Usar o cluster HDInsight Spark para analisar dados no Data Lake Storage Gen1
Neste artigo, você usa o Jupyter Notebook disponível com clusters do HDInsight Spark para executar uma tarefa que lê dados de uma conta do Data Lake Storage.
Pré-requisitos
Conta do Azure Data Lake Storage Gen1. Siga as instruções em Introdução ao Azure Data Lake Storage Gen1 usando o portal do Azure.
Cluster do Azure HDInsight Spark com o Data Lake Storage Gen1 como armazenamento. Siga as instruções em guia de início rápido: configurar clusters no HDInsight.
Preparar os dados
Observação
Não é necessário realizar essa etapa se você criou o cluster HDInsight com o Data Lake Storage como armazenamento padrão. Os processos de criação de cluster adicionam alguns dados de exemplo à conta do Data Lake Storage especificada durante a criação do cluster. Vá para a seção Usar o cluster HDInsight Spark com o Data Lake Storage.
Se você criou um cluster HDInsight com o Data Lake Store como armazenamento adicional e o Azure Storage Blob como armazenamento padrão, copie primeiro alguns dados de exemplo para a conta do Data Lake Storage. Use os dados de exemplo do Blob de Armazenamento do Azure associado ao cluster HDInsight.
Abra um prompt de comando e navegue até o diretório onde AdlCopy está instalado, normalmente
%HOMEPATH%\Documents\adlcopy.Execute o seguinte comando para copiar um blob específico do contêiner de origem para um Repositório Data Lake Storage:
AdlCopy /source https://<source_account>.blob.core.windows.net/<source_container>/<blob name> /dest swebhdfs://<dest_adls_account>.azuredatalakestore.net/<dest_folder>/ /sourcekey <storage_account_key_for_storage_container>Copie o arquivo de exemplo de dados HVAC.csv em /HdiSamples/HdiSamples/SensorSampleData/hvac/ para a conta do Azure Data Lake Storage. O snippet de código deve parecer com:
AdlCopy /Source https://mydatastore.blob.core.windows.net/mysparkcluster/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv /dest swebhdfs://mydatalakestore.azuredatalakestore.net/hvac/ /sourcekey uJUfvD6cEvhfLoBae2yyQf8t9/BpbWZ4XoYj4kAS5Jf40pZaMNf0q6a8yqTxktwVgRED4vPHeh/50iS9atS5LQ==Aviso
Certifique-se de que os nomes de arquivo e caminho usem a capitalização adequada.
Você deverá inserir as credenciais da assinatura do Azure vinculadas à sua conta do Data Lake Storage. Você verá um resultado semelhante ao seguinte snippet:
Initializing Copy. Copy Started. 100% data copied. Copy Completed. 1 file copied.O arquivo de dados (HVAC.csv) será copiado em uma pasta /hvac na conta do Data Lake Storage.
Usar um cluster Spark HDInsight com o Data Lake Storage Gen1
No quadro inicial do portal do Azure, clique no bloco do cluster do Apache Spark (se você o fixou no quadro inicial). Você também pode navegar até o cluster em Procurar Tudo>Clusters HDInsight.
Na folha do cluster Spark, clique em Links Rápidos e, na folha Painel do Cluster, clique em Notebook do Jupyter. Se você receber uma solicitação, insira as credenciais de administrador para o cluster.
Observação
Você também pode acessar o Bloco de Notas Jupyter de seu cluster abrindo a seguinte URL no navegador. Substitua CLUSTERNAME pelo nome do cluster:
https://CLUSTERNAME.azurehdinsight.net/jupyterCrie um novo bloco de anotações. Clique em Novo e em PySpark.
Por ter criado um notebook usando o kernel PySpark, não será necessário criar nenhum contexto explicitamente. Os contextos do Spark e do Hive serão criados automaticamente para você ao executar a primeira célula do código. Você pode começar importando os tipos obrigatórios para este cenário. Para fazer isso, cole o snippet de código a seguir em uma célula vazia e pressione SHIFT + ENTER.
from pyspark.sql.types import *Toda vez que você executar um trabalho no Jupyter, o título da janela do navegador da Web mostrará um status (Ocupado) com o título do bloco de anotações. Você também verá um círculo sólido ao lado do texto PySpark no canto superior direito. Depois que o trabalho for concluído, isso será alterado para um círculo vazio.

Carregue os dados de exemplo em uma tabela temporária usando o arquivo HVAC.csv copiado para a conta do Data Lake Storage Gen1. Você pode acessar os dados na conta do Repositório Data Lake Storage usando o seguinte padrão de URL.
