Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a: Aplicativos Lógicos do Azure (Consumo + Standard)
A maneira como qualquer arquitetura de integração lida adequadamente com o tempo de inatividade ou problemas causados por sistemas dependentes pode representar um desafio. Para ajudar você a criar integrações robustas e resilientes que lidem com problemas e falhas, Aplicativos Lógicos do Azure oferece uma experiência de primeira classe para lidar com erros e exceções.
Políticas de repetição
Para a exceção mais básica e o tratamento de erros, você poderá usar a política de repetição se essa funcionalidade existir em um gatilho ou ação, como a ação HTTP. Se a solicitação original do gatilho ou da ação atingir o tempo limite ou falhar, resultando em uma resposta 408, 429 ou 5xx, a política de repetição especificará que o gatilho ou a ação reenviará a solicitação por configurações de política.
Limites da política de repetição
Para saber mais sobre políticas de repetição, configurações, limites e outras opções, revise os Limites de política de repetição.
Tipo de política de repetição
As operações de conector que dão suporte a políticas de repetição usam a política Padrão, a menos que você selecione uma política de repetição diferente.
| Política de repetição | Descrição |
|---|---|
| Padrão | Para a maioria das operações, a política de repetição Padrão é uma política de intervalo exponencial que envia até 4 tentativas, em intervalos exponencialmente aumentados. Esses intervalos obedecem a uma escala de aumento de 7,5 segundos, mas são limitados entre 5 e 45 segundos. Várias operações usam uma política de repetição Padrão diferente, como uma política de intervalo fixo. Para obter mais informações, examine o Tipo de política padrão. |
| Nenhuma | Não reenvie o pedido. Para obter mais informações, examine Nenhum – Nenhuma política de repetição. |
| Intervalo exponencial | Essa política aguarda um intervalo aleatório, selecionado de um intervalo em crescimento exponencial antes de enviar a próxima solicitação. Para obter mais informações, examine o tipo de política de intervalo exponencial. |
| Intervalo fixo | Essa política aguarda o intervalo especificado antes de enviar a próxima solicitação. Para obter mais informações, examine o tipo de política intervalo fixo. |
Alterar o tipo de política de repetição no designer
Abra o recurso de aplicativo lógico no portal do Azure.
Na barra lateral do recurso, siga estas etapas para abrir o designer de fluxo de trabalho, com base em seu aplicativo lógico:
Consumo: em Ferramentas de desenvolvimento, selecione o designer para abrir seu fluxo de trabalho.
Standard
Em Fluxos de Trabalho, selecione Fluxos de Trabalho.
Na página Fluxos de Trabalho , selecione seu fluxo de trabalho.
Em Ferramentas, selecione o designer para abrir seu fluxo de trabalho.
No gatilho ou ação em que você deseja alterar o tipo de política de repetição, siga estas etapas para abrir as configurações:
No designer, selecione a operação.
No painel de informações da operação, selecione Configurações.
Em Rede, em Política de Repetição, selecione o tipo de política desejado.
Alterar o tipo de política de repetição no editor de exibição de código
Confirme se o gatilho ou a ação dá suporte a políticas de repetição concluindo as etapas anteriores no designer.
Abra o fluxo de trabalho do aplicativo lógico no editor de exibição de código.
Na definição de gatilho ou ação, adicione o
retryPolicyobjeto JSON ao objeto do gatilho ou dainputsação. Se nenhumretryPolicyobjeto existir, o gatilho ou ação usará adefaultpolítica de repetição."inputs": { <...>, "retryPolicy": { "type": "<retry-policy-type>", // The following properties apply to specific retry policies. "count": <retry-attempts>, "interval": "<retry-interval>", "maximumInterval": "<maximum-interval>", "minimumInterval": "<minimum-interval>" }, <...> }, "runAfter": {}Necessário
Propriedade Valor Tipo Descrição type<tipo-de-política-de-repetição> String O tipo de política de repetição que você deseja usar: default,none,fixedouexponentialcount<tentativas-de-repetição> Integer Para os tipos de política fixedeexponential, o número de tentativas de repetição, que é um valor de 1 a 90. Para saber mais, revise Intervalo Fixo e Intervalo Exponencial.interval<intervalo-de-repetição> String Para os tipos de política fixedeexponential, o valor do intervalo de repetição no formato ISO 8601. Para a políticaexponential, você também pode especificar intervalos máximos e mínimos opcionais. Para saber mais, revise Intervalo Fixo e Intervalo Exponencial.
