APLICA-SE A: Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Neste artigo, você aprenderá a implantar seu modelo em um ponto de extremidade online para uso em inferências em tempo real. Comece implantando um modelo em seu computador local para depurar qualquer erro. Em seguida, implante e teste o modelo no Azure, exiba os logs de implantação e monitore o SLA (contrato de nível de serviço). Ao final deste artigo, você tem um ponto de extremidade HTTPS/REST escalonável que pode ser usado para inferência em tempo real.
Os pontos de extremidade online são pontos de extremidade usados para inferência em tempo real. Há dois tipos de pontos de extremidade online: pontos de extremidade online gerenciados e pontos de extremidade online do Kubernetes. Para obter mais informações sobre as diferenças, consulte Pontos de extremidade online gerenciados versus pontos de extremidade online do Kubernetes.
Os pontos de extremidade online gerenciados ajudam a implantar seus modelo de machine learning de maneira pronta para uso. Os pontos de extremidade online gerenciados funcionam com computadores com CPU e GPU poderosas no Azure, de maneira escalonável e totalmente gerenciada. Pontos de extremidade online gerenciados cuidam da entrega, escala, proteção e monitoramento dos seus modelos. Essa assistência libera você da sobrecarga de configurar e gerenciar a infraestrutura subjacente.
O exemplo principal neste artigo usa pontos de extremidade online gerenciados para implantação. Para usar o Kubernetes, confira as observações neste documento que estão alinhadas à discussão sobre os pontos de extremidade online gerenciados.
Pré-requisitos
APLICA-SE A:Extensão de ML da CLI do Azurev2 (atual)
A CLI do Azure e a ml extensão para a CLI do Azure, instaladas e configuradas. Para obter mais informações, consulte Instalar e configurar a CLI (v2).
Um shell bash ou um shell compatível, por exemplo, um shell em um sistema Linux ou Subsistema do Windows para Linux. Os exemplos da CLI do Azure neste artigo pressupõem que você use esse tipo de shell.
Um Workspace do Azure Machine Learning. Para obter instruções para criar um workspace, consulte Configurar.
O RBAC (controle de acesso baseado em função) do Azure é usado para conceder acesso a operações no Azure Machine Learning. Para realizar as etapas deste artigo, sua conta de usuário deve ter a função Proprietário ou Colaborador atribuída para o workspace do Azure Machine Learning, ou uma função personalizada deve permitir Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Se você usar o estúdio do Azure Machine Learning para criar e gerenciar pontos de extremidade ou implantações online, precisará da permissão extra Microsoft.Resources/deployments/write do proprietário do grupo de recursos. Para obter mais informações, consulte Gerenciar acesso a workspaces do Azure Machine Learning.
(Opcional) Para implantar localmente, você deve instalar o Mecanismo do Docker em seu computador local.
É altamente recomendável essa opção, o que facilita a depuração de problemas.
APLICA-SE A: SDK Python azure-ai-ml v2 (atual)
Um Workspace do Azure Machine Learning. Para obter etapas para criar um workspace, consulte Criar o workspace.
O SDK do Azure Machine Learning para Python v2. Para instalar o SDK, use o seguinte comando:
pip install azure-ai-ml azure-identity
Para atualizar uma instalação do SDK existente para a versão mais recente, use o seguinte comando:
pip install --upgrade azure-ai-ml azure-identity
Para obter mais informações, consulte a biblioteca de clientes do Pacote do Azure Machine Learning para Python.
O RBAC do Azure é usado para conceder acesso a operações no Azure Machine Learning. Para realizar as etapas deste artigo, sua conta de usuário deve ter a função Proprietário ou Colaborador atribuída para o workspace do Azure Machine Learning, ou uma função personalizada deve permitir Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Para obter mais informações, consulte Gerenciar acesso a workspaces do Azure Machine Learning.
(Opcional) Para implantar localmente, você deve instalar o Mecanismo do Docker em seu computador local.
É altamente recomendável essa opção, o que facilita a depuração de problemas.
Antes de seguir as etapas deste artigo, verifique se você tem os seguintes pré-requisitos:
- Uma assinatura do Azure. Caso não tenha uma assinatura do Azure, crie uma conta gratuita antes de começar. Experimente a versão gratuita ou paga do Azure Machine Learning.
- Um workspace do Azure Machine Learning e uma instância de computação. Se você não tiver esses recursos, consulte Criar recursos necessários para começar.
- O RBAC do Azure é usado para conceder acesso a operações no Azure Machine Learning. Para realizar as etapas deste artigo, sua conta de usuário deve ter a função Proprietário ou Colaborador atribuída para o workspace do Azure Machine Learning, ou uma função personalizada deve permitir
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Para obter mais informações, consulte Gerenciar acesso a um workspace do Azure Machine Learning.
A CLI do Azure e a extensão da CLI para machine learning são usadas nestas etapas, mas não são o foco principal. Eles são usados mais como utilitários para passar modelos para o Azure e verificar o status das implantações de modelo.
A CLI do Azure e a ml extensão para a CLI do Azure, instaladas e configuradas. Para obter mais informações, consulte Instalar e configurar a CLI (v2).
Um shell bash ou um shell compatível, por exemplo, um shell em um sistema Linux ou Subsistema do Windows para Linux. Os exemplos da CLI do Azure neste artigo pressupõem que você use esse tipo de shell.
Um Workspace do Azure Machine Learning. Para obter instruções para criar um workspace, consulte Configurar.
- O RBAC do Azure é usado para conceder acesso a operações no Azure Machine Learning. Para realizar as etapas deste artigo, sua conta de usuário deve ter a função Proprietário ou Colaborador atribuída para o workspace do Azure Machine Learning, ou uma função personalizada deve permitir
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Para obter mais informações, consulte Gerenciar acesso a um workspace do Azure Machine Learning.
Verifique se você tem cota de VM (máquina virtual) suficiente alocada para implantação. O Azure Machine Learning reserva 20% de seus recursos de computação para executar atualizações em algumas versões da VM. Por exemplo, se você solicitar 10 instâncias em uma implantação, deverá ter uma cota de 12 para cada número de núcleos para a versão da VM. A falha ao considerar os recursos computacionais adicionais resulta em um erro. Algumas versões de VM são isentas da reserva de cota extra. Para obter mais informações sobre alocação de cotas, confira Alocação de cotas de máquina virtual para implantação.
Como alternativa, você pode usar a cota do pool de cotas compartilhadas do Azure Machine Learning por um tempo limitado. O Azure Machine Learning fornece um pool de cotas compartilhado do qual os usuários em várias regiões podem acessar a cota para executar testes por um tempo limitado, dependendo da disponibilidade.
Ao usar o estúdio para implantar os modelos Llama-2, Phi, Nemotron, Mistral, Dolly e Deci-DeciLM do catálogo de modelos em um ponto de extremidade online gerenciado, o Azure Machine Learning permite que você acesse seu pool de cotas compartilhadas por um curto período de tempo para que possa executar testes. Para obter mais informações sobre o pool de cotas compartilhado, confira Cota compartilhada do Azure Machine Learning.
Preparar seu sistema
Definir variáveis de ambiente
Se você ainda não definiu os padrões da CLI do Azure, salve as configurações padrão. Para evitar passar os valores para sua assinatura, espaço de trabalho e grupo de recursos várias vezes, execute este código:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Clone o repositório de exemplos
Para acompanhar este artigo, primeiro clone o repositório azureml-examples e, em seguida, altere para o diretório azureml-examples/cli do repositório:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli
Use --depth 1 para clonar apenas a confirmação mais recente no repositório, o que reduz o tempo para concluir a operação.
Os comandos neste tutorial estão nos arquivos deploy-local-endpoint.sh e deploy-managed-online-endpoint.sh no diretório da CLI . Os arquivos de configuração YAML estão no subdiretório endpoints/online/managed/sample/.
Observação
Os arquivos de configuração YAML para pontos de extremidade online do Kubernetes estão nos pontos de extremidade/online/kubernetes/ subdiretório.
Clone o repositório de exemplos
Para executar os exemplos de treinamento, primeiro clone o repositório azureml-examples e, em seguida, altere para o diretório azureml-examples/sdk/python/endpoints/online/managed :
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
Use --depth 1 para clonar apenas a confirmação mais recente no repositório, o que reduz o tempo para concluir a operação.
As informações neste artigo são baseadas no notebook online-endpoints-simple-deployment.ipynb. Ele contém o mesmo conteúdo deste artigo, embora a ordem dos códigos seja um pouco diferente.
Conectar-se ao workspace do Azure Machine Learning
O workspace é o recurso de nível superior do Azure Machine Learning. Ele fornece um local centralizado para trabalhar com todos os artefatos criados quando você usa o Azure Machine Learning. Nesta seção, você se conecta ao workspace no qual executa tarefas de implantação. Para acompanhar, abra seu notebook online-endpoints-simple-deployment.ipynb.
Importe as bibliotecas necessárias:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration
)
from azure.identity import DefaultAzureCredential
Observação
Se você usar o ponto de extremidade online do Kubernetes, importe a classe KubernetesOnlineEndpoint e KubernetesOnlineDeployment da biblioteca azure.ai.ml.entities.
Configure os detalhes do workspace e obtenha um identificador para o workspace.
Para se conectar a um workspace, você precisa desses parâmetros de identificador: uma assinatura, um grupo de recursos e um nome de workspace. Use esses detalhes em MLClient de azure.ai.ml para obter um identificador para o workspace do Azure Machine Learning necessário. Este exemplo usa a autenticação padrão do Azure.
# enter details of your Azure Machine Learning workspace
subscription_id = "<subscription ID>"
resource_group = "<resource group>"
workspace = "<workspace name>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
Se você tiver o Git instalado em seu computador local, poderá seguir as instruções para clonar o repositório de exemplos. Caso contrário, siga as instruções para baixar arquivos do repositório de exemplos.
Clone o repositório de exemplos
Para acompanhar esse artigo, primeiro clone o repositório azureml-examples e, em seguida, altere para o diretório azureml-examples/cli/endpoints/online/model-1.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
Use --depth 1 para clonar apenas a confirmação mais recente no repositório, o que reduz o tempo para concluir a operação.
Baixar arquivos do repositório de exemplos
Se você clonou o repositório de exemplos, seu computador local já tem cópias dos arquivos para este exemplo e você pode pular para a próxima seção. Se você não clonou o repositório, baixe-o no computador local.
