir configurações por computador, como o endereço IP, por meio de
conf/spark-env.shscript em cada nó. - Registro em log pode ser configurado por meio de
log4j.properties.
Quando você seleciona uma versão específica do Spark, seu cluster inclui as definições de configuração padrão. Você pode alterar os valores de configuração do Spark padrão usando um arquivo de configuração personalizado do Spark. Um exemplo é mostrado abaixo.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
O exemplo mostrado acima substitui vários valores padrão para cinco parâmetros de configuração do Spark. Esses valores são o codec de compactação, o tamanho mínimo dividido de MapReduce do Apache Hadoop e os tamanhos de bloco parquet. Além disso, os valores padrão de tamanhos de arquivos abertos e partição Spark SQL. Essas alterações de configuração são escolhidas porque os dados e trabalhos associados (neste exemplo, dados de genoma) têm características específicas. Essas características serão melhores usando essas definições de configuração personalizadas.
Exibir definições de configuração do cluster
Verifique as definições atuais de configuração do cluster HDInsight antes de executar a otimização de desempenho no cluster. Iniciar o dashboard de HDInsight do portal do Azure clicando no link Dashboard no painel de cluster Spark. Entre com o nome de usuário e a senha do administrador do cluster.
A interface do usuário da Web do Apache Ambari aparece, com um painel das principais métricas de uso de recursos do cluster. O painel do Ambari mostra a configuração do Apache Spark e outros serviços instalados. O painel inclui uma guia Histórico de Configuração, onde você pode exibir informações dos serviços instalados, incluindo o Spark.
Para ver os valores de configuração para o Apache Spark, selecione Histórico de Configuração, em seguida, selecione Spark2. Selecione a guia configurações e, em seguida, selecione o link Spark (ou Spark2, dependendo de sua versão) na lista de serviços. Você verá uma lista de valores de configuração para o cluster:
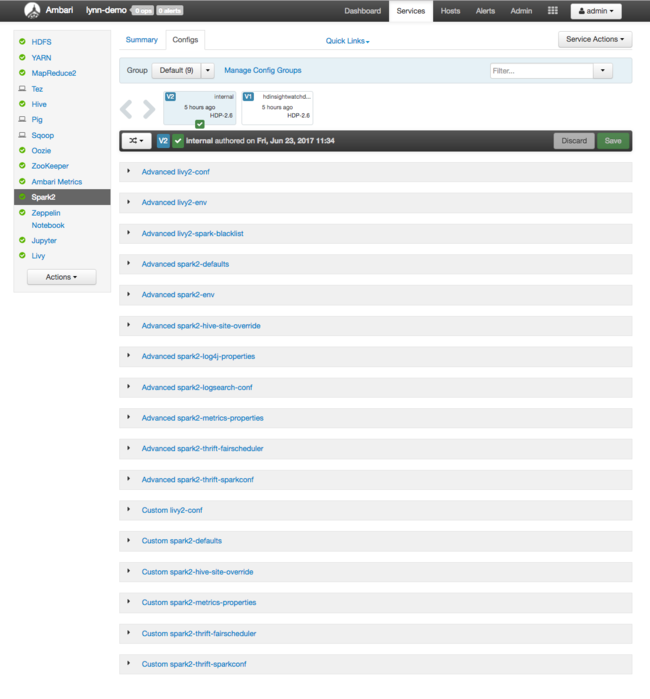
Para ver e alterar valores individuais de configuração do Spark, selecione qualquer link com “spark” no título. Configurações para Spark incluem os dois valores de configuração avançada e personalizada nestas categorias:
- Spark2-defaults personalizada
- Spark2-metrics-properties personalizada
- Spark2-defaults avançada
- Spark2-env avançada
- Spark2-hive-site-override avançada
Se você criar um conjunto fora do padrão de valores de configuração, o histórico de atualização será visível. Esse histórico de configuração pode ser útil para ver qual configuração não-padrão tem um desempenho ideal.
Observação
Para ver, mas não alterar, definições de configurações de cluster Spark comuns, selecione a guia Ambiente na interface superior interface do usuário de trabalho Spark.