Consumo: cinco segundos (PT5S) a um dia (P1D).
Padrão: para fluxos de trabalho com estado, cinco segundos (PT5S) a um dia (P1D). Para fluxos de trabalho sem estado, um segundo (PT1S) a um minuto (PT1M).Opcional
Propriedade Valor Tipo Descrição maximumInterval<intervalo-máximo> String Para a política exponential, o maior intervalo para o intervalo selecionado aleatoriamente no formato ISO 8601. O valor padrão é de um dia (P1D). Para saber mais, revise o Intervalo Exponencial.minimumInterval<intervalo-mínimo> String Para a política exponential, o menor intervalo para o intervalo selecionado aleatoriamente no formato ISO 8601. O valor padrão é de cinco segundos (PT5S). Para saber mais, revise o Intervalo Exponencial.
Política de repetição padrão
As operações de conector que dão suporte a políticas de repetição usam a política Padrão, a menos que você selecione uma política de repetição diferente. Para a maioria das operações, a política de repetição Padrão é uma política de intervalo exponencial que envia até 4 tentativas, em intervalos exponencialmente aumentados. Esses intervalos obedecem a uma escala de aumento de 7,5 segundos, mas são limitados entre 5 e 45 segundos. Várias operações usam uma política de repetição Padrão diferente, como uma política de intervalo fixo.
Na sua definição de fluxo de trabalho, a definição do gatilho ou da ação não define explicitamente a política padrão, mas o exemplo a seguir mostra como a política de repetição padrão se comporta para a ação HTTP:
"HTTP": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "http://myAPIendpoint/api/action",
"retryPolicy" : {
"type": "exponential",
"interval": "PT7S",
"count": 4,
"minimumInterval": "PT5S",
"maximumInterval": "PT1H"
}
},
"runAfter": {}
}
Nenhum – Nenhuma política de repetição
Para especificar que a ação ou gatilho não tentará repetir solicitações com falha, defina o <tipo-de-política-de-repetição> como none.
Política de repetição de intervalo fixa
Para especificar que a ação ou o acionador aguarda o intervalo especificado antes de enviar a próxima solicitação, defina <tipo-de-política-de-repetição> como fixed.
Exemplo
Essa política de repetição tenta receber as últimas notícias mais duas vezes após a primeira solicitação com falha, com um atraso de 30 segundos entre cada tentativa:
"Get_latest_news": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "https://mynews.example.com/latest",
"retryPolicy": {
"type": "fixed",
"interval": "PT30S",
"count": 2
}
}
}
Política de repetição de intervalo exponencial
A política de repetição de intervalo exponencial especifica que o gatilho ou a ação aguarda um intervalo aleatório antes de enviar a próxima solicitação. O intervalo aleatório é selecionado de um intervalo que cresce exponencialmente. Opcionalmente, você pode substituir os intervalos mínimo e máximo padrão especificando seus próprios intervalos mínimo e máximo, com base no seu fluxo de trabalho de aplicativo lógico Padrão ou de Consumo.
