Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Ao usar pontos de extremidade em lote no Azure Machine Learning, você pode executar longas operações em lotes em grandes quantidades de dados de entrada. Os dados podem estar localizados em locais diferentes, como em regiões diferentes. Determinados tipos de pontos de extremidade em lotes também podem receber parâmetros literais como entradas.
Este artigo descreve como especificar entradas de parâmetro para pontos de extremidade em lotes e criar trabalhos de implantação. O processo dá suporte ao trabalho com dados de várias fontes, como ativos de dados, armazenamentos de dados, contas de armazenamento e arquivos locais.
Pré-requisitos
Um ponto de extremidade e implantação em lotes. Para criar esses recursos, consulte Implantar modelos do MLflow em implantações em lote no Azure Machine Learning.
Permissões para executar uma implantação de ponto de extremidade em lote. Você pode usar as funções de Cientista de Dados, Colaborador e Proprietário do AzureML para executar uma implantação. Para analisar permissões específicas que são necessárias para definições de função personalizada, confira Autorização em pontos de extremidade em lote.
Credenciais para invocar um ponto de extremidade. Para obter mais informações, confira Estabelecer autenticação.
Acesso de leitura aos dados de entrada para o cluster de cálculo em que o ponto de extremidade está implantado.
Dica
Determinadas situações exigem o uso de um armazenamento de dados sem credencial ou uma conta externa do Armazenamento do Microsoft Azure como entrada de dados. Nesses cenários, garanta que você tenha configurado clusters de cálculo para acesso aos dados, pois a identidade gerenciada do cluster de cálculo é usada para montar a conta de armazenamento. Você ainda tem controle de acesso mais refinado, pois a identidade do trabalho (invocador) é usada para ler os dados subjacentes.
Estabelecer autenticação
Para invocar um ponto de extremidade, você precisa de um token válido do Microsoft Entra. Quando você invoca um ponto de extremidade, o Azure Machine Learning cria um trabalho de implantação em lotes na identidade que é associada ao token.
- Se você usa a CLI do Azure Machine Learning (v2) ou o SDK do Azure Machine Learning para Python (v2) para invocar pontos de extremidade, não será necessário obter o token do Microsoft Entra manualmente. Durante a entrada, o sistema autentica sua identidade de usuário. Ele também recupera e passa o token para você.
- Se você usar a API REST para invocar pontos de extremidade, precisará obter o token manualmente.
Você pode usar suas próprias credenciais para a invocação, conforme descrito nos procedimentos a seguir.
Use a CLI do Azure para entrar com autenticação interativa ou de código do dispositivo:
az login
Para obter mais informações sobre vários tipos de credenciais, consulte Como executar trabalhos usando diferentes tipos de credenciais.
Criar trabalhos básicos
Para criar um trabalho a partir de um ponto de extremidade em lotes, invoque o ponto de extremidade. A invocação pode ser feita usando a CLI do Azure Machine Learning, o SDK do Azure Machine Learning para Python ou uma chamada à API REST.
Os exemplos a seguir mostram os conceitos básicos da invocação para um ponto de extremidade em lote que recebe uma única pasta de dados de entrada para processamento. Para obter exemplos com várias entradas e saídas, confira Noções básicas sobre entradas e saídas.
Use a operação invoke em pontos de extremidade em lote:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Invocar uma implantação específica
Os pontos de extremidade do lote podem hospedar várias implantações no mesmo ponto de extremidade. O ponto de extremidade padrão será usado, salvo especificações em contrário por parte do usuário. Você pode usar os procedimentos a seguir para alterar a implantação que você usa.
Use o argumento --deployment-name ou -d para especificar o nome da implantação:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Configurar propriedades do trabalho
Você pode configurar algumas propriedades de trabalho no momento da invocação.
Observação
Atualmente, você pode configurar propriedades de trabalho apenas em pontos de extremidade em lote com implantações de componente de pipeline.
Configurar o nome do experimento
Use os procedimentos a seguir para configurar o nome do experimento.
Use o argumento --experiment-name para especificar o nome do experimento:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Entender entradas e saídas
Os pontos de extremidade em lote fornecem uma API durável que os consumidores podem usar para criar trabalhos em lote. A mesma interface pode ser usada para especificar as entradas e saídas esperadas pela implantação. Use entradas para passar qualquer informação que seu ponto de extremidade precise para executar o trabalho.
