Configurar o treinamento do AutoML com Python
APLICA-SE A: SDK do Python azureml v1
SDK do Python azureml v1
Nesta guia, saiba como configurar uma execução de treinamento do AutoML (machine learning automatizado) com o SDK do Python do Azure Machine Learning usando ML automatizado do Azure Machine Learning. O ML automatizado escolhe um algoritmo e hiperparâmetros para você e gera um modelo pronto para implantação. Este guia fornece detalhes das várias opções que você pode usar para configurar experimentos de ML automatizado.
Para ver um exemplo de ponta a ponta, confira Tutorial: AutoML – modelo de regressão de treinamento.
Se preferir uma experiência sem código, você também poderá Configurar o treinamento AutoML sem código no Estúdio do Azure Machine Learning.
Pré-requisitos
Para este artigo, você precisa,
Um Workspace do Azure Machine Learning. Para criar o workspace, confira Criar recursos do workspace.
O SDK do Python do Azure Machine Learning instalado. Para instalar o SDK, você pode:
Criar uma instância de computação, que instala automaticamente o SDK e é pré-configurada para fluxos de trabalho de ML. Para obter mais informações, confira Criar e gerenciar uma instância de computação do Azure Machine Learning.
Instalar o pacote
automlpor conta própria, que inclui a instalação padrão do SDK.
Importante
Os comandos do Python neste artigo exigem a versão mais recente do pacote
azureml-train-automl.-
Instale o pacote
azureml-train-automlmais recente em seu ambiente local. - Para obter detalhes sobre o pacote
azureml-train-automlmais recente, veja as notas sobre a versão.
Aviso
O Python 3.8 não é compatível com
automl.
Selecionar o tipo de experimento
Antes de iniciar o experimento, determine o tipo de problema de aprendizado de máquina a ser resolvido. O machine learning automatizado é compatível com os tipos de tarefa de classification, regression e forecasting. Saiba mais sobre tipos de tarefas.
Observação
Suporte para tarefas de NLP (processamento de linguagem natural): a classificação de imagem (várias classes e vários rótulos) e o reconhecimento de entidade nomeada estão disponíveis em versão prévia pública. Saiba mais sobre as tarefas de NLP no ML automatizado.
Essas funcionalidades em versão prévia são fornecidas sem um contrato de nível de serviço. Alguns recursos podem não ter suporte ou ter funcionalidades restritas. Para obter mais informações, consulte Termos de Uso Complementares de Versões Prévias do Microsoft Azure.
O código a seguir usa o parâmetro task no construtor AutoMLConfig para especificar o tipo de experimento como classification.
from azureml.train.automl import AutoMLConfig
# task can be one of classification, regression, forecasting
automl_config = AutoMLConfig(task = "classification")
Fonte de dados e formato
O aprendizado de máquina automatizado é compatível com os dados que residem na área de trabalho local ou na nuvem no Armazenamento de Blobs do Azure. Os dados podem ser lidos em um DataFrame do Pandas ou em um TabularDataset do Azure Machine Learning. Saiba mais sobre conjuntos de dados.
Requisitos para treinamento de dados no aprendizado de máquina:
- Os dados devem estar em formato de tabela.
- O valor que você quer prever, coluna de destino, deve estar presente nos dados.
Importante
Experimentos ML automatizados não dão suporte a treinamento com conjuntos de dados que usam acesso a dados baseado em identidade.
Para experimentos remotos, os dados de treinamento devem estar acessíveis a partir da computação remota. O ML automatizado somente aceita o TabularDatasets do Azure Machine Learning quando ele está funcionando em uma computação remota.
Os conjuntos de dados do Azure Machine Learning expõem a funcionalidade para:
- Transferir com facilidade os dados de arquivos estáticos ou de fontes de URL para seu workspace.
- Disponibilizar dados para scripts de treinamento ao executar recursos de computação em nuvem. Confira Como treinar com conjuntos de dados para obter um exemplo de como usar a classe
Datasetpara montar os dados para seu destino de computação remota.
O código a seguir cria um TabularDataset a partir de uma URL da Web. Confira Criar um TabularDataset para ver exemplos de código sobre como criar conjuntos de dados de outras fontes, incluindo arquivos locais e armazenamentos de dados.
from azureml.core.dataset import Dataset
data = "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv"
dataset = Dataset.Tabular.from_delimited_files(data)
Para experimentos de computação local, recomendamos dataframes pandas para obter tempos de processamento mais rápidos.
