Usar um contêiner personalizado para implantar um modelo em um ponto de extremidade online
APLICA-SE A: Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Saiba como usar um contêiner personalizado para implantar um modelo em um ponto de extremidade online no Azure Machine Learning.
As implantações de contêineres personalizados podem usar servidores Web diferentes do servidor Python Flask padrão usado pelo Azure Machine Learning. Os usuários dessas implantações ainda podem aproveitar o monitoramento, dimensionamento, alerta e autenticação integrados do Azure Machine Learning.
A tabela a seguir lista vários exemplos de implantação que usam contêineres personalizados, como o Serviço do TensorFlow, o TorchServe, o Triton Inference Server, o pacote Plumber do R e a imagem Mínima de Inferência do Azure Machine Learning.
| Exemplo | Script (CLI) | Descrição |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | Implante vários modelos em uma só implantação estendendo a imagem Mínima de Inferência do Azure Machine Learning. |
| minimal/single-model | deploy-custom-container-minimal-single-model | Implante um só modelo estendendo a imagem Mínima de Inferência do Azure Machine Learning. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Implante dois modelos do MLFlow com requisitos diferentes do Python em duas implantações separadas com a proteção de um ponto de extremidade individual usando a imagem Mínima de Inferência do Azure Machine Learning. |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Implante três modelos de regressão em um ponto de extremidade usando o pacote Plumber R |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Implante um modelo do Half Plus Two usando um contêiner personalizado do TensorFlow Serving usando o processo de registro de modelo padrão. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Implante um modelo do Half Plus Two usando um contêiner personalizado do TensorFlow Serving com o modelo integrado à imagem. |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | Implante um único modelo usando um contêiner personalizado do TorchServe. |
| triton/single-model | deploy-custom-container-triton-single-model | Implante um modelo do Triton usando um contêiner personalizado |
Este artigo se concentra no atendimento de um modelo do TensorFlow com o TensorFlow (TF) Serving.
Aviso
A Microsoft pode não conseguir ajudar a solucionar problemas causados por uma imagem personalizada. Se você encontrar problemas, pode ser solicitado a usar a imagem padrão ou uma das imagens que a Microsoft oferece para ver se o problema é específico da imagem.
Pré-requisitos
Antes de seguir as etapas neste artigo, verifique se você tem os seguintes pré-requisitos:
Um Workspace do Azure Machine Learning. Se você não tiver um, use as etapas do artigo Início Rápido: criar recursos de workspace para criar.
A CLI do Azure e a extensão
mlou o SDK do Python v2 do Azure Machine Learning:Para instalar a extensão e a CLI do Azure, consulte Instalar, configurar e usar a CLI (v2).
Importante
Os exemplos de CLI neste artigo pressupõem que você esteja usando o shell Bash (ou compatível). Por exemplo, de um sistema Linux ou Subsistema do Windows para Linux.
Para instalar o SDK do Python v2, use o seguinte comando:
pip install azure-ai-ml azure-identityPara atualizar uma instalação do SDK existente para a versão mais recente, use o seguinte comando:
pip install --upgrade azure-ai-ml azure-identityPara saber mais, confira Instalar o SDK do Python v2 para Azure Machine Learning.
Você, ou a entidade de serviço que você usa, deve ter acesso de Colaborador ao grupo de recursos do Azure que contém seu workspace. Você tem esse grupo de recursos se tiver configurado o workspace de acordo com o artigo de início rápido.
Para fazer a implantação localmente, o mecanismo do Docker precisa ser executado localmente. Este passo é altamente recomendado. Ele ajuda você a depurar problemas.
Fazer download do código-fonte
Para acompanhar este tutorial, clone o código-fonte do GitHub.
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Inicializar variáveis de ambiente
Defina variáveis de ambiente:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Implantar um modelo do TensorFlow
Baixe e descompacte um modelo que divide uma entrada por dois e adiciona 2 ao resultado:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Executar uma imagem do TF Serving localmente para testar seu funcionamento
Use o docker para executar a imagem localmente para teste:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Verificar se você pode enviar solicitações de investigação de atividade e pontuação para a imagem
Primeiro, verifique se o contêiner está em atividade, o que significa que o processo dentro do contêiner ainda está em execução. Você deve obter uma resposta 200 (OK).
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Em seguida, verifique se você pode obter previsões sobre dados sem rótulo:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
Parar a imagem
Agora que você testou localmente, pare a imagem:
docker stop tfserving-test
Implantar o ponto de extremidade online no Azure
Depois, implante o ponto de extremidade online no Azure.
Criar um arquivo YAML para seu ponto de extremidade e implantação
Você pode configurar sua implantação de nuvem usando o YAML. Confira o exemplo de YAML para esse exemplo:
tfserving-endpoint.yml
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
tfserving-deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: {{MODEL_VERSION}}
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/{{MODEL_VERSION}}
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
Existem alguns conceitos importantes a serem anotados nesse parâmetro YAML/Python:
Base image
A imagem base é especificada como um parâmetro no ambiente e docker.io/tensorflow/serving:latest é usada neste exemplo. Ao inspecionar o contêiner, você pode descobrir que esse servidor usa ENTRYPOINT para iniciar um script de ponto de entrada, que leva as variáveis de ambiente como MODEL_BASE_PATH e MODEL_NAME e expõe portas como 8501. Esses detalhes são todas informações específicas para esse servidor escolhido. Você pode usar esse reconhecimento do servidor para determinar como definir a implantação. Por exemplo, se você definir variáveis de ambiente para MODEL_BASE_PATH e MODEL_NAME na definição de implantação, o servidor (neste caso, TF Serving) usará os valores para iniciar o servidor. Da mesma forma, se você definir a porta para as rotas como 8501 na definição de implantação, a solicitação do usuário para tais rotas será corretamente direcionada para o servidor TF Serving.