- Vá para o repositório de exemplos (azureml-examples).
- Vá para o <> botão Código na página e, na guia Local , selecione Baixar ZIP.
- Localize a pasta /cli/endpoints/online/model-1/model e o arquivo /cli/endpoints/online/model-1/onlinescoring/score.py.
Definir variáveis de ambiente
Defina as variáveis de ambiente a seguir para que você possa usá-las nos exemplos deste artigo. Substitua os valores pela ID da assinatura do Azure, pela região do Azure em que o workspace está localizado, pelo grupo de recursos que contém o workspace e pelo nome do workspace:
export SUBSCRIPTION_ID="<subscription ID>"
export LOCATION="<your region>"
export RESOURCE_GROUP="<resource group>"
export WORKSPACE="<workspace name>"
Alguns exemplos de templates exigem que você carregue arquivos no Armazenamento de Blobs do Azure para o seu espaço de trabalho. As etapas a seguir consultam o workspace e armazenam essas informações em variáveis de ambiente usadas nos exemplos:
Obter um token de acesso:
TOKEN=$(az account get-access-token --query accessToken -o tsv)
Definir a versão da API REST:
API_VERSION="2022-05-01"
Obter as informações de armazenamento:
# Get values for storage account
response=$(curl --location --request GET "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices/workspaces/$WORKSPACE/datastores?api-version=$API_VERSION&isDefault=true" \
--header "Authorization: Bearer $TOKEN")
AZUREML_DEFAULT_DATASTORE=$(echo $response | jq -r '.value[0].name')
AZUREML_DEFAULT_CONTAINER=$(echo $response | jq -r '.value[0].properties.containerName')
export AZURE_STORAGE_ACCOUNT=$(echo $response | jq -r '.value[0].properties.accountName')
Clone o repositório de exemplos
Para acompanhar este artigo, primeiro clone o repositório azureml-examples e, em seguida, altere para o diretório azureml-examples :
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
Use --depth 1 para clonar apenas a confirmação mais recente no repositório, o que reduz o tempo para concluir a operação.
Definir o ponto de extremidade
Para definir um ponto de extremidade online, especifique o nome do ponto de extremidade e o modo de autenticação. Para obter mais informações sobre os pontos de extremidade online gerenciados, confira Pontos de extremidade online.
Definir um nome de ponto de extremidade
Para definir o nome do ponto de extremidade, execute o seguinte comando. Substitua <YOUR_ENDPOINT_NAME> por um nome exclusivo na região do Azure. Para obter mais informações sobre as regras de nomenclatura, consulte os limites do Ponto de Extremidade.
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
O snippet a seguir mostra o arquivo endpoints/online/managed/sample/endpoint.yml:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
A referência para o formato de ponto de extremidade YAML é descrita na tabela a seguir. Para saber como especificar esses atributos, consulte areferência do YAML para ponto de extremidade online . Para obter informações sobre os limites relacionados aos pontos de extremidade gerenciados, consulte pontos de extremidade online do Azure Machine Learning e pontos de extremidade em lote.
| Chave |
Descrição |
$schema |
(Opcional) O esquema YAML. Para ver todas as opções disponíveis no arquivo YAML, você pode visualizar o esquema no exemplo anterior em um navegador. |
name |
O nome do ponto de extremidade. |
auth_mode |
Use key para autenticação baseada em chave.
Use aml_token para autenticação baseada em chave do Azure Machine Learning.
Use aad_token para autenticação baseada em token do Microsoft Entra (versão prévia).
Para obter mais informações sobre autenticação, consulte Autenticar clientes para pontos de extremidade online. |
Primeiro, defina o nome do ponto de extremidade online e, depois, configure o ponto de extremidade.
Substitua <YOUR_ENDPOINT_NAME> por um nome exclusivo na região do Azure ou use o método de exemplo para definir um nome aleatório. Exclua o método que você não usa. Para obter mais informações sobre as regras de nomenclatura, consulte os limites do Ponto de Extremidade.
# method 1: define an endpoint name
endpoint_name = "<YOUR_ENDPOINT_NAME>"
# method 2: example way to define a random name
import datetime
endpoint_name = "endpt-" + datetime.datetime.now().strftime("%m%d%H%M%f")
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name = endpoint_name,
description="this is a sample endpoint",
auth_mode="key"
)
O código anterior usa key para autenticação baseada em chave. Use aml_token para autenticação baseada em token do Azure Machine Learning. Para usar a autenticação baseada em token do Microsoft Entra (versão prévia), use aad_token. Para obter mais informações sobre autenticação, consulte Autenticar clientes para pontos de extremidade online.
Ao implantar no Azure a partir do estúdio, crie um ponto de extremidade e uma implantação para adicioná-lo. Nesse momento, será solicitado que você forneça nomes para o ponto de extremidade e a implantação.
Definir um nome de ponto de extremidade
Para definir o nome do ponto de extremidade, execute o comando a seguir para gerar um nome aleatório. O valor precisa ser exclusivo na região do Azure. Para obter mais informações sobre as regras de nomenclatura, consulte os limites do Ponto de Extremidade.
export ENDPOINT_NAME=endpoint-`echo $RANDOM`
Para definir o ponto de extremidade e a implantação, este artigo usa os modelos do Azure Resource Manager (ARM templates) online-endpoint.json e online-endpoint-deployment.json. Para usar os modelos para definir um ponto de extremidade online e uma implantação, confira a seção Implantar no Azure.
Definir a implantação
Uma implantação é um conjunto de recursos necessários para hospedar o modelo que executa a inferência real. Para este exemplo, você implanta um scikit-learn modelo que faz regressão e usa um script de pontuação score.py para executar o modelo em uma solicitação de entrada específica.
Para saber mais sobre os principais atributos de uma implantação, confira Implantações online.
Sua configuração de implantação usa o local do modelo que você deseja implantar.
O snippet a seguir mostra o arquivo endpoints/online/managed/sample/blue-deployment.yml, com todas as entradas necessárias para configurar uma implantação:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
O arquivo blue-deployment.yml especifica os seguintes atributos de implantação:
-
model: especifica as propriedades do modelo embutidas usando o path parâmetro (de onde carregar arquivos). A CLI carrega automaticamente os arquivos de modelo e registra o modelo com um nome gerado automaticamente.
-
environment: usa definições embutidas que incluem de onde carregar arquivos. A CLI carrega automaticamente o arquivo conda.yaml e registra o ambiente. Posteriormente, para criar o ambiente, a implantação usará o parâmetro image para a imagem base. Neste exemplo, é mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. As conda_file dependências são instaladas sobre a imagem base.
-
code_configuration: Faz o upload dos arquivos locais, como o código-fonte Python para o modelo de pontuação, do ambiente de desenvolvimento durante a implantação.
Para saber mais sobre o esquema YAML, confira a referência YAML do ponto de extremidade online.
Observação
Para usar pontos de extremidade do Kubernetes em vez de pontos de extremidade online gerenciados como um destino de computação:
- Crie o cluster do Kubernetes e anexe-o como um destino de computação ao espaço de trabalho do Azure Machine Learning usando o Estúdio do Azure Machine Learning.
- Use o YAML do ponto de extremidade para segmentar o Kubernetes em vez do YAML do ponto de extremidade gerenciado. É necessário editar o YAML para alterar o valor de
compute para o nome do destino de computação registrado. Você pode usar este arquivo deployment.yaml que contém outras propriedades aplicáveis a um deployment no Kubernetes.
Todos os comandos usados neste artigo para pontos de extremidade online gerenciados também se aplicam aos pontos de extremidade do Kubernetes, exceto pelos seguintes recursos que não se aplicam aos pontos de extremidade do Kubernetes:
Use o seguinte código para configurar uma implantação:
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
-
Model: especifica as propriedades do modelo embutidas usando o path parâmetro (de onde carregar arquivos). O SDK carrega automaticamente os arquivos de modelo e registra o modelo com um nome gerado automaticamente.
-
Environment: usa definições embutidas que incluem de onde carregar arquivos. O SDK carrega automaticamente o arquivo conda.yaml e registra o ambiente. Posteriormente, para criar o ambiente, a implantação usará o parâmetro image para a imagem base. Neste exemplo, é mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. As conda_file dependências são instaladas sobre a imagem base.
-
CodeConfiguration: Faz o upload dos arquivos locais, como o código-fonte Python para o modelo de pontuação, do ambiente de desenvolvimento durante a implantação.
Para obter mais informações sobre a definição de implantação online, confira Classe OnlineDeployment.
Ao implantar no Azure, crie um ponto de extremidade e uma implantação para adicioná-lo. Nesse momento, será solicitado que você forneça nomes para o ponto de extremidade e a implantação.
Como funciona o script de pontuação
O formato do script de pontuação para pontos de extremidade online é o mesmo formato usado na versão anterior da CLI e no SDK do Python.
O script de pontuação especificado em code_configuration.scoring_script deve ter uma função init() e uma função run().
O script de pontuação deve ter uma função init() e uma função run().
O script de pontuação deve ter uma função init() e uma função run().
O script de pontuação deve ter uma função init() e uma função run(). Este artigo usa o arquivo score.py.
Ao usar um modelo para implantação, você deve primeiro carregar o arquivo de pontuação no Armazenamento de Blobs e registrá-lo:
O código a seguir usa o comando az storage blob upload-batch da CLI do Azure para carregar o arquivo de pontuação:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/score -s cli/endpoints/online/model-1/onlinescoring --account-name $AZURE_STORAGE_ACCOUNT
O código a seguir usa um modelo para registrar o código:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/code-version.json \
--parameters \
workspaceName=$WORKSPACE \
codeAssetName="score-sklearn" \
codeUri="https://$AZURE_STORAGE_ACCOUNT.blob.core.windows.net/$AZUREML_DEFAULT_CONTAINER/score"
Este exemplo usa o arquivo score.py do repositório que você clonou ou baixou anteriormente:
import os
import logging
import json
import numpy
import joblib
def init():
"""
This function is called when the container is initialized/started, typically after create/update of the deployment.
You can write the logic here to perform init operations like caching the model in memory
"""
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment.