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("your-local-file.csv")
train_data, test_data = train_test_split(df, test_size=0.1, random_state=42)
label = "label-col-name"
Dados de treinamento, validação e teste
Você pode especificar conjuntos de dados de validação e de treinamento separados diretamente no construtor AutoMLConfig. Saiba mais sobre Como configurar treinamento, validação, validação cruzada e dados de teste para seus experimentos do AutoML.
Se você não especificar explicitamente um parâmetro validation_data ou n_cross_validation, o ML automatizado aplicará técnicas padrão para determinar como a validação é executada. Essa determinação depende do número de linhas no conjuntos de dados atribuído ao parâmetro training_data.
| Tamanho dos dados de treinamento | Técnica de validação |
|---|---|
| Maior que 20.000 linhas | A divisão de dados de treinamento/validação é aplicada. O padrão é levar 10% do conjunto de dados de treinamento inicial como o conjunto de validação. Por sua vez, esse conjunto de validação é usado para cálculo de métricas. |
| Menor que 20.000 linhas | A abordagem de validação cruzada é aplicada. O número padrão de dobras depende do número de colunas. Se o conjunto de registros for menor que 1.000 linhas, serão usadas 10 dobras. Se as linhas estiverem entre 1.000 e 20.000, serão usadas três dobras. |
Dica
Você pode carregar dados de teste (versão prévia) para avaliar modelos que o ML automatizado gerou para você. Esses métodos são uma versão prévia experimental das funcionalidades e podem ser alterados a qualquer momento. Saiba como:
- Passar dados de teste para o objeto AutoMLConfig.
- Testar o ML automatizado dos modelos para seu experimento.
Se você preferir uma experiência sem código, confira a etapa 12 em Configurar o AutoML com a UI (interface do usuário) do estúdio
Dados grandes
O ML automatizado é compatível com um número limitado de algoritmos usados para treinamento em dados grandes que podem criar com êxito modelos de Big Data em máquinas virtuais pequenas. As heurísticas do ML automatizado dependem de propriedades, como o tamanho dos dados, o tamanho da memória da máquina virtual, o tempo limite do experimento e as configurações de definição de recursos para determinar se esses algoritmos de dados grandes devem ser aplicados. Saiba mais sobre quais modelos são compatíveis com o ML automatizado.
Para a regressão: o Regressor Descendente do Gradiente Online e o Regressor Linear Rápido
Para a classificação: o Classificador do Perceptron Médio e o Classificador SVM Linear, em que o classificador SVM Linear tem versões de dados grandes e pequenos.
Caso queira substituir essas heurísticas, defina as seguintes configurações:
| Tarefa | Configuração | Observações |
|---|---|---|
| Bloquear algoritmos de streaming de dados | Use blocked_models no objeto AutoMLConfig e liste os modelos que você não deseja usar. |
Resulta em uma falha de execução ou um tempo de execução longo |
| Usar algoritmos de streaming de dados | Use allowed_models no objeto AutoMLConfig e liste os modelos que você deseja usar. |
|
| Usar algoritmos de streaming de dados (experimentos de interface do usuário do estúdio) |
Bloqueie todos os modelos, exceto os algoritmos de Big Data que você deseja usar. |
Computação para executar o experimento
Em seguida, determine onde o modelo será treinado. Um experimento de treinamento de ML automatizado pode ser executado nas opções de computação a seguir.
Escolher uma computação local: se seu cenário for sobre explorações ou demonstrações iniciais que usam dados pequenos e treinamentos breves (por exemplo, segundos ou alguns minutos por execução filho), o treinamento em seu computador local poderá ser uma opção melhor. Não há tempo de configuração e os recursos de infraestrutura (seu PC ou sua VM) estão diretamente disponíveis. Consulte este notebook para obter um exemplo de computação local.
