Configurar o treinamento automatizado de ML sem código para dados tabulares com a interface do usuário do estúdio
Neste artigo, você configura trabalhos automatizados de treinamento de machine learning usando o Azure Machine Learning Automated ML no Estúdio do Azure Machine Learning. Essa abordagem permite configurar o trabalho sem escrever uma única linha de código. O ML automatizado é um processo em que o Azure Machine Learning seleciona o melhor algoritmo de machine learning para seus dados específicos. O processo permite que você gere modelos de machine learning rapidamente. Para obter mais informações, consulte a visão geral do processo de ML automatizado.
Este tutorial fornece uma visão geral de alto nível para trabalhar com ML Automatizado no estúdio. Os artigos a seguir fornecem instruções detalhadas para trabalhar com modelos específicos de machine learning:
- Classificação: Tutorial: Treinar um modelo de classificação com ML automatizado no estúdio
- Previsão de série temporal: Tutorial: Previsão da demanda com ML automatizado no estúdio
- NLP (Processamento de Linguagem Natural): configurar o ML automatizado para treinar um modelo NLP (CLI do Azure ou SDK do Python)
- Pesquisa Visual Computacional: configurar o AutoML para treinar modelos de pesquisa visual computacional (CLI do Azure ou SDK do Python)
- Regressão: treinar um modelo de regressão com o SDK do Python (ML Automatizado)
Pré-requisitos
Uma assinatura do Azure. Você pode criar uma conta gratuita ou paga do Azure Machine Learning.
Um workspace do Azure Machine Learning e uma instância de computação. Para preparar esses recursos, consulte Início Rápido: Introdução ao Azure Machine Learning.
O ativo de dados a ser usado para o trabalho de treinamento de ML automatizado. Este tutorial descreve como selecionar um ativo de dados existente ou criar um ativo de dados de uma fonte de dados, como um arquivo local, URL da Web ou armazenamento de dados. Para saber mais, confira Criar e gerenciar coleções.
Importante
Há dois requisitos para os dados de treinamento:
- Os dados devem estar no formato tabular.
- O valor a ser previsto (a coluna de destino) deve estar presente nos dados.
Criar um experimento
Crie e execute um experimento seguindo estas etapas:
Entre no Estúdio do Azure Machine Learning e selecione sua assinatura e espaço de trabalho.
No menu à esquerda, selecione ML Automatizado na seção de Criação:
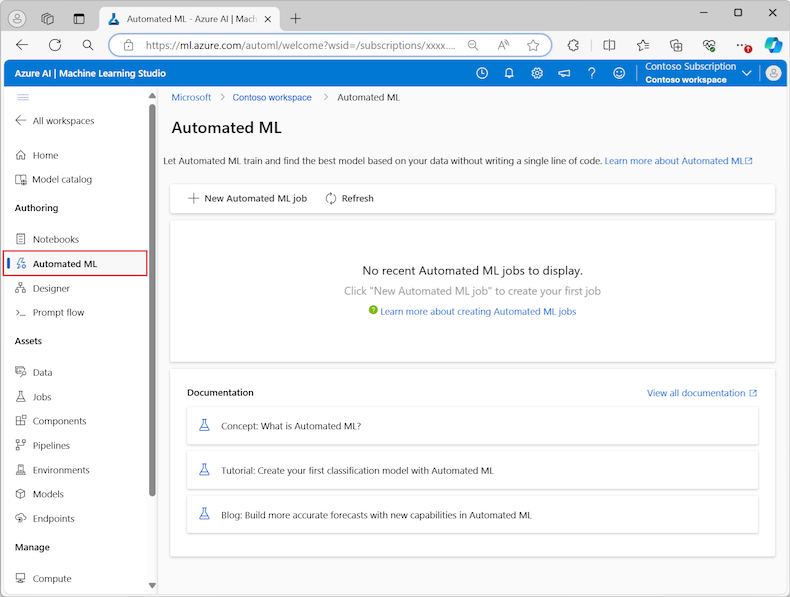
Na primeira vez que você trabalha com experimentos no estúdio, você vê uma lista vazia e links para a documentação. Caso contrário, você verá uma lista dos experimentos de ML automatizados recentes, incluindo itens criados com o SDK do Azure Machine Learning.
Selecione Novo trabalho de ML automatizado para iniciar o processo Enviar um trabalho de ML automatizado processo.
Por padrão, o processo seleciona a opção Treinar automaticamente na guia Método de treinamento e continua para as configurações.
Na guia de Configurações do Basics, insira valores para as configurações necessárias, incluindo o nome do Trabalho e o nome do Experimento. Você também pode fornecer valores para as configurações opcionais, conforme desejado.
Selecione Avançar para continuar.

Identificar as fontes de dados
Na guia Tipo de tarefa & dados, especifique o ativo de dados para o experimento e o modelo de machine learning a ser usado para treinar os dados.
Neste tutorial, você pode usar um ativo de dados existente ou criar um novo ativo de dados de um arquivo em seu computador local. As páginas da interface do usuário do estúdio são alteradas com base na sua seleção para a fonte de dados e o tipo de modelo de treinamento.
Se você optar por usar um ativo de dados existente, poderá continuar na seção Configurar modelo de treinamento.
Para criar um novo ativo de dados, siga estas etapas:
Para criar um novo ativo de dados de um arquivo no computador local, selecione Criar.
Na página Tipo de dados:
- Insira um nome de Ativo de dados.
- Para o Tipo, selecione Tabular na lista suspensa.
- Selecione Avançar.
Na página da Fonte de dados, selecione De arquivos locais.
O Machine Learning Studio adiciona opções extras ao menu à esquerda para você configurar a fonte de dados.
Selecione Próximo para continuar na página Tipo de armazenamento de destino, em que você especifica o local do Armazenamento do Microsoft Azure para carregar seu ativo de dados.
Você pode especificar o contêiner de armazenamento padrão criado automaticamente com seu workspace ou escolher um contêiner de armazenamento a ser usado para o experimento.
- Em Tipo de armazenamento de dados: selecione Armazenamento de Blobs do Azure.
- Na lista de armazenamentos de dados, selecione workspaceblobstore.
- Selecione Avançar.
Na página Seleção de arquivo e pasta, use o menu suspenso Carregar arquivos ou pastas e selecione a opção Carregar arquivos ou Carregar pasta.
- Navegue até o local dos dados para carregar e selecionar Abrir.
- Depois que os arquivos forem carregados, selecione Próximo.
O Machine Learning Studio valida e carrega seus dados.
