O que é contextualização no processador de dados?
Importante
O recurso Pré-visualização de Operações do Azure IoT — habilitado pelo Azure Arc — está atualmente em VERSÃO PRÉVIA. Você não deve usar esse software em versão prévia em ambientes de produção.
Você precisará implantar uma nova instalação do Azure IoT Operations quando uma versão geralmente disponível for disponibilizada, você não poderá atualizar uma instalação de visualização.
Veja os Termos de Uso Complementares para Versões Prévias do Microsoft Azure para obter termos legais que se aplicam aos recursos do Azure que estão em versão beta, versão prévia ou que, de outra forma, ainda não foram lançados em disponibilidade geral.
A contextualização adiciona informações a mensagens em um pipeline. A contextualização pode:
- Aprimorar o valor, o significado e os insights derivados dos dados que fluem pelo pipeline.
- Enriquecer seus dados de origem para torná-los mais compreensíveis e significativos.
- Facilitar a interpretação dos dados e tornar a tomada de decisões mais fácil, precisa e eficaz.
Por exemplo, o sensor de temperatura em sua fábrica envia um ponto de dados que lê 120 °C. Sem contextualização, é difícil derivar qualquer significado desse dado. No entanto, se você adicionar contexto como "A temperatura do ativo forno durante o turno da manhã foi de 120 °C", o valor dos dados aumenta significativamente, pois agora você pode derivar insights úteis dele.
Dados contextualizados fornecem uma visão mais abrangente das operações, ajudando você a tomar decisões mais informadas. As informações contextuais enriquecem os dados facilitando a análise de dados. Elas ajudam você a otimizar processos, melhorar a eficiência e reduzir o tempo de inatividade.
Melhoramento da mensagem
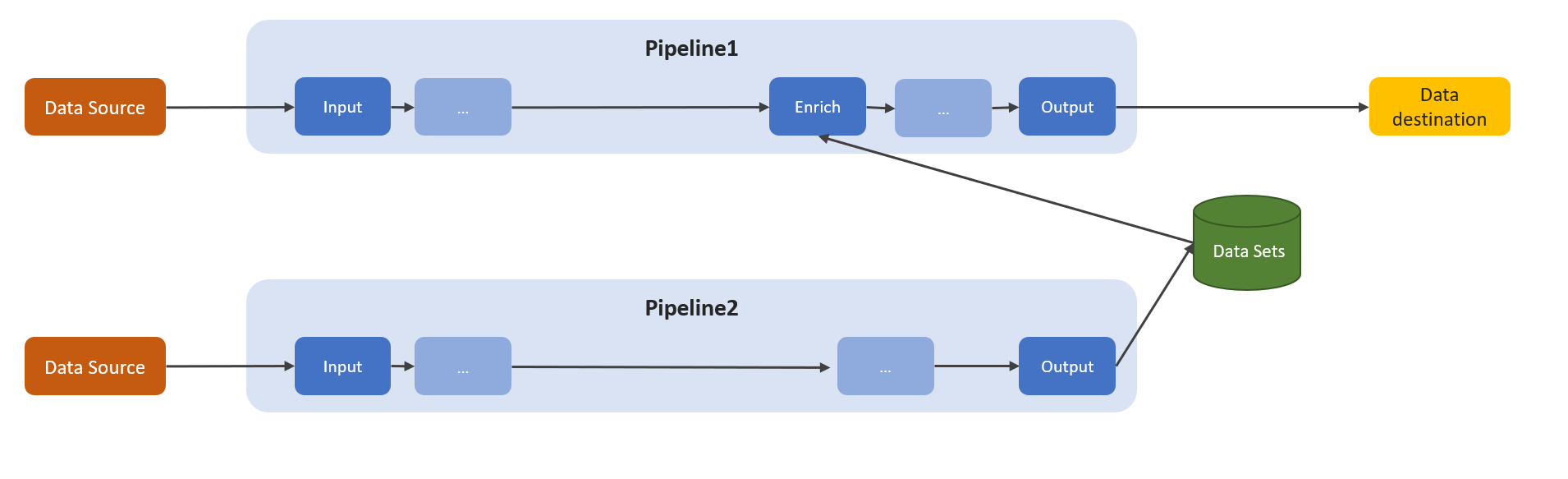
Um pipeline do processador de dados contextualiza os dados enriquecendo as mensagens que fluem pelo pipeline com dados de referência armazenados anteriormente. A contextualização usa o armazenamento de dados de referência interno. Você pode interromper o processo de uso do armazenamento de dados de referência em um pipeline em três etapas:
Crie e configure um conjunto de dados. Esta etapa cria e configura seus conjuntos de dados no armazenamento de dados de referência. A configuração inclui as chaves a serem usadas para junções e as políticas de expiração de dados de referência.
Faça a ingestão de seus dados de referência. Depois de configurar seus conjuntos de dados, a próxima etapa é ingerir dados no armazenamento de dados de referência. Use o estágio de saída do pipeline de dados de referência para alimentar os dados em seus conjuntos de dados.
Enriqueça seus dados. Em um estágio de enriquecimento, use os dados armazenados no armazenamento de dados de referência para enriquecer os dados que passam pelo pipeline do processador de dados. Esse processo aprimora o valor e a relevância dos dados, fornecendo insights mais avançados e recursos aprimorados de análise de dados.