Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a: Aplicativos Lógicos do Azure (Consumo + Padrão)
Se o fluxo de trabalho do aplicativo lógico estiver sujeito a limitação, que ocorre quando o número de solicitações excede a taxa que o destino pode manipular em um determinado período de tempo, você receberá o erro "HTTP 429 - Muitas solicitações". A limitação pode criar problemas como atraso no processamento de dados, velocidade de desempenho reduzida e erros (por exemplo, exceder a política de repetições).
Por exemplo, a seguinte ação do SQL Server em um fluxo de trabalho de Consumo mostra um erro 429, que relata um problema de limitação:
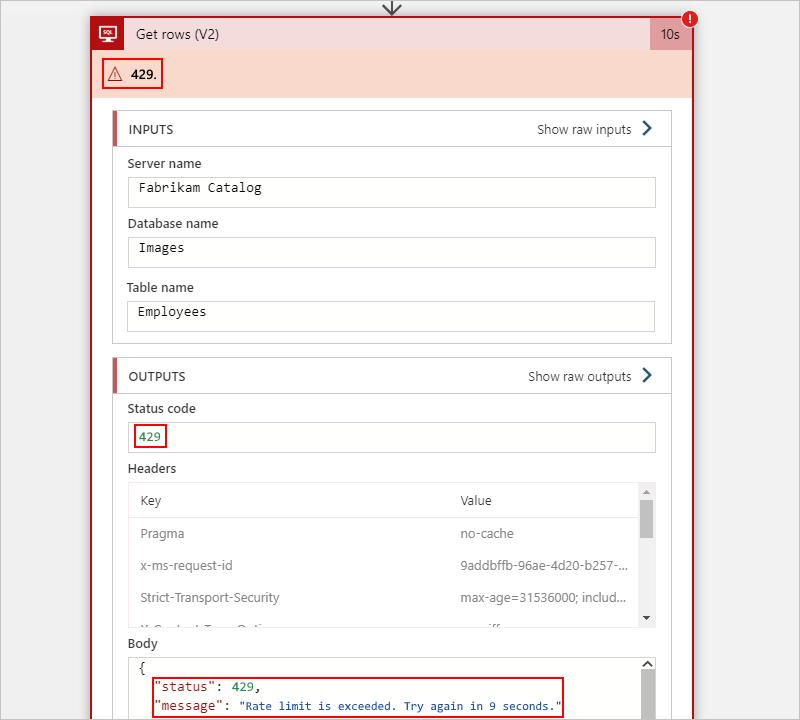
As seções a seguir descrevem os níveis comuns nos quais seu fluxo de trabalho poderá enfrentar uma limitação:
Limitação de recurso de aplicativo lógico
O recurso Aplicativos Lógicos do Azure tem seus próprios limites de taxa de transferência. Portanto, se o seu aplicativo lógico exceder esses limites, o recurso do seu aplicativo lógico ficará limitado, não apenas uma instância ou execução de um fluxo de trabalho específico.
Para detectar eventos de limitação nesse nível, siga as etapas abaixo:
No portal do Azure, abra o recurso de aplicativo lógico de Consumo.
No menu da barra lateral do recurso, em Monitoramento, selecione Métricas.
Na guia Título do Gráfico, selecione Adicionar métrica, que irá adicionar outra barra de métrica ao gráfico.
Na primeira barra de métricas, na lista Métrica, selecione Eventos com Limitação de Ações. Na lista Agregação, selecione Número.
Na segunda barra de métricas, na lista Métrica, selecione Eventos com Limitação de Gatilhos. Na lista Agregação, selecione Número.
O gráfico agora mostra eventos limitados tanto para ações quanto para gatilhos no fluxo de trabalho do seu aplicativo lógico. Para obter mais informações, consulte Exibir métricas de integridade e desempenho do fluxo de trabalho em Aplicativos Lógicos do Azure.
Para lidar com limitações nesse nível, você tem as seguintes opções:
Limitar o número de instâncias de fluxo de trabalho que podem ser executadas ao mesmo tempo.
Por padrão, se a condição de gatilho do fluxo de trabalho for atendida várias vezes simultaneamente, várias instâncias desse gatilho serão disparadas e executadas ao mesmo tempo, ou paralelamente. Cada instância do gatilho será disparada antes que a instância do fluxo de trabalho anterior termine de ser executada.
