Varredura e seleção do modelo para previsão no AutoML
Este artigo se concentra em como o AutoML pesquisa e seleciona modelos de previsão. Consulte o artigo de visão geral de métodos para informações mais gerais sobre a metodologia de previsão no AutoML. Instruções e exemplos de modelos de previsão de treinamento em AutoML podem ser encontrados em nosso artigo configurar o AutoML para previsão de série temporal.
Varredura do modelo
A tarefa central do AutoML é treinar e avaliar vários modelos e escolher o melhor em relação à métrica primária fornecida. A palavra "modelo" aqui refere-se à classe de modelo - como ARIMA ou Random Forest - e às configurações específicas do hiperparâmetro que distinguem modelos dentro de uma classe. Por exemplo, ARIMA refere-se a uma classe de modelos que compartilham um modelo matemático e um conjunto de suposições estatísticas. O treinamento ou ajuste de um modelo ARIMA requer uma lista de inteiros positivos que especificam a forma matemática precisa do modelo. Esses são os hiperparâmetros. ARIMA(1, 0, 1) e ARIMA(2, 1, 2) têm a mesma classe, mas hiperparâmetros diferentes e, portanto, podem ser ajustados separadamente com os dados de treinamento e comparados. O AutoML pesquisa, ou varre, em diferentes classes de modelo e em classes variando os hiperparâmetros.
A tabela a seguir mostra os diferentes métodos de varredura de hiperparâmetro que o AutoML usa para classes de modelo diferentes:
| Grupo de classes de modelo | Tipo de modelo | Método de varredura de hiperparâmetro |
|---|---|---|
| Naive, Seasonal Naive, Average, Seasonal Average | Série temporal | Nenhuma varredura na classe devido à simplicidade do modelo |
| Ajuste exponencial, ARIMA(X) | Série temporal | Pesquisa de grade para limpeza na classe |
| Prophet | Regressão | Sem varredura na classe |
| Linear SGD, LARS LASSO, Elastic Net, K Nearest Neighbors, Decision Tree, Random Forest, Extremely Randomized Trees, Gradient Boosted Trees, LightGBM, XGBoost | Regressão | O serviço de recomendação de modelo do AutoML explora dinamicamente os espaços de hiperparâmetro |
| ForecastTCN | Regressão | Lista estática de modelos seguidos de pesquisa aleatória sobre o tamanho da rede, a taxa de abandono e a taxa de aprendizado. |
Para obter uma descrição dos diferentes tipos de modelo, consulte a seção modelos de previsão do artigo Visão geral dos métodos.
A quantidade de varredura que o AutoML faz depende da configuração do trabalho de previsão. Você pode especificar os critérios de interrupção como um limite de tempo ou um limite no número de avaliações ou, da mesma forma, o número de modelos. A lógica de término antecipado pode ser usada em ambos os casos para parar de varrer se a métrica primária não estiver melhorando.
Seleção de modelos
A pesquisa e a seleção do modelo de previsão do AutoML ocorrem nas três fases a seguir:
- Faça uma varredura dos modelos de série temporal e selecione o melhor modelo de cada classe usando métodos de probabilidade penalizados.
- Examine os modelos de regressão e classifique-os, juntamente com os melhores modelos de série temporal da fase 1, de acordo com seus valores de métrica primários de conjuntos de validação.
- Crie um modelo de conjunto com base nos modelos mais bem classificados, calcule sua métrica de validação e classifique-o com os outros modelos.
O modelo com o valor de métrica mais bem classificado no final da fase 3 é designado como o melhor modelo.
Importante
A fase final da seleção de modelo do AutoML sempre calcula as métricas em dados fora da amostra. Ou seja, dados que não foram usados para se ajustar aos modelos. Isso ajuda a evitar o sobreajuste.
O AutoML tem duas configurações de validação: validação cruzada e dados de validação explícitos. No caso de validação cruzada, o AutoML usa a configuração de entrada para criar divisões de dados em dobras de treinamento e validação. A ordem de tempo deve ser preservada nessas divisões. Portanto, o AutoML usa a chamada Validação cruzada de origem sem interrupção, que divide a série em dados de treinamento e validação usando um ponto de tempo de origem. Deslizar a origem no tempo gera as dobras de validação cruzada. Cada dobra de validação contém o próximo horizonte de observações imediatamente após a posição da origem da dobra fornecida. Essa estratégia preserva a integridade dos dados da série temporal e elimina o risco de vazamento de informações.
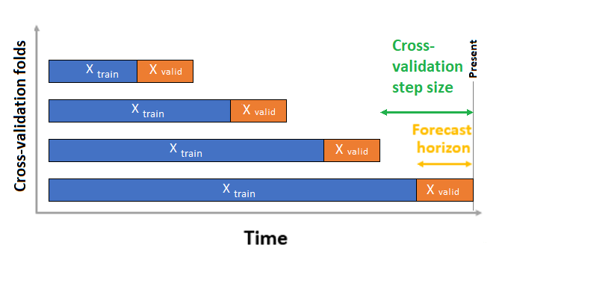
O AutoML segue o procedimento de validação cruzada usual, treinando um modelo separado em cada dobra e média de métricas de validação de todas as dobras.
A validação cruzada para trabalhos de previsão é configurada definindo o número de dobras de validação cruzada e, opcionalmente, o número de períodos de tempo entre duas dobras de validação cruzada consecutivas. Consulte o guia configurações de validação cruzada personalizadas para obter mais informações e um exemplo de configuração da validação cruzada para previsão.
Também é possível usar seus próprios dados de validação. Saiba mais no artigo Configurar divisões de dados e validação cruzada no AutoML (SDK v1).
Próximas etapas
- Saiba mais sobre como configurar o AutoML para treinar um modelo de previsão de série temporal.
- Procurar por Perguntas Frequentes sobre Previsão de AutoML.
- Saiba sobre os recursos de calendário para previsão de série temporal no AutoML.
- Saiba mais sobre como o AutoML usa o aprendizado de máquina para compilar modelos de previsão.