Configurando executores Spark
O diagrama a seguir mostra os objetos de chave Spark: o programa de driver e seu contexto Spark associado e o gerenciador de cluster e seus n nós de trabalho. Cada nó de trabalho inclui um Executor, um cache, e n instâncias da tarefa.
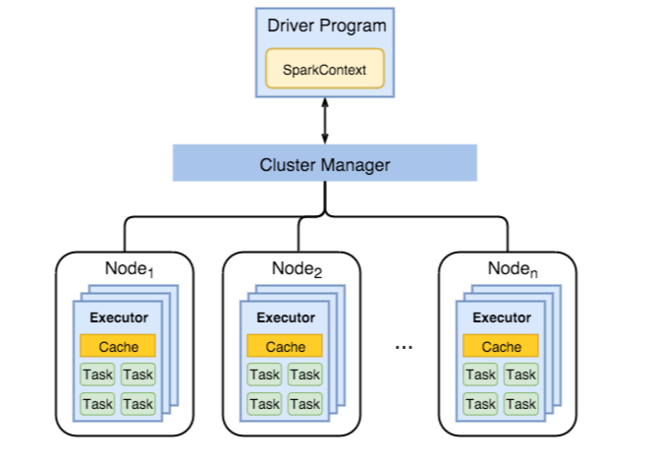
Os trabalhos de Spark usam recursos de trabalho, particularmente, memória, portanto, é comum para ajustar os valores de configuração do Spark para executores de nó de trabalho.
Três parâmetros de chave que geralmente são ajustados para ajustar as configurações do Spark para melhorar os requisitos do aplicativo são spark.executor.instances, spark.executor.cores, e spark.executor.memory. Um Executor é um processo iniciado por um aplicativo Spark. Um Executor é executado no nó de trabalho e é responsável por realizar as tarefas do aplicativo. O número de nós de trabalho e o tamanho do nó de trabalho determina o número de executores e os tamanhos de executor. Esses valores são armazenados em spark-defaults.conf nos nós do cabeçalho do cluster. Você pode editar esses valores em um cluster em execução selecionando Personalizar padrões Spark na interface do usuário da Web do Ambari. Depois de fazer alterações, você será solicitado pela interface do usuário para reiniciar todos os serviços afetados.
Observação
Esses três parâmetros de configuração podem ser definidos no nível de cluster (para todos os aplicativos que são executados no cluster) ou também especificados para cada aplicativo individualmente.
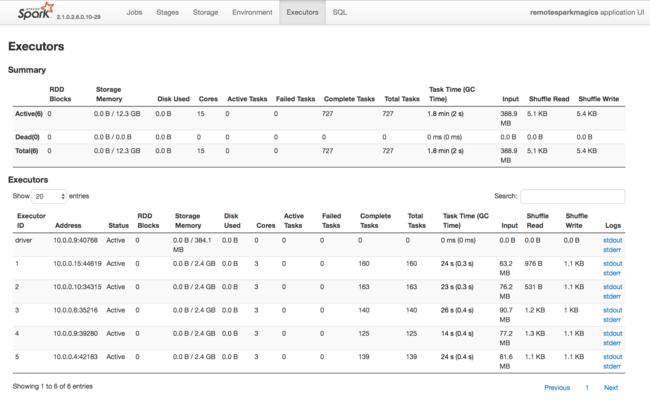
Outra fonte de informações sobre os recursos usados pelos executores do Spark é a interface do usuário do aplicativo Spark. Na interface do usuário, a opção Executores mostra as exibições de Resumo e Detalhe da configuração e dos recursos consumidos. Determine se os valores de executores devem ser alterados para todo o cluster ou para um conjunto específico de execuções de trabalho.
Ou você pode usar a API REST do Ambari para verificar periodicamente as configurações de cluster HDInsight e Spark. Mais informações estão disponíveis na Referência da API do Apache Ambari no GitHub.