Escolher um cluster de computação do ML remoto: se você estiver treinando com conjuntos de dados maiores, como no treinamento em produção que cria modelos que precisam de treinamentos maiores, a computação remota fornecerá um desempenho de ponta a ponta muito melhor, pois
AutoMLvai paralelizar os treinamentos nos nós do cluster. Em uma computação remota, o tempo de inicialização da infraestrutura interna adicionará cerca de 1,5 minuto por execução filho, além de minutos adicionais para a infraestrutura de cluster se as VMs ainda não estiverem em execução. A Computação Gerenciada do Azure Machine Learning é um serviço gerenciado que permite treinar modelos de machine learning em clusters de máquinas virtuais do Azure. A instância de computação também tem suporte como destino de computação.No cluster Azure Databricks na sua assinatura do Azure. Você pode encontrar mais detalhes em Configurar cluster do Azure Databricks para o ML automatizado. Consulte este site do GitHub para obter exemplos de notebooks com Azure Databricks.
Considere estes fatores ao escolher seu destino de computação:
| Prós (vantagens) | Contras (desvantagens) | |
|---|---|---|
| Destino de computação local | ||
| Clusters de computação do ML remota |
Configurar as definições do experimento
Existem várias opções que você pode usar para configurar o experimento de ML automatizado. Esses parâmetros são definidos pela instanciação de um objeto AutoMLConfig. Consulte a classe AutoMLConfig para obter uma lista completa de parâmetros.
O exemplo a seguir é para uma tarefa de classificação. Experimento usa AUC ponderado como a métrica primária e tem um tempo limite de experimento definido como 30 minutos e duas dobras de validação cruzada.
automl_classifier=AutoMLConfig(task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
blocked_models=['XGBoostClassifier'],
training_data=train_data,
label_column_name=label,
n_cross_validations=2)
Você também pode configurar tarefas de previsão, que exigem configuração adicional. Confira o artigo Configurar o AutoML para previsão de séries temporais para obter mais detalhes.
time_series_settings = {
'time_column_name': time_column_name,
'time_series_id_column_names': time_series_id_column_names,
'forecast_horizon': n_test_periods
}
automl_config = AutoMLConfig(
task = 'forecasting',
debug_log='automl_oj_sales_errors.log',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=20,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
path=project_folder,
verbosity=logging.INFO,
**time_series_settings
)
Modelos com suporte
O machine learning automatizado testa diferentes modelos e algoritmos durante o processo de automação e ajuste. Como usuário, não há necessidade de especificar o algoritmo.
Os três valores de parâmetro task diferentes determinam a lista de algoritmos ou modelos a serem aplicados. Use os parâmetros allowed_models ou blocked_models para modificar ainda mais as iterações com os modelos disponíveis a serem incluídos ou excluídos.
A tabela a seguir resume os modelos com suporte por tipo de tarefa.
Observação
Caso planeje exportar os modelos de ML automatizado criados para um modelo ONNX, somente os algoritmos indicados com um asterisco (*) podem ser convertidos para o formato ONNX. Saiba mais sobre conversão de modelos para ONNX.
Observe também que, no momento, o ONNX tem suporte apenas a tarefas de classificação e regressão.
Métrica principal
O parâmetro primary_metric determina a métrica a ser usada durante o treinamento do modelo para otimização. As métricas disponíveis que você poderá selecionar serão determinadas pelo tipo de tarefa que você escolher.
A escolha da métrica primária para otimizar o ML automatizado depende de muitos fatores. Recomendamos que a sua consideração principal seja escolher uma métrica que melhor represente suas necessidades de negócios. Em seguida, considere se a métrica é adequada para o seu perfil de conjunto de dados (tamanho de dados, intervalo, distribuição de classe etc.). As seções a seguir resumem as métricas primárias recomendadas com base no tipo de tarefa e no cenário de negócios.
Saiba mais sobre as definições específicas dessas métricas em Entender os resultados do machine learning automatizado.