Observação
Se seus dados estiverem atrás de uma rede virtual, você precisará habilitar a funçãoIgnorar a validaçãopara garantir que o espaço de trabalho possa acessar seus dados. Para obter mais informações, confiraUsar o Estúdio do Azure Machine Learning em uma rede virtual do Azure.
Verifique os dados carregados na página Configurações para obter precisão. Os campos na página são pré-preenchidos com base no tipo de arquivo de seus dados:
Campo Descrição Formato de arquivo Define o layout e o tipo de dados armazenados em um arquivo. Delimitador Identifica um ou mais caracteres para especificar o limite entre regiões separadas e independentes em texto sem formatação ou outros fluxos de dados. Codificação Identifica qual tabela de esquema de bit para caractere usar para ler seu conjunto de dados. Cabeçalhos de coluna Indica como os cabeçalhos do conjunto de dados, se houver, são tratados. Ignorar linhas Indica quantas linhas, se houver, serão ignoradas no conjunto de registros. Selecione Próximo para continuar na página Esquema. Esta página também é pré-preenchida com base em suas seleções de Configurações. Você pode configurar o tipo de dados para cada coluna, examinar os nomes das colunas e gerenciar colunas:
- Para alterar o tipo de dados de uma coluna, use o menu suspenso Tipo para selecionar uma opção.
- Para excluir uma coluna do ativo de dados, alterne a opção Incluir para a coluna.
Selecione Próximo para continuar na página Revisão. Examine o resumo das configurações do trabalho e selecione Criar.
Configurar o modelo de treinamento
Quando o ativo de dados estiver pronto, o Estúdio do Machine Learning retornará à guia Tipo de tarefa & de dados para o processo Enviar um trabalho de ML automatizado processo. O novo ativo de dados está listado na página.
Siga estas etapas para concluir a configuração do trabalho:
Expanda o Selecionar tipo de tarefa menu suspenso e escolha o modelo de treinamento a ser usado para o experimento. As opções incluem classificação, regressão, previsão de série temporal, NLP (processamento de linguagem natural) ou pesquisa visual computacional. Para obter mais informações sobre essas opções, consulte as descrições dos tipos de tarefa com suporte.
Depois de especificar o modelo de treinamento, selecione o conjunto de dados na lista.
Selecione Avançar para continuar para a guia Inspecionar.
Na lista suspensa Coluna de destino, selecione a coluna a ser usada para as previsões do modelo.
Dependendo do modelo de treinamento, defina as seguintes configurações necessárias:
Classificação: escolha se deseja Habilitar aprendizado profundo.
Previsão de série temporal: escolha se deseja Habilitar de aprendizado profundo e confirme suas preferências para as configurações necessárias:
Use a coluna Time para especificar os dados de tempo a serem usados no modelo.
Escolha se deseja habilitar uma ou mais opções de Detecção Automática. Ao desmarcar uma opção de Detecção Automática, como Horizonte de previsão de detecção automática, você pode especificar um valor específico. O valor Horizonte de previsão indica quantas unidades de tempo (minutos/horas/dias/semanas/meses/anos) o modelo pode prever para o futuro. Quanto mais longe no futuro o modelo tiver que prever, menos preciso ele se tornará.
Para obter mais informações sobre como definir essas configurações, consulte Usar o ML automatizado para treinar um modelo de previsão de série temporal.
Processamento de idioma natural: confirme suas preferências para as configurações necessárias:
Use a opção Selecionar sub tipo para configurar o tipo de subclasse para o modelo NLP. Você pode escolher entre classificação de várias classes, classificação de vários rótulos e NER (reconhecimento de entidade nomeada).
Na seção Configurações do Sweep, forneça valores para o Fator Slack e algoritmo de Amostragem.
Na seção Espaço de pesquisa, configure o conjunto de opções Modelo algorítmico.
Para obter mais informações sobre como definir essas configurações, consulte Configurar o ML Automatizado para treinar um modelo NLP (CLI do Azure ou SDK do Python).
Pesquisa Visual Computacional: escolha se deseja habilitar Varredura manual e confirme suas preferências para as configurações necessárias:
- Use a opção Selecionar subtipo para configurar o tipo de subclasse para o modelo de pesquisa visual computacional. Você pode escolher entre Classificação de imagem (Várias Classes) ou (Vários Rótulos), Detecção de objetos e Polígono (segmentação de instância).
Para obter mais informações sobre como definir essas configurações, consulte Configurar o ML automatizado para treinar modelos de visão computacional (CLI do Azure ou SDK do Python).
Especificar configurações opcionais
O Machine Learning Studio fornece configurações opcionais que você pode configurar com base na seleção do modelo de machine learning. As seções a seguir descrevem as configurações extras.
Definir as configurações adicionais
Você pode selecionar o Exibir configurações adicionais opção para ver ações a serem executadas nos dados em preparação para treinamento.