Embora o número padrão de instâncias de disparo que podem ser executadas simultaneamente seja ilimitado, você pode limitar esse número ativando a configuração de simultaneidade de disparos e, se necessário, selecionar um limite diferente do valor padrão.
Habilite o modo de alta taxa de transferência .
Um fluxo de trabalho de Consumo tem um limite padrão para o número de ações que podem ser executadas ao longo de um intervalo de 5 minutos. Para aumentar esse limite até o número máximo de ações, ative o modo de alta taxa de transferência no recurso do seu aplicativo lógico.
Um fluxo de trabalho Padrão não tem limite para o número de ações que podem ser executadas durante qualquer intervalo.
Desabilitar desagrupamento de matriz ou configuração Dividir em em gatilhos.
Se um gatilho retornar uma matriz para que as ações de fluxo de trabalho restantes sejam processadas, a configuração Dividir do gatilho divide os itens da matriz e inicia uma instância de fluxo de trabalho para cada item da matriz. Esse comportamento dispara várias execuções simultâneas com eficácia até o limite da configuração Dividir.
Para controlar a limitação, desative a configuração Dividir em do gatilho e faça com que o fluxo de trabalho processe a matriz inteira com uma única chamada, em vez de manipular um único item por chamada.
Refatorar ações em diversos fluxos de trabalho menores.
Conforme mencionado anteriormente, um fluxo de trabalho de Consumo de um aplicativo lógico é limitado a um número padrão de ações que podem ser executadas ao longo de um período de 5 minutos. Embora possa aumentar esse limite habilitando o modo de alta taxa de transferência, você também pode pensar em dividir as ações do seu fluxo de trabalho em fluxos de trabalho menores de modo que o número de ações executadas em cada fluxo de trabalho permaneça abaixo do limite. Assim, você reduz a carga de um único fluxo de trabalho e distribui a carga entre diversos fluxos de trabalho. Essa solução funciona melhor para ações que manipulam grandes conjuntos de dados ou geram tantas ações executadas simultaneamente, iterações de loop ou ações dentro de cada iteração de loop que excedem o limite de execução da ação.