| Nome | Limite de consumo | Limite padrão | Observações |
|---|---|---|---|
| Atraso máximo | Padrão: 1 dia | Padrão: 1 hora | Para alterar o limite padrão em um fluxo de trabalho do aplicativo lógico de Consumo, use o parâmetro de política de repetição. Para alterar o limite padrão em um fluxo de trabalho de aplicativo lógico Padrão, revise Editar configurações de host e aplicativo para aplicativos lógicos em Aplicativos Lógicos do Azure de locatário único. |
| Atraso mínimo | Padrão: 5s | Padrão: 5s | Para alterar o limite padrão em um fluxo de trabalho do aplicativo lógico de Consumo, use o parâmetro de política de repetição. Para alterar o limite padrão em um fluxo de trabalho de aplicativo lógico Padrão, revise Editar configurações de host e aplicativo para aplicativos lógicos em Aplicativos Lógicos do Azure de locatário único. |
Intervalos de variável aleatória
Para a política de repetição de intervalo exponencial, a tabela a seguir mostra o algoritmo geral que Aplicativos Lógicos do Azure usa para gerar uma variável aleatória uniforme no intervalo especificado para cada repetição. O intervalo especificado pode chegar até o número de repetições.
| Número de Repetições | Intervalo mínimo | Intervalo máximo |
|---|---|---|
| 1 | max(0, <intervalo-mínimo>) | min(intervalo, <intervalo-máximo>) |
| 2 | max(intervalo, <intervalo-mínimo>) | min(2 * intervalo, <intervalo-máximo>) |
| 3 | max(2 * intervalo, <intervalo-mínimo>) | min (4 * intervalo, <intervalo-máximo>) |
| 4 | max(4 * intervalo, <intervalo-mínimo>) | min (8 * intervalo, <intervalo-máximo>) |
| .... | .... | .... |
Gerenciar o comportamento "executar após"
Ao adicionar ações no designer de fluxo de trabalho, você declara implicitamente a sequência para executar essas ações. Após o término da execução da ação, essa ação é marcada com um status como Êxito, Falha, Ignorada ou Tempo esgotado. Em outras palavras, a ação predecessora deve primeiro terminar com qualquer um dos status permitidos antes que a ação sucessora possa ser executada.
Por padrão, uma ação que você adiciona ao designer é executada somente se a ação anterior for concluída com o status bem-sucedido . Este comportamento 'executar após' especifica precisamente a ordem de execução de ações em um fluxo de trabalho.
No designer, você pode alterar o comportamento padrão "executar após" para uma ação editando a configuração Executar após a ação. Essa configuração está disponível apenas em ações subsequentes que seguem a primeira ação em um fluxo de trabalho. A primeira ação em um fluxo de trabalho sempre é executada depois que o gatilho é executado com êxito. Portanto, a configuração Executar após não está disponível e não se aplica à primeira ação.
Na definição JSON subjacente de uma ação, a configuração Executar após é a mesma que a da runAfter propriedade. Essa propriedade especifica uma ou mais ações predecessoras que devem ser concluídas primeiro com os status permitidos específicos antes que a ação sucessora possa ser executada. A runAfter propriedade é um objeto JSON que fornece flexibilidade, permitindo que você especifique todas as ações predecessoras que devem ser concluídas antes da execução da ação sucessora. Esse objeto também define uma matriz de status aceitáveis.
Por exemplo, para que uma ação seja executada após a ação A ser bem-sucedida e também após a ação B ser bem-sucedida ou falhar quando você estiver trabalhando na definição JSON de uma ação, configure a seguinte runAfter propriedade:
{
// Other parts in action definition
"runAfter": {
"Action A": ["Succeeded"],
"Action B": ["Succeeded", "Failed"]
}
}
Comportamento "Executar após" para tratamento de erros
Quando uma ação gera um erro ou exceção sem tratamento, a ação é marcada com Falha e qualquer ação sucessora é marcada como Ignorada. Se esse comportamento ocorrer para uma ação que tenha ramificações paralelas, o mecanismo de Aplicativos Lógicos do Azure seguirá as outras ramificações para determinar o status de conclusão. Por exemplo, se uma ramificação terminar com uma ação Ignorada, o status de conclusão da ramificação será baseado no status antecessor da ação ignorada. Após a execução do fluxo de trabalho, o mecanismo determina o status de toda a execução, avaliando os status de todas as ramificações. Se qualquer ramificação terminar em falha, toda a execução do fluxo de trabalho será marcada com Falha.