A página Configuração adicional mostra valores padrão com base na seleção e nos dados do experimento. Você pode usar os valores padrão ou definir as seguintes configurações:
| Configuração | Descrição |
|---|---|
| Métrica principal | Identifique a métrica principal para pontuar seu modelo. Para obter mais informações, consulte métricas de modelo. |
| Habilitar o empilhamento de conjunto | Permitir o aprendizado de conjunto e melhorar os resultados de machine learning e o desempenho preditivo combinando vários modelos em vez de usar modelos únicos. Para obter mais informações, consulte modelos de conjunto. |
| Usar todos os modelos suportados | Use essa opção para instruir o ML automatizado se deve usar todos os modelos com suporte no experimento. Para obter mais informações, consulte o algoritmos com suporte para cada tipo de tarefa. - Selecione esta opção para definir a configuração Modelos bloqueados. – Desmarque essa opção para definir a configuração Modelos permitidos. |
| Modelos bloqueados | (Disponível quando Usar todos os modelos com suporte está selecionado) Use a lista suspensa e selecione os modelos a serem excluídos do trabalho de treinamento. |
| Modelos permitidos | (Disponível quando Usar todos os modelos com suporte está selecionado) Use a lista suspensa e selecione os modelos a serem usados no trabalho de treinamento. Importante: disponível somente para experimentos do SDK. |
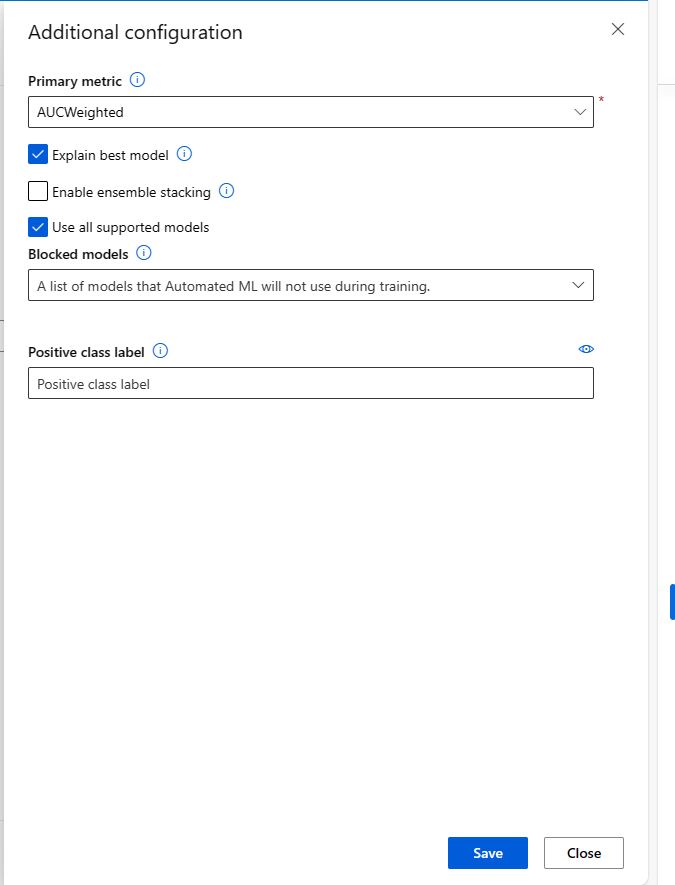
| Explicar o melhor modelo | Escolha essa opção para mostrar automaticamente a explicação sobre o melhor modelo criado pelo ML Automatizado. |
| Rótulo de classe positiva | Insira o rótulo para ML automatizado a ser usado para calcular métricas binárias. |
Configurar a definição de recursos
Você pode selecionar a opção Exibir configurações da definição de recursos para ver ações a serem executadas nos dados em preparação para treinamento.
A página Definição de recursos mostra técnicas padrão de definição de recursos para suas colunas de dados. Você pode habilitar/desabilitar a caracterização automática e personalizar as configurações automáticas de definição de recursos para seu experimento.

Selecione a opção Habilita definição de recursos para permitir a configuração.
Importante
Quando seus dados contêm colunas não numéricas, a definição de recursos é sempre habilitada.
Configure cada coluna disponível, conforme desejado. A tabela a seguir sintetize as personalizações disponíveis presente por meio do estúdio.
Coluna Personalização Tipo de recurso Altera o tipo de valor da coluna selecionada. Entrar com Selecione qual valor entrar com a conta da Microsoft com valores ausentes em seus dados. 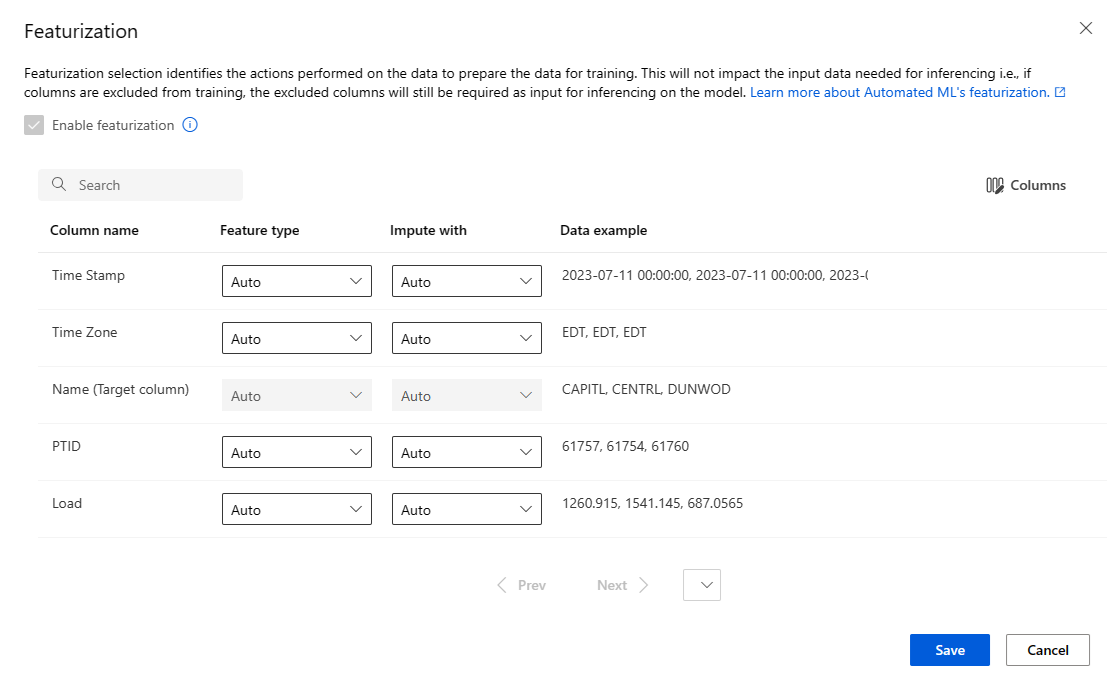

As configurações de definição de recursos não afetam os dados de entrada necessários para inferência. Se você excluir colunas do treinamento, as colunas excluídas ainda serão necessárias como entrada para inferência no modelo.