Por exemplo, o fluxo de trabalho de Consumo a seguir executa todo o trabalho para obter tabelas de um banco de dados SQL Server e obtém as linhas de cada tabela. O loop For each itera simultaneamente em cada tabela para que a ação Obter linhas retorne as linhas de cada tabela. Com base nas quantidades de dados nessas tabelas, essas ações podem exceder o limite de execuções de ações.
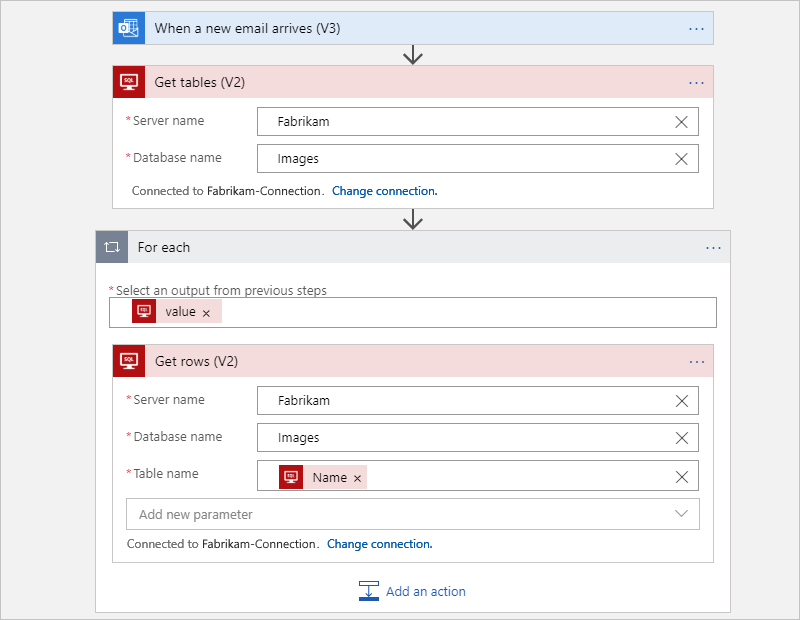
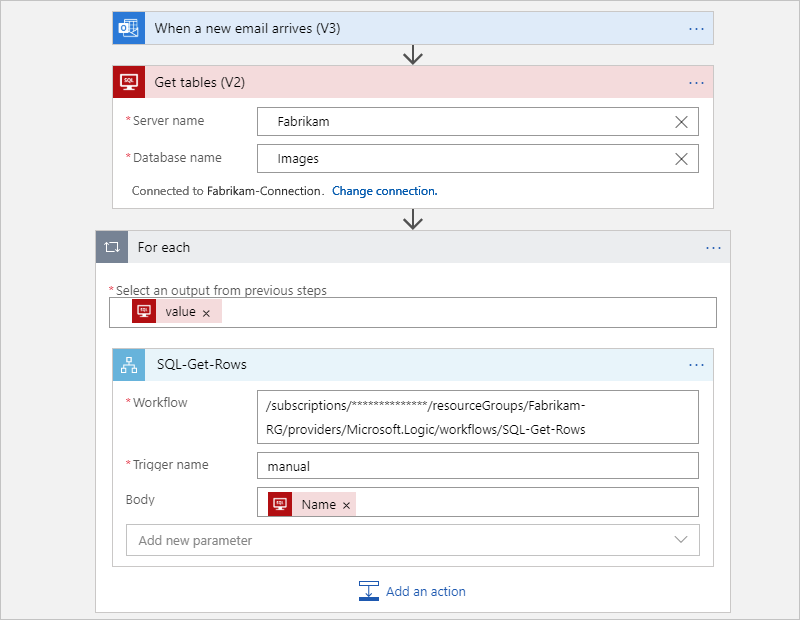
Após a refatoração, o fluxo de trabalho original é dividido em um fluxo de trabalho pai e um fluxo de trabalho filho.
O fluxo de trabalho pai a seguir obtém as tabelas do SQL Server e, em seguida, chama um fluxo de trabalho filho para cada tabela de modo a obter as linhas:
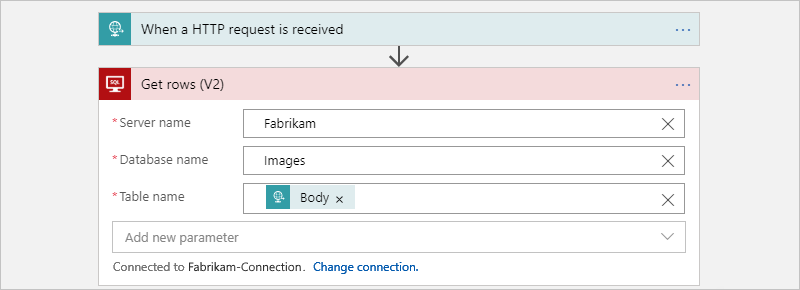
O fluxo de trabalho filho a seguir é chamado pelo fluxo de trabalho pai para obter as linhas de cada tabela:
Limitação do conector
Cada conector tem seus próprios parâmetros de limitação, que podem ser encontrados na página de referência técnica de cada conector. Por exemplo, o conector do Barramento de Serviço do Azure tem um limite de limitação que permite até 6.000 chamadas por minuto, enquanto o conector do SQL Server tem limites de limitação que variam conforme o tipo de operação.
Alguns gatilhos e ações, como HTTP, têm uma política de repetição que você pode personalizar com base nos limites de política de repetição para implementar o tratamento de exceções. Esta política especifica se e com que frequência o gatilho ou a ação tenta novamente executar uma solicitação quando a solicitação original expira ou falha, resultando em uma resposta 408, 429 ou 5xx. Assim, quando a limitação inicia e retorna um erro 429, os Aplicativos Lógicos seguem a política de repetição quando for compatível.
Para saber se um gatilho ou uma ação é compatível com a políticas de repetição, verifique as configurações do disparo (gatilho) ou da ação. Para exibir as tentativas de repetição de um gatilho ou ação, acesse o histórico de execução do fluxo de trabalho do aplicativo lógico, selecione a execução que você deseja examinar e expanda esse gatilho ou ação para exibir detalhes sobre entradas, saídas e todas as tentativas.