As métricas usadas em cenários de classificação
As métricas dependentes do limite, como accuracy, recall_score_weighted, norm_macro_recall e precision_score_weighted, talvez nem otimizem para conjuntos de dados, que são pequenos e têm uma distorção de classe muito grande (desequilíbrio de classe) ou quando o valor esperado da métrica é muito próximo de 0,0 ou 1,0. Nesses casos, AUC_weighted pode ser uma opção melhor para a métrica primária. Após a conclusão do ML automatizado, você pode escolher o modelo vencedor baseado na métrica mais adequada para suas necessidades de negócios.
| Métrica | Exemplos de casos de uso |
|---|---|
accuracy |
Classificação de imagem, análise de sentimentos, previsão de rotatividade |
AUC_weighted |
Detecção de fraudes, classificação de imagem, detecção de anomalias/de spam |
average_precision_score_weighted |
Análise de sentimento |
norm_macro_recall |
Previsão de rotatividade |
precision_score_weighted |
As métricas usadas em cenários de regressão
r2_score, normalized_mean_absolute_error e normalized_root_mean_squared_error estão todos tentando minimizar os erros de previsão.
r2_score e normalized_root_mean_squared_error estão minimizando erros ao quadrado médios enquanto normalized_mean_absolute_error minimizam o valor absoluto médio de erros. O valor absoluto trata erros em todas as magnitudes, e erros ao quadrado terão uma penalidade muito maior para erros com valores absolutos maiores. Dependendo se erros maiores devem ser mais ou não, é possível optar por otimizar o erro ao quadrado ou o erro absoluto.
A principal diferença entre r2_score e normalized_root_mean_squared_error é a maneira como eles são normalizados e seus significados.
normalized_root_mean_squared_error é o erro quadrado médio raiz normalizado por intervalo e pode ser interpretado como a magnitude média do erro para previsão.
r2_score é o erro quadrado média normalizado por uma estimativa de variação de dados. É a proporção de variação que pode ser capturada pelo modelo.
Observação
r2_score e normalized_root_mean_squared_error também se comportam da mesma forma que as métricas primárias. Se um conjunto de validação fixo for aplicado, essas duas métricas estão otimizando o mesmo destino, erro ao quadrado médio e serão otimizadas pelo mesmo modelo. Quando apenas um conjunto de treinamento estiver disponível e a validação cruzada for aplicada, ele será ligeiramente diferente, pois o normalizador para normalized_root_mean_squared_error é fixo como o intervalo de conjunto de treinamento, mas o normalizador para r2_score variaria para cada dobra, pois é a variação para cada dobra.
Se a classificação, em vez do valor exato for de interesse, spearman_correlation poderá ser uma opção melhor, pois ela mede a correlação de classificação entre valores reais e previsões.
No entanto, atualmente, nenhuma métrica primária para regressão aborda a diferença relativa. Todos r2_score, normalized_mean_absolute_error e normalized_root_mean_squared_error e tratam um erro de previsão de US$ 20 mil da mesma forma para um trabalhador com um salário de US$ 30 mil como um trabalhador que ganha US$ 20 milhões, se esses dois pontos de dados pertencem ao mesmo conjuntos de dados para regressão ou à mesma série de tempo especificada pelo identificador de séries temporárias. Na realidade, a previsão de desconto de apenas US$ 20 mil de um salário de US$ 20 milhões é muito próxima (uma pequena diferença relativa de 0,1%), enquanto US$ 20 mil de desconto de US$ 30 mil não está próximo (uma grande diferença relativa de 67%). Para resolver o problema de diferença relativa, é possível treinar um modelo com métricas primárias disponíveis e, em seguida, selecionar o modelo com o melhor mean_absolute_percentage_error ou root_mean_squared_log_error.
| Métrica | Exemplos de casos de uso |
|---|---|
spearman_correlation |
|
normalized_root_mean_squared_error |
Previsão de preço (casa/produto/gorjeta), revisar previsão de pontuação |
r2_score |
Atraso de companhia aérea, estimativa de salário, tempo de resolução de bug |
normalized_mean_absolute_error |
As métricas usadas em cenários de previsão de série temporal
As recomendações são semelhantes às observadas em cenários de regressão.
| Métrica | Exemplos de casos de uso |
|---|---|
normalized_root_mean_squared_error |
Previsão de preço (previsão), otimização de estoque, previsão de demanda |
r2_score |
Previsão de preço (previsão), otimização de estoque, previsão de demanda |
normalized_mean_absolute_error |
Definição de recursos de dados
Em todos os experimentos de ML automatizado, seus dados são automaticamente escalados e normalizados para ajudar determinados algoritmos sensíveis a recursos que estão em escalas diferentes. Essa colocação em escala e normalização são chamados de definição de recursos. Confira Definição de recursos em AutoML para obter mais detalhes e exemplos de código.