# It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION)
# Please provide your model's folder name if there is one
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl"
)
# deserialize the model file back into a sklearn model
model = joblib.load(model_path)
logging.info("Init complete")
def run(raw_data):
"""
This function is called for every invocation of the endpoint to perform the actual scoring/prediction.
In the example we extract the data from the json input and call the scikit-learn model's predict()
method and return the result back
"""
logging.info("model 1: request received")
data = json.loads(raw_data)["data"]
data = numpy.array(data)
result = model.predict(data)
logging.info("Request processed")
return result.tolist()
A função init() é chamada quando o contêiner é inicializado ou iniciado. Normalmente, essa inicialização ocorre logo depois que a implantação é criada ou atualizada. A função init é o local para escrever a lógica das operações de inicialização global, como o armazenamento em cache do modelo na memória (conforme mostrado neste arquivo score.py).
A run() função é chamada sempre que o ponto de extremidade é invocado. Ele faz a pontuação e a previsão reais. Neste arquivo score.py, a função run() extrai dados de uma entrada JSON, chama o método predict() do modelo do scikit-learn e, em seguida, retorna o resultado da previsão.
Implantar e depurar localmente usando um ponto de extremidade local
É altamente recomendável que você execute um teste no seu endpoint localmente para validar e depurar seu código e configuração antes de publicar no Azure. A CLI do Azure e o SDK do Python dão suporte a implantações e pontos de extremidade locais, mas o Estúdio do Azure Machine Learning e os modelos do ARM não.
Para implantar localmente, o Mecanismo do Docker deve estar instalado e em execução. O Mecanismo do Docker normalmente é iniciado quando o computador é iniciado. Caso ele não seja, solucione o problema do Mecanismo do Docker.
Você pode usar o pacote Python do servidor HTTP de inferência do Azure Machine Learning para depurar seu script de pontuação localmente sem o Mecanismo do Docker. A depuração com o servidor de inferência ajuda a depurar o script de pontuação antes de implantá-lo em pontos de extremidade locais, para que você possa depurar sem ser afetado pelas configurações do contêiner de implantação.
Para mais informações sobre como depurar pontos de extremidade online localmente antes de implantá-los no Azure, confira Depuração de ponto de extremidade online.
Implantar o modelo localmente
Primeiro, crie um ponto de extremidade. Opcionalmente, para um ponto de extremidade local, você pode ignorar essa etapa. Você pode criar a implantação diretamente (próxima etapa), que, por sua vez, cria os metadados necessários. A implantação de modelos localmente é útil para fins de desenvolvimento e teste.
az ml online-endpoint create --local -n $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
ml_client.online_endpoints.begin_create_or_update(endpoint, local=True)
O estúdio não dá suporte a pontos de extremidade locais. Para saber como testar o ponto de extremidade localmente, confira as guias CLI do Azure ou Python.
O modelo não dá suporte a pontos de extremidade locais. Para saber como testar o ponto de extremidade localmente, confira as guias CLI do Azure ou Python.
Agora, crie a implantação chamada blue no ponto de extremidade.
az ml online-deployment create --local -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml
O sinalizador --local direciona a CLI para implantar o ponto de extremidade no ambiente do Docker.
ml_client.online_deployments.begin_create_or_update(
deployment=blue_deployment, local=True
)
O sinalizador local=True direciona o SDK para implantar o endpoint no ambiente do Docker.
O estúdio não dá suporte a pontos de extremidade locais. Para saber como testar o ponto de extremidade localmente, confira as guias CLI do Azure ou Python.
O modelo não dá suporte a pontos de extremidade locais. Para saber como testar o ponto de extremidade localmente, confira as guias CLI do Azure ou Python.
Verifique se a implantação local foi bem-sucedida
Verifique o status da implantação para ver se o modelo foi implantado sem erros:
az ml online-endpoint show -n $ENDPOINT_NAME --local
A saída deve ter aparência similar ao seguinte JSON. O provisioning_state parâmetro é Succeeded.
{
"auth_mode": "key",
"location": "local",
"name": "docs-endpoint",
"properties": {},
"provisioning_state": "Succeeded",
"scoring_uri": "http://localhost:49158/score",
"tags": {},
"traffic": {}
}
ml_client.online_endpoints.get(name=endpoint_name, local=True)
O método retorna ManagedOnlineEndpoint entidade. O provisioning_state parâmetro é Succeeded.
ManagedOnlineEndpoint({'public_network_access': None, 'provisioning_state': 'Succeeded', 'scoring_uri': 'http://localhost:49158/score', 'swagger_uri': None, 'name': 'endpt-10061534497697', 'description': 'this is a sample endpoint', 'tags': {}, 'properties': {}, 'id': None, 'Resource__source_path': None, 'base_path': '/path/to/your/working/directory', 'creation_context': None, 'serialize': <msrest.serialization.Serializer object at 0x7ffb781bccd0>, 'auth_mode': 'key', 'location': 'local', 'identity': None, 'traffic': {}, 'mirror_traffic': {}, 'kind': None})
O estúdio não dá suporte a pontos de extremidade locais. Para saber como testar o ponto de extremidade localmente, confira as guias CLI do Azure ou Python.
O modelo não dá suporte a pontos de extremidade locais. Para saber como testar o ponto de extremidade localmente, confira as guias CLI do Azure ou Python.
A tabela a seguir contém os possíveis valores para provisioning_state:
| Valor |
Descrição |
Creating |
O recurso está sendo criado. |
Updating |
O recurso está sendo atualizado. |
Deleting |
O recurso está sendo excluído. |
Succeeded |
A operação de criação ou atualização foi bem-sucedida. |
Failed |
Falha na operação de criação, atualização ou exclusão. |
Invocar o ponto de extremidade local para pontuar os dados usando o modelo
Invoque o ponto de extremidade para pontuar o modelo usando o comando invoke e passando os parâmetros de consulta armazenados em um arquivo JSON:
az ml online-endpoint invoke --local --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Se você quiser usar um cliente REST (como a ondulação), deverá ter o URI de pontuação. Para obter o URI de pontuação, execute az ml online-endpoint show --local -n $ENDPOINT_NAME. Nos dados retornados, encontre o atributo scoring_uri.
Invoque o ponto de extremidade para pontuar o modelo usando o comando fácil invoke e passando os parâmetros de consulta que são armazenados em um arquivo JSON.
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
request_file="../model-1/sample-request.json",
local=True,
)
Se você quiser usar um cliente REST (como a ondulação), deverá ter o URI de pontuação. Para obter o URI de pontuação, execute o código a seguir. Nos dados retornados, encontre o atributo scoring_uri.
endpoint = ml_client.online_endpoints.get(endpoint_name, local=True)
scoring_uri = endpoint.scoring_uri
O estúdio não dá suporte a pontos de extremidade locais. Para saber como testar o ponto de extremidade localmente, confira as guias CLI do Azure ou Python.
O modelo não dá suporte a pontos de extremidade locais. Para saber como testar o ponto de extremidade localmente, confira as guias CLI do Azure ou Python.
Examinar os logs em busca da saída da operação de invocação
No exemplo o arquivo score.py, o método run() registra uma saída no console.
Você pode visualizar essa saída usando o comando get-logs:
az ml online-deployment get-logs --local -n blue --endpoint $ENDPOINT_NAME
Você pode visualizar essa saída usando o método get_logs:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, local=True, lines=50
)
O estúdio não dá suporte a pontos de extremidade locais. Para saber como testar o ponto de extremidade localmente, confira as guias CLI do Azure ou Python.
O modelo não dá suporte a pontos de extremidade locais. Para saber como testar o ponto de extremidade localmente, confira as guias CLI do Azure ou Python.
Implantar o ponto de extremidade online no Azure
Depois, implante o ponto de extremidade online no Azure. Como prática recomendada para produção, recomendamos que você registre o modelo e o ambiente usados em sua implantação.
Registrar modelo e ambiente
Recomendamos que você registre seu modelo e ambiente antes da implantação no Azure, para que possa especificar seus nomes e versões registrados durante a implantação. Depois de registrar seus ativos, você pode reutilizá-los sem a necessidade de carregá-los sempre que criar implantações. Essa prática aumenta a reprodutibilidade e a rastreabilidade.
Ao contrário da implantação no Azure, a implantação local não dá suporte ao uso de modelos e ambientes registrados. Em vez disso, a implantação local usa arquivos de modelo locais e usa ambientes somente com arquivos locais.
Para implantação no Azure, você pode usar ativos locais ou registrados (modelos e ambientes). Nesta seção do artigo, a implantação no Azure usa ativos registrados, mas você tem a opção de usar ativos locais. Para obter um exemplo de uma configuração de implantação que carrega arquivos locais a serem usados para implantação local, confira Configurar uma implantação.
Para registrar o modelo e o ambiente, use o formulário model: azureml:my-model:1 ou environment: azureml:my-env:1.
Para registro, você pode extrair as definições YAML de model e environment em arquivos YAML separados na pasta endpoints/online/managed/sample, e usar os comandos az ml model create e az ml environment create. Para saber mais sobre esses comandos, execute az ml model create -h e az ml environment create -h.
Crie uma definição yaml para o modelo. Nomeie o arquivo model.yml:
$schema: https://azuremlschemas.azureedge.net/latest/model.schema.json
name: my-model
path: ../../model-1/model/
Registre o modelo:
az ml model create -n my-model -v 1 -f endpoints/online/managed/sample/model.yml
Crie uma definição yaml para o ambiente. Nomeie o arquivo environment.yml:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: my-env
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
conda_file: ../../model-1/environment/conda.yaml
Registre o ambiente:
az ml environment create -n my-env -v 1 -f endpoints/online/managed/sample/environment.yml
Para obter mais informações sobre como registrar seu modelo como um ativo, consulte Registrar um modelo usando a CLI do Azure ou o SDK do Python. Para obter mais informações sobre como criar um ambiente, consulte Criar um ambiente personalizado.
Registre um modelo:
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
file_model = Model(
path="../model-1/model/",
type=AssetTypes.CUSTOM_MODEL,
name="my-model",
description="Model created from local file.",
)
ml_client.models.create_or_update(file_model)
Registre o ambiente:
from azure.ai.ml.entities import Environment
env_docker_conda = Environment(
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file="../model-1/environment/conda.yaml",
name="my-env",
description="Environment created from a Docker image plus Conda environment.",
)
ml_client.environments.create_or_update(env_docker_conda)
Para saber como registrar seu modelo como um ativo para que você possa especificar seu nome e versão registrados durante a implantação, consulte Registrar um modelo usando a CLI do Azure ou o SDK do Python.
