Publicar pipelines de machine learning
APLICA-SE A:  SDK do Python do AzureML v1
SDK do Python do AzureML v1
Este artigo mostrará como compartilhar um pipeline de aprendizado de máquina com seus colegas ou clientes.
Os pipelines de aprendizado de máquina são fluxos de trabalho reutilizáveis para tarefas de aprendizado de máquina. Um benefício dos pipelines é o aumento da colaboração. Você também pode usar versões de pipeline, permitindo que os clientes usem o modelo atual enquanto você trabalha em uma nova versão.
Pré-requisitos
Criar um workspace do Azure Machine Learning para manter todos os seus recursos de pipeline
Configurar o ambiente de desenvolvimento para instalar o SDK do Azure Machine Learning ou usar uma instância de computação do Azure Machine Learning com o SDK já instalado
Criar e executar um pipeline de aprendizado de máquina, como ao seguir Tutorial: criar um pipeline do Azure Machine Learning para pontuação de lote. Para outras opções, confira Criar e executar pipelines de aprendizado de máquina com o SDK do Azure Machine Learning
Publicar um pipeline
Quando um pipeline estiver em funcionamento, você poderá publicá-lo para que ele seja executado com diferentes entradas. No ponto de extremidade REST de um pipeline já publicado para aceitar parâmetros, você deve configurar seu pipeline para usar objetos PipelineParameter nos argumentos que podem variar.
Para criar um parâmetro de pipeline, use um objeto PipelineParameter com um valor padrão.
from azureml.pipeline.core.graph import PipelineParameter pipeline_param = PipelineParameter( name="pipeline_arg", default_value=10)Adicione esse objeto
PipelineParametercomo um parâmetro a qualquer uma das etapas no pipeline da seguinte maneira:compareStep = PythonScriptStep( script_name="compare.py", arguments=["--comp_data1", comp_data1, "--comp_data2", comp_data2, "--output_data", out_data3, "--param1", pipeline_param], inputs=[ comp_data1, comp_data2], outputs=[out_data3], compute_target=compute_target, source_directory=project_folder)Publique este pipeline que aceitará um parâmetro quando invocado.
published_pipeline1 = pipeline_run1.publish_pipeline( name="My_Published_Pipeline", description="My Published Pipeline Description", version="1.0")Depois de publicar seu pipeline, você pode verificá-lo na interface do usuário. A ID do pipeline é a identificação exclusiva do pipeline publicado.