Observação
As etapas de definição de recursos de machine learning automatizado (normalização de recursos, manipulação de dados ausentes, conversão de texto em números, etc.) tornam-se parte do modelo subjacente. Ao usar o modelo para previsões, as mesmas etapas de definição de recursos aplicadas durante o treinamento são aplicadas aos dados de entrada automaticamente.
Ao configurar seus experimentos em seu objeto AutoMLConfig, você pode habilitar/desabilitar a configuração featurization. A tabela a seguir mostra as configurações aceitas para definição de recursos no objeto AutoMLConfig.
| Configuração de definição de recursos | Descrição |
|---|---|
"featurization": 'auto' |
Indica que, como parte do pré-processamento, verificadores de integridade dos dados e etapas de definição de recursos são executados automaticamente. Configuração padrão. |
"featurization": 'off' |
Indica que a etapa de definição de recursos não deve ser feita automaticamente. |
"featurization": 'FeaturizationConfig' |
Indica que uma etapa de definição de recursos personalizada deve ser usada. Saiba como personalizar a definição de recursos. |
Configuração do Ensemble
Os modelos de Ensemble são habilitados por padrão e aparecem como as iterações de execução final em uma execução de ML automatizado. Atualmente, há suporte para VotingEnsemble e StackEnsemble.
A votação implementa a votação suave, que usa médias ponderadas. E a implementação de empilhamento usa uma implementação de duas camadas, em que os modelos da primeira camada são iguais ao do ensemble de votação, e o modelo da segunda camada é usado para encontrar a combinação ideal dos modelos da primeira camada.
Se você estiver usando modelos ONNX ou tiver a explicação de modelo habilitada, o empilhamento será desabilitado e somente a votação será utilizada.
O treinamento do Ensemble pode ser desabilitado usando os parâmetros boolianos enable_voting_ensemble e enable_stack_ensemble.
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=data_train,
label_column_name=label,
n_cross_validations=5,
enable_voting_ensemble=False,
enable_stack_ensemble=False
)
Para alterar o comportamento padrão de ensemble, há vários argumentos padrão que podem ser fornecidos como kwargs em um objeto AutoMLConfig.
Importante
Os parâmetros a seguir não são parâmetros explícitos da classe AutoMLConfig.
ensemble_download_models_timeout_sec: Durante VotingEnsemble e geração de modelo de StackEnsemble, vários modelos ajustados das execuções filho anteriores são baixados. Se você encontrar esse erro:AutoMLEnsembleException: Could not find any models for running ensembling, talvez seja necessário dar mais tempo para que os modelos sejam baixados. O valor padrão é 300 segundos para baixar esses modelos em paralelo e não o tempo limite máximo não é limitado. Configure esse parâmetro com um valor maior que 300 segundos, se for necessário mais tempo.Observação
Se o tempo limite for atingido e houver modelos baixados, o ensembling continuará com quantos modelos foram baixados. Não é necessário que todos os modelos sejam baixados para concluir dentro desse tempo limite. Os parâmetros a seguir se aplicam somente a modelos de StackEnsemble:
stack_meta_learner_type: o meta-aprendiz é um modelo treinado na saída dos modelos heterogêneos individuais. Os meta-aprendizes padrão sãoLogisticRegressionpara tarefas de classificação (ouLogisticRegressionCVse a validação cruzada estiver habilitada) eElasticNetpara tarefas de regressão/previsão (ouElasticNetCVse a validação cruzada estiver habilitada). Esse parâmetro pode ser uma das seguintes cadeias de caracteres:LogisticRegression,LogisticRegressionCV,LightGBMClassifier,ElasticNet,ElasticNetCV,LightGBMRegressorouLinearRegression.stack_meta_learner_train_percentage: especifica a proporção do conjunto de treinamento (ao escolher treinar e tipo de validação de treinamento) a ser reservado para treinar o meta-aprendiz. O valor padrão é0.2.stack_meta_learner_kwargs: parâmetros opcionais a serem passados para o inicializador do meta-aprendiz. Esses parâmetros e tipos de parâmetro espelham os parâmetros e os tipos de parâmetro do construtor de modelo correspondente e são encaminhados para o construtor de modelo.