Para garantir que uma ação ainda possa ser executada apesar do status da sua antecessora, altere o comportamento de "executar após" de uma ação para lidar com os status malsucedidos da antecessora. Dessa forma, a ação é executada quando o status da antecessora é Êxito, Falha, Ignorada, Tempo esgotado ou todos esses status.
Por exemplo, para executar a ação Enviar um email do Office 365 Outlook depois que a ação antecessora Adicionar uma linha a uma tabela Excel Online for marcada como Falha, em vez de Êxito, altere o comportamento "executar após" usando o designer ou o editor de exibição de código.
Alterar o comportamento de "executar após" no designer
Abra o recurso de aplicativo lógico no portal do Azure.
Na barra lateral do recurso, siga estas etapas para abrir o designer de fluxo de trabalho, com base em seu aplicativo lógico:
Consumo: em Ferramentas de desenvolvimento, selecione o designer para abrir seu fluxo de trabalho.
Standard
Na barra lateral do recurso, em Fluxos de Trabalho, selecione Fluxos de Trabalho.
Na página Fluxos de Trabalho , selecione seu fluxo de trabalho.
Em Ferramentas, selecione o designer para abrir seu fluxo de trabalho.
No gatilho ou na ação em que você deseja alterar o comportamento "executar após", siga estas etapas para abrir as configurações da operação:
No designer, selecione a operação.
No painel de informações da operação, selecione Configurações.
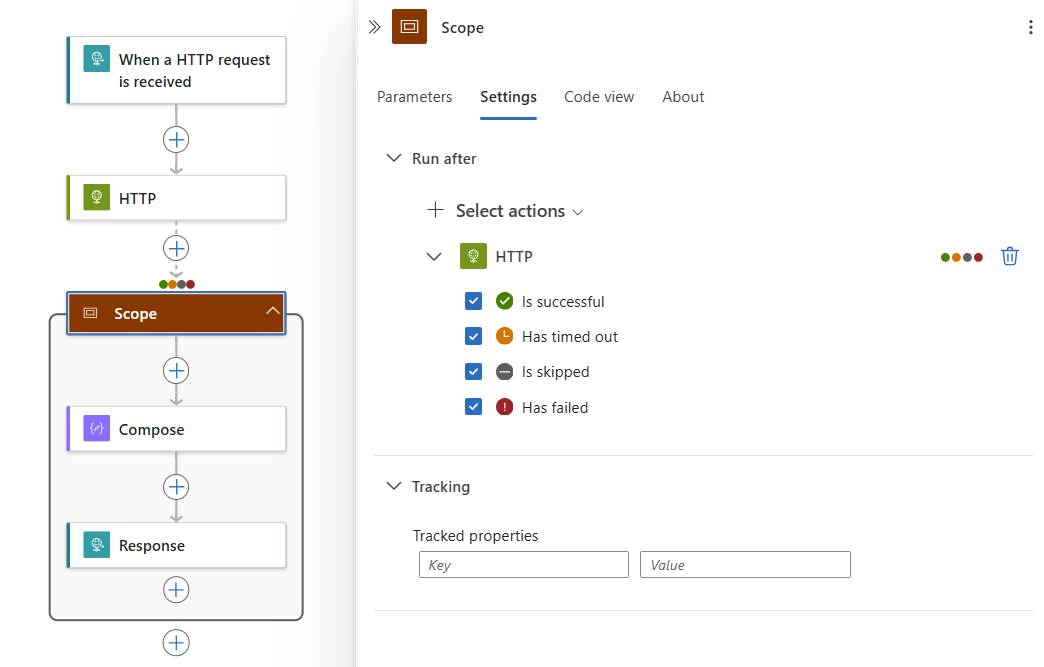
A seção Executar após contém a lista Select actions, que mostra as operações predecessoras disponíveis para a operação atualmente selecionada, por exemplo:

Na lista Selecionar ações, expanda a operação predecessora atual, que é HTTP neste exemplo:

Por padrão, o status "executar após" é definido como Bem-sucedido. Esse valor significa que a operação predecessora deve ser concluída com êxito antes que a ação atual possa ser executada.