Para obter mais informações sobre como criar um ambiente, consulte Criar um ambiente personalizado.
Registre o modelo
Um registro de modelo é uma entidade lógica no workspace que pode conter um só arquivo de modelo ou um diretório de vários arquivos. Como prática recomendada para produção, registre o modelo e o ambiente. Antes de criar o ponto de extremidade e a implantação neste artigo, registre a pasta do modelo que contém o modelo.
Para registrar o modelo de exemplo, siga estas etapas:
Acesse o Estúdio do Azure Machine Learning.
No painel esquerdo, selecione a página Modelos .
Selecione Registrar e, em seguida, De arquivos locais.
Selecione Tipo não especificado para o Tipo de modelo.
Selecione Procurar e escolha Procurar pasta.
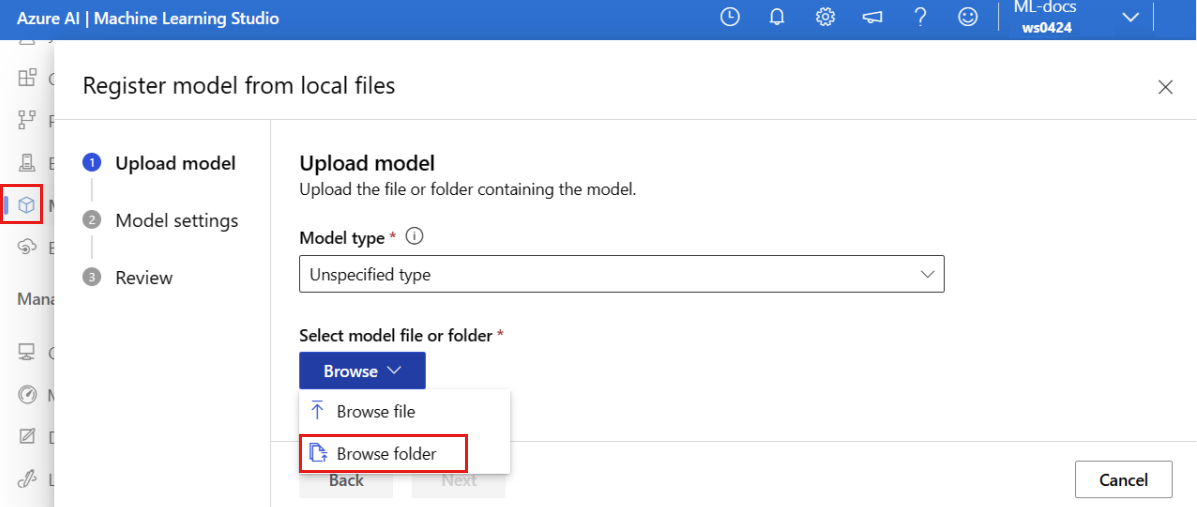
Selecione a pasta \azureml-examples\cli\endpoints\online\model-1\model na cópia local do repositório que você clonou ou baixou anteriormente. Quando for solicitado, selecione Carregar e aguarde a conclusão do upload.
Selecione Próximo.
Insira um nome amigável para o modelo. As etapas neste artigo pressupõem que o modelo seja nomeado model-1.
Selecione Avançar e selecione Registrar para concluir o registro.
Para obter mais informações sobre como trabalhar com modelos registrados, consulte Trabalhar com modelos registrados.
Criar e registrar o ambiente
No painel esquerdo, selecione a página Ambientes .
Selecione a guia Ambientes personalizados e, em seguida, escolha Criar.
Na página Configurações, insira um nome, como my-env para o ambiente.
Para Selecionar fonte do ambiente, escolha Usar imagem do Docker existente com fonte conda opcional.
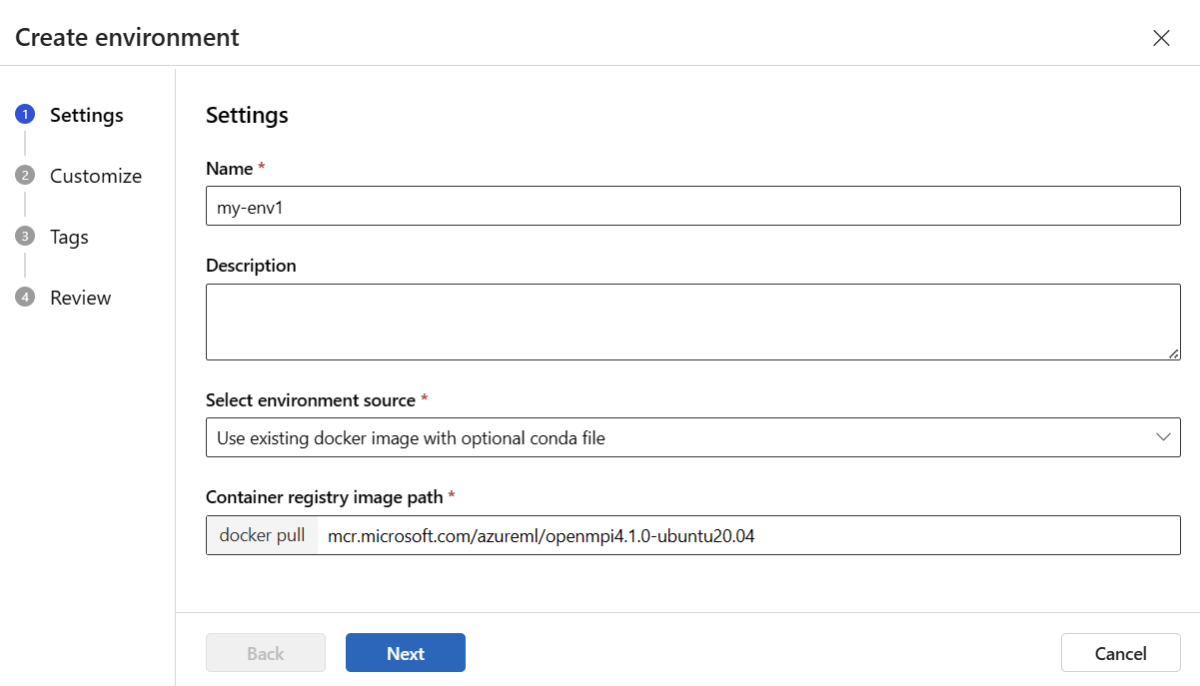
Selecione Avançar para ir para a página Personalizar .
Copie o conteúdo do arquivo \azureml-examples\cli\endpoints\online\model-1\environment\conda.yaml do repositório que você clonou ou baixou anteriormente.
Cole o conteúdo na caixa de texto.
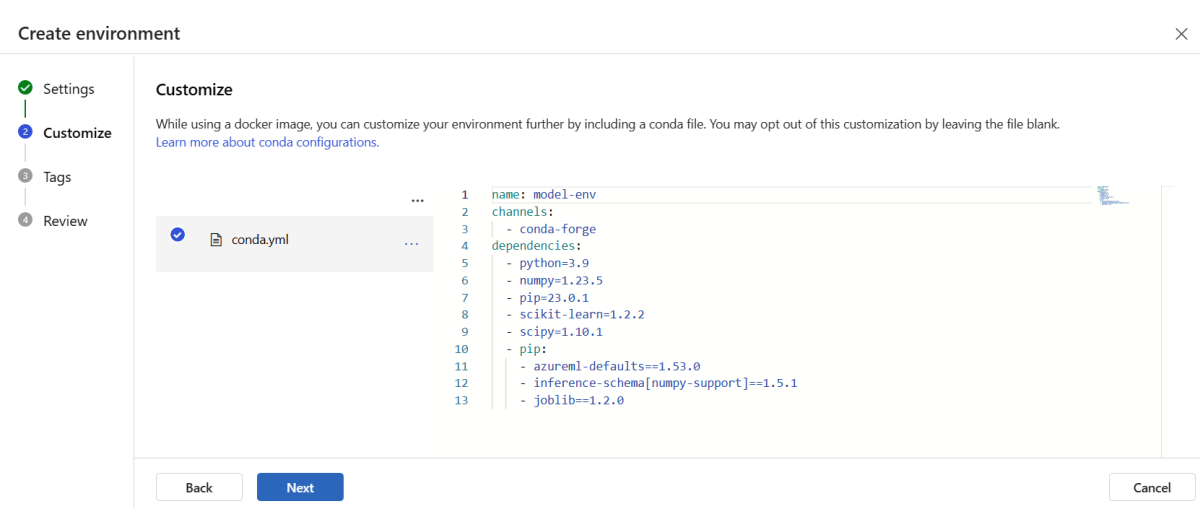
Selecione Avançar até chegar à página Criar e selecione Criar.
Para obter mais informações sobre como criar um ambiente no estúdio, consulte Criar um ambiente.
Para registrar o modelo usando um modelo predefinido, primeiro você deve carregar o arquivo de modelo no Armazenamento de Blobs. O exemplo a seguir usa o comando az storage blob upload-batch para carregar um arquivo no armazenamento padrão para seu workspace:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/model -s cli/endpoints/online/model-1/model --account-name $AZURE_STORAGE_ACCOUNT
Depois de carregar o arquivo, use o modelo para criar um registro de modelo. No exemplo a seguir, o parâmetro modelUri contém o caminho para o modelo:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/model-version.json \
--parameters \
workspaceName=$WORKSPACE \
modelAssetName="sklearn" \
modelUri="azureml://subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/workspaces/$WORKSPACE/datastores/$AZUREML_DEFAULT_DATASTORE/paths/model/sklearn_regression_model.pkl"
Parte do ambiente é um arquivo conda que especifica as dependências de modelo necessárias para hospedar o modelo. O exemplo a seguir demonstra como ler o conteúdo do arquivo conda em variáveis de ambiente:
CONDA_FILE=$(cat cli/endpoints/online/model-1/environment/conda.yaml)
O exemplo a seguir demonstra como usar o modelo para registrar o ambiente. O conteúdo do arquivo conda da etapa anterior é passado para o modelo usando o condaFile parâmetro:
ENV_VERSION=$RANDOM
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/environment-version.json \
--parameters \
workspaceName=$WORKSPACE \
environmentAssetName=sklearn-env \
environmentAssetVersion=$ENV_VERSION \
dockerImage=mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20210727.v1 \
condaFile="$CONDA_FILE"
Importante
Ao definir um ambiente personalizado para sua implantação, verifique se o azureml-inference-server-http pacote está incluído no arquivo conda. Esse pacote é essencial para que o servidor de inferência funcione corretamente. Se você não estiver familiarizado com como criar seu próprio ambiente personalizado, use um de nossos ambientes selecionados, como minimal-py-inference (para modelos personalizados que não usam mlflow) ou mlflow-py-inference (para modelos que usam mlflow). Você pode encontrar esses ambientes curados na guia Ambientes da sua instância do Azure Machine Learning Studio.