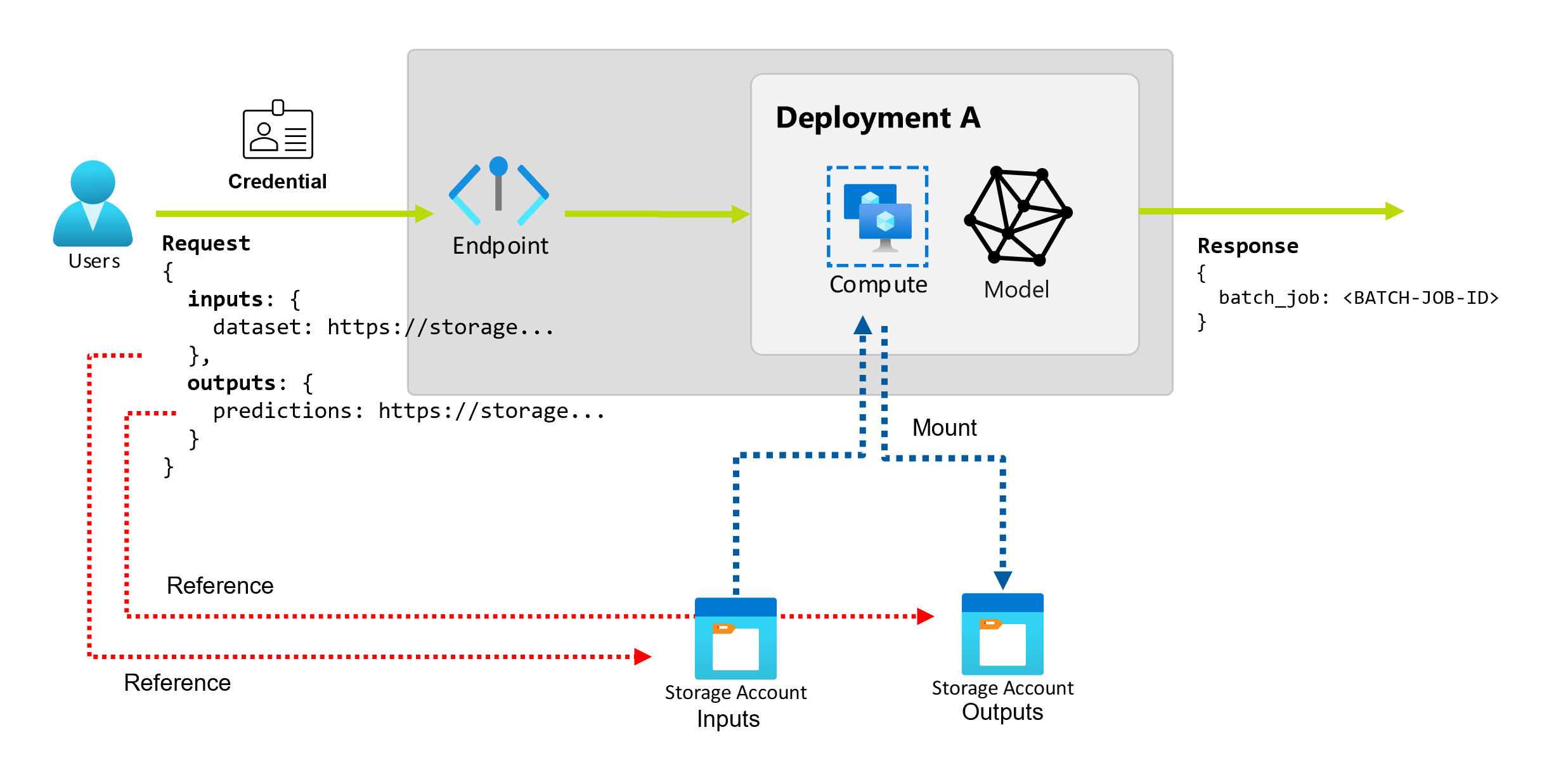
Os pontos de extremidade do lote dão suporte a dois tipos de entradas:
- Entradas de dados ou ponteiros para um local de armazenamento ou ativo do Azure Machine Learning específico
- Entradas literais ou valores literais como números ou cadeias de caracteres que você deseja passar para o trabalho
O número e o tipo de entradas e saídas dependem do tipo de implantação em lote. As implantações de modelo sempre requerem uma entrada de dados e produzem uma saída de dados. Não há suporte para entradas literais em implantações de modelo. Por outro lado, as implantações de componentes de pipeline fornecem um constructo mais geral para criar pontos de extremidade. Em uma implantação de componente de pipeline, você pode especificar qualquer número de entradas de dados, entradas literais e saídas.