O código a seguir mostra um exemplo de especificação do comportamento de ensemble personalizado em um objeto AutoMLConfig.
ensemble_settings = {
"ensemble_download_models_timeout_sec": 600
"stack_meta_learner_type": "LogisticRegressionCV",
"stack_meta_learner_train_percentage": 0.3,
"stack_meta_learner_kwargs": {
"refit": True,
"fit_intercept": False,
"class_weight": "balanced",
"multi_class": "auto",
"n_jobs": -1
}
}
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
**ensemble_settings
)
Critérios de saída
Há algumas opções que você pode definir no AutoMLConfig para encerrar seu experimento.
| Critérios | descrição |
|---|---|
| Sem critérios | Se você não definir nenhum parâmetro de saída, o experimento continuará até que nenhum progresso adicional seja feito em sua métrica primária. |
| Após um período de tempo | Use experiment_timeout_minutes em suas configurações para definir por quanto tempo, em minutos, seu experimento deve continuar a ser executado. Para ajudar a evitar falhas de atingir tempo limite do experimento, existirá um mínimo de 15 ou 60 minutos se o tamanho de linha por coluna exceder 10 milhões. |
| Uma pontuação foi atingida | O uso de experiment_exit_score concluirá o experimento depois que uma pontuação de métrica primária especificada for atingida. |
Executar o experimento
Aviso
Caso execute várias vezes um experimento com as mesmas definições de configuração e a mesma métrica primária, será possível ver uma variação na pontuação das métricas finais de cada experimento, bem como nos modelos gerados. Os algoritmos que o ML automatizado emprega têm uma aleatoriedade inerente. Por isso, o experimento pode causar uma ligeira variação na saída dos modelos e na pontuação final das métricas do modelo recomendado, como a precisão. Também será possível ver resultados com o mesmo nome do modelo, porém com diferentes hiperparâmetros usados.
Para ML automatizado, você pode criar um objeto Experiment, que é um objeto nomeado em um Workspace usado para executar experimentos.
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
# Choose a name for the experiment and specify the project folder.
experiment_name = 'Tutorial-automl'
project_folder = './sample_projects/automl-classification'
experiment = Experiment(ws, experiment_name)
Envie o experimento para ser executado e para gerar um modelo. Passe o AutoMLConfig para o método submit para gerar o modelo.
run = experiment.submit(automl_config, show_output=True)
Observação
As dependências são instaladas pela primeira vez em um novo computador. Pode levar até dez minutos antes da saída ser exibida.
Definir show_output como True faz a saída ser mostrada no console.
Várias execuções filhas em clusters
Execuções filhas de experimento de ML automatizados podem ser realizadas em um cluster que já esteja executando outro experimento. No entanto, o tempo depende de quantos nós o cluster tem e se esses nós estão disponíveis para executar um experimento diferente.
Cada nó no cluster atua como uma VM (máquina virtual) individual que pode realizar uma única execução de treinamento; para o ML automatizado, isso significa uma execução filha. Se todos os nós estiverem ocupados, o novo experimento será colocado na fila. Mas, se houver nós livres, o novo experimento executará a filha de ML automatizado em paralelo nos nós/VMs disponíveis.
Para ajudar a gerenciar as execuções filhas e quando elas podem ser executadas, recomendamos que você crie um cluster dedicado por experimento e coincida com o número de max_concurrent_iterations do seu experimento para o número de nós no cluster. Dessa forma, você usa todos os nós do cluster ao mesmo tempo com o número de execuções/iterações filhas simultâneas desejadas.
Configure max_concurrent_iterations em seu objeto AutoMLConfig. Se não estiver configurado, por padrão, apenas uma execução/iteração filha simultânea será permitida por experimento.
No caso da instância de computação, é possível definir max_concurrent_iterations com o mesmo o número de núcleos da VM da instância de computação.
Explorar modelos e métricas
O ML automatizado oferece opções para você monitorar e avaliar os resultados do treinamento.
Será possível exibir os resultados de treinamento em um widget ou embutidos se você estiver usando um notebook. Confira Monitorar execuções do machine learning automatizado para obter mais detalhes.
Para obter definições e exemplos dos gráficos e métricas de desempenho fornecidos para cada execução, confira Avaliar resultados do experimento de machine learning automatizado.