Sua configuração de implantação usa o modelo registrado que você deseja implantar e seu ambiente registrado.
Use os ativos registrados (modelo e ambiente) em sua definição de implantação. O trecho a seguir mostra o arquivo endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml, com todas as entradas obrigatórias para configurar uma implantação:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:my-model:1
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment: azureml:my-env:1
instance_type: Standard_DS3_v2
instance_count: 1
Para configurar uma implantação, use o modelo e o ambiente registrados:
model = "azureml:my-model:1"
env = "azureml:my-env:1"
blue_deployment_with_registered_assets = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
Ao implantar a partir do estúdio, crie um ponto de extremidade e uma implantação para adicionar a ele. Nesse momento, você será solicitado a inserir nomes para o ponto de extremidade e a implantação.
Usar diferentes imagens e tipos de instância de GPU e CPU
Você pode especificar os tipos de instância de CPU ou GPU e as imagens em sua definição de implantação, tanto para a implantação local quanto para a implantação no Azure.
Sua definição de implantação no arquivo blue-deployment-with-registered-assets.yml utilizou uma instância de uso geral do tipo Standard_DS3_v2 e uma imagem Docker que não utiliza GPU mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. Para computação com GPU, escolha uma versão de tipo de computação com GPU e uma imagem do Docker com GPU.
Para tipos de instância com suporte, de uso geral e com GPU, confira Lista de SKUs de pontos de extremidade online gerenciados. Para obter uma lista de imagens de base de GPU e CPU do Azure Machine Learning, confira Imagens de base do Azure Machine Learning.
Você pode especificar os tipos de instância de CPU ou GPU e as imagens na configuração de implantação, tanto para a implantação local quanto para a implantação no Azure.
Anteriormente, você configurou uma implantação que usava uma instância Standard_DS3_v2 do tipo de uso geral e uma imagem do Docker sem GPU mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. Para computação com GPU, escolha uma versão de tipo de computação com GPU e uma imagem do Docker com GPU.
Para tipos de instância com suporte, de uso geral e com GPU, confira Lista de SKUs de pontos de extremidade online gerenciados. Para obter uma lista de imagens de base de GPU e CPU do Azure Machine Learning, confira Imagens de base do Azure Machine Learning.
O registro anterior do ambiente especifica uma imagem do Docker sem GPU mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04 passando o valor para o modelo environment-version.json usando o parâmetro dockerImage. Para uma computação com GPU, forneça um valor para uma imagem do Docker com GPU ao modelo (use o parâmetro dockerImage) e forneça uma versão de tipo de computação com GPU ao modelo online-endpoint-deployment.json (use o parâmetro skuName).
Para tipos de instância com suporte, de uso geral e com GPU, confira Lista de SKUs de pontos de extremidade online gerenciados. Para obter uma lista de imagens de base de GPU e CPU do Azure Machine Learning, confira Imagens de base do Azure Machine Learning.
Depois, implante o ponto de extremidade online no Azure.
Implantar no Azure
Crie o ponto de acesso na nuvem Azure.
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Crie a implantação denominada blue no ponto de extremidade:
az ml online-deployment create --name blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml --all-traffic
A criação da implantação pode levar até 15 minutos, dependendo se o ambiente ou imagem subjacente está sendo criado pela primeira vez. As implantações seguintes que usam o mesmo ambiente são processadas mais rapidamente.
Se você preferir não bloquear o console da CLI, adicione o sinalizador --no-wait ao comando. No entanto, essa opção interrompe a exibição interativa do status da implantação.
O sinalizador --all-traffic no código az ml online-deployment create usado para criar a implantação aloca 100% do tráfego do ponto de extremidade para a implantação azul recém-criada. Usar esse sinalizador é útil para fins de desenvolvimento e teste, mas, para produção, talvez você queira rotear o tráfego para a nova implantação por meio de um comando explícito. Por exemplo, use az ml online-endpoint update -n $ENDPOINT_NAME --traffic "blue=100".
Criar o ponto de extremidade:
Usando o parâmetro endpoint definido anteriormente e o parâmetro MLClient criado anteriormente, agora você pode criar o ponto de extremidade no espaço de trabalho. Esse comando inicia a criação do ponto de extremidade e retorna uma resposta de confirmação enquanto a criação do ponto de extremidade continuar.
ml_client.online_endpoints.begin_create_or_update(endpoint)
Criar a implantação:
Usando o blue_deployment_with_registered_assets parâmetro que você definiu anteriormente e o MLClient parâmetro que você criou anteriormente, agora você pode criar a implantação no workspace. Esse comando iniciará a criação da implantação e retornará uma resposta de confirmação enquanto a criação da implantação continuar.
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Se preferir não bloquear o console do Python, adicione o sinalizador no_wait=True aos parâmetros. No entanto, essa opção interrompe a exibição interativa do status da implantação.
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint)
Criar um ponto de extremidade online gerenciado e uma implantação
Use o estúdio para criar um ponto de extremidade online gerenciado diretamente no navegador. Ao criar um ponto de extremidade online gerenciado no estúdio, você precisa definir uma implantação inicial. Não é possível criar um ponto de extremidade online gerenciado vazio.
Outra forma de criar um ponto de extremidade online gerenciado no estúdio é a partir da página Modelos. Essa é uma forma fácil de adicionar um modelo a uma implantação online gerenciada existente. Para implantar o modelo denominado model-1 que você registrou anteriormente na seção Registrar modelo e ambiente:
Acesse o Estúdio do Azure Machine Learning.
No painel esquerdo, selecione a página Modelos .
Selecione o modelo chamado model-1.
Selecione Implantar> Ponto de extremidade em tempo real.
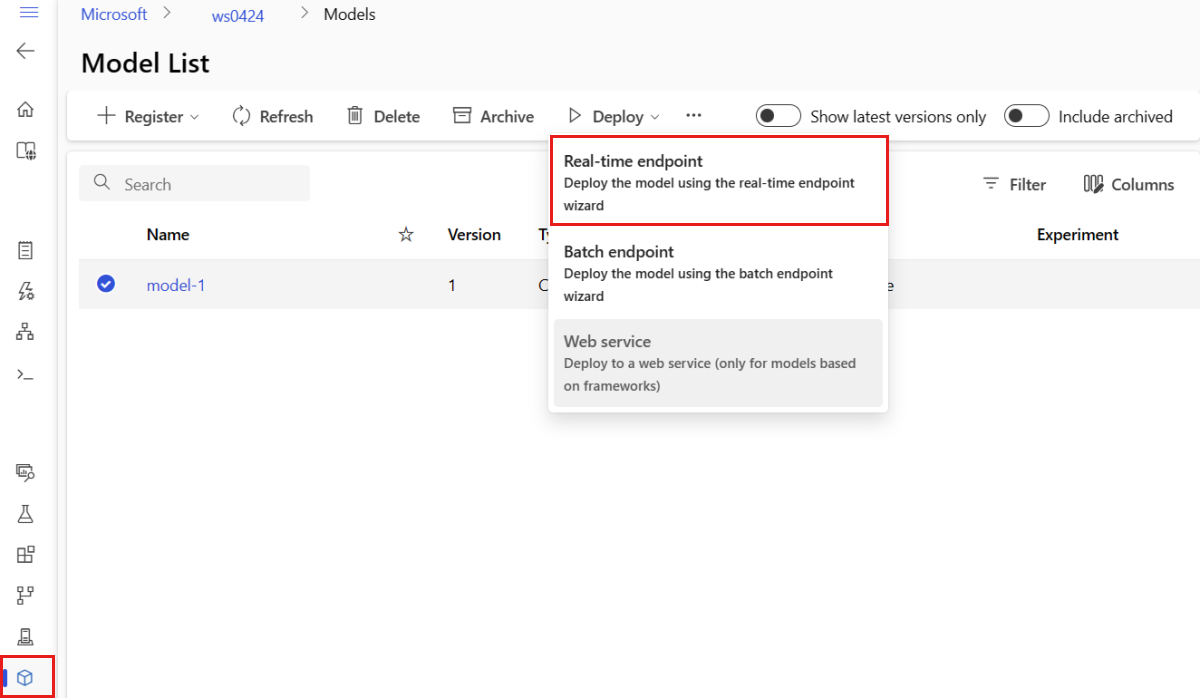
Essa ação abre uma janela em que você pode especificar detalhes sobre seu ponto de extremidade.