A tabela a seguir resume as entradas e saídas para implantações em lote:
| Tipo de implantação | Número de entradas | Tipos de entrada com suporte | Número de saídas | Tipos de saída compatíveis |
|---|---|---|---|---|
| Implantação de modelo | 1 | Entradas de dados | 1 | Saídas de dados |
| Implantação do componente de pipeline | 0-N | Entradas de dados e entradas literais | 0-N | Saídas de dados |
Dica
Entradas e saídas são sempre nomeadas. Cada nome serve como uma chave para identificar os dados e passar o valor durante a invocação. Como as implantações de modelo sempre exigem uma entrada e uma saída, os nomes são ignorados durante a invocação em implantações de modelo. Você pode atribuir o nome que melhor descreve o seu caso de uso, como sales_estimation.
Explorar entradas de dados
As entradas de dados referem-se a entradas que apontam para um local onde os dados são colocados. Como os pontos de extremidade em lotes geralmente consomem grandes quantidades de dados, você não pode passar os dados de entrada como parte da solicitação de invocação. Em vez disso, você especifica o local aonde o ponto de extremidade do lote deve ir para procurar os dados. Os dados de entrada são montados e transmitidos na instância de computação de destino para melhorar o desempenho.
Os pontos de extremidade em lote podem ler arquivos localizados nos seguintes tipos de armazenamento:
- Ativos de dados do Azure Machine Learning, incluindo os tipos de pasta (
uri_folder) e de arquivo (uri_file). - Armazenamentos de dados do Azure Machine Learning, incluindo o Armazenamento de Blobs do Azure, o Azure Data Lake Storage Gen1 e o Azure Data Lake Storage Gen2.
- Contas de Armazenamento do Microsoft Azure, incluindo o Armazenamento de Blobs, o Data Lake Storage Gen1 e o Data Lake Storage Gen2.
- As pastas e os arquivos de dados locais, quando você usa a CLI do Azure Machine Learning ou o SDK do Azure Machine Learning para Python para invocar pontos de extremidade. Mas os dados locais são carregados no armazenamento de dados padrão do seu Workspace do Azure Machine Learning.
Importante
Aviso de substituição: ativos de dados do tipo FileDataset (V1) estão preteridos e serão desativados no futuro. Os pontos de extremidade em lotes existentes que dependem dessa funcionalidade continuarão funcionando. Mas não há suporte para conjuntos de dados V1 em pontos de extremidade em lote criados com:
- Versões da CLI do Azure Machine Learning v2 que estão em disponibilidade geral (2.4.0 e mais recentes).
- Versões da API REST que estão em disponibilidade geral (2022-05-01 e mais recente).
Explorar entradas literais
Entradas literais referem-se a entradas que podem ser representadas e resolvidas no momento da invocação, como cadeias de caracteres, números e valores boolianos. Normalmente, você usa entradas literais para passar parâmetros para o ponto de extremidade como parte de uma implantação de componente de pipeline. Os pontos de extremidade do lote dão suporte aos seguintes tipos literais:
stringbooleanfloatinteger
As entradas de literais só têm suporte nas implantações de componentes do pipeline. Para saber como especificar pontos de extremidade literais, confira Criar trabalhos com entradas literais.
Explorar saídas de dados
As saídas de dados se referem ao local em que os resultados de um trabalho em lotes devem ser colocados. Cada saída tem um nome identificável e o Azure Machine Learning atribui automaticamente um caminho exclusivo a cada saída nomeada. Você pode especificar outro caminho, se precisar.
Importante
Os pontos de extremidade em lote só dão suporte à gravação de saídas em armazenamentos de dados do Armazenamento de Blobs. Se precisar gravar em uma conta de armazenamento com namespaces hierárquicos habilitados, como o Data Lake Storage Gen2, você poderá registrar o serviço de armazenamento como um armazenamento de dados do Armazenamento de Blobs porque os serviços são totalmente compatíveis. Dessa forma, você pode gravar saídas de pontos de extremidade em lote no Data Lake Storage Gen2.