Para alterar o comportamento de "executar após" para os status desejados, selecione esses status.
O exemplo a seguir seleciona Falha.
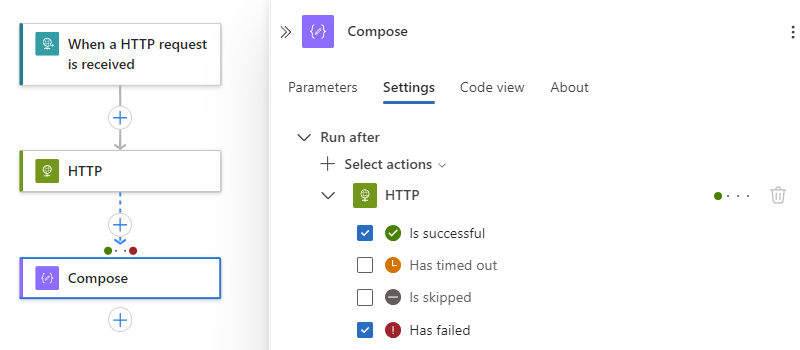
Para especificar que a operação atual é executada somente quando a ação predecessora for concluída com o status Obteve falha, Foi ignorada ou Atingiu o tempo limite, selecione esses status e desmarque o status padrão, por exemplo:
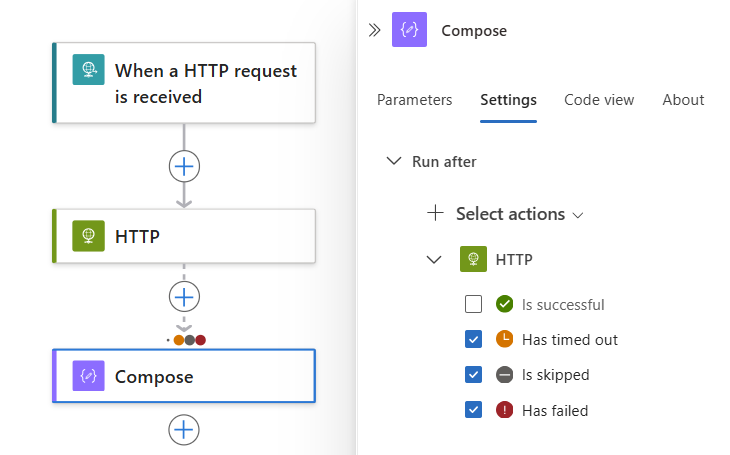
Observação
Antes de limpar o status padrão, certifique-se de selecionar primeiro outro status. Você sempre deve ter pelo menos um status selecionado.
Para exigir que várias operações predecessoras sejam executadas e concluídas, cada uma com seus próprios status de "executar após", siga estas etapas:
Abra a lista Selecionar ações e selecione as operações predecessoras desejadas.
Selecione os status de "executar posteriormente" para cada operação.