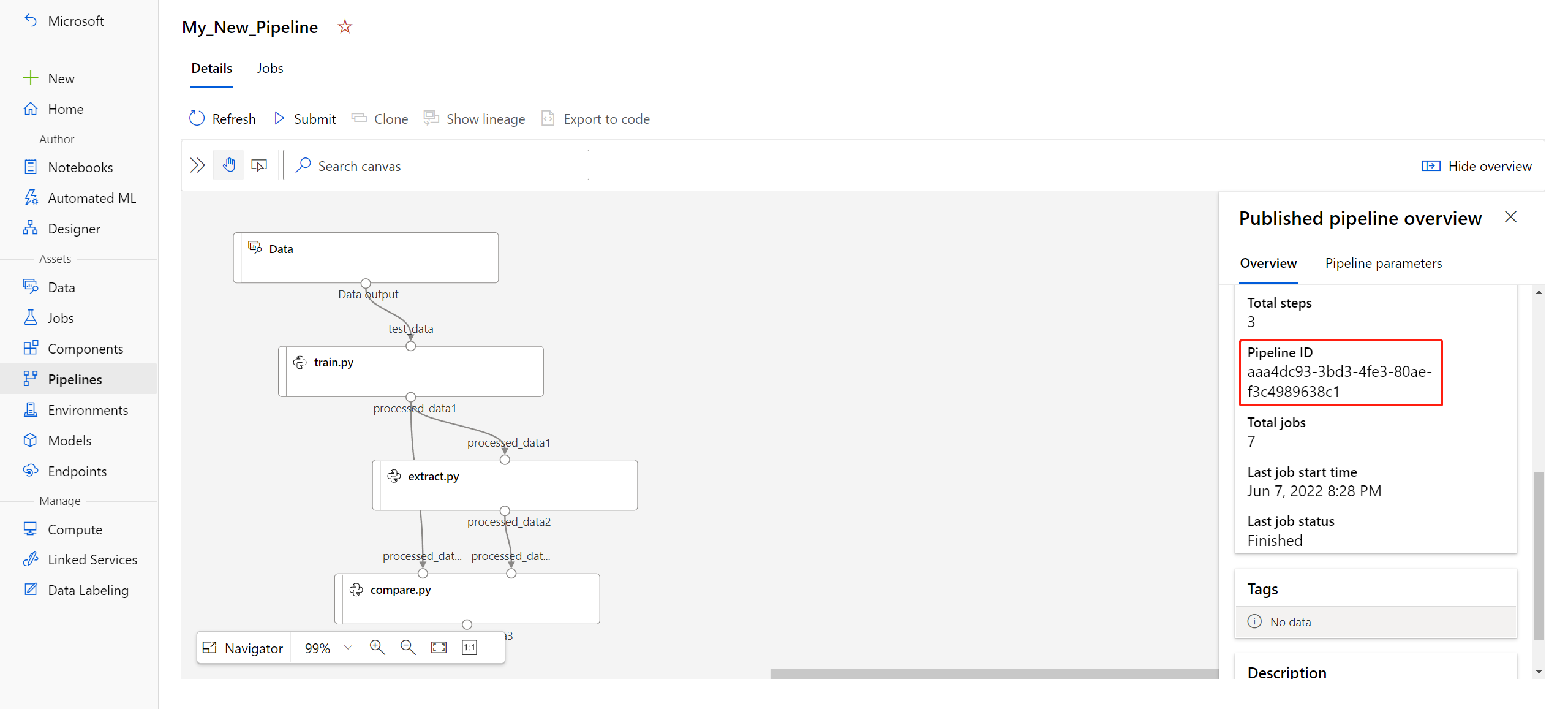

Execute um pipeline publicado
Todos os pipelines publicados têm um ponto de extremidade REST. Com o ponto de extremidade do pipeline, você pode disparar uma execução do pipeline de qualquer sistema externo, incluindo clientes não Python. Esse ponto de extremidade permite a "repetibilidade gerenciada" em cenários de retreinamento e pontuação de lote.
Importante
Se estiver usando o RBAC (controle de acesso baseado em função) do Azure para gerenciar o acesso ao pipeline, defina as permissões para o cenário de pipeline (treinamento ou pontuação).
Para invocar a execução do pipeline anterior, você precisa de um token de cabeçalho de autenticação do Microsoft Entra. O modo de obter esse token é descrito na referência da classe AzureCliAuthentication e no notebook Autenticação no Azure Machine Learning.
from azureml.pipeline.core import PublishedPipeline
import requests
response = requests.post(published_pipeline1.endpoint,
headers=aad_token,
json={"ExperimentName": "My_Pipeline",
"ParameterAssignments": {"pipeline_arg": 20}})
O argumento json para a solicitação POST deve conter, para a chave ParameterAssignments, um dicionário que contenha os parâmetros de pipeline e seus valores. Além disso, o argumento json pode conter as seguintes chaves:
| Chave | Descrição |
|---|---|
ExperimentName |
O nome da experiência associada a esse ponto de extremidade |
Description |
Texto de forma livre que descreve o ponto de extremidade |
Tags |
Pares chave-valor de forma livre que podem ser usados para rotular e anotar solicitações |
DataSetDefinitionValueAssignments |
Dicionário usado para alterar conjuntos de dados sem treinar novamente (confira a discussão abaixo) |
DataPathAssignments |
Dicionário usado para alterar os caminhos de dados sem novo treinamento (confira a discussão abaixo) |
Executar um pipeline publicado usando C#
O código a seguir mostra como chamar um pipeline de forma assíncrona pelo C#. O snippet de código parcial mostra apenas a estrutura de chamada e não faz parte de um exemplo da Microsoft. Ele não mostra as classes completas nem o tratamento de erros.