Criar trabalhos com entradas de dados
Os exemplos a seguir mostram como criar trabalhos obtendo entradas de dados de ativos de dados, armazenamentos de dados e contas de Armazenamento do Microsoft Azure.
Usar dados de entrada de um ativo de dados
Os ativos de dados do Azure Machine Learning (anteriormente conhecidos como conjuntos de dados) têm suporte como entradas para trabalhos. Siga essas etapas para executar um trabalho de ponto de extremidade em lote que usa dados de entrada que são armazenados em um ativo de dados registrado no Azure Machine Learning.
Aviso
No momento, os ativos de dados do tipo Tabela (MLTable) não são compatíveis.
Crie o ativo de dados. Neste exemplo, ele consiste em uma pasta que contém vários arquivos CSV. Você usa pontos de extremidade em lote para processar os arquivos em paralelo. Você pode ignorar essa etapa se seus dados já estiverem registrados como um ativo de dados.
Crie uma definição de ativo de dados em um arquivo YAML chamado heart-data.yml:
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-data description: An unlabeled data asset for heart classification. type: uri_folder path: dataCrie o ativo de dados:
az ml data create -f heart-data.yml
Configure a entrada:
DATA_ASSET_ID=$(az ml data show -n heart-data --label latest | jq -r .id)A ID do ativo de dados tem o formato
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/<data-asset-name>/versions/<data-asset-version>.Execute o ponto de extremidade:
Use o argumento
--setpara especificar a entrada. Primeiro, substitua os hifens no nome do ativo de dados por caracteres de sublinhado. Chaves podem conter somente caracteres alfanuméricos e caracteres de sublinhado.az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$DATA_ASSET_IDPara um ponto de extremidade que serve uma implantação de modelo, você pode usar o argumento
--inputpara especificar a entrada de dados porque uma implantação de modelo sempre requer apenas uma entrada de dados.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATA_ASSET_IDO argumento
--settende a produzir comandos longos quando você especifica várias entradas. Nesses casos, você pode listar suas entradas em um arquivo e, em seguida, fazer referência ao arquivo ao invocar o ponto de extremidade. Por exemplo, você pode criar um arquivo YAML chamado inputs.yml que contém as seguintes linhas:inputs: heart_data: type: uri_folder path: /subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/heart-data/versions/1Em seguida, você pode executar o seguinte comando, que usa o argumento
--filepara especificar as entradas:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Usar dados de entrada de um armazenamentos de dados
Seus trabalhos de implantações em lotes podem referenciar dados diretamente que estão em armazenamentos de dados registrados do Azure Machine Learning. Neste exemplo, primeiro você carrega alguns dados em um armazenamento de dados no workspace do Azure Machine Learning. Em seguida, você executa uma implantação em lote nesses dados.
Este exemplo usa o armazenamento de dados padrão, mas você pode usar um armazenamento de dados diferente. Em qualquer workspace do Azure Machine Learning, o nome do armazenamento de dados de blob padrão é workspaceblobstore. Se você quiser usar um armazenamento de dados diferente nas etapas a seguir, substitua workspaceblobstore pelo nome do armazenamento de dados preferido.
Carregue dados de exemplo no armazenamento de dados. Os dados de exemplo estão disponíveis no repositório azureml-examples. Você pode encontrar os dados na pasta sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/data desse repositório.
- No Estúdio do Azure Machine Learning, abra a página de ativos de dados do armazenamento de dados de blob padrão e procure o nome do contêiner de blobs.
- Use uma ferramenta como o Gerenciador de Armazenamento do Microsoft Azure ou o AzCopy para carregar os dados de exemplo em uma pasta chamada heart-disease-uci-unlabeled nesse contêiner.