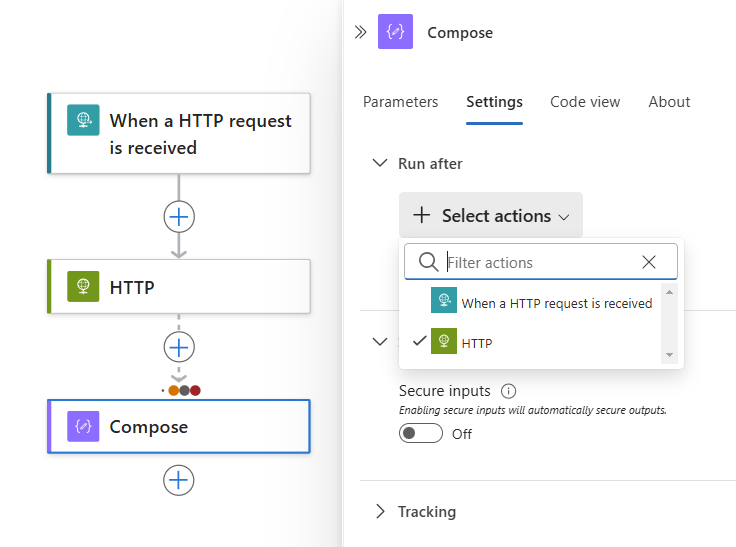
Quando terminar, feche o painel de informações da operação.






Alterar o comportamento de "executar após" no editor de exibição de código
Na barra lateral do recurso, siga estas etapas para abrir o editor de exibição de código, com base em seu aplicativo lógico:
Consumo: em Ferramentas de desenvolvimento, selecione o modo de exibição de código para abrir o fluxo de trabalho no editor JSON.
Standard
Em Fluxos de Trabalho, selecione Fluxos de Trabalho.
Na página Fluxos de Trabalho , selecione seu fluxo de trabalho.
Em Ferramentas, selecione a exibição de código para abrir seu fluxo de trabalho no editor JSON.
Na definição de JSON da ação, edite a propriedade
runAfter, que tem esta sintaxe:"<action-name>": { "inputs": { "<action-specific-inputs>" }, "runAfter": { "<preceding-action>": [ "Succeeded" ] }, "type": "<action-type>" }Para este exemplo, altere a
runAfterpropriedade deSucceededparaFailed:"Send_an_email_(V2)": { "inputs": { "body": { "Body": "<p>Failed to add row to table: @{body('Add_a_row_into_a_table')?['Terms']}</p>", "Subject": "Add row to table failed: @{body('Add_a_row_into_a_table')?['Terms']}", "To": "Sophia.Owen@fabrikam.com" }, "host": { "connection": { "name": "@parameters('$connections')['office365']['connectionId']" } }, "method": "post", "path": "/v2/Mail" }, "runAfter": { "Add_a_row_into_a_table": [ "Failed" ] }, "type": "ApiConnection" }Para especificar que a ação seja executada se a ação predecessora estiver marcada como
Failed,SkippedouTimedOut, adicione os outros status:"runAfter": { "Add_a_row_into_a_table": [ "Failed", "Skipped", "TimedOut" ] },
Avaliar ações com escopos e seus resultados
Assim como na execução de etapas depois de ações individuais com a propriedade "executar após", você pode agrupar ações dentro de um escopo. Você pode usar escopos quando quiser agrupar ações logicamente, avaliar o status agregado do escopo e executar ações com base no status. Depois que todas as ações em um escopo concluem a execução, o próprio escopo também obtém seu próprio status.
Para verificar o status de um escopo, é possível usar os mesmos critérios utilizados para verificar o status de execução de um aplicativo lógico, como com Êxito, Falha e assim por diante.
Por padrão, quando todas as ações do escopo são bem-sucedidas, o status do escopo é marcado como com Êxito. Se a ação final em um escopo for marcada como Falha ou Abortada, o status do escopo fica marcado como Falha.
Para capturar exceções em um escopo com Falha e executar ações que lidam com esses erros, você pode usar a configuração "executar após" com escopo Falha. Dessa maneira, se quaisquer ações no escopo falharem e você usar a configuração "executar após" para esse escopo, será possível criar uma ação única para capturar falhas.
Para limites nos escopos, consulte Limites e configurações.
Configurar um escopo com "executar após" para tratamento de exceção
No portal do Azure, abra o recurso de aplicativo lógico e o fluxo de trabalho no designer.
Seu fluxo de trabalho já deve ter um gatilho que inicie o fluxo de trabalho.