[DataContract]
public class SubmitPipelineRunRequest
{
[DataMember]
public string ExperimentName { get; set; }
[DataMember]
public string Description { get; set; }
[DataMember(IsRequired = false)]
public IDictionary<string, string> ParameterAssignments { get; set; }
}
// ... in its own class and method ...
const string RestEndpoint = "your-pipeline-endpoint";
using (HttpClient client = new HttpClient())
{
var submitPipelineRunRequest = new SubmitPipelineRunRequest()
{
ExperimentName = "YourExperimentName",
Description = "Asynchronous C# REST api call",
ParameterAssignments = new Dictionary<string, string>
{
{
// Replace with your pipeline parameter keys and values
"your-pipeline-parameter", "default-value"
}
}
};
string auth_key = "your-auth-key";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", auth_key);
// submit the job
var requestPayload = JsonConvert.SerializeObject(submitPipelineRunRequest);
var httpContent = new StringContent(requestPayload, Encoding.UTF8, "application/json");
var submitResponse = await client.PostAsync(RestEndpoint, httpContent).ConfigureAwait(false);
if (!submitResponse.IsSuccessStatusCode)
{
await WriteFailedResponse(submitResponse); // ... method not shown ...
return;
}
var result = await submitResponse.Content.ReadAsStringAsync().ConfigureAwait(false);
var obj = JObject.Parse(result);
// ... use `obj` dictionary to access results
}
Executar um pipeline publicado usando Java
O código a seguir mostra uma chamada para um pipeline que requer autenticação (veja Configurar a autenticação para recursos e fluxos de trabalho do Azure Machine Learning). Se o seu pipeline for implantado publicamente, você não precisará das chamadas que produzem authKey. O snippet de código parcial não mostra a classe Java e o clichê do tratamento de exceções. O código usa Optional.flatMap para encadear funções que podem retornar um Optional vazio. O uso de flatMap encurta e esclarece o código, mas observe que getRequestBody() assimila exceções.
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.Optional;
// JSON library
import com.google.gson.Gson;
String scoringUri = "scoring-endpoint";
String tenantId = "your-tenant-id";
String clientId = "your-client-id";
String clientSecret = "your-client-secret";
String resourceManagerUrl = "https://management.azure.com";
String dataToBeScored = "{ \"ExperimentName\" : \"My_Pipeline\", \"ParameterAssignments\" : { \"pipeline_arg\" : \"20\" }}";
HttpClient client = HttpClient.newBuilder().build();
Gson gson = new Gson();
HttpRequest tokenAuthenticationRequest = tokenAuthenticationRequest(tenantId, clientId, clientSecret, resourceManagerUrl);
Optional<String> authBody = getRequestBody(client, tokenAuthenticationRequest);
Optional<String> authKey = authBody.flatMap(body -> Optional.of(gson.fromJson(body, AuthenticationBody.class).access_token);;
Optional<HttpRequest> scoringRequest = authKey.flatMap(key -> Optional.of(scoringRequest(key, scoringUri, dataToBeScored)));
Optional<String> scoringResult = scoringRequest.flatMap(req -> getRequestBody(client, req));
// ... etc (`scoringResult.orElse()`) ...