Dependendo da carga de trabalho do Spark, você poderá determinar que uma configuração Spark não padrão proporcione execuções de trabalho do Spark mais otimizadas. Execute testes de comparação com cargas de trabalho de exemplo para validar quaisquer configurações não padrão de cluster. Estes são alguns dos parâmetros comuns que você pode considerar ajustar:
| Parâmetro | Descrição |
|---|---|
| --num-executors | Define o número de executores. |
| --executor-cores | Define o número de núcleos para cada executor. É recomendável usar executores de tamanho médio, pois outros processos também consomem parte da memória disponível. |
| --executor-memory | Controla o tamanho da memória (tamanho de heap) de cada executor no Apache Hadoop YARN, e você precisará deixar alguma memória para a sobrecarga de execução. |
Aqui está um exemplo de dois nós de trabalho com valores de configuração diferentes:

A lista a seguir mostra os principais parâmetros de memória de executor Spark.
| Parâmetro | Descrição |
|---|---|
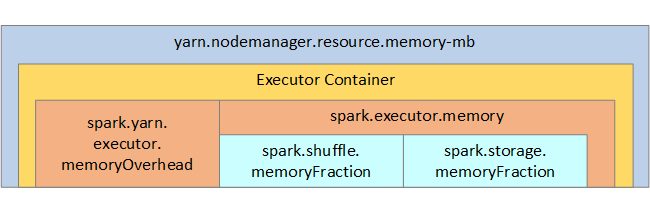
| spark.executor.memory | Define a quantidade total de memória disponível para um executor. |
| spark.storage.memoryFraction | (padrão aproximadamente 60%) define a quantidade de memória disponível para o armazenamento RDDs persistentes. |
| spark.shuffle.memoryFraction | (padrão aproximadamente 20%) define a quantidade de memória reservada para ordem aleatória. |
| spark.storage.unrollFraction e spark.storage.safetyFraction | (totalizando aproximadamente 30% do total de memória). Esses valores são usados internamente pelo Spark e não devem ser alterados. |
O YARN controla a soma máxima da memória usada por todos os contêineres em cada nó do Spark. O diagrama a seguir mostra as relações por nó entre objetos de configuração YARN e objetos Spark.
Alterar parâmetros para um aplicativo em execução no Jupyter Notebook
Os clusters Spark no HDInsight incluem um número de componentes por padrão. Cada um desses componentes inclui valores de configuração padrão que podem ser substituídos conforme necessário.
| Componente | Descrição |
|---|---|
| Spark Core | Spark Core, Spark SQL, APIs de streaming do Spark, GraphX e Apache Spark MLlib. |
| Anaconda | Um gerenciador de pacotes Python. |
| Apache Livy | A API REST do Apache Spark, usada para enviar trabalhos remotos para um cluster Spark do HDInsight. |
| Jupyter Notebooks e Apache Zeppelin Notebooks | Interface do usuário interativa baseada em navegador para interagir com o cluster Spark. |
| Driver ODBC | Conecta clusters Spark no HDInsight para ferramentas de business intelligence (BI), como o Microsoft Power BI e o Tableau. |
Para aplicativos em execução no Jupyter Notebook, você pode usar o comando %%configure para fazer as alterações na configuração no próprio notebook. Essas alterações de configuração serão aplicadas aos trabalhos Spark executados da sua instância do bloco de notas. Faça tais alterações no início do aplicativo, antes de executar a primeira célula de código. A configuração alterada é aplicada à sessão Livy, quando ela é criada.
Observação
Para alterar a configuração em uma fase posterior no aplicativo, use o parâmetro -f (força). No entanto, todo o progresso do aplicativo será perdido.
O código abaixo mostra como alterar a configuração de um aplicativo em execução em um Jupyter Notebook.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Conclusão
Monitore as definições de configuração principais para garantir que os trabalhos do Spark sejam executados de maneira previsível e com bom desempenho. Essas configurações ajudam a determinar a melhor configuração de cluster do Spark para suas cargas de trabalho específicas. Além disso, você precisará monitorar a execução de trabalhos do Spark de longa duração e/ou que consomem recursos. Os desafios mais comuns giram em torno da pressão de memória de configurações inadequadas, como executores de tamanho incorreto. Além disso, tarefas e operações de longa duração, que resultam em operações cartesianas.