No designer, siga estas etapas genéricas para adicionar uma ação de controle chamada Escopo ao fluxo de trabalho.
Na ação Escopo, siga estas etapas genéricas para adicionar ações a serem executadas, por exemplo:
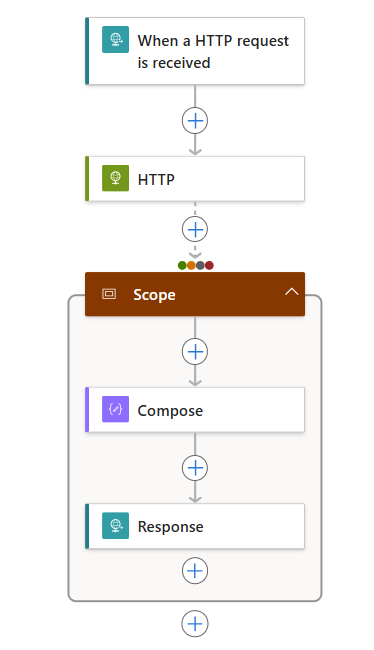
A lista a seguir mostra algumas ações de exemplo que você pode incluir dentro de uma ação Escopo:
- Obter dados de uma API.
- Processe os dados.
- Salve os dados em um banco de dados.
Agora defina as regras de "executar após" para execução das ações no escopo.
No designer, selecione o título Escopo. Quando o painel de informações do escopo for aberto, selecione Configurações.
Se você tiver mais de uma ação anterior no fluxo de trabalho, na lista Selecionar ações, selecione a ação após a qual deseja executar as ações com escopo.
Para a ação selecionada, selecione todos os status de ação que podem executar as ações com escopo.
Em outras palavras, qualquer um dos status escolhidos resultantes da ação selecionada faz com que as ações no escopo sejam executadas.
No exemplo a seguir, as ações com escopo são executadas após a conclusão da ação HTTP com qualquer um dos status selecionados:
Obter o contexto e os resultados de falhas
Embora seja útil detectar falhas de um escopo, convém ter mais contexto para ajudar você a entender exatamente quais ações falharam, além de quaisquer erros ou códigos de status. A função result() retorna os resultados das ações de nível superior em uma ação com escopo. Essa função aceita o nome do escopo como um único parâmetro e retorna uma matriz com os resultados dessas ações de nível superior. Esses objetos de ação têm os mesmos atributos que os atributos retornados pela função actions(), como hora de início, hora de término, status, entradas, IDs de correlação e saídas da ação.
Observação
A função result() retorna os resultados somente de ações de nível superior e não de ações aninhadas mais profundas, como ações de alternância ou condição.
Para obter o contexto sobre as ações que falharam em um escopo, você pode usar a expressão @result() com o nome do escopo e a configuração "executar após". Para filtrar a matriz retornada para ações com o status Falha, você pode adicionar a ação Filtrar matriz. Para executar uma ação para uma ação retornada com falha, pegue a matriz filtrada retornada e use um loop Para cada .
O exemplo de solicitação JSON a seguir envia uma solicitação HTTP POST com o corpo da resposta para quaisquer ações que falharam na ação de escopo chamada My_Scope. Uma explicação detalhada segue o exemplo.