Configurar limites para o trabalho
A seção Limites fornece opções de configuração para as seguintes configurações:
| Configuração | Descrição | Valor |
|---|---|---|
| Máx. de tentativas | Especifique o número máximo de avaliações a serem testadas durante o trabalho de ML Automatizado, em que cada avaliação tem uma combinação diferente de algoritmo e hiperparâmetros. | Um número inteiro entre 1 e 1.000 |
| Máx. de tentativas simultâneas | O número máximo de trabalhos de tentativa que podem ser executados em paralelo. | Um número inteiro entre 1 e 1.000 |
| Máx. de nós | Especifique o número máximo de nós que esse trabalho pode usar no destino de computação selecionado. | 1 ou mais, dependendo da configuração de computação |
| Limite de pontuação da métrica | Insira o valor do limite da métrica de iteração. Quando a iteração atinge o limite, o trabalho de treinamento é encerrado. Tenha em mente que modelos significativos têm uma correlação maior que zero. Caso contrário, o resultado será o mesmo que adivinhar. | Limite médio de métrica, entre limites [0, 10] |
| Tempo limite do experimento (em minutos) | Especifique o tempo máximo que todo o experimento pode ser executado. Depois que o experimento atinge o limite, o sistema cancela o trabalho de ML Automatizado, incluindo todos os seus testes (trabalhos infantis). | Número de minutos |
| Tempo limite da iteração (em minutos) | Especifique o tempo máximo que cada trabalho de avaliação pode ser executado. Depois que o trabalho de avaliação atingir esse limite, o sistema cancelará a avaliação. | Número de minutos |
| Habilitar o encerramento antecipado | Use essa opção para encerrar o trabalho quando a pontuação não estiver melhorando no curto prazo. | Selecione a opção para habilitar o término antecipado do trabalho |
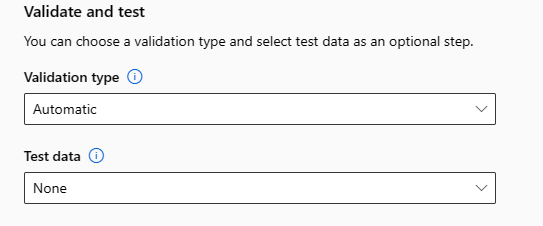
Validar e testar
A seção Validar e testar fornece as seguintes opções de configuração:
Especifique o Tipo de validação a ser usado para seu trabalho de treinamento. Se você não especificar explicitamente um parâmetro
validation_dataoun_cross_validations, o ML Automatizado aplicará técnicas padrão dependendo do número de linhas fornecidas no único conjunto de dadostraining_data.Tamanho dos dados de treinamento Técnica de validação Maior que 20.000 linhas A divisão de dados de treinamento/validação é aplicada. O padrão é levar 10% do conjunto de dados de treinamento inicial como o conjunto de validação. Por sua vez, esse conjunto de validação é usado para cálculo de métricas. Menor que 20.000 linhas A abordagem de validação cruzada é aplicada. O número padrão de dobras depende do número de colunas.
- Conjunto de dados com menos de 1.000 linhas: 10 dobras são usadas
- Conjunto de dados com 1.000 a 20.000 linhas: três dobras são usadasForneça os Dados de teste (versão prévia) para avaliar o modelo recomendado que o ML Automatizado gera no final do experimento. Quando você fornece um conjunto de dados de teste, um trabalho de teste é disparado automaticamente no final do experimento. Esse trabalho de teste é o único trabalho no melhor modelo recomendado pelo ML Automatizado. Para obter mais informações, consulte Exibir resultados do trabalho de teste remoto (versão prévia).
Importante
Fornecer um conjuntos de dados de teste para avaliar modelos gerados é uma versão prévia do recurso. Esse funcionalidade é uma versão prévia do recurso experimental e pode mudar a qualquer momento.
Os dados de teste são considerados separados do treinamento e da validação e não devem influenciar os resultados do trabalho de teste do modelo recomendado. Para obter mais informações, consulte Treinamento, validação e dados de teste.
Você pode fornecer seu próprio conjunto de dados de teste ou optar por usar uma porcentagem do seu conjunto de dados de treinamento. Os dados de teste devem estar na forma de um conjunto de dados de tabela do Azure Machine Learning.
O esquema do conjunto de dados de teste deve corresponder ao conjunto de dados de treinamento. A coluna de destino é opcional, mas se nenhuma coluna de destino for indicada, nenhuma métrica de teste será calculada.
O conjunto de dados de teste não deve ser o mesmo que o conjunto de dados de treinamento ou o conjunto de dados de validação.
Trabalhos de previsão não dão suporte à divisão de treinamento/teste.
Configurar a computação
Siga estas etapas e configure a computação:
Selecione Avançar para continuar para a guia Computação.
Use o Selecionar tipo de computação lista suspensa para escolher uma opção para o trabalho de criação de perfil e treinamento de dados. As opções incluem o cluster de computação, instância de computação ou sem servidor.
Depois de selecionar o tipo de computação, a outra interface do usuário na página será alterada com base em sua seleção:
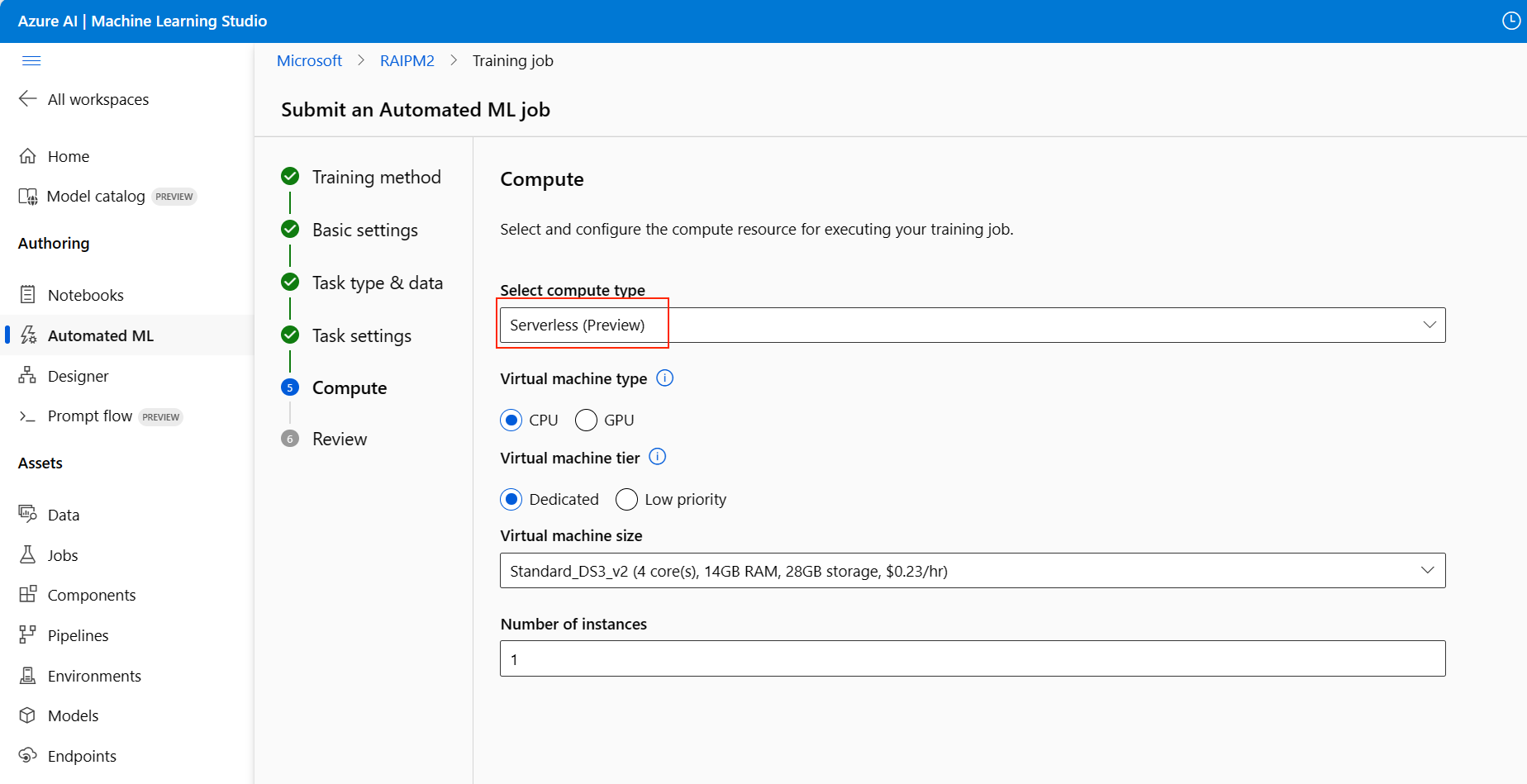
Sem servidor: as configurações são exibidas na página atual. Continue para a próxima etapa para obter descrições das configurações a serem definidas.