Se o Data Lake Storage Gen1 for seu armazenamento padrão, HVAC.csv estará em um caminho semelhante à URL a seguir:
adl://<data_lake_store_name>.azuredatalakestore.net/<cluster_root>/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvOu, você também pode usar um formato reduzido como o seguinte:
adl:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvSe o Data Lake Storage for seu armazenamento adicional, HVAC.csv estará no local onde você o copiou, por exemplo:
adl://<data_lake_store_name>.azuredatalakestore.net/<path_to_file>Em uma célula vazia, cole o seguinte exemplo de código, substitua MYDATALAKESTORE pelo nome de sua conta do Data Lake Storage e pressione Shift+Enter. Esse exemplo de código registra os dados em uma tabela temporária chamada hvac.
# Load the data. The path below assumes Data Lake Storage is default storage for the Spark cluster hvacText = sc.textFile("adl://MYDATALAKESTORazuredatalakestore. net/cluster/mysparkclusteHdiSamples/HdiSamples/ SensorSampleData/hvac/HVAC.csv") # Create the schema hvacSchema = StructType([StructField("date", StringTy(), False) ,StructField("time", StringType(), FalseStructField ("targettemp", IntegerType(), FalseStructField("actualtemp", IntegerType(), FalseStructField("buildingID", StringType(), False)]) # Parse the data in hvacText hvac = hvacText.map(lambda s: s.split(",")).filt(lambda s: s [0] != "Date").map(lambda s:(str(s[0]), s(s[1]), int(s[2]), int (s[3]), str(s[6]) )) # Create a data frame hvacdf = sqlContext.createDataFrame(hvac,hvacSchema) # Register the data fram as a table to run queries against hvacdf.registerTempTable("hvac")
Como está usando um kernel PySpark, agora você pode executar diretamente uma consulta SQL na tabela temporária hvac que acabou de criar usando a mágica de
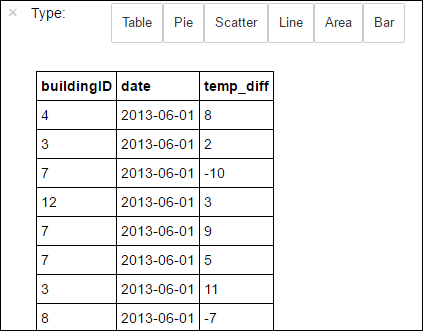
%%sql. Para mais informações sobre o%%sqlmagic, assim como sobre outros magics disponíveis com o kernel do PySpark, consulte Kernels disponíveis no Jupyter Notebook com clusters do Apache Spark para HDInsight.%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Depois que o trabalho for concluído com êxito, a saída tabular a seguir será exibida por padrão.
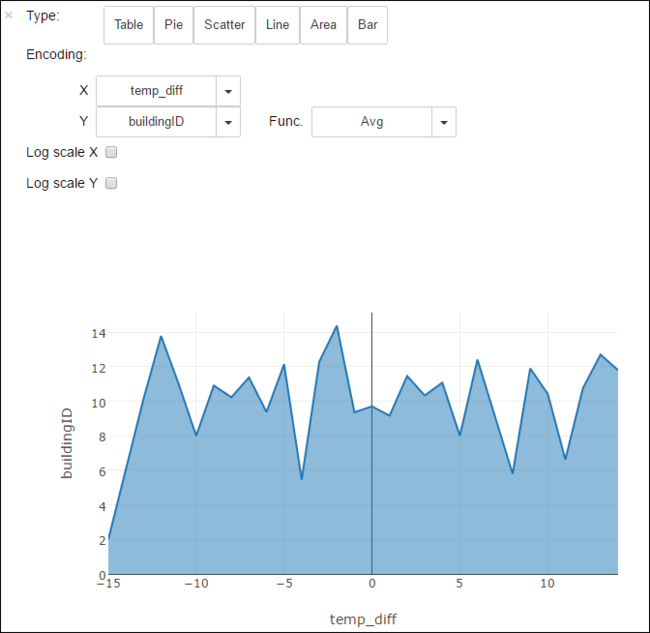
Você também pode ver os resultados em outras visualizações. Por exemplo, um grafo de área para a mesma saída seria semelhante ao seguinte.
Depois de concluir a execução do aplicativo, você deve encerrar o notebook para liberar os recursos. Para isso, no menu Arquivo do bloco de anotações, clique em Fechar e Interromper. Isso desligará e fechará o bloco de anotações.
Próximas etapas
- Criar um aplicativo Scala autônomo para ser executado no cluster do Apache Spark
- Use as ferramentas do HDInsight no Azure Toolkit for IntelliJ crie aplicativos do Apache Spark para o cluster do HDInsight Spark Linux
- Use as ferramentas do HDInsight no Azure Toolkit for Eclipse para criar aplicativos Apache Spark para o cluster do HDInsight Spark Linux
- Usar Gen2 de armazenamento do Azure Data Lake com clusters de HDInsight do Azure