Para obter um resumo de personalização e entender quais recursos foram adicionados a um modelo específico, confira Transparência da definição de recursos.
Veja os hiperparâmetros, as técnicas de normalização e escala e o algoritmo aplicado a uma execução específica de ML automatizado com a solução de código personalizado, print_model().
Dica
O ML automatizado também permite que você veja o código de treinamento do modelo gerado para modelos de ML treinados automaticamente. Essa funcionalidade está em versão prévia pública e pode ser alterada a qualquer momento.
Monitore execuções de machine learning automatizado
Para execuções do ML automatizado, para acessar os gráficos de uma execução anterior, substitua <<experiment_name>> pelo nome de teste apropriado:
from azureml.widgets import RunDetails
from azureml.core.run import Run
experiment = Experiment (workspace, <<experiment_name>>)
run_id = 'autoML_my_runID' #replace with run_ID
run = Run(experiment, run_id)
RunDetails(run).show()
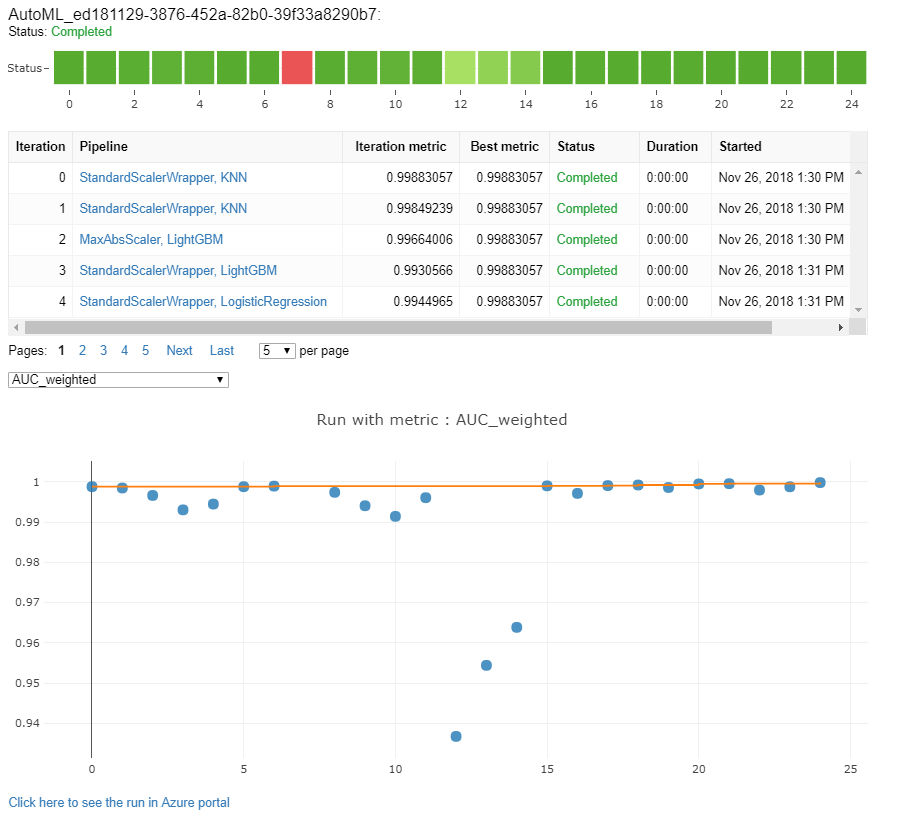
Testar modelos (visualização)
Importante
Testar seus modelos com um conjunto de dados de teste para avaliar modelos gerados por ML automatizados é uma versão prévia do recurso. Esse recurso está em versão prévia experimental e pode mudar a qualquer momento.
Aviso
Esse recurso não está disponível para os seguintes cenários de ML automatizado
- Tarefas da Pesquisa Visual Computacional
- Muitos modelos e treinamento de previsão de séries temporais hierárquicas (versão prévia)
- Tarefas de previsão em que as DNN (redes neurais de aprendizado profundo) estão habilitadas
- A ML automatizada é executada a partir de computação local ou de clusters do Azure Databricks
Passar os parâmetros test_data ou test_size no AutoMLConfig dispara automaticamente uma execução de teste remota que usa os dados de teste fornecidos para avaliar o melhor modelo que o ML automatizado recomenda após a conclusão do experimento. Essa execução de teste remoto é feita no final do experimento, uma vez que o melhor modelo é determinado. Veja como passar dados de teste para seu AutoMLConfig.