Cluster de computação ou Instância de computação: escolha entre as seguintes opções:
Use a lista suspensa Selecionar computação ML Automatizada para selecionar uma computação existente para seu workspace e selecione Próximo. Continue para a seção Execute experimentos e veja os resultados.
Selecione Novo para criar uma instância de computação. Essa opção abre a página Criar computação. Continue para a próxima etapa para obter descrições das configurações a serem definidas.
Para uma computação sem servidor ou uma nova computação, defina as configurações necessárias (*):
As configurações diferem dependendo do tipo de computação. A tabela a seguir resume as várias configurações que talvez seja necessário configurar:
Campo Descrição Nome da computação Insira um nome exclusivo que identifique o contexto da computação. Localidade Especifique a região do computador. Prioridade de máquina virtual As máquinas virtuais com baixa prioridade são as mais baratas, mas não garantem os nós de computação. Tipo de máquina virtual Selecione CPU ou GPU do tipo de máquina virtual. Camada de serviço de máquina virtual Selecione a prioridade do experimento. Tamanho da máquina virtual Selecione o tamanho da máquina virtual da computação. Nós Mín./Máx Para criar um perfil de dados, você deve especificar um ou mais nós. Insira o número máximo de nós da sua computação. O padrão é seis nós para Computação do Machine Learning. Segundos de espera antes de reduzir verticalmente Especifique o tempo ocioso antes que o cluster seja automaticamente reduzido para a contagem mínima de nós. Configurações avançadas Estas configurações permitem que você configure uma conta de usuário e uma rede virtual existente para seu experimento. Depois de definir as configurações necessárias, selecione Próximo ou Criar, conforme apropriado.
A criação da nova computação pode levar alguns minutos. Quando a criação for concluída, selecione Próximo.
Executar o experimento e exibir os resultados
Selecione Concluir, para executar o experimento. O processo de preparação do experimento pode levar até 10 minutos. Os trabalhos de treinamento podem levar mais 2 a 3 minutos para que cada pipeline termine a execução. Se você especificou para gerar o painel RAI para o modelo mais recomendado, pode levar até 40 minutos.
Observação
Os algoritmos que o ML automatizado emprega têm aleatoriedade inerente que pode causar uma pequena variação na pontuação final de métricas de um modelo recomendado, como precisão. O ML automatizado também executa operações em dados como divisão de teste de treinamento, divisão de validação de treinamento ou validação cruzada, conforme necessário. Se você executar um experimento com as mesmas configurações e a métrica primária várias vezes, provavelmente verá variação na pontuação final de métricas de cada experimento devido a esses fatores.
Exibir detalhes do experimento
A tela Detalhes do Trabalho é aberta na guia Detalhes. Essa tela mostra um resumo do trabalho de experimento, incluindo uma barra de status na parte superior, ao lado do número de trabalho.
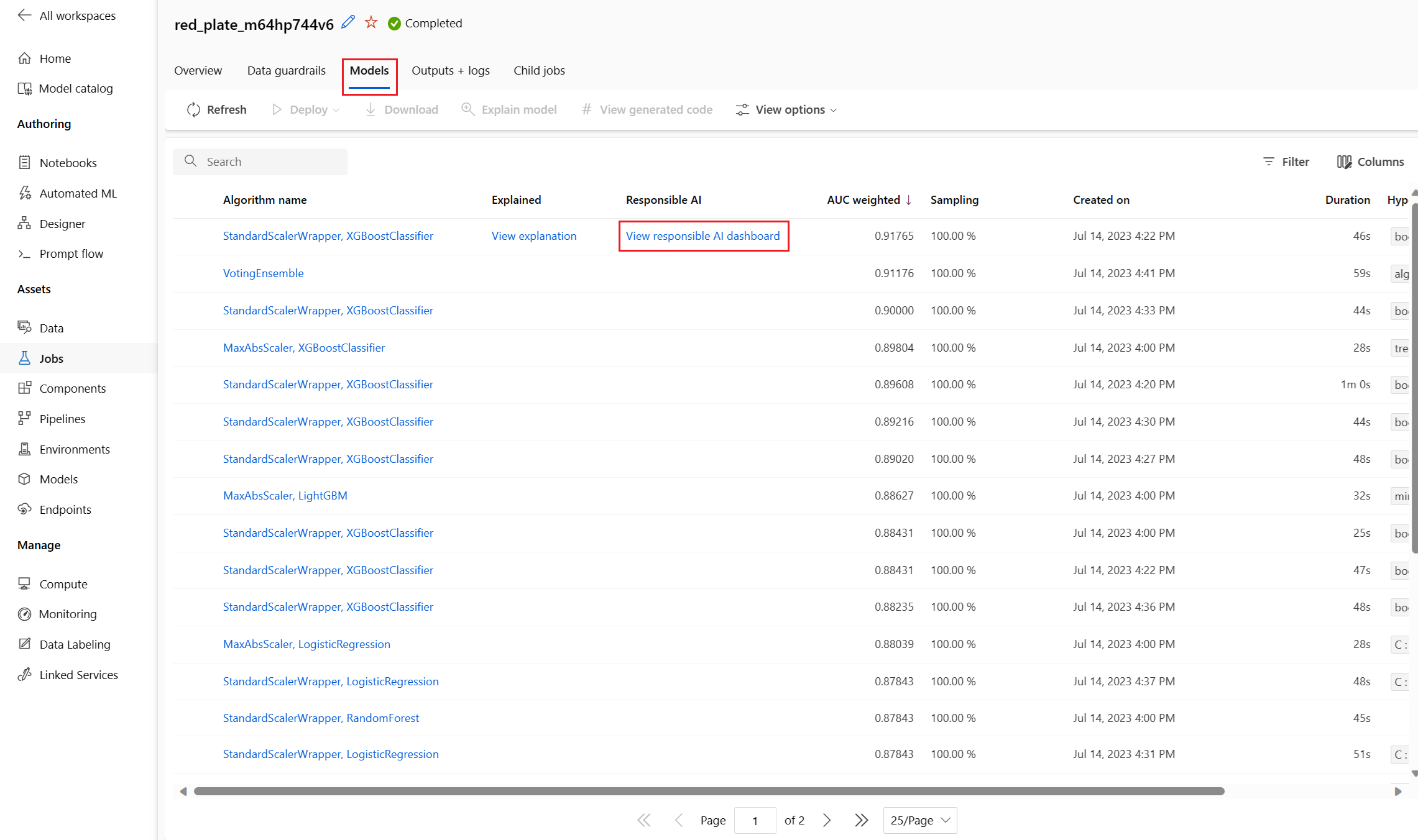
A guia Modelos contém uma lista dos modelos criados ordenados pela pontuação da métrica. Por padrão, o modelo com a pontuação mais alta de acordo com a métrica escolhida é exibido no início da lista. À medida que o trabalho de treinamento tenta mais modelos, os modelos exercidos são adicionados à lista. Use essa abordagem para obter uma comparação rápida das métricas para os modelos produzidos até agora.