"Filter_array": {
"type": "Query",
"inputs": {
"from": "@result('My_Scope')",
"where": "@equals(item()['status'], 'Failed')"
},
"runAfter": {
"My_Scope": [
"Failed"
]
}
},
"For_each": {
"type": "foreach",
"actions": {
"Log_exception": {
"type": "Http",
"inputs": {
"method": "POST",
"body": "@item()['outputs']['body']",
"headers": {
"x-failed-action-name": "@item()['name']",
"x-failed-tracking-id": "@item()['clientTrackingId']"
},
"uri": "http://requestb.in/"
},
"runAfter": {}
}
},
"foreach": "@body('Filter_array')",
"runAfter": {
"Filter_array": [
"Succeeded"
]
}
}
As etapas a seguir descrevem o que acontece neste exemplo:
Para obter o resultado de todas as ações dentro de My_Scope, a ação Filtrar matriz usa essa expressão de filtro:
@result('My_Scope')A condição de Matriz de Filtro é qualquer item
@result()que tenha um status igual aFailed. Essa condição filtra a matriz que tem todos os resultados de ação My_Scope para uma matriz com apenas os resultados de ação com falha.Executar uma ação de loop
For_eachpra cada saída filtrada da matriz. Esta etapa executa uma ação para cada resultado de ação com falha que foi filtrado anteriormente.Se uma única ação no escopo tiver falhado, as ações em
For_eachserão executadas apenas uma vez. Várias ações com falha causam uma ação por falha.Envie um POST HTTP no
For_eachitem do corpo de resposta do item, que é a expressão@item()['outputs']['body'].A forma do item
@result()é a mesma que a forma@actions()e pode ser analisada da mesma maneira.Inclua dois cabeçalhos personalizados com o nome da ação com falha (
@item()['name']) e o ID de acompanhamento do cliente de execução com falha (@item()['clientTrackingId']).
Para referência, aqui está um exemplo de um único item @result(), mostrando as propriedades name, body e clientTrackingId que são analisadas no exemplo anterior. Fora de uma ação For_each, @result() retorna uma matriz desses objetos.
{
"name": "Example_Action_That_Failed",
"inputs": {
"uri": "https://myfailedaction.azurewebsites.net",
"method": "POST"
},
"outputs": {
"statusCode": 404,
"headers": {
"Date": "Thu, 11 Aug 2016 03:18:18 GMT",
"Server": "Microsoft-IIS/8.0",
"X-Powered-By": "ASP.NET",
"Content-Length": "68",
"Content-Type": "application/json"
},
"body": {
"code": "ResourceNotFound",
"message": "/docs/folder-name/resource-name does not exist"
}
},
"startTime": "2016-08-11T03:18:19.7755341Z",
"endTime": "2016-08-11T03:18:20.2598835Z",
"trackingId": "bdd82e28-ba2c-4160-a700-e3a8f1a38e22",
"clientTrackingId": "08587307213861835591296330354",
"code": "NotFound",
"status": "Failed"
}
Para executar diferentes padrões de tratamento de exceções, você pode usar as expressões descritas anteriormente neste artigo. Você pode optar por executar uma única ação de tratamento de exceções fora do escopo que aceita toda a matriz filtrada de falhas e remover a For_eachação. Adicionalmente, é possível incluir outras propriedades úteis da resposta \@result(), conforme descrito anteriormente.
Configurar os logs do Azure Monitor
Os padrões anteriores são maneiras úteis de lidar com erros e exceções que ocorrem dentro de uma execução. No entanto, você também pode identificar e responder a erros que ocorrem independentemente da execução. Para avaliar os status de execução, você pode monitorar os logs e as métricas de suas execuções ou publicá-los em qualquer ferramenta de monitoramento de sua preferência.
Por exemplo, o Azure Monitor fornece uma maneira simplificada de enviar todos os eventos de fluxo de trabalho, incluindo todos os status de execução e ação, para um destino. Você pode configurar alertas para métricas e limites específicos no Azure Monitor. Você também pode enviar eventos de fluxo de trabalho para um espaço de trabalho do Log Analytics ou uma conta de armazenamento do Azure. Ou você pode transmitir todos os eventos por meio dos Hubs de Eventos do Azure para o Azure Stream Analytics. No Stream Analytics é possível gravar consultas dinâmicas com base em quaisquer anomalias, médias ou falhas dos logs de diagnóstico. Você pode usar o Stream Analytics para enviar informações a outras fontes de dados, como filas, tópicos, SQL, Azure Cosmos DB ou Power BI.
Para obter mais informações, consulte Configurar logs do Azure Monitor e coletar dados de diagnóstico para aplicativos lógicos do Azure.