Obter resultados do trabalho de teste
Você pode obter as previsões e métricas do trabalho de teste remoto no Estúdio do Azure Machine Learning ou com o código a seguir.
best_run, fitted_model = remote_run.get_output()
test_run = next(best_run.get_children(type='automl.model_test'))
test_run.wait_for_completion(show_output=False, wait_post_processing=True)
# Get test metrics
test_run_metrics = test_run.get_metrics()
for name, value in test_run_metrics.items():
print(f"{name}: {value}")
# Get test predictions as a Dataset
test_run_details = test_run.get_details()
dataset_id = test_run_details['outputDatasets'][0]['identifier']['savedId']
test_run_predictions = Dataset.get_by_id(workspace, dataset_id)
predictions_df = test_run_predictions.to_pandas_dataframe()
# Alternatively, the test predictions can be retrieved via the run outputs.
test_run.download_file("predictions/predictions.csv")
predictions_df = pd.read_csv("predictions.csv")
O trabalho de teste do modelo gera o arquivo predictions.csv, que é armazenado no armazenamento de dados padrão criado com o workspace. Esse armazenamento de dados é visível para todos os usuários com a mesma assinatura. Os trabalhos de teste não são recomendados para cenários em que qualquer uma das informações usadas para o trabalho de teste ou por ele criadas precisam permanecer privadas.
Testar modelo de ML automatizado existente
Para testar outros modelos de ML automatizados existentes criados, melhor trabalho ou trabalho filho, use ModelProxy() para testar um modelo depois que a execução principal do AutoML for concluída.
ModelProxy() já retorna as previsões e métricas e não requer processamento adicional para recuperar as saídas.
Observação
Esse método é a versão prévia experimental e pode mudar a qualquer momento.
O código a seguir demonstra como testar um modelo de qualquer execução usando o método ModelProxy.test(). No método test(), você tem a opção de especificar se deseja ver apenas as previsões da execução de teste com o parâmetro include_predictions_only.
from azureml.train.automl.model_proxy import ModelProxy
model_proxy = ModelProxy(child_run=my_run, compute_target=cpu_cluster)
predictions, metrics = model_proxy.test(test_data, include_predictions_only= True
)
Registro e implantação de modelos
Depois de testar um modelo e confirmar que deseja usá-lo na produção, você pode registrá-lo para uso posterior e
Para registrar um modelo de uma execução de ML automatizado, use o método register_model().
best_run = run.get_best_child()
print(fitted_model.steps)
model_name = best_run.properties['model_name']
description = 'AutoML forecast example'
tags = None
model = run.register_model(model_name = model_name,
description = description,
tags = tags)
Para obter detalhes sobre como criar uma configuração de implantação e implantar um modelo registrado em um serviço Web, confira como e onde implantar um modelo.
Dica
Para modelos registrados, a implantação com um clique está disponível por meio do Estúdio do Azure Machine Learning. Confira como implantar modelos registrados do estúdio.
Interpretabilidade do modelo
A interpretabilidade de modelo permite entender por que seus modelos fizeram previsões e os valores de importância do recurso subjacentes. O SDK inclui vários pacotes para habilitar recursos de interpretação de modelo, tanto no tempo de inferência quanto no treinamento, para modelos locais e implantados.
Confira como habilitar recursos de interpretação especificamente em experimentos de ML automatizado.
Para obter informações gerais sobre como as explicações de modelo e a importância do recurso podem ser habilitadas em outras áreas do SDK fora do machine learning automatizado, consulte o artigo conceito sobre a interpretabilidade.
Observação
Atualmente o modelo ForecastTCN não tem suporte no Cliente de Explicação. Esse modelo não retornará um painel de explicação se for retornado como o melhor modelo e não oferece suporte para execuções de explicação sob demanda.
Próximas etapas
Saiba mais sobre como e onde implantar um modelo.
Saiba mais sobre Treinar um modelo de regressão com machine learning automatizado.