Exibir detalhes do trabalho de treinamento
Faça uma busca detalhada em qualquer um dos modelos concluídos para os detalhes do trabalho de treinamento. Você pode ver gráficos de métricas de desempenho para modelos específicos na guia Métricas. Para obter mais informações, consulte Avaliar os resultados do experimento de machine learning automatizado. Nesta página, você também pode encontrar detalhes sobre todas as propriedades do modelo, juntamente com código associado, trabalhos filho e imagens.
Exibir resultados do trabalho de teste remoto (versão prévia)
Se você especificou um conjunto de dados de teste ou optou por uma divisão de treinamento/teste durante a instalação do experimento no formulário Validar e testar, o ML automatizado testará automaticamente o modelo recomendado por padrão. Como resultado, o ML automatizado calcula as métricas de teste para determinar a qualidade do modelo recomendado e suas previsões.
Importante
Testar seus modelos com um conjunto de dados de teste para avaliar modelos gerados por ML automatizados é uma versão prévia do recurso. Esse funcionalidade é uma versão prévia do recurso experimental e pode mudar a qualquer momento.
Esse recurso não está disponível para os seguintes cenários de ML Automatizado:
- Tarefas da Pesquisa Visual Computacional
- Muitos modelos e treinamento de previsão de série temporal hierárquica (versão prévia)
- Tarefas de previsão em que as DNN (redes neurais de aprendizado profundo) estão habilitadas
- Trabalhos do ML automatizado na computação local ou em clusters do Azure Databricks
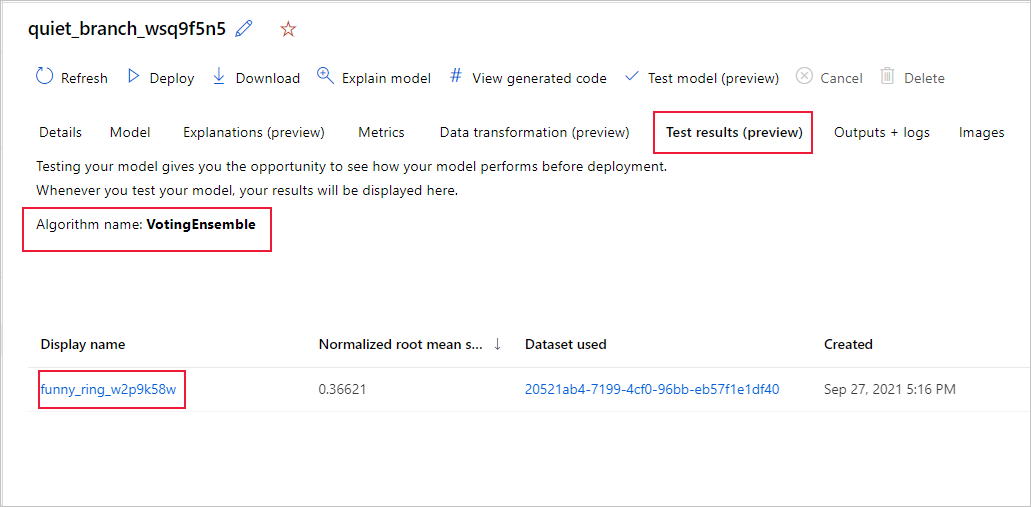
Siga estas etapas para exibir as métricas de trabalho de teste do modelo recomendado:
No estúdio, navegue até a página Modelos e selecione o melhor modelo.
Selecione a guia Resultados do teste (versão prévia) .
Selecione a execução que você deseja e veja a guia Métricas:
Exiba as previsões de teste usadas para calcular as métricas de teste seguindo estas etapas:
Na parte inferior da página, selecione o link em Conjunto de dados saídas para abrir o conjunto de dados.
Na página Conjuntos de dados, selecione a guia Explorar para exibir as previsões do trabalho de teste.
O arquivo de previsão também pode ser exibido e baixado na guia Saídas + logs. Expanda a pasta Previsões de para localizar o arquivo prediction.csv.
O trabalho de teste de modelo gera o arquivo de predictions.csv armazenado no armazenamento de dados padrão criado com o workspace. Esse armazenamento de dados é visível para todos os usuários com a mesma assinatura. Os trabalhos de teste não são recomendados para cenários em que qualquer informação usada ou criada pelo trabalho de teste precisa permanecer privada.
Testar o modelo de ML automatizado existente (versão prévia)
Após a conclusão do experimento, você pode testar os modelos gerados pelo ML automatizado para você.
Importante
Testar seus modelos com um conjunto de dados de teste para avaliar modelos gerados por ML automatizados é uma versão prévia do recurso. Esse recurso está em versão prévia experimental e pode mudar a qualquer momento.