Observe que esse exemplo específico é baseado no caso do TF Serving, mas você pode usar quaisquer contêineres que permanecerão ativos e responderão a solicitações que chegam às rotas de atividade, preparação e pontuação. Você pode consultar outros exemplos e ver como o dockerfile é formado (por exemplo, usando CMD em vez de ENTRYPOINT) para criar os contêineres.
Configuração de inferência
A configuração de inferência é um parâmetro no ambiente e especifica a porta e o caminho para 3 tipos de rota: rota de atividade, preparação e pontuação. A configuração de inferência é obrigatória se você quiser executar seu próprio contêiner com ponto de extremidade online gerenciado.
Rota de preparação vs rota de atividade
O servidor API que você escolher pode fornecer uma forma de verificar o status do servidor. Existem dois tipos de rota que você pode especificar: atividade e preparação. Uma rota de atividade é usada para verificar se o servidor está em execução. Uma rota de preparação é usada para verificar se o servidor está pronto para realizar um trabalho. No contexto de inferência de machine learning, um servidor pode responder 200 OK a uma solicitação de atividade antes de carregar um modelo, e o servidor pode responder 200 OK a uma solicitação de preparação somente após o modelo ser carregado na memória.
Para obter mais informações sobre investigações de atividade e preparação em geral, confira a documentação do Kubernetes.
As rotas de atividade e preparação serão determinadas pelo servidor de API de sua escolha, como você teria identificado ao testar o contêiner localmente na etapa anterior. Observe que o exemplo de implantação neste artigo usa o mesmo caminho para atividade e preparação, já que o TF Serving define apenas uma rota de atividade. Consulte outros exemplos para diferentes padrões para definir as rotas.
Rota de pontuação
O servidor de API que você escolher deve fornecer uma forma de receber o payload para trabalhar. No contexto de inferência de machine learning, um servidor deve receber os dados de entrada por meio de uma rota específica. Identifique essa rota para o seu servidor de API ao testar o contêiner localmente na etapa anterior, e especifique-a ao definir a implantação a ser criada.
Observe que a criação bem-sucedida da implantação também atualizará o parâmetro scoring_uri do ponto de extremidade, que você pode verificar com az ml online-endpoint show -n <name> --query scoring_uri.
Localizar o modelo montado
Quando você implanta um modelo como um ponto de extremidade online, o Azure Machine Learning monta seu modelo em seu ponto de extremidade. A montagem do modelo permite que você implante novas versões do modelo sem ter que criar uma imagem do Docker. Por padrão, um modelo registrado com o nome foo e versão 1 estaria localizado no seguinte caminho dentro do seu contêiner implantado: /var/azureml-app/azureml-models/foo/1
Por exemplo, se você tiver uma estrutura de diretório de /azureml-examples/cli/endpoints/online/custom-container em seu computador local, onde o modelo é nomeado half_plus_two:
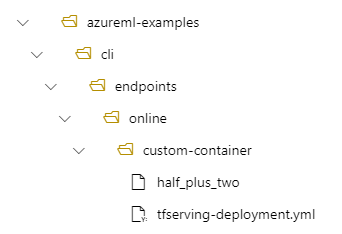
E tfserving-deployment.yml contém:
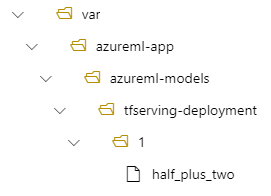
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
Em seguida, seu modelo estará localizado em /var/azureml-app/azureml-models/tfserving-deployment/1 na sua implantação:
Opcionalmente, você pode configurar seu model_mount_path. Ele permite que você altere o caminho onde o modelo está montado.
Importante
O model_mount_path deve ser um caminho absoluto válido no Linux (o sistema operacional da imagem de contêiner).
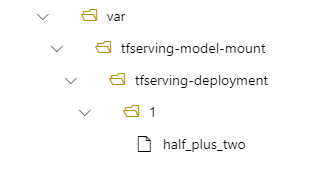
Por exemplo, você pode ter um parâmetro model_mount_path em seu tfserving-deployment.yml:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
.....
Em seguida, seu modelo estará localizado em /var/tfserving-model-mount/tfserving-deployment/1 na sua implantação. Observe que ele não está mais em azureml-app/azureml-models, mas no caminho de montagem especificado:
Criar seu ponto de extremidade e implantação
Agora que você entende como o YAML foi construído, crie seu ponto de extremidade.
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving-endpoint.yml
A criação de uma implantação pode levar alguns minutos.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving-deployment.yml --all-traffic
Invocar o ponto de extremidade
Assim que sua implantação for concluída, confira se você pode fazer uma solicitação de pontuação para o ponto de extremidade implantado.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Excluir o ponto de extremidade
Agora que você pontuou com sucesso com seu ponto de extremidade, você pode excluí-lo:
az ml online-endpoint delete --name tfserving-endpoint