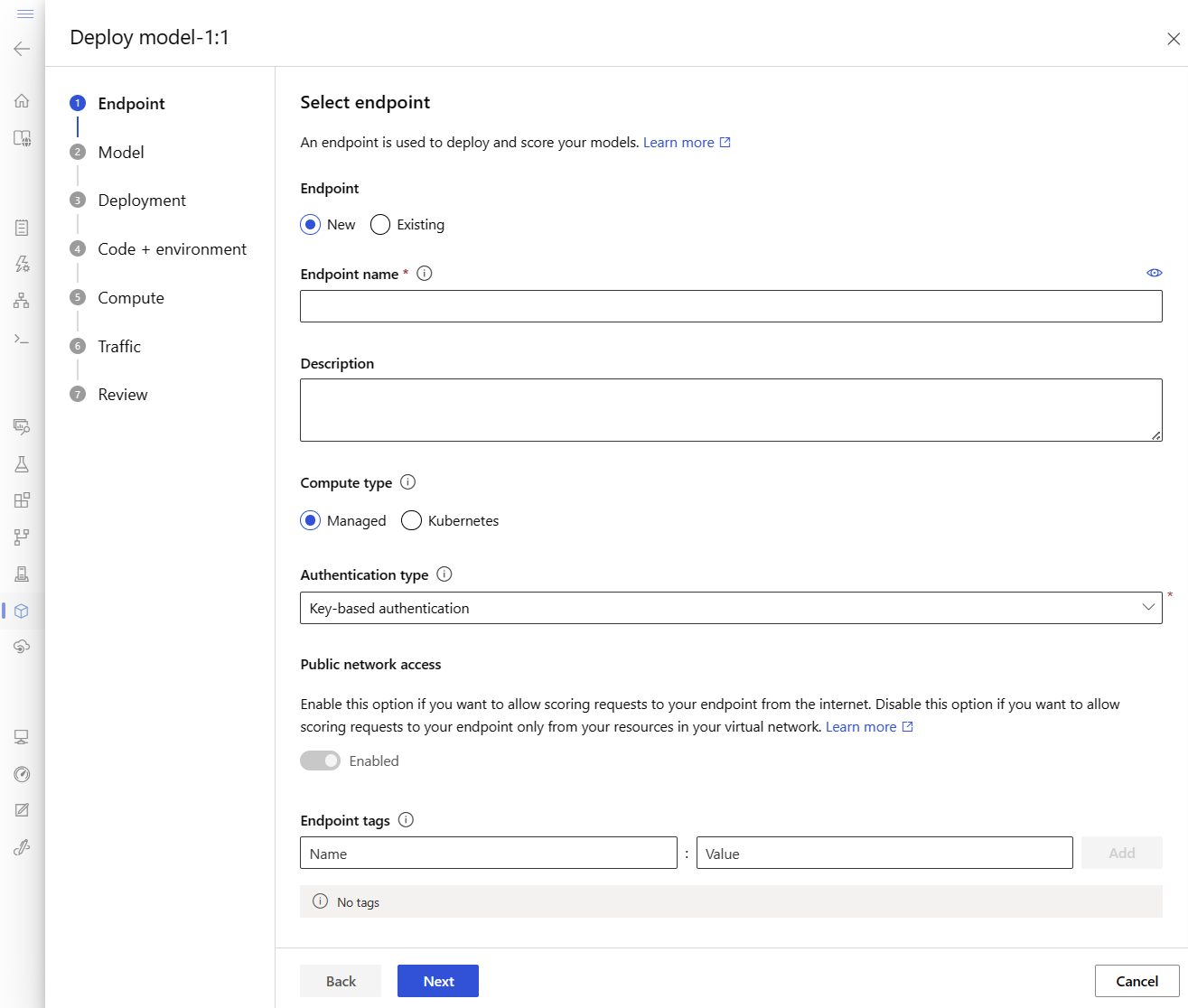
Insira um nome de endpoint específico na região do Azure. Para obter mais informações sobre as regras de nomenclatura, consulte os limites do Ponto de Extremidade.
Mantenha a seleção padrão: Gerenciado para o tipo de computação.
Mantenha a seleção padrão: autenticação baseada em chave para o tipo de autenticação. Para obter mais informações sobre autenticação, consulte Autenticar clientes para pontos de extremidade online.
Selecione Avançar até chegar à página Implantação . Alterne Diagnóstico do Application Insights para Habilitado para que você possa ver gráficos das atividades do ponto de extremidade no estúdio posteriormente e analisar métricas e logs usando o Application Insights.
Selecione Avançar para ir para a página Código + ambiente. Selecione as seguintes opções:
-
Selecione um script de pontuação para inferência: procure e selecione o arquivo \azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py do repositório que você clonou ou baixou anteriormente.
-
Seção Selecionar ambiente: selecione Ambientes personalizados e, em seguida, selecione o ambiente my-env:1 que você criou anteriormente.
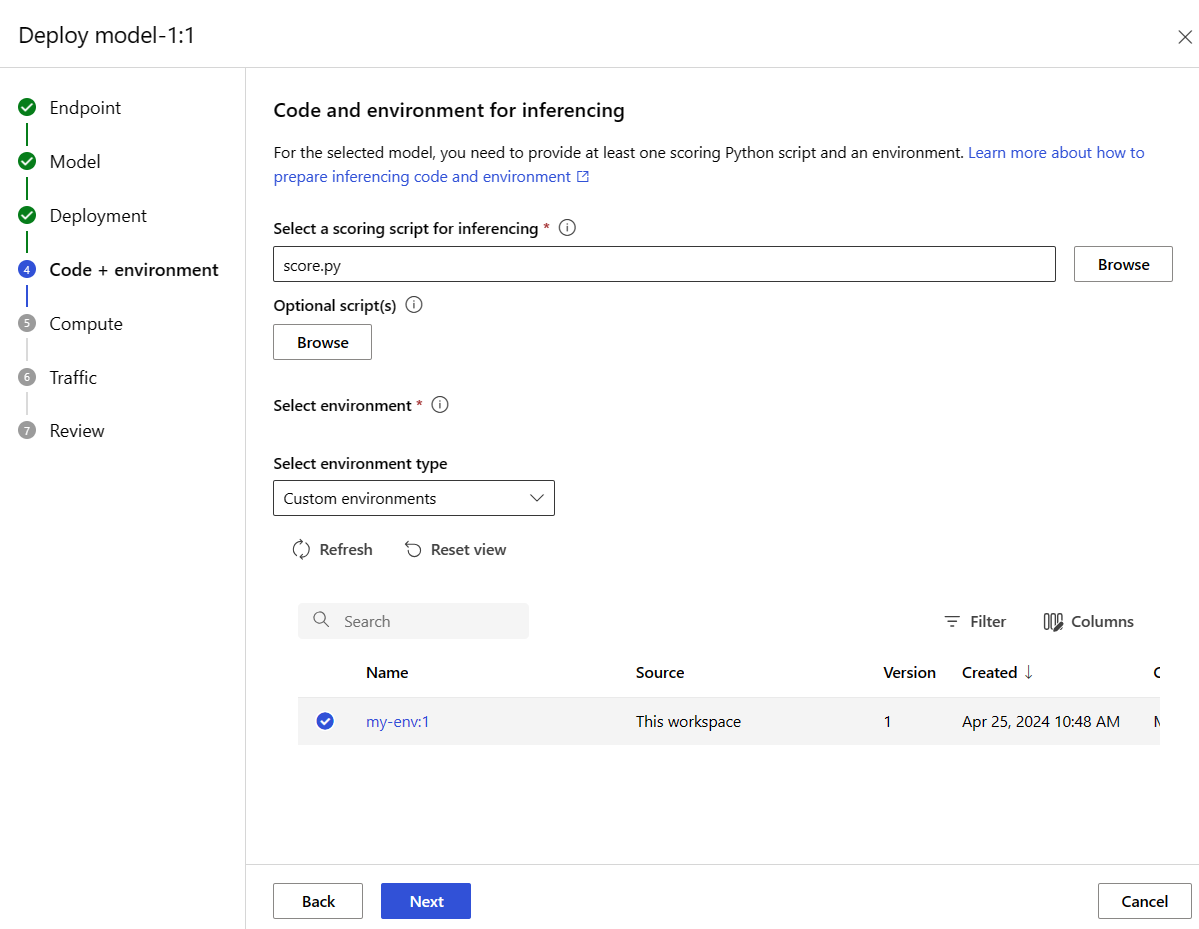
Selecione Avançar e aceite os padrões até que você seja solicitado a criar a implantação.
Examine as configurações de implantação e selecione Criar.
Como alternativa, você pode criar um ponto de extremidade online gerenciado na página Ponto de extremidade do estúdio.
Acesse o Estúdio do Azure Machine Learning.
No painel esquerdo, selecione a página Endpoints.
Selecione + Criar.
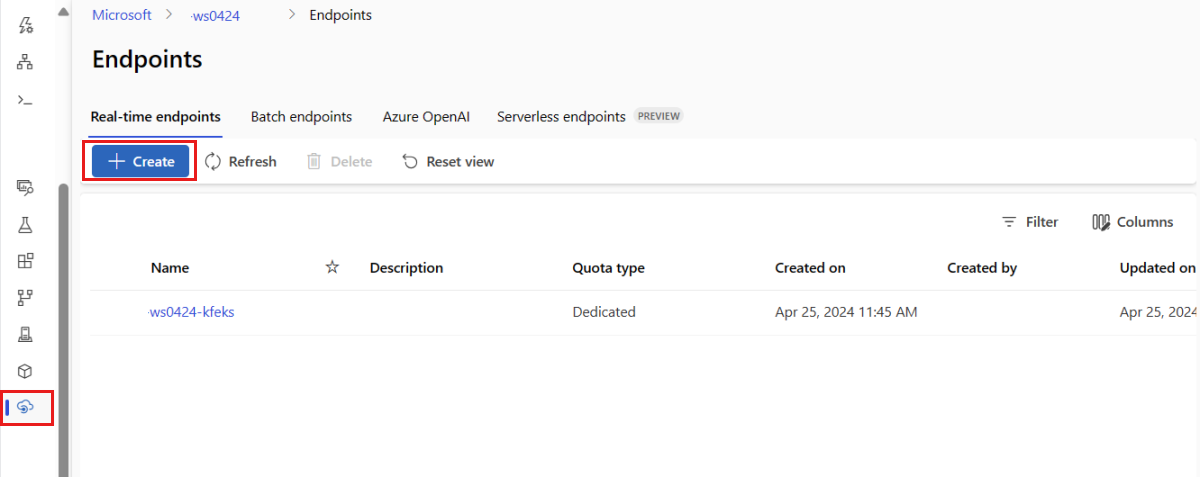
Essa ação abre uma janela para que você selecione o modelo e especifique detalhes sobre o ponto de extremidade e a implantação. Insira as configurações do ponto de extremidade e da implantação, conforme descrito anteriormente, e selecione Criar para criar a implantação.
Use o modelo para criar um ponto de extremidade online:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint.json \
--parameters \
workspaceName=$WORKSPACE \
onlineEndpointName=$ENDPOINT_NAME \
identityType=SystemAssigned \
authMode=AMLToken \
location=$LOCATION
Implante o modelo no ponto de extremidade após a criação do ponto de extremidade:
resourceScope="/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices"
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint-deployment.json \
--parameters \
workspaceName=$WORKSPACE \
location=$LOCATION \
onlineEndpointName=$ENDPOINT_NAME \
onlineDeploymentName=blue \
codeId="$resourceScope/workspaces/$WORKSPACE/codes/score-sklearn/versions/1" \
scoringScript=score.py \
environmentId="$resourceScope/workspaces/$WORKSPACE/environments/sklearn-env/versions/$ENV_VERSION" \
model="$resourceScope/workspaces/$WORKSPACE/models/sklearn/versions/1" \
endpointComputeType=Managed \
skuName=Standard_F2s_v2 \
skuCapacity=1
Para depurar erros em sua implantação, confira Solução de problemas de implantações de pontos de extremidade online.