Esse recurso não está disponível para os seguintes cenários de ML Automatizado:
- Tarefas da Pesquisa Visual Computacional
- Muitos modelos e treinamento de previsão de série temporal hierárquica (versão prévia)
- Tarefas de previsão em que as DNN (redes neurais de aprendizado profundo) estão habilitadas
- Trabalhos do ML automatizado na computação local ou em clusters do Azure Databricks
Se você quiser testar um modelo diferente gerado por ML automatizado e não o modelo recomendado, siga estas etapas:
Selecione um trabalho de teste de ML automatizado existente.
Navegue até a guia Modelos do trabalho e selecione o modelo concluído que você deseja testar.
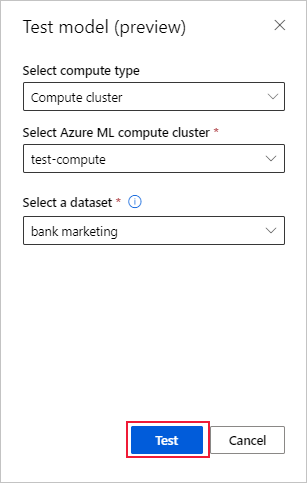
Na página Detalhes do modelo, selecione a opção Modelo de teste (versão prévia) para abrir o painel Modelo de teste.
No painel Modelo de teste, selecione o cluster de computação e um conjunto de teste que você deseja usar para o trabalho de teste.
Selecione no botão Testar. O esquema do conjunto de dados de teste deve corresponder ao conjunto de dados de treinamento, mas o Coluna de destino é opcional.
Após a criação bem-sucedida do trabalho de teste do modelo, a página Detalhes exibirá uma mensagem de êxito. Selecione a guia Resultados de teste para ver o progresso do trabalho.
Para exibir os resultados do trabalho de teste, abra a página Detalhes e siga as etapas na seção Exibir resultados do trabalho de teste remoto.
Painel de IA Responsável (versão prévia)
Para entender melhor seu modelo, você pode ver várias informações sobre seu modelo usando o painel de IA Responsável. Essa interface do usuário permite que você avalie e depure seu melhor modelo de ML automatizado. O painel de IA Responsável avalia erros de modelo e problemas de imparcialidade, diagnostica por que os erros estão acontecendo avaliando seus dados de treinamento e/ou teste e observando explicações do modelo. Juntos, esses insights podem ajudar você a criar confiança em seu modelo e a ser aprovado nos processos de auditoria. Dashboards de IA responsável não podem ser gerados para um modelo de ML automatizado existente. O painel é criado apenas para o modelo mais recomendado quando um novo trabalho de ML automatizado é criado. Os usuários devem continuar a usar explicações de modelo (versão prévia) até que o suporte seja fornecido para modelos existentes.
Gere um painel de IA responsável para um modelo específico seguindo estas etapas:
Enquanto você envia um trabalho de ML automatizado, prossiga para a seção de Configurações da Tarefa no menu à esquerda e selecione a opção Exibir configurações adicionais.
Na página Configuração adicional, selecione a opção Explicar o melhor modelo:
Alterne para a guia Computação e selecione a opção Sem servidor para sua computação:
Após a conclusão da operação, navegue até a página Modelos do trabalho de ML Automatizado, que contém uma lista dos modelos treinados. Selecione o link do painel de IA Responsável da exibição:
O painel de IA responsável é exibido para o modelo selecionado:
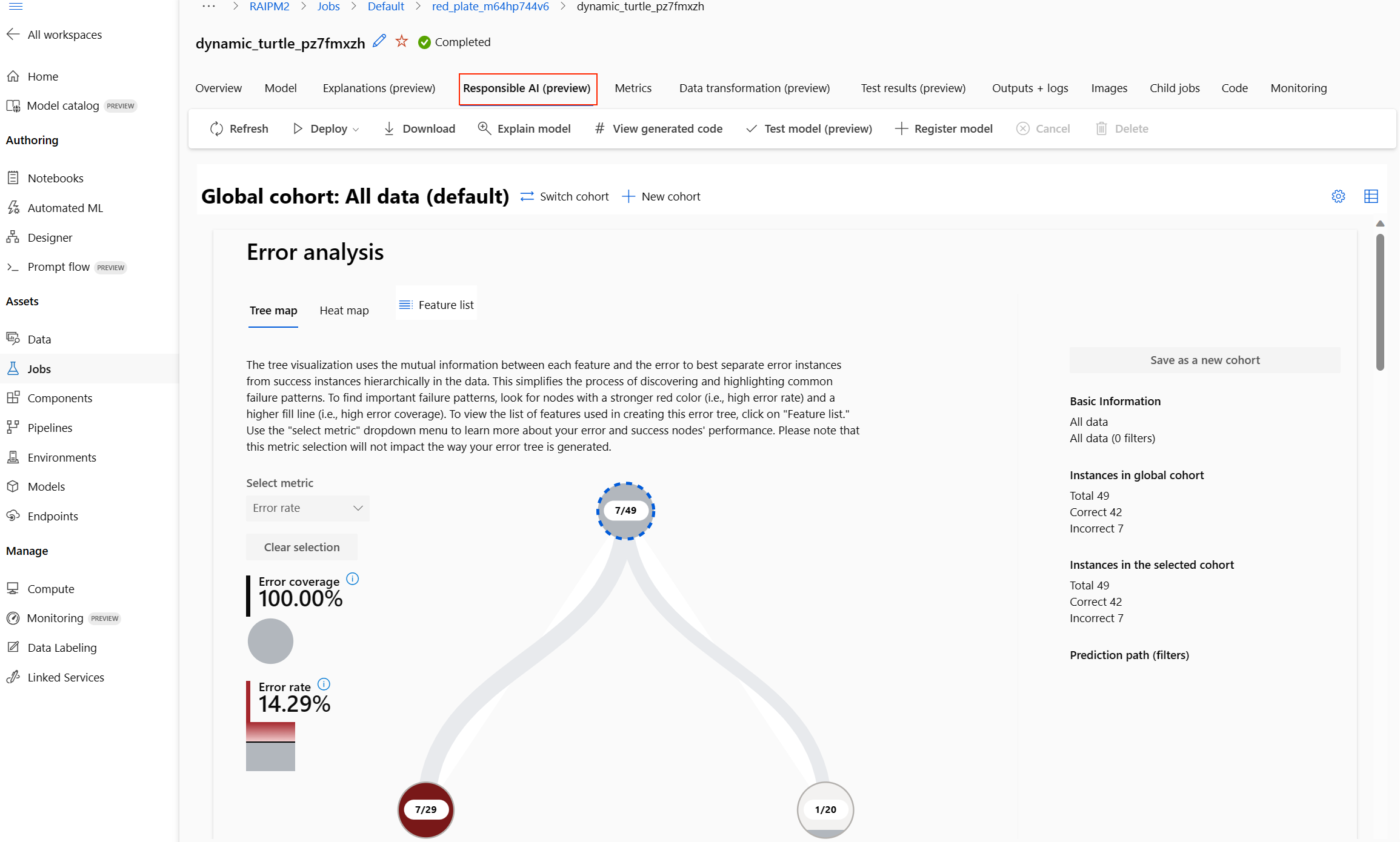
No painel, você verá quatro componentes ativados para seu melhor modelo de ML Automatizado:
Componente O que o componente mostra? Como fazer a leitura do gráfico? Análise de Erro Use a Análise de Erro quando precisar:
– Obtenha uma compreensão profunda de como as falhas de modelo são distribuídas em um conjunto de dados e em várias dimensões de entrada e recursos.