static HttpRequest tokenAuthenticationRequest(String tenantId, String clientId, String clientSecret, String resourceManagerUrl)
{
String authUrl = String.format("https://login.microsoftonline.com/%s/oauth2/token", tenantId);
String clientIdParam = String.format("client_id=%s", clientId);
String resourceParam = String.format("resource=%s", resourceManagerUrl);
String clientSecretParam = String.format("client_secret=%s", clientSecret);
String bodyString = String.format("grant_type=client_credentials&%s&%s&%s", clientIdParam, resourceParam, clientSecretParam);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(authUrl))
.POST(HttpRequest.BodyPublishers.ofString(bodyString))
.build();
return request;
}
static HttpRequest scoringRequest(String authKey, String scoringUri, String dataToBeScored)
{
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(scoringUri))
.header("Authorization", String.format("Token %s", authKey))
.POST(HttpRequest.BodyPublishers.ofString(dataToBeScored))
.build();
return request;
}
static Optional<String> getRequestBody(HttpClient client, HttpRequest request) {
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
System.out.println(String.format("Unexpected server response %d", response.statusCode()));
return Optional.empty();
}
return Optional.of(response.body());
}catch(Exception x)
{
System.out.println(x.toString());
return Optional.empty();
}
}
class AuthenticationBody {
String access_token;
String token_type;
int expires_in;
String scope;
String refresh_token;
String id_token;
AuthenticationBody() {}
}
Alterar conjuntos e caminhos de dados sem novo treinamento
Talvez você queira realizar treinamento e inferência em diferentes conjuntos e caminhos de dados. Por exemplo, você pode querer treinar em um conjunto de um dados menor, mas realizar inferência no conjunto de dados completo. Alterne os conjuntos de dados com a chave DataSetDefinitionValueAssignments no argumento json da solicitação. Alterne os caminhos de dados com DataPathAssignments. A técnica para ambos é semelhante:
No script de definição de pipeline, crie um
PipelineParameterpara o conjunto de dados. Crie umDatasetConsumptionConfigouDataPathemPipelineParameter:tabular_dataset = Dataset.Tabular.from_delimited_files('https://dprepdata.blob.core.windows.net/demo/Titanic.csv') tabular_pipeline_param = PipelineParameter(name="tabular_ds_param", default_value=tabular_dataset) tabular_ds_consumption = DatasetConsumptionConfig("tabular_dataset", tabular_pipeline_param)Em seu script ML, acesse o conjunto de dados especificado dinamicamente usando
Run.get_context().input_datasets:from azureml.core import Run input_tabular_ds = Run.get_context().input_datasets['tabular_dataset'] dataframe = input_tabular_ds.to_pandas_dataframe() # ... etc ...Observe que o script ML acessa o valor especificado para
DatasetConsumptionConfig(tabular_dataset), e não o valor dePipelineParameter(tabular_ds_param).Em seu script de definição de pipeline, defina
DatasetConsumptionConfigcomo um parâmetro paraPipelineScriptStep:train_step = PythonScriptStep( name="train_step", script_name="train_with_dataset.py", arguments=["--param1", tabular_ds_consumption], inputs=[tabular_ds_consumption], compute_target=compute_target, source_directory=source_directory) pipeline = Pipeline(workspace=ws, steps=[train_step])Para alternar conjuntos de dados dinamicamente em sua chamada REST de inferência, use
DataSetDefinitionValueAssignments:tabular_ds1 = Dataset.Tabular.from_delimited_files('path_to_training_dataset') tabular_ds2 = Dataset.Tabular.from_delimited_files('path_to_inference_dataset') ds1_id = tabular_ds1.id d22_id = tabular_ds2.id response = requests.post(rest_endpoint, headers=aad_token, json={ "ExperimentName": "MyRestPipeline", "DataSetDefinitionValueAssignments": { "tabular_ds_param": { "SavedDataSetReference": {"Id": ds1_id #or ds2_id }}}})
Os notebooks Demonstração de Dataset e PipelineParameter e Demonstração de DataPath e PipelineParameter têm exemplos completos dessa técnica.
Criar um ponto de extremidade de pipeline com versões
Você pode criar um ponto de extremidade de pipeline com vários pipelines publicados por trás dele. Essa técnica fornece um ponto de extremidade REST fixo conforme você itera e atualiza seus pipelines de ML.
from azureml.pipeline.core import PipelineEndpoint
published_pipeline = PublishedPipeline.get(workspace=ws, id="My_Published_Pipeline_id")
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws, name="PipelineEndpointTest",
pipeline=published_pipeline, description="Test description Notebook")
Enviar um trabalho para um ponto de extremidade de pipeline
Você pode enviar um trabalho para a versão padrão de um ponto de extremidade de pipeline:
pipeline_endpoint_by_name = PipelineEndpoint.get(workspace=ws, name="PipelineEndpointTest")
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment")
print(run_id)
Você também pode enviar um trabalho para uma versão específica:
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment", pipeline_version="0")
print(run_id)
O mesmo pode ser feito usando a API REST:
rest_endpoint = pipeline_endpoint_by_name.endpoint
response = requests.post(rest_endpoint,
headers=aad_token,
json={"ExperimentName": "PipelineEndpointExperiment",
"RunSource": "API",
"ParameterAssignments": {"1": "united", "2":"city"}})
Usar pipelines publicados no estúdio
Você também pode executar o pipeline publicado no estúdio:
Entre no Estúdio do Azure Machine Learning.