Verificar o status do ponto de extremidade online
Use o comando show para exibir informações em provisioning_state sobre o ponto de extremidade e a implantação:
az ml online-endpoint show -n $ENDPOINT_NAME
Liste todos os pontos de extremidade no workspace em um formato de tabela usando o comando list:
az ml online-endpoint list --output table
Verifique o status do ponto de extremidade para ver se o modelo foi implantado sem erros:
ml_client.online_endpoints.get(name=endpoint_name)
Liste todos os pontos de extremidade no workspace em um formato de tabela usando o método list:
for endpoint in ml_client.online_endpoints.list():
print(endpoint.name)
O método retorna a lista (iterador) de entidades ManagedOnlineEndpoint.
Você pode obter mais informações especificando mais parâmetros. Por exemplo, gere a lista de pontos de extremidade como uma tabela:
print("Kind\tLocation\tName")
print("-------\t----------\t------------------------")
for endpoint in ml_client.online_endpoints.list():
print(f"{endpoint.kind}\t{endpoint.location}\t{endpoint.name}")
Ver os pontos de extremidade online gerenciados
Você pode exibir todos os pontos de extremidade online que você gerencia na página Pontos de Extremidade. Vá para a página Detalhes do ponto de extremidade para encontrar informações críticas, como o URI do ponto de extremidade, status, ferramentas de teste, monitores de atividade, logs de implantação e código de consumo de exemplo.
No painel esquerdo, selecione Endpoints para ver uma lista de todos os endpoints no espaço de trabalho.
(Opcional) Crie um filtro no tipo de computação para mostrar apenas tipos de computação gerenciados .
Selecione o nome de um ponto de extremidade para exibir a página Detalhes do ponto de extremidade.
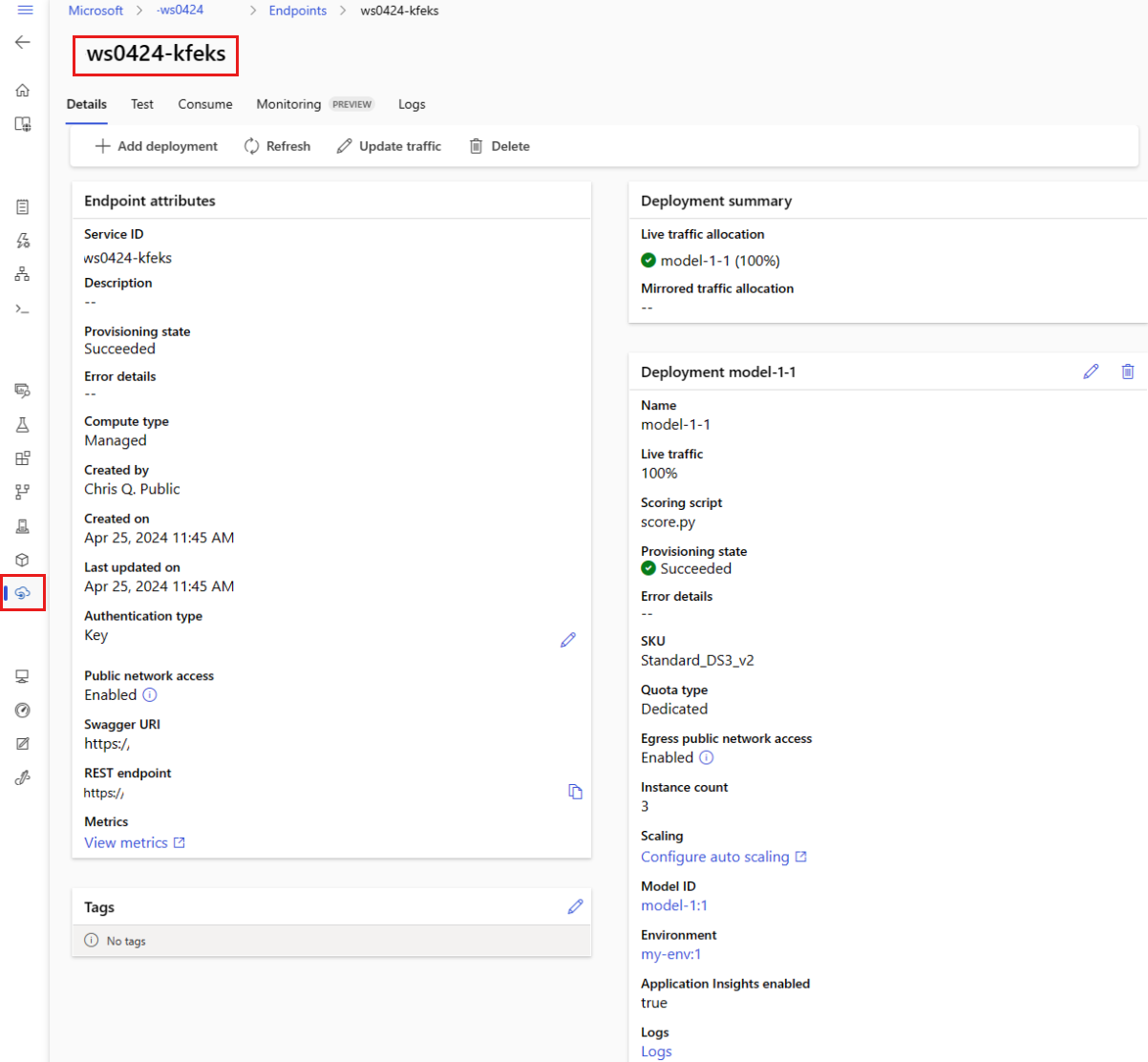
Os modelos são úteis para implantar recursos, mas você não pode usá-los para listar, mostrar ou invocar recursos. Use a CLI do Azure, o SDK do Python ou o estúdio para executar essas operações. O seguinte código usa a CLI do Azure.
Use o comando show para exibir informações no parâmetro provisioning_state para o ponto de extremidade e a implantação:
az ml online-endpoint show -n $ENDPOINT_NAME
Liste todos os pontos de extremidade no workspace em um formato de tabela usando o comando list:
az ml online-endpoint list --output table
Verifique o status da implantação online
Verifique os logs para ver se o modelo foi implantado sem erro.
Para ver a saída de log do contêiner, use o seguinte comando da CLI:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Por padrão, os logs são extraídos do contêiner do servidor de inferência. Para ver os logs do contêiner do inicializador de armazenamento, adicione o sinalizador --container storage-initializer. Para obter mais informações sobre logs de implantação, consulte Obter logs de contêiner.
Você pode exibir a saída do log usando o método get_logs:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
Por padrão, os logs são extraídos do contêiner do servidor de inferência. Para ver os logs do contêiner do inicializador de armazenamento, adicione a opção container_type="storage-initializer". Para obter mais informações sobre logs de implantação, consulte Obter logs de contêiner.
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50, container_type="storage-initializer"
)
Para exibir a saída do log, selecione a guia Logs na página do ponto de extremidade. Se houver várias implantações no ponto de extremidade, use a lista suspensa para selecionar a implantação com o log que você deseja ver.
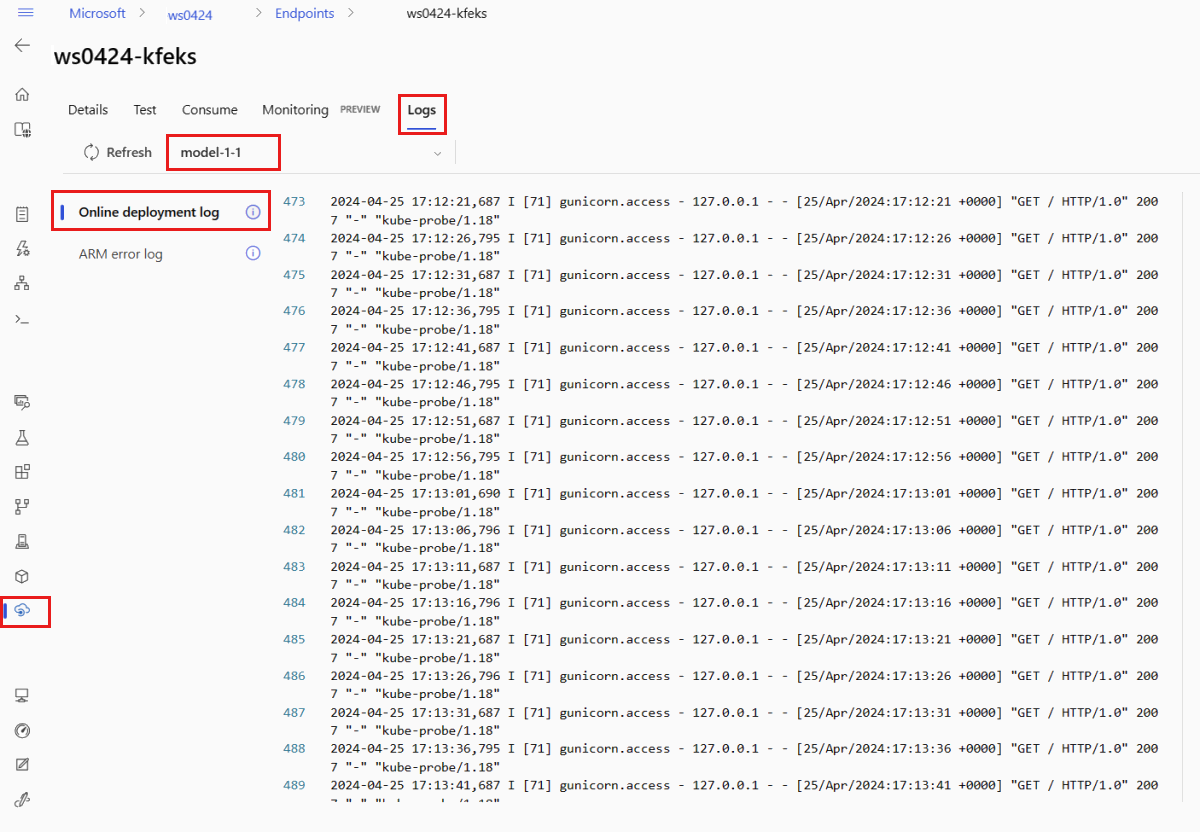
Por padrão, os logs são extraídos do servidor de inferência. Para ver os logs do contêiner do inicializador de armazenamento, use a CLI do Azure ou o SDK do Python (confira cada guia para obter detalhes). Os logs do contêiner do inicializador de armazenamento fornecem informações sobre se os dados do código e do modelo foram baixados com êxito para o contêiner. Para obter mais informações sobre logs de implantação, consulte Obter logs de contêiner.