O exemplo de fluxo de trabalho de Consumo a seguir mostra onde você pode encontrar essas informações para uma ação em HTTP:
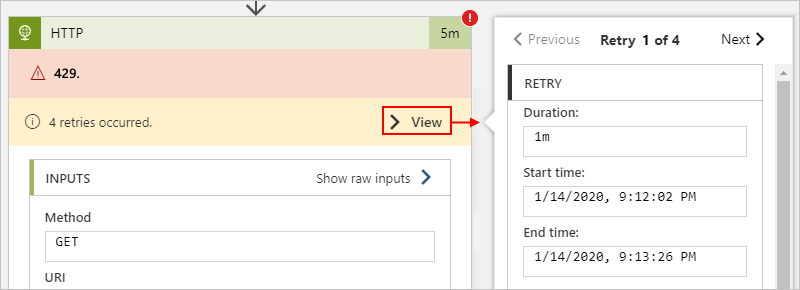
Embora o histórico de repetições forneça informações de erros, você pode ter problemas para diferenciar entre a limitação do conector e alimitação do destino. Nesse caso, revise os detalhes da resposta ou execute alguns cálculos de intervalo de limitação para identificar a origem.
Para fluxos de trabalho de Consumo de um aplicativo lógico no serviço de Aplicativos Lógicos do Azure multilocatário, a limitação ocorre no nível da conexão.
Para lidar com limitações nesse nível, você tem as seguintes opções:
Configurar diversas conexões para uma única ação, de modo que o fluxo de trabalho possa particionar os dados para processamento.
Leve em conta a possibilidade de distribuir a carga de trabalho dividindo as solicitações de uma ação entre várias conexões com o mesmo destino, usando as mesmas credenciais.
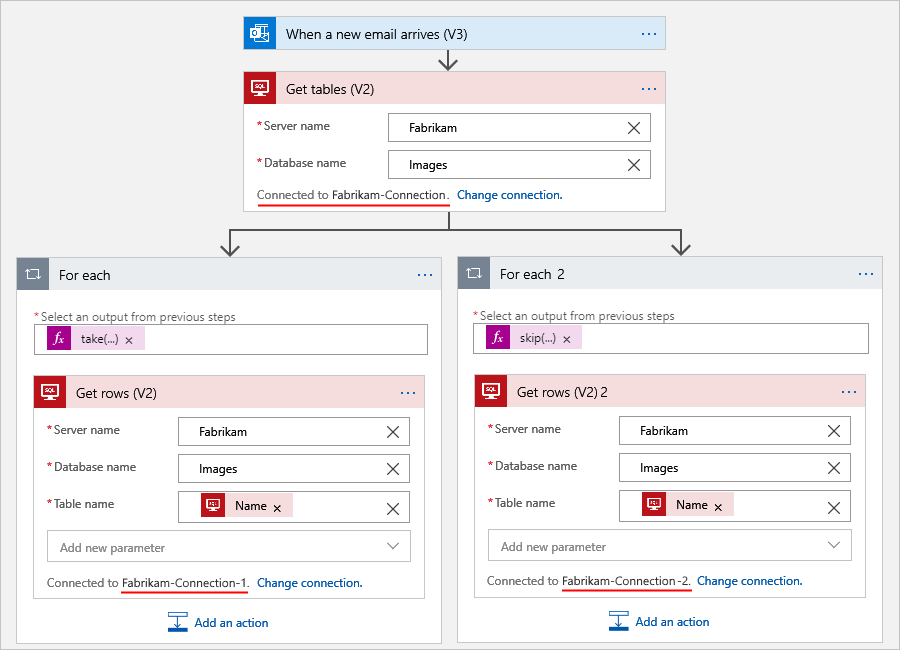
Por exemplo, suponha que seu fluxo de trabalho obtenha tabelas de um banco de dados SQL Server e, em seguida, obtenha as linhas de cada tabela. Com base no número de linhas que precisa processar, você pode usar várias conexões e vários loops For each para dividir o número total de linhas em conjuntos menores para processamento. Esse cenário usa dois loops For each para dividir o número total de linhas na metade. O primeiro loop For each usa uma expressão que obtém a primeira metade. O outro loop For each usa uma expressão diferente que obtém a segunda metade, por exemplo:
Expressão 1: a função
take()obtém o início de uma coleção. Para obter mais informações, confira a funçãotake().@take(collection-or-array-name, div(length(collection-or-array-name), 2))Expressão 2: a função
skip()remove o início de uma coleção e retorna todos os outros itens. Para obter mais informações, confira a funçãoskip().@skip(collection-or-array-name, div(length(collection-or-array-name), 2))O exemplo de fluxo de trabalho de Consumo a seguir mostra como você pode usar essas expressões:
Configure uma conexão diferente para cada ação.