Configure as informações de entrada:
Coloque o caminho do arquivo na variável
INPUT_PATH:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="azureml://datastores/workspaceblobstore/paths/$DATA_PATH"Observe como a pasta
pathsfaz parte do caminho de entrada. Este formato indica que o valor a seguir é um caminho.Execute o ponto de extremidade:
Use o argumento
--setpara especificar a entrada:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_PATHPara um ponto de extremidade que serve uma implantação de modelo, você pode usar o argumento
--inputpara especificar a entrada de dados porque uma implantação de modelo sempre requer apenas uma entrada de dados.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderO argumento
--settende a produzir comandos longos quando você especifica várias entradas. Nesses casos, você pode listar suas entradas em um arquivo e, em seguida, fazer referência ao arquivo ao invocar o ponto de extremidade. Por exemplo, você pode criar um arquivo YAML chamado inputs.yml que contém as seguintes linhas:inputs: heart_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/<data-path>Se os dados estiverem em um arquivo, use o tipo
uri_filepara a entrada.Em seguida, você pode executar o seguinte comando, que usa o argumento
--filepara especificar as entradas:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Usar dados de entrada de uma conta de Armazenamento do Microsoft Azure
Os pontos de extremidade em lote do Azure Machine Learning podem ler dados de locais de nuvem em contas do Armazenamento do Microsoft Azure, tanto pública quanto privada. Use as etapas a seguir para executar um trabalho de ponto de extremidade em lote com dados em uma conta de armazenamento.
Para saber mais informações sobre a configuração adicional necessária para ler dados de contas de armazenamento, confira Configurar clusters de cálculo para ter acesso aos dados.
Configure a entrada:
Defina a variável
INPUT_DATA:INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Se os dados estiverem em um arquivo, use um formato semelhante ao seguinte para definir o caminho de entrada:
INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Execute o ponto de extremidade:
Use o argumento
--setpara especificar a entrada:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_DATAPara um ponto de extremidade que serve uma implantação de modelo, você pode usar o argumento
--inputpara especificar a entrada de dados porque uma implantação de modelo sempre requer apenas uma entrada de dados.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderO argumento
--settende a produzir comandos longos quando você especifica várias entradas. Nesses casos, você pode listar suas entradas em um arquivo e, em seguida, fazer referência ao arquivo ao invocar o ponto de extremidade. Por exemplo, você pode criar um arquivo YAML chamado inputs.yml que contém as seguintes linhas:inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataEm seguida, você pode executar o seguinte comando, que usa o argumento
--filepara especificar as entradas:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlSe os dados estiverem em um arquivo, use o tipo
uri_fileno arquivo inputs.yml para a entrada de dados.
Criar trabalhos com entradas literais
As implantações de componente de pipeline podem aceitar entradas literais. Para obter um exemplo de uma implantação em lote que contém um pipeline básico, consulte Como implantar pipelines com pontos de extremidade em lotes.
O exemplo a seguir mostra como especificar uma entrada chamada score_mode, do tipo string, com um valor de append:
Coloque suas entradas em um arquivo YAML, como um chamado inputs.yml:
inputs:
score_mode:
type: string
default: append
Execute o seguinte comando, que usa o argumento --file para especificar as entradas.
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Você também pode usar o argumento --set para especificar o tipo e valor padrão. Essa abordagem tende a produzir comandos longos quando você especifica várias entradas:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Criar trabalhos com saídas de dados
O exemplo a seguir mostra como alterar o local de uma saída chamada score. Para ficarem completos, esses exemplos também configuram uma entrada chamada heart_data.
Este exemplo usa o armazenamento de dados padrão, workspaceblobstore. No entanto, você pode usar qualquer outro armazenamento de dados em seu workspace, desde que seja uma conta de Armazenamento de Blobs. Se você quiser usar um armazenamento de dados diferente, nas etapas a seguir, substitua workspaceblobstore pelo nome do armazenamento de dados preferido.
Obter a ID do armazenamento de dados.
DATA_STORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')A ID do armazenamento de dados tem o formato
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/datastores/workspaceblobstore.Criar uma saída de dados:
Defina os valores de entrada e saída em um arquivo chamado inputs-and-outputs.yml. Use a ID do armazenamento de dados no caminho de saída. Para ficar completo, você também define uma entrada de dados.
inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data outputs: score: type: uri_file path: <data-store-ID>/paths/batch-jobs/my-unique-pathObservação
Observe como a pasta
pathsfaz parte do caminho de saída. Este formato indica que o valor a seguir é um caminho.Execute a implantação:
Use o argumento
--filepara especificar os valores de entrada e saída:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs-and-outputs.yml