Os modelos são úteis para implantar recursos, mas você não pode usá-los para listar, mostrar ou invocar recursos. Use a CLI do Azure, o SDK do Python ou o estúdio para executar essas operações. O seguinte código usa a CLI do Azure.
Para ver a saída de log do contêiner, use o seguinte comando da CLI:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Por padrão, os logs são extraídos do contêiner do servidor de inferência. Para ver os logs do contêiner do inicializador de armazenamento, adicione o sinalizador --container storage-initializer. Para obter mais informações sobre logs de implantação, consulte Obter logs de contêiner.
Invocar o ponto de extremidade para pontuar os dados usando o modelo
Use o comando invoke ou um cliente REST de sua escolha para chamar o ponto de extremidade e obter alguns dados:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Obtenha a chave usada para autenticar no ponto de extremidade:
Você pode controlar quais entidades de segurança do Microsoft Entra podem obter a chave de autenticação atribuindo-as a uma função personalizada que permite Microsoft.MachineLearningServices/workspaces/onlineEndpoints/token/action e Microsoft.MachineLearningServices/workspaces/onlineEndpoints/listkeys/action. Para obter mais informações sobre como gerenciar a autorização para workspaces, consulte Gerenciar o acesso a um workspace do Azure Machine Learning.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n $ENDPOINT_NAME -o tsv --query primaryKey)
Use curl para pontuar dados.
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @endpoints/online/model-1/sample-request.json
Observe que você usa show e get-credentials comandos para obter as credenciais de autenticação. Observe também que você usa o --query sinalizador para filtrar apenas os atributos necessários. Para saber mais sobre o sinalizador --query, confira Consultar a saída de comando da CLI do Azure.
Para ver os logs de invocação, execute get-logs novamente.
Usando o parâmetro MLClient criado anteriormente, você obtém um identificador para o ponto de extremidade. Em seguida, você pode invocar o ponto de extremidade usando o invoke comando com os seguintes parâmetros:
-
endpoint_name: o nome do ponto de extremidade.
-
request_file: arquivo com dados de solicitação.
-
deployment_name: nome da implantação específica a ser testada em um ponto de extremidade.
Envie uma solicitação de exemplo usando um arquivo JSON .
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
Use a guia Teste na página de detalhes do endpoint para testar sua implantação online gerenciada. Insira uma entrada de exemplo e veja os resultados.
Selecione a guia Testar na página de detalhes do ponto de extremidade.
Use a lista suspensa para selecionar a implantação que você deseja testar.
Insira a entrada de exemplo.
Selecione Testar.

Os modelos são úteis para implantar recursos, mas você não pode usá-los para listar, mostrar ou invocar recursos. Use a CLI do Azure, o SDK do Python ou o estúdio para executar essas operações. O seguinte código usa a CLI do Azure.
Use o comando invoke ou um cliente REST de sua escolha para chamar o ponto de extremidade e obter alguns dados:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file cli/endpoints/online/model-1/sample-request.json
(Opcional) Atualizar a implantação
Se você quiser atualizar o código, o modelo ou o ambiente, atualize o arquivo YAML. Em seguida, execute o az ml online-endpoint update comando.
Se você atualizar a contagem de instâncias (para dimensionar sua implantação) juntamente com outras configurações de modelo (como código, modelo ou ambiente) em um único update comando, a operação de dimensionamento será executada primeiro. As outras atualizações são aplicadas em seguida. É uma boa prática executar essas operações separadamente em um ambiente de produção.
Para entender como update funciona:
Abra o arquivo online/model-1/onlinescoring/score.py.
Altere a última linha da função init(): depois de logging.info("Init complete"), adicione logging.info("Updated successfully").
Salve o arquivo.
Execute este comando:
az ml online-deployment update -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml
A atualização usando YAML é declarativa. Ou seja, as alterações no YAML são refletidas nos recursos subjacentes do Resource Manager (pontos de extremidade e implantações). Uma abordagem declarativa facilita o GitOps:Todas as alterações em pontos de extremidade e implantações (até mesmo instance_count) passam pelo YAML.
Você pode usar parâmetros de atualização genéricos, como o parâmetro --set, com o comando update da CLI para substituir atributos em seu YAML ou para definir atributos específicos sem passá-los no arquivo YAML. Use --set para atributos individuais é útil principalmente em cenários de desenvolvimento e teste. Por exemplo, para escalar verticalmente o valor instance_count da primeira implantação, você pode usar o sinalizador --set instance_count=2. No entanto, como o YAML não está atualizado, essa técnica não facilita o GitOps.
Especificar o arquivo YAML não é obrigatório. Por exemplo, se você quiser testar diferentes configurações de simultaneidade para uma implantação específica, poderá tentar algo como az ml online-deployment update -n blue -e my-endpoint --set request_settings.max_concurrent_requests_per_instance=4 environment_variables.WORKER_COUNT=4. Essa abordagem mantém toda a configuração existente, mas atualiza apenas os parâmetros especificados.
Como você modificou a init() função, que é executada quando o ponto de extremidade é criado ou atualizado, a mensagem Updated successfully é exibida nos logs. Recupere os logs executando:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
O comando update também funciona com implantações locais. Use o mesmo comando az ml online-deployment update com o sinalizador --local.
Se você quiser atualizar o código, o modelo ou o ambiente, atualize a configuração e execute o MLClientmétodo 's online_deployments.begin_create_or_update para criar ou atualizar uma implantação.
Se você atualizar a contagem de instâncias (para dimensionar sua implantação) junto com outras configurações de modelo (como código, modelo ou ambiente) em um único begin_create_or_update método, a operação de dimensionamento será executada primeiro. Em seguida, as outras atualizações são aplicadas. É uma boa prática executar essas operações separadamente em um ambiente de produção.
Para entender como begin_create_or_update funciona:
Abra o arquivo online/model-1/onlinescoring/score.py.
Altere a última linha da função init(): depois de logging.info("Init complete"), adicione logging.info("Updated successfully").
Salve o arquivo.
Execute o método :
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Como você modificou a init() função, que é executada quando o ponto de extremidade é criado ou atualizado, a mensagem Updated successfully é exibida nos logs. Recupere os logs executando:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
O método begin_create_or_update também funciona com implantações locais. Use o mesmo método com o sinalizador local=True.
Atualmente, você só pode fazer atualizações na contagem de instâncias de uma implantação. Use as seguintes instruções para aumentar ou reduzir uma implantação individual ajustando o número de instâncias:
- Abra a página Detalhes do ponto de extremidade e encontre o cartão da implantação que você deseja atualizar.
- Selecione o ícone de edição (ícone de lápis) ao lado do nome da implantação.
- Atualize a contagem de instâncias associada à implantação. Escolha entre o padrão ou a utilização de destino para o tipo de escala de implantação.
- Se você selecionar Padrão, também poderá especificar um valor numérico para a contagem de instâncias.
- Se você selecionar a Utilização de Destino, poderá especificar valores a serem usados para parâmetros ao dimensionar automaticamente a implantação.
- Selecione Atualizar para concluir a atualização das contagens de instâncias para a implantação.
Atualmente, não há uma opção para atualizar a implantação usando um modelo do ARM.
Observação
A atualização da implantação nesta seção é um exemplo de uma atualização contínua no local.
- Para um ponto de extremidade online gerenciado, a implantação será atualizada para a nova configuração com 20% dos nós por vez. Ou seja, se a implantação tiver 10 nós, 2 nós por vez serão atualizados.
- Para um ponto de extremidade online do Kubernetes, o sistema criará iterativamente uma nova instância de implantação com a nova configuração e exclui a antiga.
- Para uso em produção, considere a implantação azul-verde, que oferece uma alternativa mais segura para atualizar um serviço Web.
O dimensionamento automático executa automaticamente a quantidade certa de recursos para lidar com a carga em seu aplicativo. Os pontos de extremidade online gerenciados dão suporte ao dimensionamento automático por meio da integração com o recurso de escala automática do Azure Monitor. Para configurar o dimensionamento automático, consulte Pontos de extremidade online de dimensionamento automático.
(Opcional) Monitorar o SLA usando o Azure Monitor
Para ver as métricas e definir alertas com base no seu SLA, siga as etapas descritas em Monitorar pontos de extremidade online.
(Opcional) Fazer a integração com o Log Analytics
O get-logs comando da CLI ou do get_logs método para o SDK fornece apenas as últimas centenas de linhas de logs de uma instância selecionada automaticamente. No entanto, o Log Analytics oferece uma forma de armazenar e analisar logs de modo durável. Para obter mais informações sobre como usar logs, consulte Uso de logs.
Excluir o ponto de extremidade e a implantação
Utilize o seguinte comando para excluir o endpoint e todas as suas implantações associadas.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Utilize o seguinte comando para excluir o endpoint e todas as suas implantações associadas.
ml_client.online_endpoints.begin_delete(name=endpoint_name)
Se você não for usar o ponto de extremidade e a implantação, exclua-os. Ao excluir o ponto de extremidade, você também excluirá todas as suas implantações subjacentes.
- Acesse o Estúdio do Azure Machine Learning.
- No painel esquerdo, selecione a página Endpoints.
- Selecionar um ponto de extremidade.
- Selecione Excluir.
Como alternativa, você pode excluir um ponto de extremidade online gerenciado diretamente selecionando o ícone Excluir na página de detalhes do ponto de extremidade.
Utilize o seguinte comando para excluir o endpoint e todas as suas implantações associadas.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Conteúdo relacionado