Pense em se é possível distribuir a carga de trabalho propagando as solicitações de cada ação por meio de sua própria conexão, mesmo quando as ações se conectam ao mesmo serviço ou sistema e usam as mesmas credenciais.
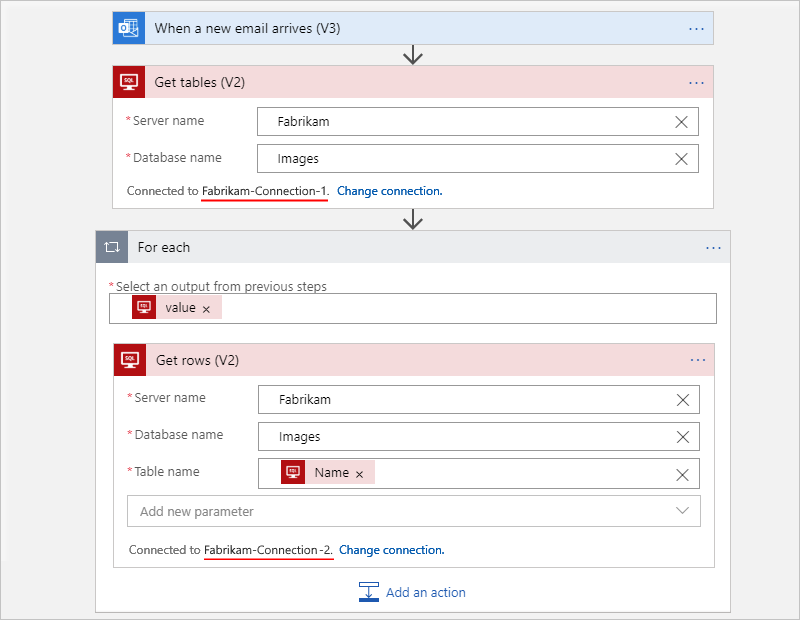
Por exemplo, suponha que seu fluxo de trabalho obtenha tabelas de um banco de dados SQL Server e obtenha as linhas de cada tabela. Você pode usar conexões separadas para que a ação Obter tabelas use uma conexão, enquanto a ação Obter linhas usa outra conexão.
O exemplo a seguir mostra um fluxo de trabalho de Consumo que cria e utiliza uma conexão diferente para cada ação:
Altere a simultaneidade ou o paralelismo de um loop For each.
Por padrão, as iterações de For each loop ocorrem ao mesmo tempo até o limite de concorrência. Se você tiver uma conexão que está sendo limitada dentro de um loop Para cada, poderá reduzir o número de iterações do loop que são executadas em paralelo. Para saber mais, confira a seguinte documentação:
Para cada loop - altere a simultaneidade ou execute sequencialmente
Esquema da Linguagem de Definição de Fluxo de Trabalho – loops Para cada
Esquema da Linguagem de Definição de Fluxo de Trabalho – Alterar a simultaneidade do loop Para cada
Esquema de Linguagem de Definição de Fluxo de Trabalho – Executar For Each loops sequencialmente
Limitação do serviço ou sistema de destino
Embora um conector tenha seus próprios limites, o serviço ou o sistema de destino que é chamado pelo conector também pode ter limites. Por exemplo, algumas APIs do Microsoft Exchange Server têm limites mais rígidos do que o conector do Outlook do Office 365.
Por padrão, as instâncias de um fluxo de trabalho de um aplicativo lógico e quaisquer loops ou ramificações dentro dessas instâncias são executados paralelamente. Esse comportamento significa que várias instâncias podem chamar o mesmo ponto de extremidade ao mesmo tempo. Cada instância não sabe da existência da outra, então tentativas de repetir ações com falha podem criar condições de corrida em que várias chamadas tentam ser executadas ao mesmo tempo, mas para terem sucesso, essas chamadas devem chegar ao serviço ou sistema de destino antes que a limitação comece a acontecer.
Por exemplo, suponha que você tenha uma matriz com 100 itens. Você usa um loop Para cada para iterar pela matriz e ativar o controle de simultaneidade do loop para que possa restringir o número de iterações paralelas a 20 ou ao limite padrão atual. Dentro desse loop, uma ação insere um item da matriz em um banco de dados SQL Server que permite apenas 15 chamadas por segundo. Esse cenário resulta em um problema de limitação porque uma lista de pendências acumula as tentativas e nunca consegue ser executada.