À esquerda, selecione Pontos de extremidade.
Na parte superior, selecione Pontos de extremidade de pipeline.
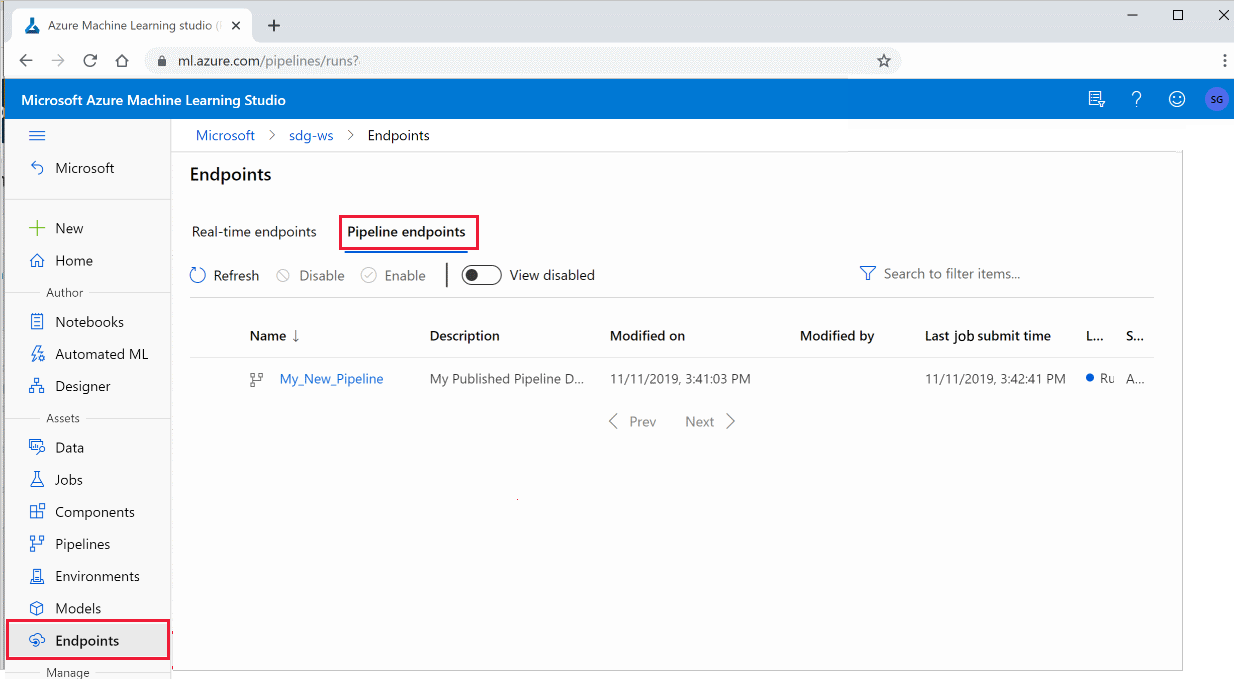
Selecione um pipeline específico para executar, consumir ou examinar os resultados das execuções anteriores do ponto de extremidade do pipeline.
Desabilitar um pipeline publicado
Para ocultar um pipeline da lista de pipelines publicados, desabilita-o no estúdio ou no SDK:
# Get the pipeline by using its ID from Azure Machine Learning studio
p = PublishedPipeline.get(ws, id="068f4885-7088-424b-8ce2-eeb9ba5381a6")
p.disable()
Você pode habilitá-lo novamente com p.enable(). Para obter mais informações, confira a referência da classe PublishedPipeline.
Próximas etapas
- Use esses Jupyter Notebooks no GitHub para explorar ainda mais pipelines de machine learning.
- Confira a ajuda de referência do SDK para o pacote azureml-pipelines-core e o pacote azureml-pipelines-steps.
- Confira o tutorial para ver dicas de como depurar e solucionar problemas de pipelines.