- Divida as métricas de desempenho agregado para descobrir automaticamente coortes errôneas para informar as etapas de mitigação direcionadas.Gráficos de Análise de Erros Visão geral do Modelo e Imparcialidade Use este componente para:
– Obtenha uma compreensão profunda do desempenho do modelo em diferentes coortes de dados.
- Entenda os problemas de imparcialidade do modelo examinando as métricas de disparidade. Essas métricas podem avaliar e comparar o comportamento do modelo em subgrupos identificados em termos de recursos confidenciais (ou não confidenciais).Visão geral do Modelo e Gráficos de Imparcialidade Explicações do Modelo Use o componente de explicação do modelo para gerar descrições compreensíveis por humanos das previsões de um modelo de aprendizado de máquina, observando:
– Explicações globais: por exemplo, quais recursos afetam o comportamento geral de um modelo de alocação de empréstimo?
- Explicações locais: por exemplo, por que o pedido de empréstimo de um cliente foi aprovado ou rejeitado?Gráficos de Explicabilidade do Modelo Análise de Dados Use a análise de dados quando precisar:
– Explore as estatísticas do conjunto de dados selecionando filtros diferentes para dividir seus dados em dimensões diferentes (também conhecidas como coortes).
- Entenda a distribuição do conjunto de dados entre diferentes coortes e grupos de recursos.
- Determine se suas descobertas relacionadas à imparcialidade, análise de erro e causalidade (derivadas de outros componentes do painel) são resultado da distribuição do conjunto de dados.
- Decida em quais áreas coletar mais dados para atenuar erros provenientes de problemas de representação, ruído de rótulo, ruído de recurso, viés de rótulo e fatores semelhantes.Gráficos do Data Explorer Além disso, é possível criar coortes (subgrupos de pontos de dados que compartilham características específicas) para concentrar a análise de cada componente em diferentes coortes. O nome da coorte atualmente aplicada ao painel é sempre mostrado na parte superior esquerda do painel. O modo de exibição padrão no painel é todo o conjunto de dados, intitulado Todos os dados por padrão. Para obter mais informações, consulte Controles globais para seu painel.


Editar e enviar trabalhos (versão prévia)
Em cenários em que você deseja criar um novo experimento com base nas configurações de um experimento existente, o ML automatizado fornece a opção Editar e enviar na interface do usuário do estúdio. Essa funcionalidade é limitada a experimentos iniciados na interface do usuário do estúdio e requer o esquema de dados para o novo experimento corresponder ao teste original.
Importante
A capacidade de copiar, editar e enviar um novo experimento com base em um experimento existente é um versão prévia do recurso. Esse funcionalidade é uma versão prévia do recurso experimental e pode mudar a qualquer momento.
A opção Editar e enviar abre o assistente Criar um novo trabalho de ML Automatizado com os dados, a computação e as configurações de experimento pré-preenchidos. Você pode configurar as opções em cada guia no assistente e editar seleções conforme necessário para o novo experimento.
Implantar o seu modelo
Depois de ter o melhor modelo, você pode implantar o modelo como um serviço Web para prever novos dados.
Observação
Para implantar um modelo gerado por meio do pacote automl com o SDK do Python, você deve registrar seu modelo) no workspace.
Depois de registrar o modelo, você pode localizar o modelo no estúdio selecionando Modelos no menu à esquerda. Na página de visão geral do modelo, você pode selecionar a opção Implantar e continuar na Etapa 2 nesta seção.
O ML Automatizado ajuda a implantar o modelo sem escrever códigos.
Inicie a implantação usando um dos seguintes métodos:
Implante o melhor modelo com os critérios de métrica que você definiu:
Após a conclusão do experimento, selecione Trabalho 1 e navegue até a página de trabalho pai.
Selecione o modelo listado na seção Resumo do melhor modelo e selecione Implantar.
Para implantar uma iteração de modelo específica deste experimento:
- Selecione o modelo desejado na guia Modelos e selecione Implantar.
Preencha o painel Implantar um modelo:
Campo Valor Nome Insira um nome exclusivo para sua implantação. Descrição Insira uma descrição para identificar melhor a finalidade da implantação. Tipo de computação Selecione o tipo de ponto de extremidade que você deseja implantar: Serviço de Kubernetes do Azure (AKS) ou Instância de Contêiner do Azure (ACI). Nome da computação (Aplica-se somente ao AKS) Selecione o nome do cluster do AKS no qual você deseja implantar. Habilitar autenticação Selecione para permitir a autenticação baseada em token ou em chave. Usar ativos da implantação personalizada Habilite ativos personalizados se você quiser carregar seu próprio script de pontuação e arquivo de ambiente. Caso contrário, o ML automatizado fornece esses ativos para você por padrão. Para saber mais, confira Implantar e classificar um modelo de machine learning usando um ponto de extremidade online. Importante
Os nomes de arquivo devem ter entre 1 e 32 caracteres. O nome deve começar e terminar com alfanuméricos e pode incluir traços, sublinhados, pontos e alfanuméricos entre eles. Não são permitidos espaços.
O menu Avançado oferece recursos de implantação padrão, como coleta de dados e configurações de utilização de recursos. Você pode usar as opções neste menu para substituir esses padrões. Para obter mais informações, consulte Monitorar pontos de extremidade online.
Selecione Implantar. A implantação pode levar cerca de 20 minutos para ser concluída.
Após o início da implantação, a guia Resumo do modelo é aberta. Você pode monitorar o progresso da implantação na seção de Status de implantação.
Agora você tem um serviço Web operacional para gerar previsões. Você pode testar as previsões consultando o serviço nos exemplos de IA de ponta a ponta do no Microsoft Fabric.
Conteúdo relacionado
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de