A tabela a seguir descreve a linha do tempo do que acontece no loop quando o intervalo de repetição da ação é de 1 segundo:
| Point-in-time | Número de ações executadas | Número de ações com falha | Número de tentativas ainda pendentes |
|---|---|---|---|
| T + 0 segundos | 20 entradas | 5 falhas, devido ao limite do SQL | 5 tentativas |
| T + 0,5 segundos | 15 entradas, devido às 5 tentativas anteriores aguardando | Todos os 15 falham, devido ao limite de SQL anterior ainda em vigor para outros 0,5 segundos | 20 tentativas (5 anteriores + 15 novas) |
| T + 1 segundo | 20 entradas | 5 falhas mais 20 tentativas anteriores, devido ao limite do SQL | 25 tentativas (20 anteriores + 5 novas) |
Para lidar com limitações nesse nível, você tem as seguintes opções:
Criar fluxos de trabalho individuais de forma que cada um lide com uma única operação.
Continuando com o exemplo do cenário do SQL Server nesta seção, você pode criar um fluxo de trabalho que coloca itens da matriz em uma fila de espera, como uma fila de espera do Barramento de Serviço do Azure. Em seguida você cria outro fluxo de trabalho que realiza apenas a operação de inserção para cada item da fila em questão. Dessa forma, apenas uma instância do fluxo de trabalho é executada em qualquer momento específico, o que conclui a operação de inserção e passa para o próximo item na fila, ou a instância obtém erros 429, mas não repete tentativas improdutivas.
Criar um fluxo de trabalho pai que chame um fluxo de trabalho filho ou aninhado para cada ação. Se o pai precisar chamar diferentes fluxos de trabalho filho com base no resultado do pai, você pode usar uma ação de condição ou uma ação de comutador que determina qual fluxo de trabalho chamar. Esse padrão pode ajudar a reduzir o número de chamadas ou operações.
Por exemplo, suponha que você tenha dois fluxos de trabalho, cada um com um gatilho de sondagem que verifica sua conta de email a cada minuto para um assunto específico, como "Sucesso" ou "Falha". Essa configuração resulta em 120 chamadas por hora. Em vez disso, se você criar um único fluxo de trabalho pai que fique sondando a cada minuto, mas chama um fluxo de trabalho filho que é executado independentemente de o assunto ser um "Sucesso" ou "Falha", você corta o número de verificações de sondagem pela metade, ou 60 nesse caso.
Configurar o processamento em lote (somente para fluxos de trabalho de consumo).
Se o serviço de destino permitir operações em lote, você pode resolver a limitação processando itens em grupos ou lotes, em vez de individualmente. Para implementar a solução de processamento em lote, você cria um fluxo de trabalho de aplicativo lógico do receptor em lote e um fluxo de trabalho do aplicativo lógico do remetente em lote . O remetente do lote coleta mensagens ou itens até que os critérios especificados sejam atendidos e, em seguida, envia essas mensagens ou itens em um único agrupamento. O destinatário do lote aceita esse grupo e processa essas mensagens ou itens. Para obter mais informações, consulte Enviar, receber e enviar mensagens de processo em lote nos Aplicativos Lógicos do Azure.
Use as versões de webhook para gatilhos e ações, em vez de versões de sondagem.
Por quê? Um gatilho de sondagem continua a verificar o serviço ou o sistema de destino em intervalos específicos. Um intervalo muito frequente, como a cada segundo, pode criar problemas de limitação. No entanto, um gatilho ou ação de webhook, como webhook HTTP, cria apenas uma única chamada para o serviço ou sistema de destino, o que acontece no momento da assinatura e solicita que o destino notifique o gatilho ou a ação somente quando um evento acontece. Dessa forma, o gatilho ou a ação não precisa verificar continuamente o destino.
Portanto, se o serviço ou o sistema de destino for compatível com webhooks ou fornecer um conector que tenha uma versão de webhook, essa opção é melhor do que usar a versão de sondagem. Para identificar gatilhos e ações de webhook, confirme se eles têm o
ApiConnectionWebhooktipo ou se eles não exigem que você especifique uma recorrência. Para obter mais informações, veja gatilho ApiConnectionWebhook e ação ApiConnectionWebhook.